数据挖掘技术在智能图书馆云检索系统中的应用研究
2020-12-31张成叔
张成叔
(1.合肥工业大学计算机与信息学院,安徽合肥 230001;2.安徽财贸职业学院信息工程学院,安徽合肥 230601)
随着数据信息量的不断增加,传统图书馆信息管理模式逐渐向数字化信息管理模式方向转化,加大了对数据信息管理技术要求[1-2]。多年来,图书馆信息管理主要阶段有3 个,分别是传统管理模式、基于现代化设备的信息管理模式、基于现代化技术的智能管理模式[3]。目前,图书馆信息管理正处于第三个阶段,着重发展智能图书馆云检索系统,选取数据挖掘技术作为研究工具展开应用研究。
1 图书馆资源检索服务现状及发展趋势
网络技术的快速发展,促进了我国图书馆资源检索改进发展步伐,借助互联网平台,开发了一些资源检索系统,利用系统完成高效检索服务操作[4]。目前,系统开发应用比较多的工具包括神经网络架构技术、云计算技术、模糊综合计算技术等[5]。实践应用结果表明,这些工具的应用开发出的检索系统在很大程度提高了资源检索效率,但是仍然存在一定提升空间[6]。以500GB 文件检索为例,设定50 个节点,统计如表1所示为不同技术应用下的资源检索耗时情况统计结果。

表1 不同技术应用下的资源检索耗时情况统计结果(单位:ms)
表1 中,3 项系统开发技术的应用在2017 年至2019 年有所进步,但是资源检索消耗时间缩短幅度较小。随着图书馆资源数据信息的不断增加,仍然需要对这些技术进行改进。在检索算法层面上开展新的突破,此项发展目标可以通过改进算法、更换新的技术开发算法等多条路径来实现。
2 大数据挖掘技术
大数据挖掘技术属于数据处理技术,在众多数据当中,根据设定的数据信息搜索范围,从中提取潜在信息,通常情况下,这部分潜在的信息是很难发现的,采用其他数据信息检索方法无法达到该项技术的检索水平[7]。实际上,数据挖掘是一个循环过程,在没有达到预期目标之前,会按照设定步骤反复循环执行,直至达到预期目标。目前,该项技术已经在很多领域均有所应用,根据信息挖掘需求设定限制条件,以此获取较为全面的数据信息。
3 大数据挖掘技术在图书馆中个性化服务的应用
3.1 大数据挖掘技术在图书馆中的应用层面
近年来,我国加大了对图书馆服务水平要求,提出了个性化服务。此项服务工作的开展,需要收集海量数据,对数据进行有效统计分析,从而为用户提供高质量服务,以此加快服务效率,扩大服务范围。以往采用的数据统计软件无法满足这些应用需求,大数据挖掘技术的出现,打破了此困境,为图书馆个性化服务开辟了新的路径。通过查阅资料,总结此项技术在图书馆中的几个重要应用层面:(1)文献阅读、文献参考情况、用户对文献资料需求情况等数据信息统计;(2)文献查阅记录、查阅人个人信息、资料下载时间、资料检索耗时等多项指标信息的统计;(3)师生用户对图书馆资源的反馈,根据师生使用资源情况,为其推荐图书及文献资源;(4)支持数据空间分布,图书文献资源管理更加清晰[8]。
3.2 大数据挖掘技术的图书馆个性化服务实现关键
大数据挖掘技术在图书馆服务中的应用层面足以证明该项技术的强大,是图书馆发展个性化服务不可缺少的工具,如何充分发挥该项技术在图书馆服务应用中的作用,提出可行性较高的应用方案成为了当前重点研究内容。
通常情况下,大数据挖掘技术在系统开发中应用较多,借助互联网平台,依据操作功能需求开发系统框架结构,并编写运行算法,从而实现各项操作功能[9]。图书馆个性化服务的实现,可以尝试借助此项技术,依据图书馆服务需求,开发一套智能操作系统。信息检索作为图书馆系统的核心功能,数据管理工作量较大,对操作技术水平要求较高[10]。因此,在探究大数据挖掘技术在图书馆个性化服务中的应用方案,应该重点探究系统检索功能。
随着互联网的迅速发展,推出了云端信息管理,在很大程度上扩大了系统存储空间,为图书馆检索系统开发提供了有利条件。因此,创造图书馆云检索系统是当前图书馆开展图书资源信息检索工作的关键。
4 智能图书馆云检索系统
4.1 智能图书馆云检索系统框架结构
选取Hodoop 和存储设备作为系统信息存储单元,用于存储图书文献信息,利用HDFS 等工具开发管理模块,通过JDBC 接口建立图书馆管理平台与用户计算机之间的通信接口,从而实现图书馆云端检索访问。如图1所示为系统框架结构。

图1 系统框架结构
图1 中,按照功能的不同,将系统功能划分为4个层次,分别是存储层、基础管理层、应用接口层、访问层。
(1)存储层。该层次位于系统结构的底端,作为系统运行基础组件,起到资源存储管理作用。由于图书馆资源过多,加大了信息管理难度,本系统借助Hadoop 平台对设备采取虚拟化处理,并诊断存储单元作业状态。如果系统存储单元作业发生异常,立即发出警告;
(2)基础管理层。该层次位于接口层和存储层中间,起到系统组件管理作用,借助HDFS、数据仓库技术实现统一管理,使得系统能够为用户提供检索服务。在此过程中,需要根据图书馆信息检索操作需求,编写数据挖掘算法;
(3)应用接口层。该层次是系统作业重要层次结构,用于创建用户和平台的通信连接,从而实现为用户提供平台资源访问服务。其中,采用的访问端口为JDBC 接口。为了保证系统运行安全,本系统添加了用户身份认证操作环节,对不同用户身份设置了操作权限。接入网络后系统可以自动识别用户身份,判断当前用户发出的操作申请是否在权限范围内,以此提高系统访问安全性;
(4)访问层。该层次指的是用户计算机操作终端,通过互联网平台登录系统,根据文献资源检索需求搜索,并下载文献资料。在此过程中,用户的个人信息和访问信息都将记录到系统中。
4.2 系统组件开发及功能
在开发系统检索功能时,以Hadoop 平台作为开发环境,主要用到3 项管理工具:HDFS 工具,存储系统管理操作相关数据信息;MapReduce 工具,对系统运行期间涉及到的所有访问、下载、查询等数据进行进行统计处理,并生成统计结果,以便图书管理员掌握当前图书文献访问、查询等多个方面现状;Hive 工具,以信息关键词作为管理依据,对信息资源进行分析,并存储到指定文件夹。
(1)HDFS组件功能。
此组件在系统开发中的应用,按照资源类别不同,将资源划分为多个数据节点,利用控制节点加以管理,从而使得信息检索得以有序、高效推行。其中,控制节点指的是系统管理者,除了集中管理书籍文献以外,根据文献管理需求,组建图书文件存储空间,以便用户检索和下载。对于新图书文献资源的管理,按照资源类别不同,选择相应存储路径,完成文件信息节点统一管理。
图书文献资源的管理基本结构由多个数据节点组成,以块状形式存储图书文献资源。通过设定管理周期,每隔一段时间向控制节点发送资源信息。在实际应用中,用户在客户端发起资源检索操作申请,HDFS 组件将开启资源块信息传输功能,向用户提供相关资源。
(2)Hive组件功能。
Hive 组件主要用于分析与查询图书文献资源信息,通过分析图书馆资源语义,从中提取元数据,形成分析与查询操作项目执行计划。按照此计划运行,建立作业节点与任务节点之间的通信连接,通过执行引擎程序完成映射任务,从而实现图书文献资源查询。
(3)MapReduce组件功能。
MapReduce组件用来开发系统信息检索功能,运用数据挖掘技术,编写信息挖掘算法,从而实现云检索功能。此组件主要操作为调度作业,按照功能不同,将系统功能模块划分为多个切片,分别由各个节点负责操作,形成较为复杂的数据映射关系,以此实现大面积数据信息检索,获取较为全面的检索结果。关于此组件的功能开发将在下一部分应用算法研究中介绍。
5 数据挖掘技术在云检索系统开发应用中的算法研究
5.1 图书馆资源数据存储模型构建及特征量的提取
智能图书馆云检索系统功能实现的关键在于资源数据存储模型的构建,从中提取特征量,以关键词作为搜索查询依据,按照设定的检索范围,为用户查询所需图书文献资料。为了进一步优化图书馆数据库存储模型,本研究利用时间序列分析法,尝试构建数据信息流模型,依据资源集特征完成特征量提取操作,并组建目标函数,形成时间序列,记为{xm}。假设资源属性类别为X和Y,资源长度为L,对存储空间区域与节点采取分段处理,形成多个空间,实施集成分配。其中,区域划分为阈值设定为λ,当该数值满足2-μt<λ,μ>0时,构建以下资源信息流模型:

公式(1)中,h[z(t0+mΔt)]代表资源数据时间序列计算结果中的近似特征量。
智能图书馆云检索系统的正常运行,需要一定数据输出基础,为系统检索提供足够的资源信息支撑。关于此操作算法的开发,本研究对时间序列采取重构处理的同时,提取频繁项特征集。假设关联规则矩阵为X(i),输入观测向量为Y(i),关联维数为N(i),频繁项集干扰阶数为H×n。如果H、n两项指标数值存在H>n关系,则对X(i)采取资源块划分处理,形成多个大小相同的资源块,记为pi。根据资源信息聚类特征空间分布情况,以空间中的嵌入维数作为核心指标,设定子矩阵,该矩阵维数为Mij×n。聚类中心向量参数设定为Xij,那么资源信息频繁项可以用以下公式来表示:

如果H、n两项指标数值存在关系,那么资源信息频繁项计算公式如下:

考虑到图书馆存储的图书文献资源分布较为均匀,所以资源信息在存储层中的特性应该满足以下关系:

为了避免系统检索期间遭受影响因素扰动降低检索运行速率,对系统存储节点采取约束处理。此项操作功能实现的关键在于频繁项特征的提取,即通过提取所需检索的资源信息对应的频繁项特征,提高系统作业效率。特征项提取计算公式为:

公式(5)中,利用频繁项特征描述目标数据特点,提取资源信息,从而实现数据信息资源的全面检索。
5.2 系统数据资源处理
选取模糊K均值聚类方法作为资源处理工具,按照频繁项特征的不同,划分特征类别,从中提取相关信息,并输出特征矢量。以下为特征矢量计算公式:

运用公式(6)计算参数数值,从中获取图书文献资源。关于此项功能的实现,选取最小二乘法作为计算工具,对相关数值采取挖掘拟合处理。以下为数据挖掘计算公式:

以上资源处理效果受节点数据影响较大,通过设定不同节点数据,来调整系统检索资源耗费时间。以公式(7)中的各项指标作为节点数据限定依据,通过调整此公式中的指标数据,实现增加或者减小节点数据操作。
5.3 系统数据检索输出
在开发系统数据检索输出操作功能时,选取特征分解法作为研究工具,设计存储节点决策树结构,根据数据检索特征,划分为多个分支,使得检索输出结果更加清晰。具体输出步骤如下:
第1步:假设检索资源与频繁项集干扰阶数存在M(i)modH<n关系;
第2 步:按照参数特征不同,对资源信息频繁项采取分解处理。计算公式如下:

第3 步:在第二步基础上,对资源信息时间序列中参数Y(i)和参数X(i)采取自适应加权处理,使得时间序列得以有效分解。计算公式如下:

第4 步:采取谱处理方法,对检索资源的关联特征进行分析。计算公式如下:
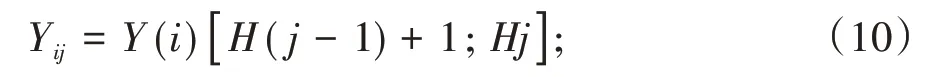
第5 步:设定以下收敛条件,以此限定资源检索范围:

第6步:输出资源检索结果。
6 应用测试分析
6.1 系统测试环境
将开发的云检索系统算法投入到某图书馆中应用,选取Matlab 软件作为仿真工具,对系统算法作业性能进行测试分析,搭建测试环境如下。
操作系统:Windows Server 2010,
CPU:酷睿i5;接口LGA1200;主频2.9GHz。
6.2 测试方法
(1)云检索系统资源检索时间测试。
为了验证算法在资源检索耗时层面上是否有所改善,通过查阅文献资料,选取神经网络架构技术、云计算技术、模糊综合计算技术应用开发系统作为对照组,以设计的系统算法作为实验组,展开实验测试研究。为了保证测试结论可靠性,研究设置3组实验,对比3 组实验测试数据,如果差异在50ms 内,认为当前系统作业耗时检测结果可靠,可以作为系统算法对比分析数据支撑。其中,检测文件大小为500GB。
(2)不同节点数量设置下数据检索时间测试。
为了充分发挥开发的系统算法在图书馆资源检索中的作用,从节点数量设置角度出发,探究节点数量不同情况下系统检索耗时情况。根据图书馆系统常规节点布设情况,设定节点数量范围60~300 个,间隔为60个,即取值60、120、180、240、300,分别测试各个节点数量设置下系统检索耗费时间。考虑到系统作业可能受到环境等因素影响,导致测试结果不准确,研究设置3组测试,对比各组测试结果。如果3组测试结果差异性较小,检索时间变动范围在±50ms内,认为当前系统作业耗时检测结果可靠。其中,检测文件大小为500GB。
6.3 测试结果分析
按照测试方法,分别对云检索系统资源检索耗时、不同节点数量设置下数据检索耗时进行测试分析,从Matlab 仿真结果中提取数据信息,得到表1 和表2中的测试结果。
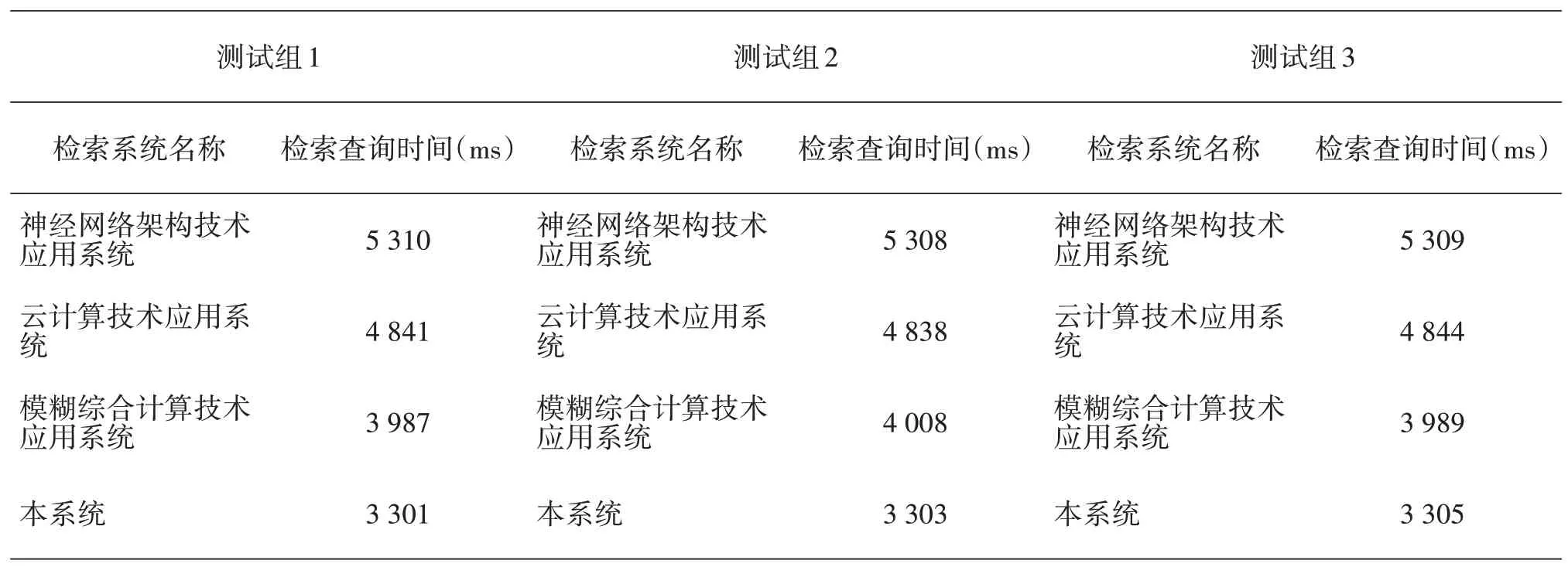
表2 云检索系统资源检索时间测试结果统计表
表2中,与神经网络架构技术、云计算技术、模糊综合计算技术应用开发系统资源检测耗时相比,本系统检索耗费的时间更短一些。另外,三组测试中,每组测试结果基本相同,所以测试结果可以作为云检索系统算法可靠性判断依据。从整体来看,本系统算法运行耗时有了明显改善,可以利用此系统算法取代传统系统作业算法,使得图书馆云系统作业效率得以有效提升。
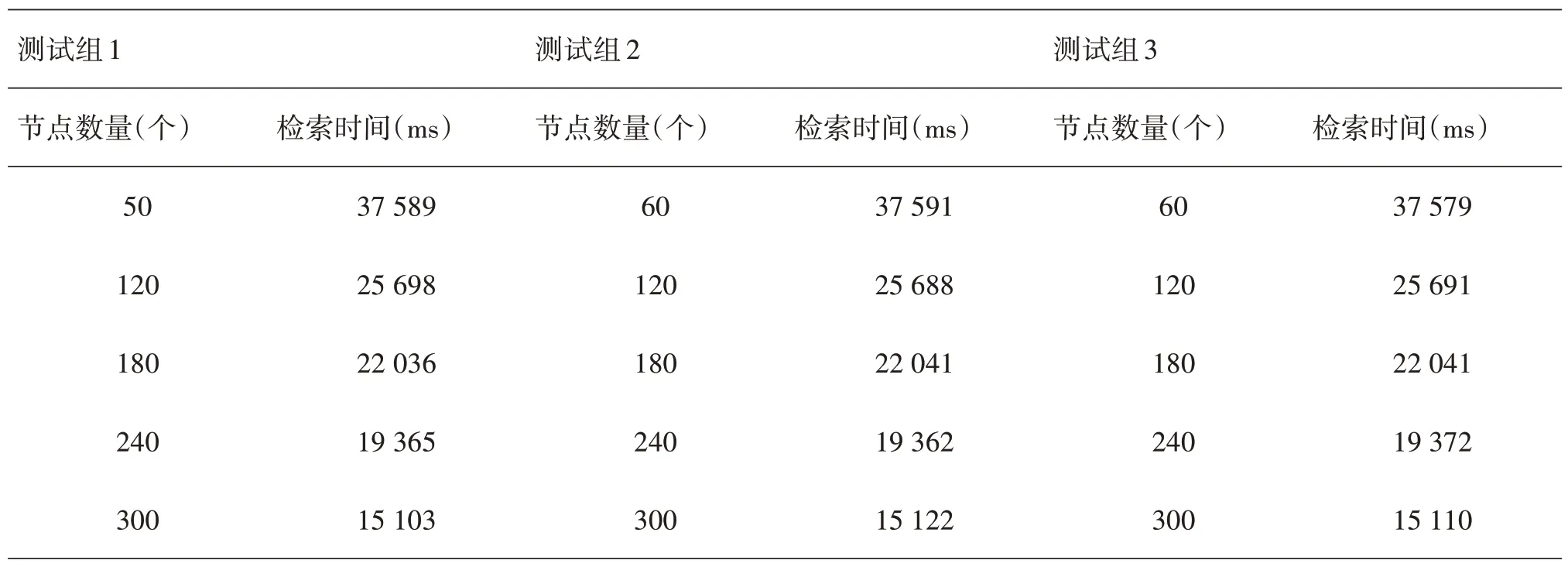
表3 不同节点数量设置下数据检索时间测试结果统计表
表3中,提出的系统算法在图书馆检索服务实际应用中,随着节点数量的增加,检索时间逐渐缩短。其中,节点数量从60 个增加至120 个时,检索时间缩短幅度最为显著。自120个节点数量以后,随着节点数量增加,检索时间缩短幅度逐渐稳定。另外,3 组测试结果差异性较小,系统算法应用稳定性较高,所以以上总结的本系统算法应用特点较为可靠。
选取数据挖掘技术作为研究工具,探究智能图书馆云检索系统开发方案。通过分析图书馆检索系统开发及实施现状,结合数据挖掘技术优势及应用范围,确定本系统开发工具。依据图书馆资源管理需求,设计系统框架结构,并开发数据挖掘技术在系统中应用算法。实验测试结果表明,本系统算法有效提高了资源检索效率,并且支持不同节点数据调整。
