基于嵌套遗传算法的拣货作业联合优化
2020-12-31孙军艳陈智瑞牛亚儒张媛媛
孙军艳,陈智瑞,牛亚儒,张媛媛,韩 昉
(陕西科技大学机电工程学院,西安 710021)
(∗通信作者电子邮箱390722942@qq.com)
0 引言
拣选作业活动是配送中心在库作业中劳动力最密集和资金占用成本最大的环节[1]。拣选作业优化主要包括订单分批、路径优化等[2],其中订单分批是前提,路径优化是关键,拣选作业优化可以有效地提高拣货效率。
在订单分批方面,Chen 等[3]提出了一种基于关联规则挖掘和整数规划的订单分批方法,将关联性较大的订单归为一批。建立了订单分批和排序数学模型,可变邻域搜索、种子算法等求解方法多被用于求解该模型,实验结果表明该方法可得出最佳解决方案,减少总拣选时间[4-6]。邵泽熠等[7]采用密度和最小距离作为参数确定初始聚类中心,再用改进遗传K-均值算法确定K值,以求得更优的分批结果。在路径优化方面,改进蚁群算法、改进遗传算法和混合蚁群算法等多用于对大型仓储拣选系统进行路径优化[8-11]。刘建胜等[12]、王永波等[13]采用蚁群算法、混合蚁群算法求解最短拣货路径,结果表明,该算法适合于大型仓储拣货路径优化。李栋栋[14]以最小化拣货车行走路程为目标建立模型,采用贪心遗传算法求解最短拣货路径。
也有学者将订单分批和拣货路径结合起来进行分步优化,即通过不同订单分批算法得到最优的分批结果,然后对分批的最优结果进行路径优化。Chen 等[15]、Ardjmand 等[16]采用智能算法针对订单分批和批次排序求解最优解,再求出最短拣货路径。Kulak等[17]以总拣选距离最短为目标,通过聚类算法得到分批结果,再用禁忌搜索算法求解最佳拣选路径。马飞[18]以订单相似度最大为目标对订单进行分批,然后以拣选路径最短为目标建立模型,设计混合粒子群算法求解最优路径。王占磊[19]以总的拣选距离最短为目标函数建立模型,先求解出文中设计的订单分批结果,再进行路径优化。刘云峰等[20]以总路径最短为目标建立数学模型,对比不同订单分批策略和路径策略组合下总行走距离,得出距离最小的方案。
显然,这种分阶段的优化思路难以得到所有订单总的拣货距离或拣货时间的全局最优,因此,订单分批和拣货路径联合优化具有重要的研究意义。联合优化的模型之间相互关联,需要考虑两者之间相互优化、不断变动的要求。目前建立订单分批和拣货路径联合优化模型的研究较少。
在现有的研究中,Cheng 等[21]建立了以拣选距离最短为总目标的数学模型,采用粒子群与蚁群算法的混合方法求解订单分批与拣选路径联合优化问题。但该模型中未考虑拣取货物的数量、体积和时间,研究区域限于小型单区型仓库,并且订单初始的分批大小随机,文中设计的方法未与传统拣选方法进行对比分析,无法验证文中方法的有效性。
在算法方面,受刘云飞等[22]采用双层遗传算法求解混合整数规划模型,郑永前等[23]设计双层嵌套式混合遗传算法求解多级供应链中混合车间生产、采购和产品运送的决策问题的启发,本文提出了一种基于嵌套遗传算法的订单分批和路径优化的联合拣货策略。本文的主要工作如下:
1)以总拣货时间最小为总目标建立订单分批和拣货路径的联合优化模型,考虑了拣选货物数量对拣选时间的影响,拣选货物的体积对分批的影响。
2)在聚类算法得出初始分批种群的前提下,设计嵌套遗传算法求解联合优化问题,实现订单分批和路径优化的整体最优。
3)将联合优化与现有的按单拣选方法、分批分步拣选方法进行对比,并分别在10、20、50 张不同订单规模条件下验证本文所设计拣选方法的有效性,为研究订单分批和路径联合优化提供了新的思路。
1 问题描述及模型建立
1.1 问题描述
双重优化问题难以获得最优解,容易陷入局部最优,具有双重复杂性。已知条件为一个周期内多张订单的订单分批和拣货路径联合优化问题,属于NP(Non-deterministic Polynomial)难问题,即有N个订单R({r=1,2,…,N})需要拣取,每个订单中包含若干品项,每个品项i的体积为vi,订单r中包含的品项集合为Xr={xr1,xr2,…,xrn}。需求解的结果是对N个订单进行分批拣取,每批订单的拣取在一条线路上一次完成,使所有订单的总拣货时间最少。本文考虑每张订单中需要拣取的品项的数量不同,则所需的拣选时间不同,总拣货时间包括所有订单拣选的路径行走的时间和拣取品项所需的时间,建立了以总拣货时间最小为目标函数的订单分批和路径优化联合模型。
1.2 订单分批与路径联合优化模型建立
1.2.1 条件假设及参数定义
假设条件如下:
1)采用摘果式,订单分批拣取货物,其中空闲等待时间忽略不计。
2)拣货区分布主要为:货架层数为1,每个储位的大小相同,每个储位只存储一种库存量单位(Stock Keeping Unit,SKU),同时每个货位最多只能存放一种SKU。
3)拣货过程中不存在缺货现象,即补货时间忽略不计。
4)订单的各品项及其存储位置是已知的。
5)订单不允许进行分割,保证一个订单一次拣完。
6)分批后的每批订单要在一条路径上完成拣货。
模型相应的参数和变量定义如下:R为订单集({r=1,2,…,N});H为分批集({h=1,2,…,M});M为订单分批的个数;N为订单的个数;i,j为订单中的拣货位({i=1,2,…,n;j=1,2,…,n});n为拣货位(品项)的个数;vi为拣货位i的品项的体积;dij为拣货位i,j之间的距离;v为拣货人员平均行走速度;Q为拣货车的容量;Xri为第r张订单的第i个拣货位的品项的数量;xr为订单r的品项集合;Gh为第h批订单品项的集合;Ghi为第h批订单的品项集合中是否包含拣货位i;yrh为订单r被分到第h批中;Sh为第h批订单拣货路径的距离;T为订单分批后总的拣货时间;tu为拣取每单位品项所需的时间。
1.2.2 目标函数建立
联合优化模型总目标是,每批订单的拣取在一条线路上一次完成,使所有订单的总拣货时间最少,建立联合优化模型目标函数(1)表示订单分批后,所有批次订单总的拣货时间;目标函数(2)表示将所有订单分批后,第h批订单中所有品项的集合;目标函数(3)表示第h批订单拣货的距离。
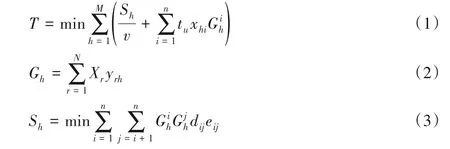
1.2.3 约束条件建立
拣货过程中订单不允许分割,一张订单只能分配到一个批次中建立约束条件(4);式(5)表示每张拣货单的路径只能走一次,同时应该对拣货车的拣货能力做出约束;式(6)表示每批订单中所包含的品项数总体积不能超过拣货车的容量。
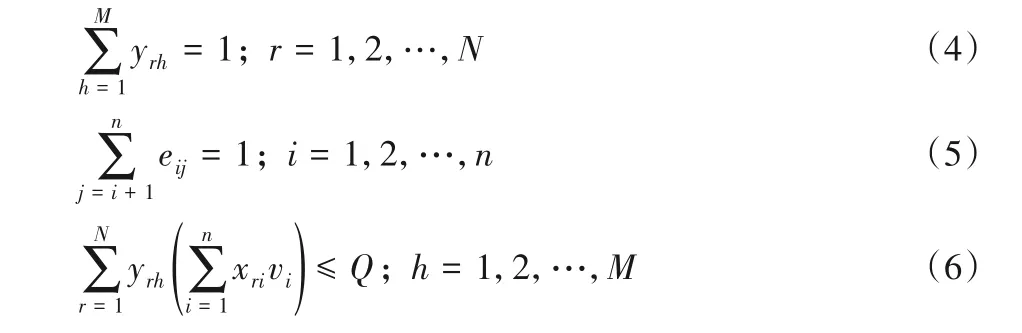
1.2.4 决策变量建立
联合优化模型关键决策变量在于判断订单分配批次、拣货位i,j顺序,均采用0-1 变量建立联合优化模型性决策变量,式(7)表示订单r是否被分配到h批拣货单中;式(8)表示拣货位i,j是否为拣货路径中相邻的点;式(9)表示第h批订单的品项集合中是否包含拣货位i;式(10)表示第h批订单的品项集合中是否包含拣货位j。

2 嵌套遗传算法设计
2.1 嵌套遗传算法设计思路
订单分批和路径优化两者相互关联,一变俱变,每一个符合约束条件的分批结果对应一个总拣货时间,分批结果变化,拣货总时间也随之改变,直到找出一种分批结果使得总拣货时间最短。因此,一般的遗传算法难以求解联合优化模型,基于联合优化问题的复杂性设计一种嵌套式遗传算法,总体框架如图1所示。
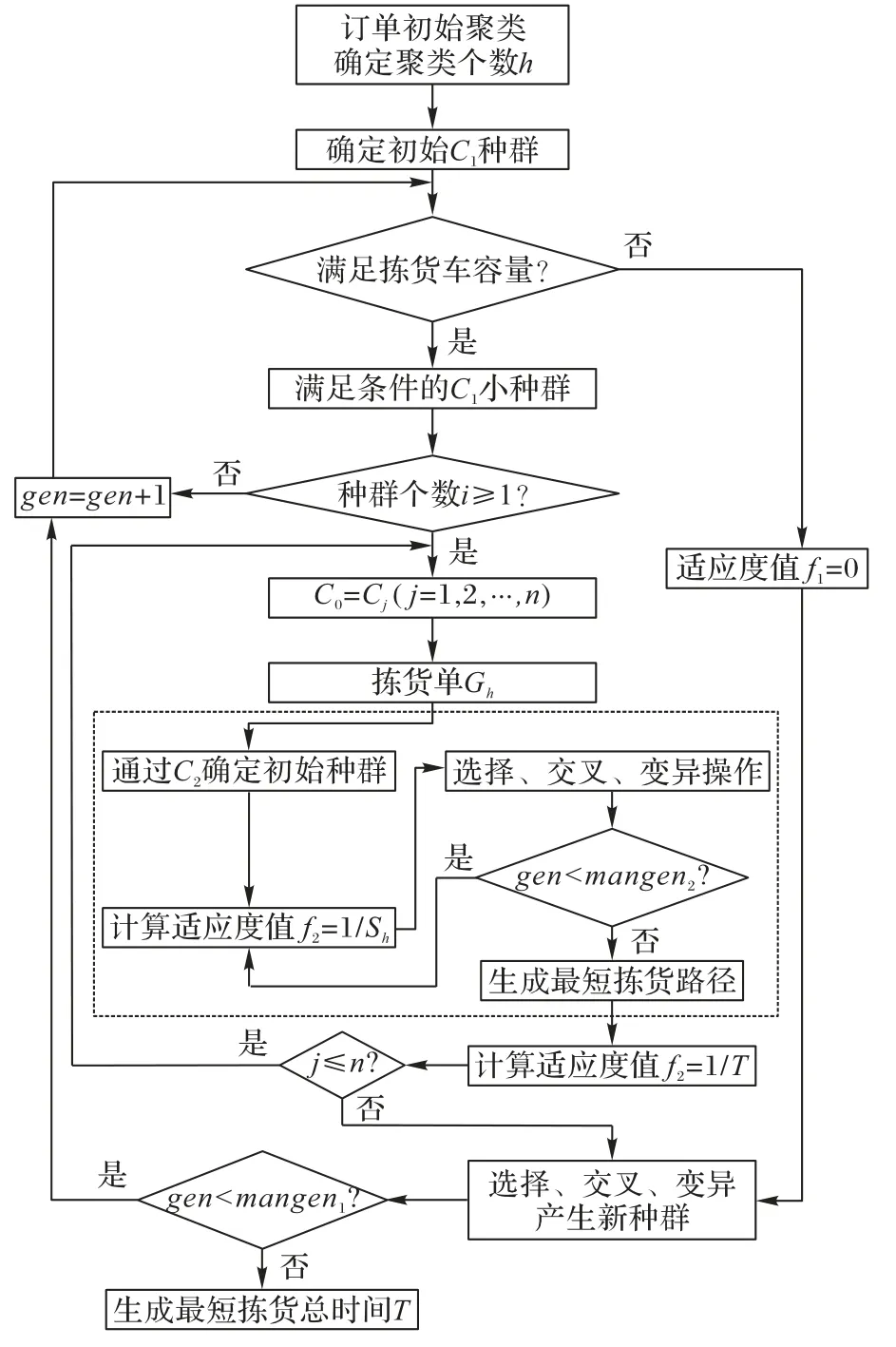
图1 嵌套遗传算法流程Fig.1 Flowchart of nested genetic algorithm
首先,以巷道间相似度最大为准则的聚类算法得出初始的聚类结果和聚类个数形成初始种群,外层遗传算法根据拣货车容量限制条件计算出满足条件的分批小种群,将其作为内层遗传算法的输入,内层遗传算法根据外层遗传算法输出的分批结果计算出每张拣货单的拣货路径和距离以及总的拣货时间,即拣货路径优化。同时,内层遗传算法将目标函数值反馈到外层,目标函数在内外层遗传算法的不断反馈中达到最优。
2.2 算法具体步骤
嵌套遗传算法的具体步骤如下:
1)初始聚类。根据订单相似系数Sij的聚类算法得到订单分批结果,确定初始聚类个数h。
2)编码设计和初始种群。根据聚类结果生成外层染色体C1,建立初始种群K。
3)生成拣货单。在一代种群中,根据式(6)判断分批结果C1是否满足拣货车容量,若满足则生成分批小种群,种群规模为n,对每一分批结果Cj通过式(1)对属于同一批次h的所有订单r的品项集合Xr进行合并,生成拣货单h的集合Gh,然后确定每张拣货单需要拣取的拣货位i,从而得到需要拣取的拣货位编号集合C2,生成路径优化初始种群。
4)路径优化。通过内层遗传算法对每张拣货单进行路径优化,染色体C2表示每张拣货单的拣货路径。适应度函数为,即为拣货单h的距离Sh的倒数,表示拣货时间越短,个体的适应度越高。通过选择算子Pi、交叉算子Pc和变异算子Pm产生新种群C2,判断是否达到最大迭代次数maxgen2,若没有达到,则计算适应度值,继续循环;若达到,则终止循环,得到一个分批结果的所有拣货单的最优拣货路径和拣货距离Sh。
5)适应度值。计算一个种群中每一个分批结果的适应度值,适应度函数为,判断一个种群中所有分批个数n是否都完成内层路径优化,若没有都完成,则返回步骤3);若都完成则继续步骤6)。
6)产生新个体。通过选择算子Pi、交叉算子Pc和变异算子Pm产生新种群C1。
7)判断是否达到最大迭代次数maxgen1,若达到,则生成最优分批结果和总拣货时间T;若没达到,则返回步骤3)判断新种群的新个体C1是否满足拣货车容量,若满足继续步骤4),若不满足则适应度值f1=0,返回步骤6)。
2.3 嵌套遗传算法优化过程
2.3.1 外层订单分批优化
1)初始聚类个数的产生。
根据聚类算法得到初始的分批结果,获得初始分批的个数为h(h=1,2,…,M),该聚类算法是通过多巷道仓库中计算两个订单拥有的相同巷道数的多少作为聚类准则[24],计算订单间的距离衡量公式、衡量相似系数。
①分别计算两两订单i,j间的相似系数Sij。
②将相似系数Sij按照降序排列。
③将Sij最大的两个订单作为一批,如果有相同的Sij,则选择品项数最多的组合,判断是否满足Vi+Vj≤Q,若不满足则选择下一个Sij,将已合成一批的订单i,j看作一个新的订单,对新的订单的集合重新计算相似系数Sij,返回步骤②;若所有的Sij都不可行,则将未分批的订单单独作为一批,得到分批结果。
订单间的距离衡量公式为:
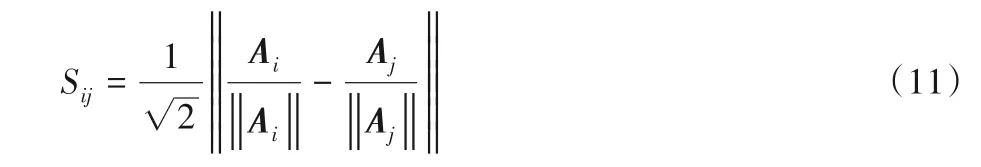
其中:Ai表示订单i中拣货位分布的通道集合向量;Sij为非中心点订单i与中心点订单j的相似系数,用来表示两个订单间的距离。订单间的相似系数结果越小,则订单间重合的通道越多,两个订单间的距离越短。作为相似系数的归一化常数,使得相似系数值域在[0,1]。
2)编码设计和初始种群。
外层染色体C1采用实数编码的方式,C1的表达式为C1=[h1,h2,…,hr],其中,基因位数对应订单的编号,基因值为订单所属的分批编号。如C1=[2,1,3,1,2,3],表示订单1 属于第2 批,订单2 属于第1 批,订单3 属于第3 批,订单4 属于第1批,…,以此类推。即形成初始种群K。
3)适应度值计算。
在一代种群中,首先根据式(6)判断一个染色体中属于同一批次的订单的体积和是否满足拣货车容量,若满足则生成小种群,根据式(1)对属于同一批次的所有订单的品项进行合并,生成拣货单,每张拣货单中包含同一批次的所有订单的品项的数量集合Gh,Gh={xh1,xh2,…,xhi,…,xhm},得到拣货单品项的数量的集合确定需要拣取的拣货位,从而得到需要拣取的拣货位编号集合C2,进入内层拣货路径优化步骤。根据内层遗传算法得出的最优拣货路径计算适应度值,适应度函数表示拣货完成的总时间T的倒数,拣货的时间越短,个体的适应度值越高,计算式为:
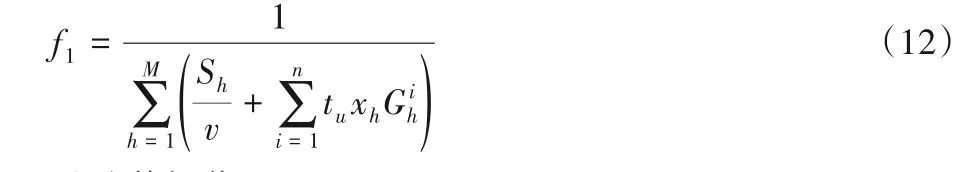
4)遗传操作。
①选择算子。采用经典的轮盘赌法,每个个体被选为父代的概率与其适应度是成正比的,适应度越高,被选中的概率越大,设Pi为第i个个体被选中的概率,则,其中Fi为第i个个体的适应度值。
②交叉算子。交叉概率为Pc,根据选择操作选择两个父代染色体和进行交叉。随机选择两个点,那么将两个点之间的位置进行交叉。例如,两个父代个体A=[2 1 3 1 2 3],B=[1 2 3 3 2 1],交叉位置数的两个点为3 和4,则子代个体为A'=[2 1 3 3 2 3],B'=[1 2 3 1 2 1]。
③变异算子。变异概率为Pm,变异操作时产生一个随机数,例如染色体编码[2,1,3,1,2,3]中将3 变成2 时,那么2 也会变成3,变异后的个体为[3,1,2,1,3,2]。
5)终止条件。
判断是否达到最大迭代次数maxgen1,若达到,则生成最优分批结果和总拣货时间T;若未达到,则判断新种群的新个体是否满足拣货车容量,若满足则重复上述过程,若不满足则适应度值f1进入遗传操作产生新种群。
2.3.2 内层订单路径优化
1)编码设计和适应度值计算。
本文中采用自然数编码,染色体C2=[i1,i2,…,in],其中元素(基因)in为[1,n](n为拣货位个数)的一个互不重复的自然数,其中基因位数对应拣货位的排序,基因值为需要拣取的拣货位编号。如C2=[0,1,2,3,4,0]表示每张拣货单的拣货路径是出入口0-拣货位1-拣货位2-拣货位3-拣货位4-出入口0,生成初始种群。
适应度函数表示拣货单总路程的倒数,拣货的路程越短,个体的适应度值越高,其计算式为:

2)遗传操作。
①选择算子。选择轮盘赌法,其扇面的角度和个体的适应度值成正比,适应度越高,被选中的概率越大。
②交叉算子。采用部分匹配交叉法,根据选择操作从父代中选择两个进行交叉,交叉概率为Pc。例如两个父代个体A=[1 2 3 4 5 6 7 8],B=[2 4 6 8 7 5 3 1],随机选择两个交叉的货位点,第一个交叉点为位置4,第二个交叉点为位置6,那么在两个点之间的位置将进行交叉,其他的位置进行复制或者用相匹配的数进行替换。第一个父代交叉的部分是4 5 6,第二个父代交叉的部分是8 7 5,则4 与8、5 与7、6 与5 相匹配,则子代个体为A'=[1 2 3 8 7 5 6 4],B'=[2 8 7 4 5 6 3 1]。
③变异算子。变异概率为Pm,变异操作时产生一个随机数,例如染色体编码[1,3,2,6,4,7,5]中将3 变成4 时,那么4也会变成3,变异后的个体为[1,4,2,6,3,7,5]。
3)终止条件。
按照以上步骤循环操作,当达到最大遗传代数maxgen2时终止算法,得到每张拣货单的最优拣货路径和拣货距离Sh。
3 实例分析
3.1 仓库模型
以双区型仓库为实例,该仓库由3 条平行的横向通道和若干条纵向通道构成,每条通道的宽度相等,每条巷道宽度也相等,纵向巷道除了第一列和最后一列的货架是单排货架,其他货架均为背靠背式货架,如图2所示。
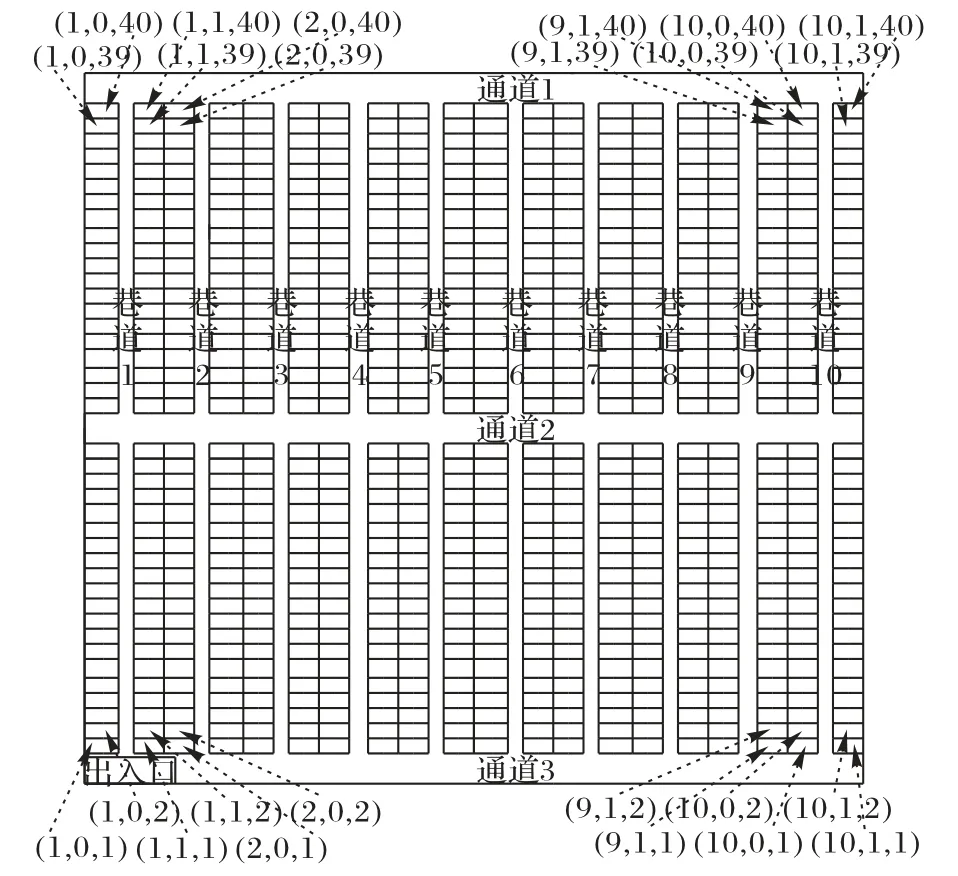
图2 双区型仓库布局Fig.2 Layout of two-zone warehouse
仓库尺寸符号说明如下:
1)a(a=1,2,…,A)为货位所在的巷道编号;
2)b为同一巷道中左右两侧的货架,左侧货架即b=0,右侧货架即b=1;
3)c(c=1,2,…,C)为同一排货架中货位的标号;
如图2 所示,设有10 条纵向通道,每个巷道的宽度为1 m,每个横向通道的宽度为2 m,两个横向通道间每一列货架的个数为20,货架的长为2 m,宽为1 m。任意两个货位i,j之间的最短距离dij取值情况如下:
1)两个货位点在同一条拣货巷道中,在中间通道的同侧:
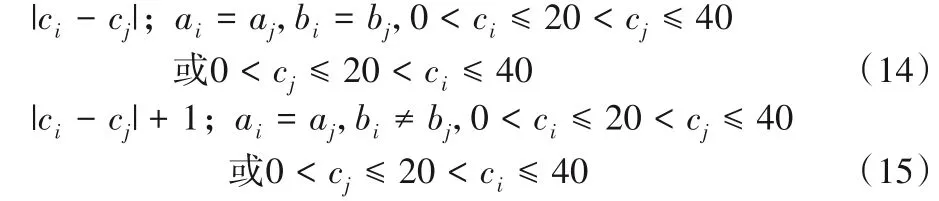
2)两个货位点在同一条拣货巷道中,分散在中间通道两侧:
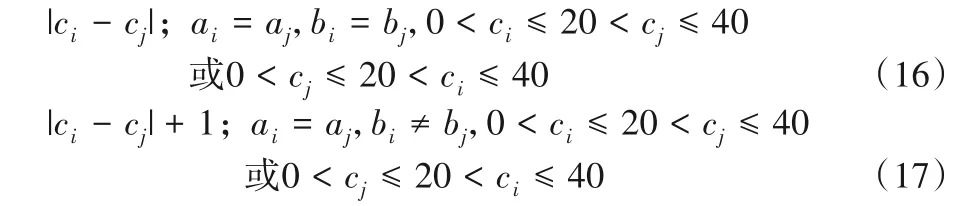
3)两个货位点在不同拣货巷道中,在中间通道的同侧:
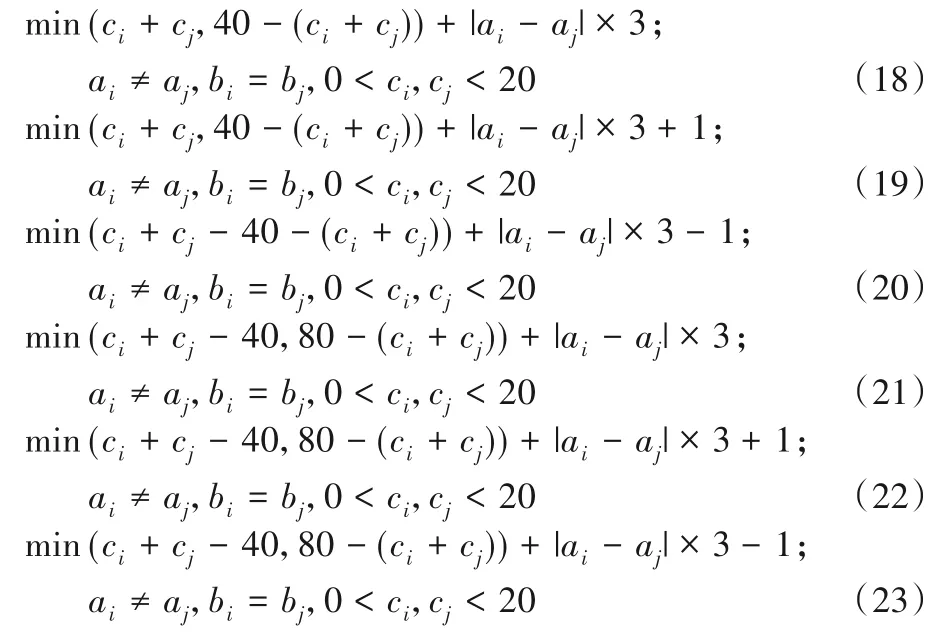
4)两个货位点在不同拣货巷道中,分散在中间通道两侧:
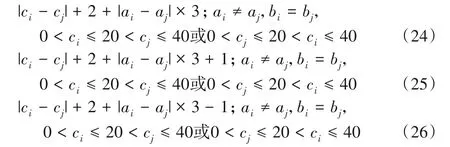
5)货位点i与出入口之间:

3.2 联合优化结果对比分析
模型的参数设置如下:拣货人员的平均行走速度为1 m/s,拣货人员拣取单个货物所需的时间为2 s,拣货车容量为80。通过查阅相关文献和大量实验可得算法的参数设置如下:外层遗传算法的初始种群为65,迭代次数为70,变异概率为Pm=0.4,交叉概率Pc=0.9;内层遗传算法的初始种群为80,迭代次数为1 000,变异概率为Pm=0.08,交叉概率Pc=0.4。实验数据来源于某电商的订单数据,每张订单数据中包含了客户购买的不同货物信息,包括货物序号、储位坐标、货物数量和体积。首先以10 张订单的拣选为例进行分析,由表1 可得,10张订单联合优化共分为3批,第一批结果是订单1、4、8,需要拣取品项数量为15,最优路径拣货顺序为:36-26-64-125-450-695-652-579-333-251-297-392-355-356-114,总拣货时间为274 s,总拣货距离为210 m,路径示意图见图3,拣货路径见图4。其中,横纵坐标为仓库模型的储位坐标,黑色标记为货物序号。
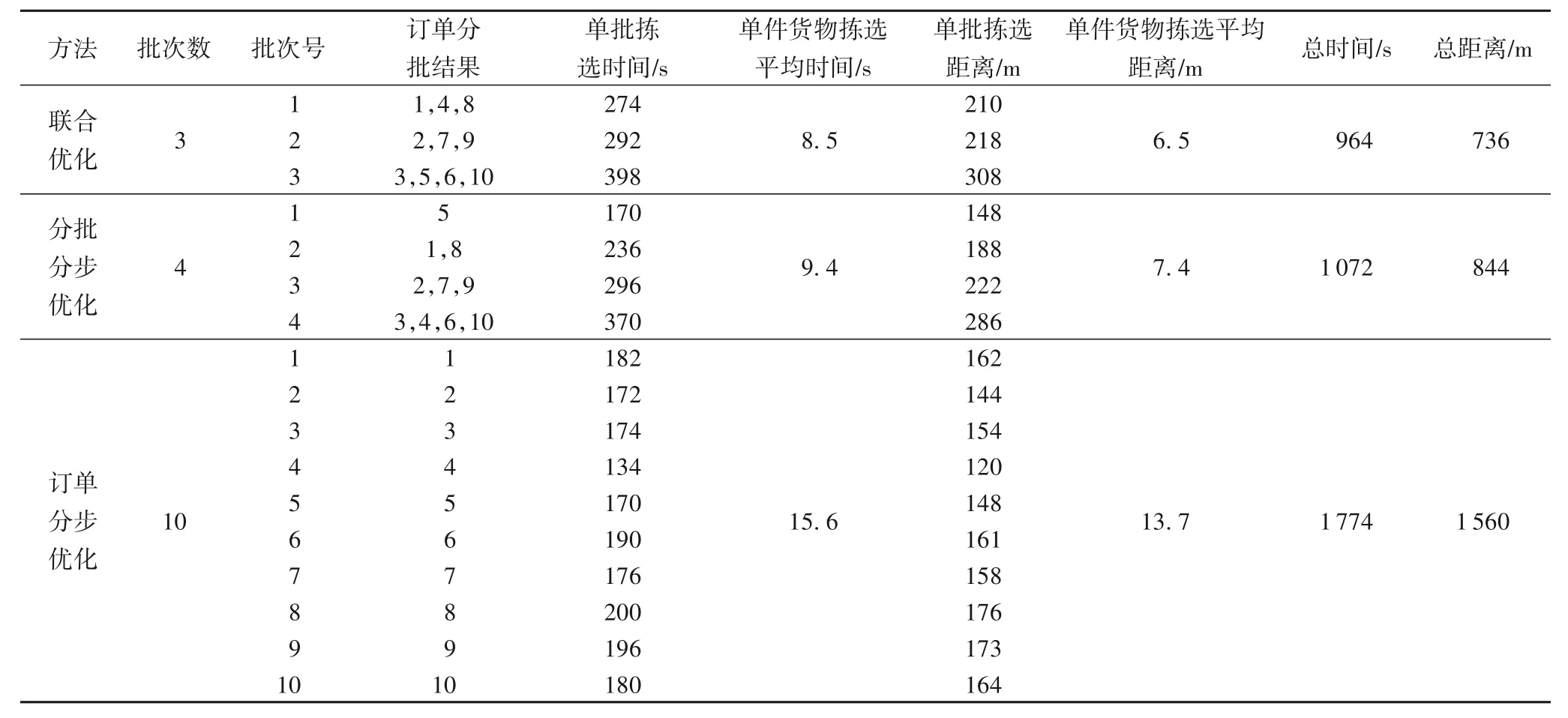
表1 联合优化计算结果Tab.1 Joint optimization results
第二批结果是订单2、7、9,需要拣取品项数量为16,最优路径拣货顺序为:109-24-61-140-254-249-365-444-450-410-579-657-774-788-708-275,总拣货时间为292 s,总拣货距离为218 m,路径示意图见图5,拣货路径见图6。
第三批结果是订单3、5、6、10,需要拣取品项数量为18,最优路径拣货顺序为36-52-105-115-186-129-87-251-361-651-732-579-548-709-635-472-356-240,总拣货时间为398 s,总拣货距离为308 m,路径示意图见图7,拣货路径见图8。
表1对比了联合优化与分步优化的计算结果,由表1可以看出,联合优化的结果最优,分批分步优化次之,按订单分步优化结果最差。其中,分批分步优化指的是对同一周期的订单进行订单分批后求解其最优路径及拣货时间,按订单分布优化指的是不对订单进行分批处理,直接求解每张订单的最短路径及拣货时间;与按订单分步优化相比,联合优化的拣货路径减少了824 m,相当于减少了52.8%,时间减少了810 s,相当于减少了45.6%;与按分批分步优化相比,联合优化的拣货路径减少了108 m,相当于减少了6.9%,时间减少了108 s,相当于减少了6%。因此,联合优化的结果更优,对于拣货效率有明显的提高,进一步减少了拣货时间。

图3 第一批订单拣货路径示意图Fig.3 Schematic diagram of picking path of first batch of orders
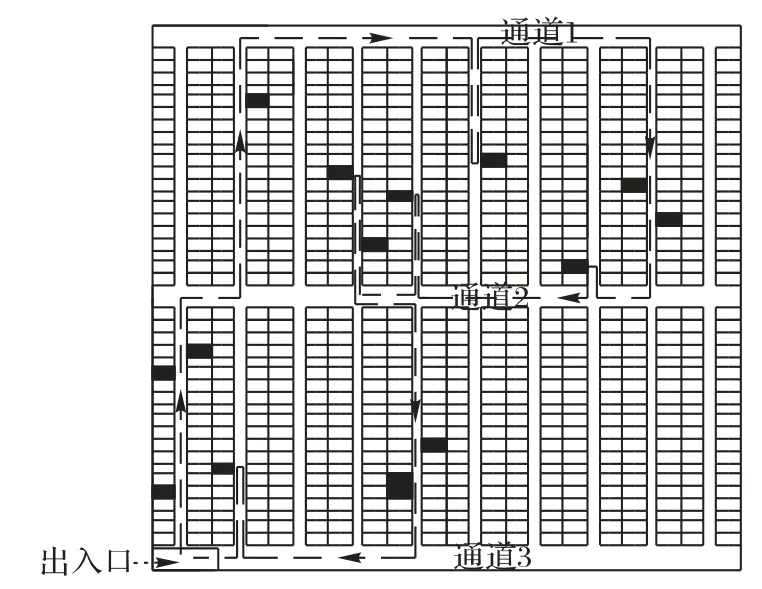
图4 第一批订单拣货路径Fig.4 Picking path of first batch of orders
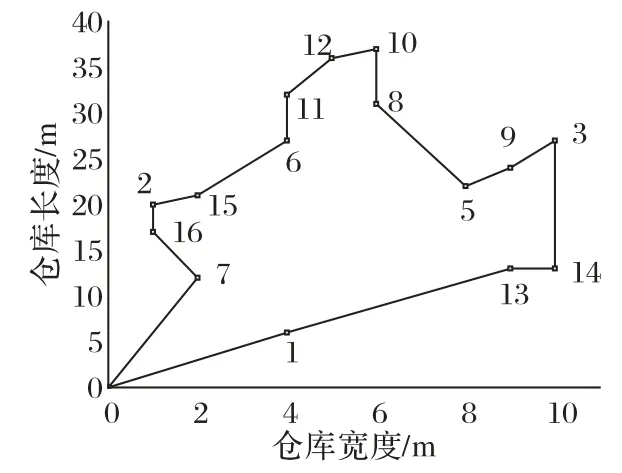
图5 第二批订单拣货路径示意图Fig.5 Schematic diagram of picking path of second batch of orders
以上为10 张订单的分析结果,为验证该算法对不同规模订单均具有较好的性能,再分别以20 张、50 张订单为算例进行验证,表2为求解10、20、50张订单分别采用联合优化、分批分步优化和按订单分步优化的结果对比。可以看出,对于不同订单量,联合优化的结果相较于分步优化结果更优,并且随着订单量的增加,节约的时间和距离越多,拣选时间减少百分比从6%增加到7.2%。因此,随着订单量的增加,拣货效率提高越明显。
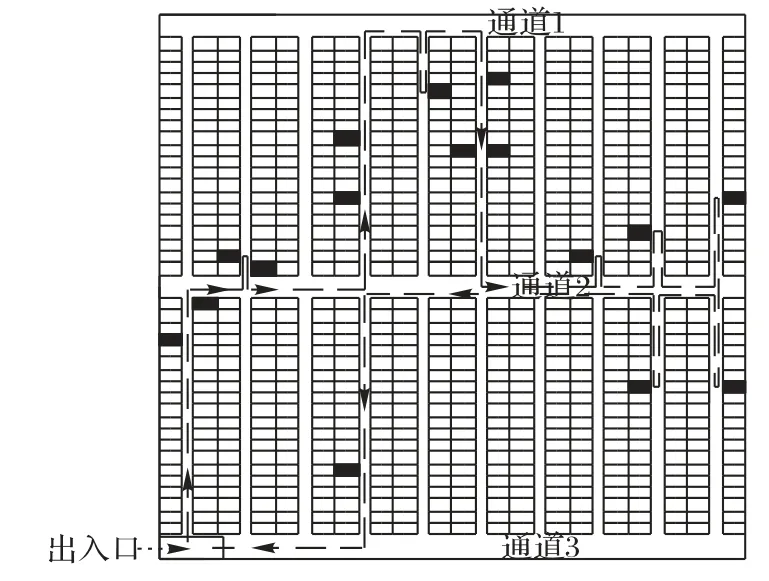
图6 第二批订单拣货路径Fig.6 Picking path of second batch of orders
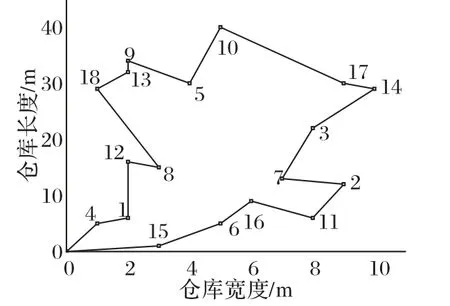
图7 第三批订单拣货路径示意图Fig.7 Schematic diagram of picking path of third batch of orders

图8 第三批订单拣货路径Fig.8 Picking path of third batch of orders
3.3 嵌套遗传算法的可靠性分析
在算法的收敛性方面,图9 为嵌套遗传算法运算过程中订单拣选总时间随迭代次数增加而逐渐收敛的过程。图9 结果表明,随着迭代次数的增加,拣选总时间呈递减趋势。当迭代次数大于40 后,拣选总时间趋于某一稳定值,表明该算法具有很好的收敛性。

表2 不同订单量算例的对比结果Tab.2 Comparison results of examples with different orders
稳定性方面,由于嵌套遗传算法的内外两层遗传算法将会导致最优结果在趋于稳定时出现一定的波动。文献[22]运用嵌套遗传算法进行10 次运算,收敛后的目标值波动在±10%之内。为了验证本文设计的嵌套遗传算法的可靠性,进行了15 次运算,最短拣货总时间的平均值为1 064 s,其波动情况如图10 所示。图10 结果表明,在15 次运算中,目标值的波动在±5%之间,可见本文设计的嵌套遗传算法具有很好的可靠性。
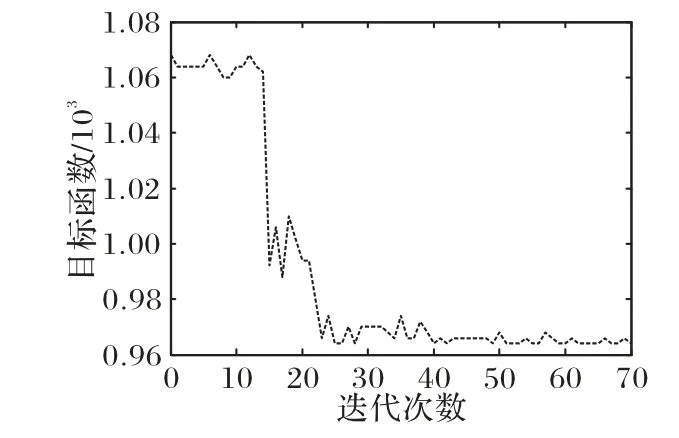
图9 嵌套遗传算法迭代图Fig.9 Nested genetic algorithm iteration graph
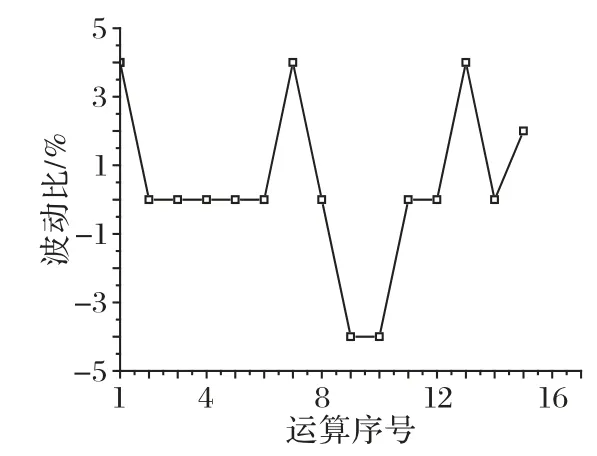
图10 目标函数波动比Fig.10 Fluctuation ratio of objective function
算法时效性方面,在Intel CoreTM i56300-HQ CPU,Matlab R2014a 环境下,针对10 张、20 张、50 张订单分别采用分批分布优化、按订单分布优化及基于嵌套遗传算法的联合优化的CPU 运行时间如表3 所示。表3 结果表明,按订单分布优化CPU 运行时间最长,时效性较差,而嵌套遗传算法解决订单分批和拣货路径联合优化具有较好的时效性。
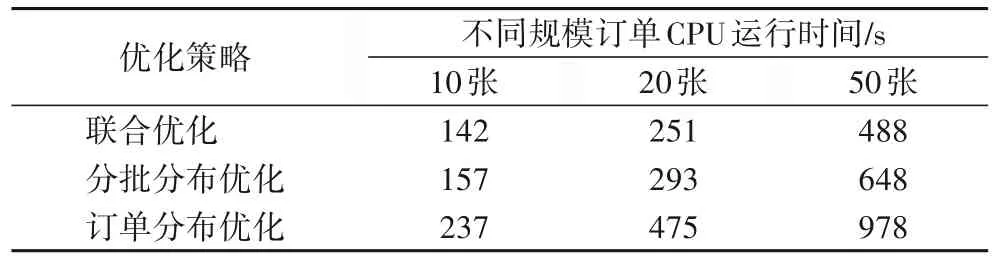
表3 不同优化策略下CPU运行时间Tab.3 CPU running time under different optimization strategies
4 结语
本文设计了以拣货时间最短为目标函数的订单分批和拣货路径联合优化模型,采用嵌套遗传算法对模型进行求解。仿真结果表明:相较于分步优化策略,采用本文设计的嵌套遗传算法求解联合优化模型稳定可靠,且得到的结果更理想,拣货时间和拣货距离更优,可以进一步减少拣货时间,提高了整个物流配送中心的拣货效率。本文中所提的模型和算法及其仿真结论可为配送中心拣货系统优化提供决策参考。
