沱江水质模糊综合评价及主要污染物的预测研究
2021-01-05符东吴雪菲易珍言陈永灿
符东,吴雪菲,易珍言,陈永灿,3*
(1.西南科技大学环境与资源学院,四川 绵阳 621010;2.四川文理学院化学化工学院,四川 达州 635000;3.清华大学水沙科学与水利水电工程国家重点实验室,北京 100084)
沱江位于四川省中部,是长江上游的一条支流。沱江自北向南流经金堂县赵镇,穿过金堂峡进入简阳市,经过资阳市、内江市、自贡市,最后在泸州市汇入长江。作为四川盆地重要的自然资源,在过去几十年,由于受到工农业活动的影响,沱江水质呈现出了不同程度的恶化[1]。虽然沱江的水资源对整个四川盆地的经济社会发展起着重要作用,但是对整个沱江的水质评价、污染源解析及水质模拟的综合研究却较少。因此,对沱江水体进行水质综合评价和预测显得尤为重要。水质评价及预测可以为沱江水环境综合治理提供科学合理的分析,有助于制定水环境综合治理针对性方案,同时可以模拟水质的变化趋势,为水环境规划与管理提供科学支撑。
目前,水质评价方法主要有模糊综合评价(Fuzzy comprehensive assessment,FCA)法[2]、人工神经网络(Artificial neural network,ANN)评价法[3]、地理信息系统方法[4]以及多种方法的相互耦合[5]等。由于水环境的连续性及不确定性,国内外学者常选择模糊综合评价法应用于地下水和湖库河流、海水等地表水环境的评价中[6-10]。例如,徐晓云等[11]利用模糊综合评价法对京杭大运河扬州段的水质进行了评价,并分析了水质的主要污染来源。樊庆锌等[12]利用灰色关联度和主成分分析法优化评价指标,并结合模糊综合评价对松花江哈尔滨段的水质进行了评价。向文英等[13]通过改进权重赋值方法,利用模糊综合评价对某水库水质进行了评价。在水质评价的基础上进行污染源解析和水质预测,可以对主要污染因子的时空变化趋势进行分析,掌握水体水质的变化状况。人工神经网络能够精确地计算复杂的非线性输入输出关系,因此被广泛用于水质的预测[14-16]。当前水质预测主要包括以当前数据预测未来水质变化趋势[17-18]和以当前采样点数据预测其他采样点水质变化趋势[19-20]两个方面。虽然模糊综合评价和人工神经网络预测在水环境中应用广泛,但大多数研究对模糊综合评价中评价因子的筛选没有详细的描述和论证,同时对人工神经网络输入指标的选择大多都基于主观性,使得计算结果不能真实反映水体的状况。鉴于沱江的重要性,本文在前人研究的基础上,拟采用沱江流域31个监测断面2018年1月—2019年10月的逐月水质数据,通过筛选评价因子对各断面使用模糊综合评价方法进行水质评价。在水质评价的基础上,利用主成分分析(Principal component analysis,PCA)识别沱江的主要污染源和污染因子,然后构建BP(Back Propagation,BP)神经网络,并利用内江二水厂断面数据预测申家沟断面主要污染因子浓度。以期为沱江的综合管理提供一定的参考。
1 研究区域及指标

图1 沱江及各监测断面位置分布图Figure 1 Tuo River and location distribution of the monitoring sections
本文选择了沱江上游至下游的31个(SS1~SS31)监测断面,沱江流域及各监测断面分布如图1所示。水质数据来源于中国环境监测总站在各监测断面2018年1月—2019年10月的逐月监测浓度。水质指标包括化学需氧量(CODCr)、溶解氧(DO)、五日生化需氧量(BOD5)、高锰酸盐指数(CODMn)、总氮(TN)、总磷(TP)、氨氮(NH3-N)、硝酸盐(NO-3)、硫酸盐(SO24-)、氟化物(F-)、氯化物(Cl-)、pH、氰化物(CN-)、硫化物(S)、阴离子表面活性剂(LAS)、石油类(Oils)、挥发酚(V-phen)、电导率(EC)、粪大肠菌群(E.coli)、汞(Hg)、铅(Pb)、铜(Cu)、锌(Zn)、铁(Fe)、锰(Mn)、六价铬(Cr6+)、镉(Cd)和温度(T)等。为保证所选指标能真实反映水体状况,需对模糊综合评价的评价因子集进行筛选和优化。GB 3838—2002《地表水环境质量标准》中[21]未对pH、T、、、Cl-、Fe、Mn和EC的浓度做出等级划分和明确要求,故将这些指标排除。CN-、S、LAS、Oils、V-phen、Hg、Pb、Cu、Zn、Fe、Mn、Cd、Cr6+浓度均符合Ⅰ类水质标准且浓度长期稳定无变化,因此将这些指标排除。E.coli由于监测次数较少,数据不连续,所以排除该指标。经过筛选后的评价因子集包含 CODCr、DO、BOD5、CODMn、TN、NH3-N、TP和F-,各指标的统计分析如表1所示。在模糊综合评价和主成分分析的基础上,选取主要污染物,利用BP神经网络对其进行预测。构建BP网络前,利用各指标的相关性,确定BP网络的输入变量。
2 方法及原理
2.1 模糊综合评价模型
2.1.1 评价因子集与评价标准
沱江流域工业集中、农业发达、食品业和养殖业密集。针对各行业废水特点以及检测数据,兼顾相关标准的水质要求,经过对28个物理化学水质参数筛选,最后使用选定的8个指标构建因子集,因子集可以表示为CTP}。评价标准依据《地表水环境质量标准》,具体如表1所示。
2.1.2 评价因子权重
模糊综合评价过程中,需要对每一个评价因子赋予相应的权重。本文选择污染因子贡献率法计算各评价因子的权重:

式中:xi为污染物i的实测浓度;Si为各评价因子的第Ⅲ类水质标准;wi为归一化后的i因子权重。评价因子的权重向量可表示为 W={w1,w2,...,wn},n为评价因子个数。由于DO属于数值越大,水质越好,所以对于 DO,ai=Si∕xi。
2.1.3 隶属函数与模糊矩阵
建立各评价因子的隶属函数,得到其对每一类水质的隶属度,进而得到模糊关系矩阵R。目前,隶属度一般采用“降半梯形分布法”计算[22]。对于数值越大污染越重的因子,可根据公式(2)~公式(4)计算其对应评价标准各等级的隶属度。
Ⅰ类水的隶属函数,即j=1时:
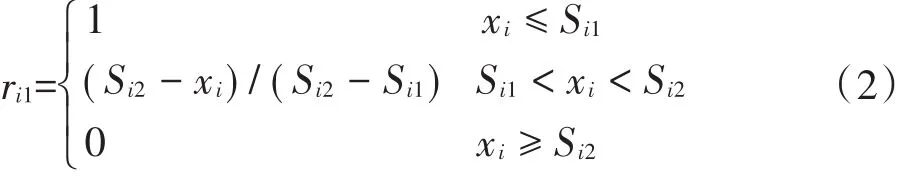
Ⅱ~Ⅳ类水的隶属函数,即j=2~4时:

Ⅴ类水的隶属函数,即j=5时:

式中:xi为评价因子i的实际监测浓度(i=1,2,…,8);Sij为第i个因子的第j类水质标准(j=1,2,…,5)。由于DO属于数值越小,污染越严重,其隶属函数如公式(5)~公式(7)所示。

表1 评价因子统计分析及水质标准(mg·L-1)Table 1 Statistical analysis of evaluation factors and water quality standards(mg·L-1)
Ⅰ类水的隶属函数,j=1时:
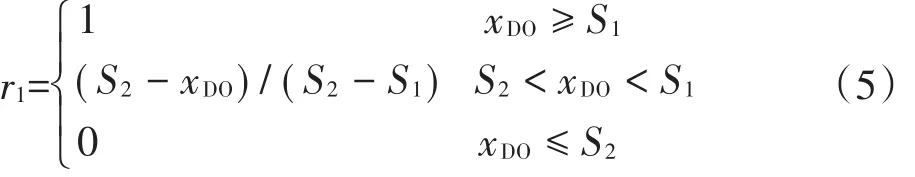
Ⅱ~Ⅳ类水的隶属函数,即j=2~4时:

Ⅴ类水的隶属函数,即j=5时:
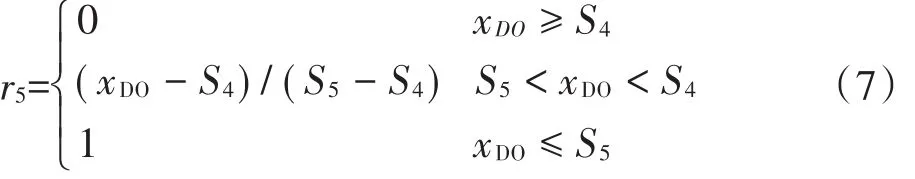
将各监测断面的评价因子浓度带入相应的隶属函数中,计算得到不同评价标准的隶属度。然后建立每个断面的单因素评价矩阵R:

式中:rij为第i个评价因子对第j类水的隶属度。
2.1.4 模糊综合评价
根据上述求得的权重向量和单因素评价矩阵,选取相乘相加算子[23]计算评价结果:B=W·R={b1,b2,b3,b4,b5},选取bmax对应的水质类别作为评价结果。
2.1.5 主成分分析
主成分分析是一种数学方法,它可以减少水质数据集的维数,同时使数据集中有用信息的损失程度较小,进而使数据集更容易理解。本文对31个监测断面在2018—2019年监测的12种变量(增加Cl-、和EC 4个指标)进行了主成分分析,以确定沱江的潜在污染源。
2.2 BP神经网络模型
2.2.1 网络参数选择
在构建BP神经网络时,需对选用的输入输出数据进行训练,以沱江内江二水厂断面(断面编号SS23)的水质数据对沱江申家沟断面(断面编号SS24)主要污染指标进行预测。BP网络相关的参数选择如下:输入层与隐含层之间的传递函数为tansig函数,隐含层与输出层之间的传递函数为purelin函数,数据归一化函数为mapminmax,训练函数为trainlm,最大学习次数1 000,目标误差为0.000 5,学习速率为0.01,其余参数为默认值。
2.2.2 网络拓扑结构
本研究输入层神经元个数的确定方法为,根据模糊综合评价结果确定沱江的主要污染因子,然后利用各水质参数与主要污染的相关性分析确定输入层神经元个数。输出层的神经元为沱江流域下游某断面的主要污染物浓度,所以输出层神经元个数为1。输入层和输出层数均为1。对于含有1个隐含层的BP神经网络,其可以逼近任意一个非线性函数,所以本研究采用1个隐含层。隐含层神经元个数的确定目前没有明确的方法,因此本文采取试错法确定隐含层神经元的个数[24]。
3 结果与讨论
3.1 沱江水质模糊综合评价
本文经过指标筛选并构建评价因子,利用公式(1)计算各监测断面评价因子的归一化权重。通过复合运算B=W·R,以最大隶属度原则可得出当前断面的水质类别。以断面SS2为例,单因素评价矩阵为:

断面SS2的权重向量为W={0.057,0.076,0.075,0.130,0.060,0.075,0.356,0.171},则断面SS2的评价结果为 B={0.365,0.125,0.154,0,0.356},根据最大隶属度原则,评价结果为Ⅰ类。沱江各断面的评价结果如表2所示。
从表2可以看出,沱江31个监测断面中有9个断面评价为Ⅰ类水,占比29.03%,其余22个断面均为Ⅴ类水,占比70.97%。按照现有沱江水质功能区划分,普遍水质标准为Ⅲ类水[25],因此目前沱江已被严重污染。从各监测断面评价结果可知,断面SS2、SS3、SS18~SS22、SS30和SS31为Ⅰ类水。综合图1可以发现,这部分断面均位于远离城郊的农村地区,森林覆盖率较高,同时周围没有工业和服务业,受人为活动的影响较小。其余22个断面为Ⅴ类水,上游、中游和下游均有分布。此部分断面具有靠近市区和城镇、人口密度大、种植业发达等特点,因此受人为活动的影响较大。从权重赋值可以得出,在挑选的8个水质评价因子中,TN的浓度很高,几乎所有断面的TN浓度都超过了Ⅴ类水的水质标准,所以导致沱江属于Ⅴ类水的监测断面比例较高。但是在沱江9个Ⅰ类水断面中,有2个断面(SS2、SS3)的TN浓度超过Ⅴ类水水质标准,有4个断面(SS19、SS20,SS30、SS31)的TN浓度超过了Ⅳ类水水质标准。因此,即使该监测断面评价结果为Ⅰ类水,也需对其中的TN浓度加以控制。从各断面监测数据可以看出,除了TN以外,其他水质指标均能满足Ⅲ类水水质标准。
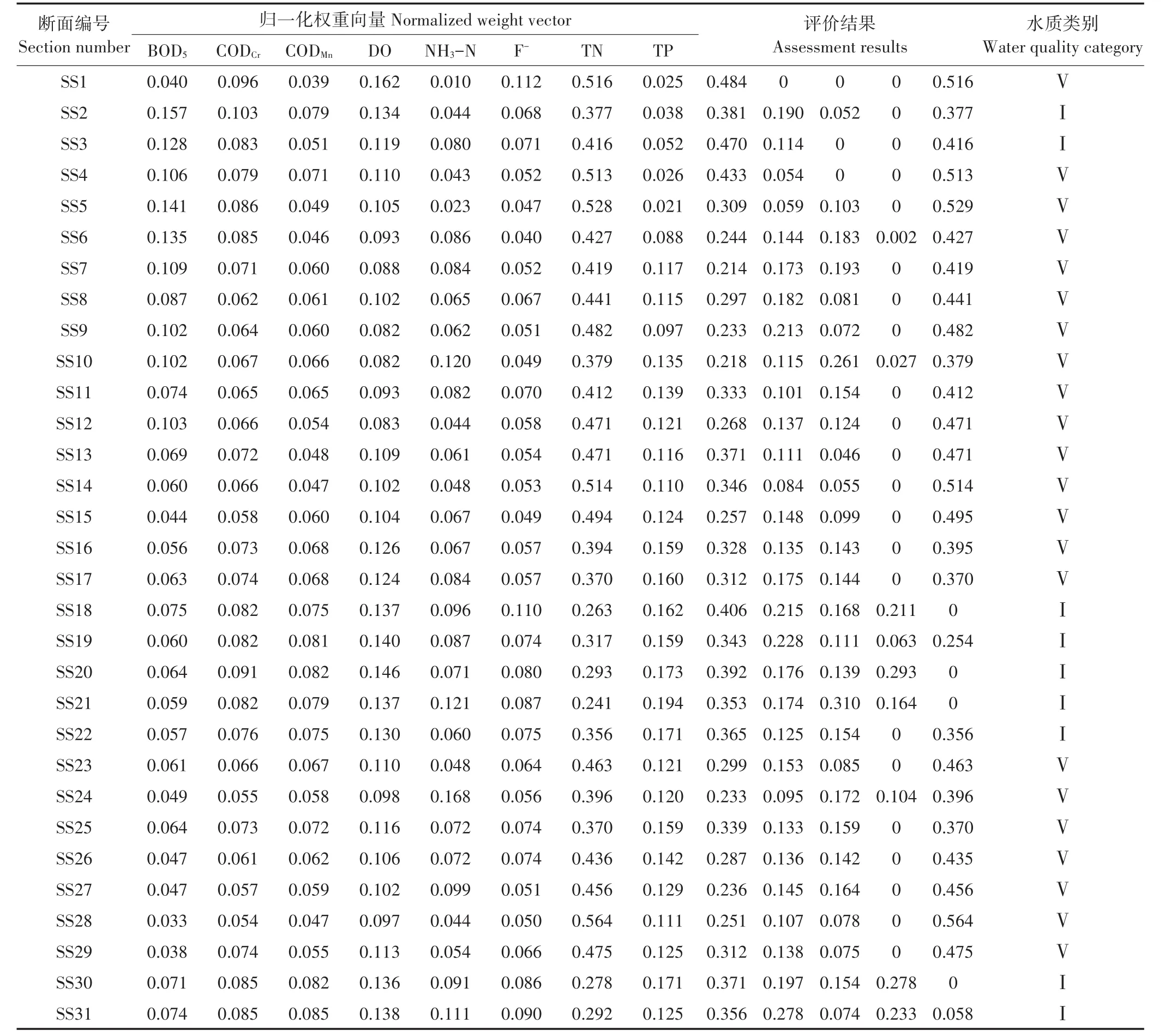
表2 沱江水质模糊综合评价结果Table 2 Results of fuzzy comprehensive assessment of water quality in Tuo River
3.2 沱江潜在污染源
利用沱江12个水质参数的主成分分析法对不同污染物的来源进行识别。Bartlett球形检验的值为785,KMO值为0.709(P<0.01),说明数据集适合主成分分析。以特征值大于1为基础,从沱江水质数据集中提取4个主成分[26],如表3所示。
第一个主成分(F1)对NO-3、SO2-4、EC和TN具有较强的正载荷,对TP具有中等的正载荷,对NH3-N具有较弱的正载荷,F1占总方差的28.263%。根据模糊综合评价结果可知,整个沱江的TN浓度很高。同时,沱江流域农业相对发达,氮和磷可以通过氮肥和磷肥的径流进入河流[27-30]。可能来自矿物岩石[31],但是在所有断面的浓度低且较为稳定,因此综合氮和磷的来源分析,F1可以看作是农业面源污染。第二个主成分(F2)对CODMn有强的正载荷,对Cl-和TP有中等的正载荷,对DO有中等的负载荷,F2解释了总方差的19.644%。根据CODMn和DO的载荷,F2可能是一种耗氧污染源[32]。同时,沱江流域的化工厂和制造业较多,Cl-可能来自工业废水。因此F2可能代表工业废水污染[29]。第三个主成分(F3)占总变异量的16.987%,对CODCr和BOD5的正载荷较大,对NH3-N的负载荷较小。F3包括营养物质和有机污染物,可归因于生活污水和工业废水[33]。由于大多数采样点的大肠杆菌浓度很高,基本超过地表水Ⅴ类标准(由于数据的不连续性,未对大肠杆菌浓度做其他分析),因此F3更有可能是生活污水污染源。第四个主成分(F4)对F-有较强的正载荷,对CODMn有较弱的负载荷,解释了总方差的9.195%。F-通常来自氟化工厂、水泥厂和冶炼厂,但沱江各采样点F-的平均浓度均未超过地表水Ⅰ类水质标准值,污染程度几乎为零或极低,因此沱江中的F-可能是当地土壤随径流进入的结果[34]。所以F4可以看作是土壤风化。综合以上分析,可以确认农业面源和工业废水是沱江的主要污染源[35]。
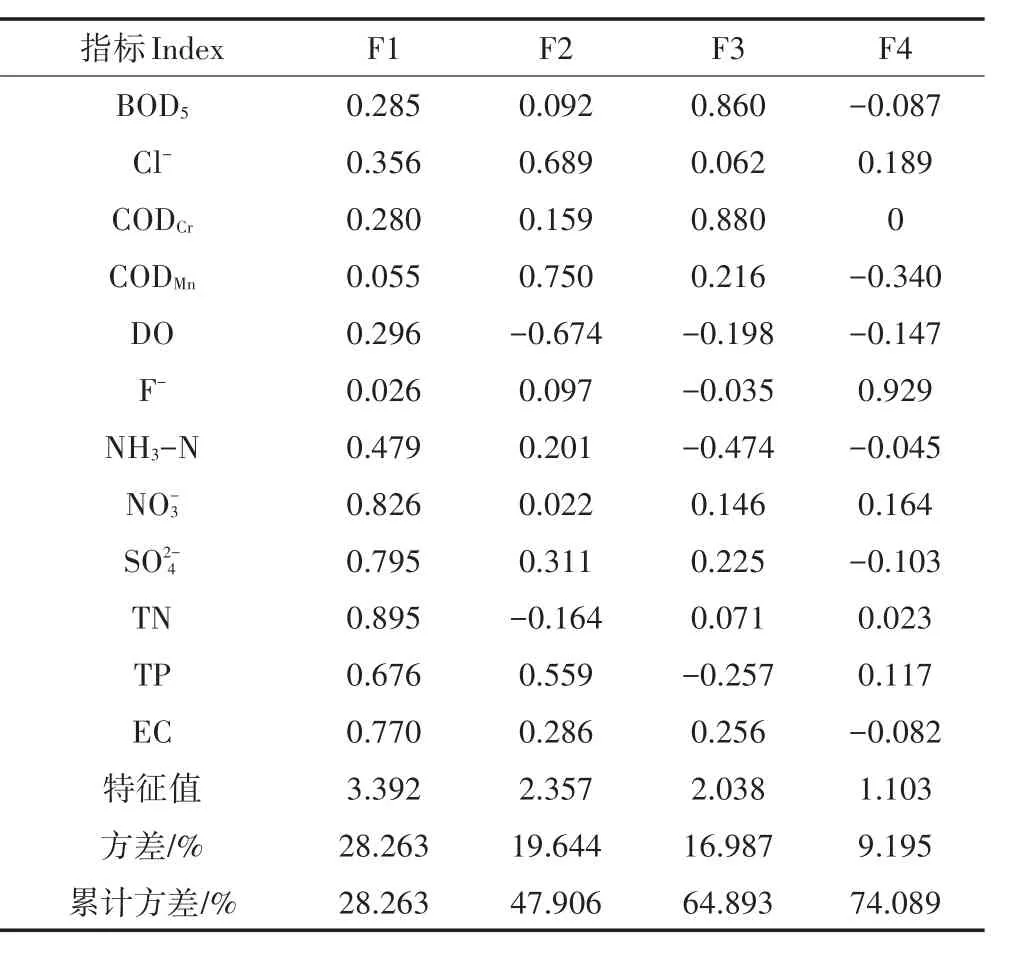
表3 12种指标的旋转因子载荷矩阵Table 3 Loadings of 12 measured variables on VARIMAX rotated factors
3.3 沱江水质预测
根据模糊综合评价和主成分分析结果,选取TN为预测指标,即输出层为1个神经元。将上述用于主成分分析的12个指标作为BP神经网络的输入备选集。数据统计技术可以帮助确定BP神经网络的输入参数[36-37]。本文通过相关性分析,选取与TN浓度显著相关且相关系数大于0.3的指标作为最终的BP输入参数,具体如表4所示。最终选择CODCr、NH3-N、NO-3、SO2-4、EC和TN为输入变量,即利用内江二水厂断面的CODCr、NH3-N、NO-3、SO2-4、EC和TN浓度预测申家沟断面的TN浓度。通过试错法确定了隐含层的神经元个数为4,所以BP网络的拓扑结构为6-4-1。根据相关系数r、决定系数R2和相对误差评价模型预测精度[38-40],模型预测结果及相对误差如图2和图3所示。
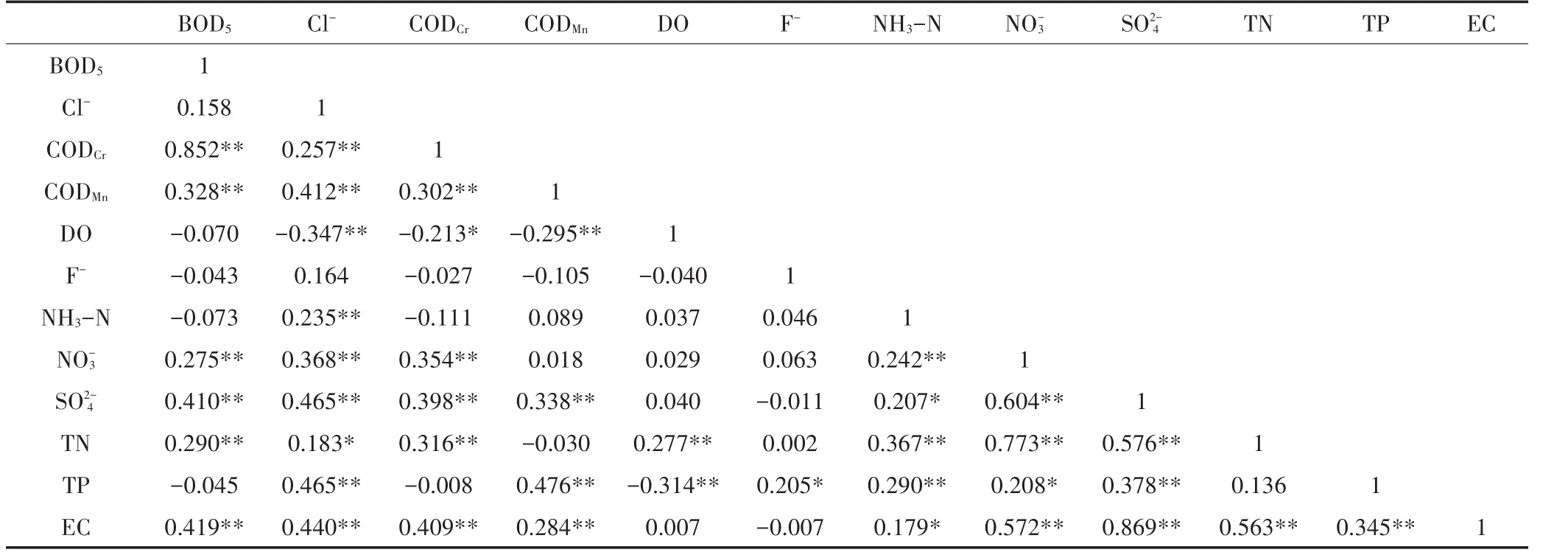
表4 各指标的相关性Table 4 The correlation of each index
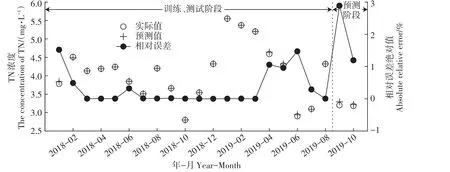
图2 BP神经网络预测值与实际值的散点图Figure 2 The scatter plot of predicted value and measured value of BP neural network

图3 TN线性回归方程Figure 3 Linear regression equation of TN
BP神经网络达到收敛时的MSE为0.000 49。另外从图2和图3可以看出,本文构建的BP神经网络在预测TN浓度时的决定系数R2为0.999,模型在训练、测试和验证阶段的相对误差均小于1.5%。虽然在预测阶段的相对误差有明显增大,但均小于3%,这有可能与用于BP神经网络训练的水质样本数量较少有关。同时利用SPSS计算实测值与预测值的Pearson相关系数,其结果表明TN的实测值与预测值极显著相关(r=0.99,P<0.01)。以上评价参数都表明构建的BP神经网络符合水质预测要求,在样本较少的情况下能够对沱江水质进行有效预测。
4 结论
(1)沱江31个评价断面中有9个断面水质符合Ⅰ类水,占29.03%,其余22个断面均为Ⅴ类水,占比70.97%。Ⅴ类水水质断面在沱江上游、中游和下游均有分布,表明沱江整体污染较为严重。
(2)沱江各监测断面TN浓度均超过Ⅳ类水质标准,其中27个监测断面超过Ⅴ类水质标准,说明沱江的主要污染物为TN。通过主成分分析,确定沱江TN的主要来源为农业面源和工业废水。
(3)通过对输入数据筛选,构建的BP神经网络性能较好,预测精度高。在对沱江申家沟断面TN浓度的预测时,平均相对误差为2.041%。基于本文的内容,可构建沱江其他断面的BP神经网络模型,并用于以沱江上游水质数据预测下游水质断面的TN浓度。
