基于多模态特征融合的轻量级人脸活体检测方法
2020-12-31皮家甜杨杰之杨琳希彭明杰赵立军唐万梅吴至友
皮家甜 ,杨杰之,杨琳希,彭明杰,邓 雄,赵立军,唐万梅,吴至友
(1.重庆师范大学计算机与信息科学学院,重庆 401331;2.重庆市数字农业服务工程技术研究中心(重庆师范大学),重庆 401331;3.智慧金融与大数据分析重庆市重点实验室(重庆师范大学),重庆 401331;4.重庆师范大学数学科学学院,重庆 401331)
(∗通信作者电子邮箱1093895431@qq.com)
0 引言
人脸识别技术现今已被广泛使用,人脸活体检测是提高人脸识别安全性的重要方法。人脸活体检测是指系统会根据摄像头捕捉到的人脸去辨别其是否为活体状态,通常可视为二分类问题。传统方法常在提取人脸图像中的以局部二值模式(Local Binary Pattern,LBP)呈现的纹理特征以及色调、饱和度和明度(Hue,Saturation,Value;HSV)颜色空间等手工设计特征后,利用机器学习等方法去分辨真实人脸和假人脸。文献[1]提取人脸图像灰度化后的纹理特征进行真假脸的判断,文献[2]利用HSV 与LBP 特征的融合来进行活体检测。虽然这类方法易实现,具有一定屏蔽光照的影响且计算量少,能从单张图片中预测结果,但对于一些低分辨率特征,准确率和鲁棒性均较低。这要求输入图像的质量足够高才能给出精确的判断。
近年来,深度学习占据了活体检测的主导地位,通过搭建多层卷积神经网络筛选高层语义的特征来辨别目标是否为活体。文献[3]利用十三层网络从RGB 图像中抽取特征进行训练以判别活体真伪,但是该方法采用数据集的总量少、攻击形式过于单一,导致网络泛化能力弱。文献[4]提出了运用多模态融合特征网络FaceBagNet,通过训练CASIA-SURF 数据集,在TPR@FPR=10E-4 指标上达到了99%的效果,但网络模型参数巨大。文献[5]分别采用18层、34层、50层的残差网络做人脸活体检测,虽然在准确率上都有着良好的效果,但是该模型在实际应用中并不具备实时性。
深度学习模型普遍有着庞大的计算量,意味着需要更优良的设备,如图形处理器(Graphics Processing Unit,GPU)、张量处理器(Tensor Processing Unit,TPU)等。随着智能移动端的发展,将深度学习模型嵌入至移动端设备成为了现如今的业界的需求,国内外研究者们提出了一系列降低卷积神经网络计算量的方法,如:Howard 等研究者提出MobileNet[6]和MobileNetV2[7]以及MobileNetV3[8]用于移动端的轻量级卷积神经网络。Iandola 等[9]研究者提出SqueezeNet,利用FireModule 模块降低卷积神经网络的参数量;但是SqueezeNet模型过于轻量,这种加宽网络的方法并不能够为人脸活体检测带来优良的效果。对于轻量级活体检测的研究,Zhang等[10]研究者提出了轻量级网络FeatherNet,用人脸的深度图作为训练数据,同时采取融合与级联的方式来提高准确率;虽然FeatherNet 是轻量级的网络,但是单个信息具有一定的局限性,虽然采用融合与级联的方式来提高准确率,但是算法的时间复杂度又增长了不少,导致识别活体的时间变得较长。
为了减少网络的计算量,同时保证网络精度,本文提出了一种基于MobileNetV3 的活体检测模型,并优化了网络结构,利用人脸的深度特征与颜色纹理特征的互补性,将人脸的深度信息与RGB 图同时作为网络输入,并在网络训练中进行特征融合,将网络的全局平均池化(Global Average Pooling,GAP)用Streaming Module 代替,在网络的底层采用1×1 的卷积替代全连接层,以此降低参数量。在确保活体检测速度提升的同时不降低活体检测的精度,实验结果表明本文方法具有良好的检测效果。
1 人脸活体检测模型
基于单帧人脸的活体检测一直是静默活体检测中最主要的方式,特征的丰富程度会决定着网络的鲁棒性。随着卷积神经网络的发展,融合的方法也在网络中更加容易实现,融合方法有决策层的决策级融合,还有卷积层的特征级融合,决策融合的优势在于当Softmax 做决策分类时,将多个决策结果进行权衡得到最终输出,其缺点在于若是多个结果差别巨大,则准确结果不容易获得。根据文献[11]指出特征级融合可分为:“高层融合”“中层融合”和“底层融合”。“高层融合”即特征图于网络的高层进行融合,会提高网络的泛化性,但是会带来信息丢失,从而导影响判别的精度。“底层融合”即融合点位于输入层,优点在于保留了原始的数据,缺点在于原始数据中同时也包含了冗余数据,特征过早的融合也会带来庞大的计算量,不利于网络训练。“中层融合”即融合点位于网络中层,既保留了网络的原始数据,同时也能够提升网络的泛化能力。基于上述分析,本文采用“中层融合”的方式作为网络的主要框架,本文活体检测模型如图1所示。
1.1 MoibileNetV3网络
MoibileNetV3 网络结构综合了以下三种网络思想:MobileNetV1的深度可分离卷积,MobileNetV2的具有线性瓶颈的逆残差结构,以及MnasNet 的基于SE(Squeeze and Excitation)[12]结构的轻量级注意力机制。MobileNetV3 是自动机器学习算法NAS(Network Architecture Search)[13]以及NetAdapt算法[14]生成。激活函数采用的是HS(H-Swish),分别替换了修正线性单元(Rectified Linear Unit,ReLU)(简称RE)以及Sigmoid,使用Swish 函数能够增加网络的精度但是也会带来庞大的计算量,因此H-Swish 激活函数成为MobileNetV3的另一个核心思想。H-Swish激活函数的计算式如式(1)所示。
1.2 网络结构优化
1.2.1 瓶颈层优化
瓶颈层最早由He 等[15]提出,Bottleneck(Bneck)不同于传统的3×3 卷积层以及池化层,瓶颈层由1×1、3×3 和1×1卷积构成:第一个1×1的卷积是为了匹配通道数;第二个3×3 的卷积通过降低特征图通道数来达到在通道低维空间中进一步学习;最后又通过1×1的卷积还原通道数。这样做有利于网络更高效的传播,同时还会降低网络的计算量。MobileNetV3 在这样的结构基础上加以改进:首先,通过设置一个扩张因子,将输入的网络通道乘以扩张因子得到了第一个1×1卷积核的个数;其次,将中间3×3的卷积换成了5×5的深度可分离卷积;接下来的1×1卷积用线性激活函数替代原来的ReLU 激活函数;最后,整个瓶颈层加入了残差连接防止梯度爆炸导致精度丢失。由于MobileNetV3 在瓶颈层没有池化的操作,因此本文在MobileNetV3上在旁路连接中加上了1×1 的卷积和一个平均池化层的操作对特征进行细粒度的提取,这样能够保证在特征尺寸下降的过程中进一步地筛选特征,实验结果表明,该方法能够提高准确率,降低损失。在MobileNetV3的注意力机制中,本文通过降低注意力机制模块中的全连接层的神经元个数来降低模型的参数量,SE 模块通过学习的方式来自动获取每个特征通道的重要程度,然后依照特征的重要程度去提升有用的特征并抑制对当前任务用处不大的特征。改进前后的瓶颈层如图2所示。

图2 瓶颈层的改进Fig.2 Improvement of bottleneck layer
1.2.2 多模态特征融合
训练数据集D可以描述为:
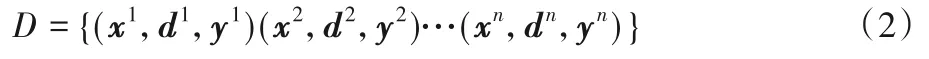
其中:xi、di分别为预处理后放入CNN 的RGB 图以及深度图;yi(yi∈RM)为图像的标签,由one-hot编码组成,M为样本的标签数量;gD(di,θD)为深度输入图经过第二个瓶颈层前向传播的结果,为待更新的参数。
训练单种特征图像表达式如下:

其中:WD为softmax层的权重;L为交叉熵损失函数。L表达式如下:
经实验后发现仅凭深度单输入网络的特征是不够的,所以网络需要多模态的特征。
在活体识别任务中本文采用了两种图像特征:第一种是RGB图,是由RealSense SR300的RGB摄像头采集的三通道图像;第二种是由RealSense SR300 的深度摄像头采集的单通道图像。RGB 图能够描述物体的轮廓、颜色以及部分纹理的信息,而深度图能够描述物体的形状、尺度以及空间几何的信息,因此两种特征的图像具备互补性。两种图像采用特征融合的方式,对于CQNU-LN 以及CASIA-SURF 数据集,输入图像是112×112×3的RGB 图像和112×112×1的深度图像。由于本文采用的“中层融合”,所以特征图在经过2个瓶颈层之后进行融合,从而令gI(di,θI)为RGB图经过第二个瓶颈层前向传播的结果,di为经过预处理后的人脸RGB图像,表达式如下:

其中θ为特征融合后的参数,所以RGB-D 多模态特征融合后的表达式如下:
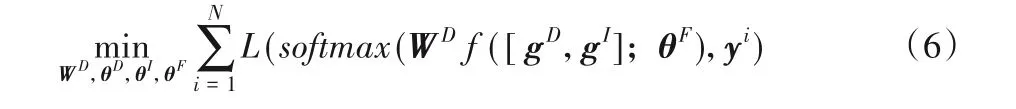
1.2.3 Streming Module
全局平均池化(GAP)被许多目标检测网络采用,比如ResNet[15]、DenseNet[16]、MobileNetV2、ShuffleNet[17-18]系列,它能够降低特征图维度和防止过拟合,并且能够有效地抑制计算量,但是在人脸相关的任务中,全局平均池化对准确性却容易造成负面影响,人脸图像不同于一般的目标检测图像,中心区域应该比边缘区域享有更高的权重,全局平均池化是无法做区域权重区分的。能够做到区域权重区分的其中一个方案是用全连接层来代替全局平均池化,为了网络的预测功能达到实时性,全连接层的使用会导致参数大量的增加并且也会让网络增加过拟合的风险,所以网络底部的全连接层不利于用作人脸活体检测模型。
Chen 等[19]设计的Streaming Module 保证了网络轻量化并且对区域权重进行区分,本文采用Streaming Module 来代替传统的全局平均池化层或者全连接层。Streaming Module 由一个全局深度可分离卷积(Global Depth Convolution,GDConv)和1×1 的卷积层组成,经过GDConv 网络后特征图会变为一个1×1 的特征图,最后通过1×1 卷积进行线性激活作为特征输出层。GDConv的计算过程为:

其中:F为输入的特征图,它的尺寸是W×H×M,W、H和M分别为特征图的宽度、高度及通道数;K为尺寸为W×H×M的GDConv;Gm为经过GDConv再通过Flatten后的大小为1×1的特征图。最终分类层上令Gm通过2 个1×1 的卷积并用Softmax激活,从而达到真假分类的目的。Streaming Module 如图3 所示,改进后模型的结构如表1 所示。Streaming Module的计算量为W×H×M×1×1×2。
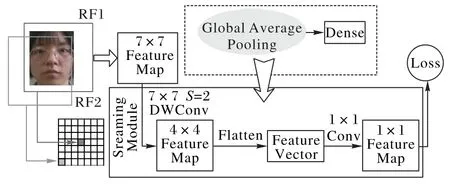
图3 Streaming Module结构Fig.3 Structure of Streaming Module

表1 改进后模型的结构Tab.1 Improved model structure
2 相关数据集
2.1 CASIA-SURF数据集
针对大多数公开的活体检测数据集只包含了RGB 人脸图像的情况,若是训练只含RGB 的图像模型在测试时精度不高,而Zhang 等[20]所制作的人脸活体检测数据库CASIA-SURF收集了1 000 张人脸,由Intel RealSense SR300 采集的21 000个视频中提取,每个样本均有RGB、深度以及红外(Infrared Radiation,IR)模态,在这些视频中共裁剪出492 522 张人脸RGB、深度、红外图像。提取到的人脸图像通过人脸重建网络(Position map Regression Network,PRNet)以及贴上掩码的操作进行预处理,让人脸以外的部分全为黑色。整个数据集分为训练集、验证集以及测试集。CASIA-SURF 主要有如下6种欺诈手段:
1)展平的打印的照片其中去除眼睛区域,使真人的眼睛裸露出来。
2)弯曲的打印的照片其中去除眼睛区域,使真人的眼睛裸露出来。
3)展平的打印的照片其中去除鼻子区域,使真人的鼻子裸露出来。
4)弯曲的打印的照片其中去除鼻子区域,使真人的鼻子裸露出来。
5)展平的打印的照片其中去除嘴巴区域,使真人的嘴巴裸露出来。
6)弯曲的打印的照片其中去除嘴巴区域,使真人的嘴巴裸露出来。
本文选取了CASIA-SURF 自主划分的训练集作为主要的数据集,在实验中将IR 图剔除,首先在训练集中按照固定的随机数种子随机选取25%同顺序的RGB 和Depth数据作为验证与测试的集合;其次在验证与测试的集合中按同样的方式随机选取60%的测试集,剩下40%作为验证集,所以训练集、测试集以及验证集所占比例为0.75∶0.15∶0.1,并且验证集在训练过程中做交叉验证,实时观测模型有无过拟合。实验中取每个epoch 在验证集上的准确率作为模型是否过拟合的观测指标。
2.2 CQNU-LN数据集
虽然CASIA-SURF 数据集样本足够丰富,但是仅局限于打印的人脸,实际应用中欺骗的手段远不止这些,电子屏的欺骗是现如今最常见的欺骗攻击手段,因此本文在CASIASURF的基础上,采集了全新的数据集CQNU-LN。
CQNU-LN 数据集由Intel Realsense SR300 采集RGB 以及深度视频,由提供数据的志愿者面对镜头做上、下、左、右,以及顺时针和逆时针的头部活动,摄像头有效采集人脸的范围为0.2 m 至1 m,超出范围则视为无效数据。视频通过RealSense SDK 操作将分辨率为640×480的RGB 视频以及深度视频对齐。
提取人脸的方法采用SSD(Single Shot MultiBox Detector)检测算法[21],在RGB 视频中截取人脸将人脸面部作为感兴趣区域(Region Of Interests,ROI),记录RGB 人脸的坐标同时在深度视频中根据坐标提取深度视频人脸。
CQNU-LN 包含了12 个样本,每个样本有4 个视频。基于CASIA-SURF 对打印人脸的采集,本文在打印攻击手段中添加了6 种方式,同时将电子屏的攻击手段也作为假集的一部分,所以CQNU-LN有如下攻击手段:
1)展平的打印的照片其中去除眼睛区域,使真人的眼睛裸露出来。
2)弯曲的打印的照片其中去除眼睛区域,使真人的眼睛裸露出来。
3)展平的打印的照片其中去除鼻子区域,使真人的鼻子裸露出来。
4)弯曲的打印的照片其中去除鼻子区域,使真人的鼻子裸露出来。
5)展平的打印的照片其中去除嘴巴区域,使真人的嘴巴裸露出来。
6)弯曲的打印的照片其中去除嘴巴区域,使真人的嘴巴裸露出来。
7)展平的打印的照片其中去除眼睛、鼻子区域,使真人的眼睛、鼻子裸露出来。
8)弯曲的打印的照片其中去除眼睛、鼻子区域,使真人的眼睛、鼻子裸露出来。
9)展平的打印的照片其中去除眼睛、嘴巴区域,使真人的眼睛、嘴巴裸露出来。
10)弯曲的打印的照片其中去除眼睛、嘴巴区域,使真人的眼睛、嘴巴裸露出来。
11)展平的打印的照片其中去除鼻子、嘴巴区域,使真人的鼻子、嘴巴裸露出来。
12)弯曲的打印的照片其中去除鼻子、嘴巴区域,使真人的眼睛、嘴巴裸露出来。
13)展平的打印的照片其中去除眼睛、鼻子、嘴巴区域,使真人的眼睛、鼻子、嘴巴裸露出来。
14)弯曲的打印的照片其中去除眼睛、鼻子、嘴巴区域,使真人的眼睛、鼻子、嘴巴裸露出来。
15)将录制的真实人脸视频保存在ipad、iphone 以及拥有2K高分辨率显示器的计算机上,作为攻击手段。
实验中共有48 498 张RGB 与Depth 人脸图像,采用与2.1 节相同的方式对数据集进行划分,其中10%作为验证集,15% 作为测试集。在对比实验中,本文采用多模态ResNet18[15]、VGG-6(轻量级)、FeatherNetA[10]、FeatherNetB[10]、ShuffleNetV1[18]、ShuffleNetV2[17]以及MobileNetV3 这7 个不同的卷积神经网络与本文方法进行对比,其中ResNet18 采用文献[20]所提的人脸活体检测方式,将文中所提的ResNet18 在Keras 框架中复现。本文将轻量级人脸活体检测网络FeatherNetA[10]和FeatherNetB[10]改为多模态特征融合的形式进行对比实验。各模型在CASIA-SURF 以及CQNU-LN 数据集上交叉验证中以验证集在每轮训练中的准确率作为指标进行采集,如图4 所示。本文方法在模型训练过程中相较其他方法,虽然准确率相差不大但是在训练中呈现的趋势更加稳定。实验结果如表2~3 所示,本文方法在CQNU-LN 以及CASIA-SURF数据集上有着更高的准确率。
表2 CASIA-SURF数据集验证结果对比Tab.2 Comparison of verification results on CASIA-SURF dataset
2.3 CQNU-3Dmask数据集
由于模型在3D的攻击手段中不具备泛化能力,所以采集了一批由医学脑部CT 图像所建模的3D 头模、头套以及面具,针对光照对于模型影响,在采集CQNU-3Dmask 时,纳入三种光线条件,即:普通光照,亮光照以及暗光照情况,如图5 所示。表4为本文实验所用到数据集的相关统计。
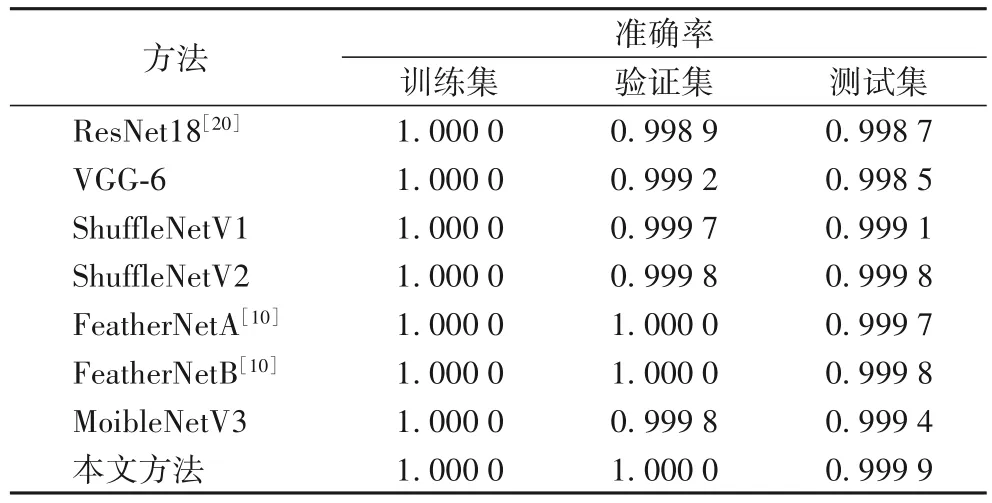
表3 CQNU-LN数据集验证结果对比Tab.3 Comparison of verification results on CQNU-LN dataset

图5 CQNU-3Dmask数据采集形式Fig.5 CQNU-3Dmask data acquisition forms

表4 实验所用数据集信息Tab.4 Information of datasets used in experiments
3 实验与结果分析
3.1 实验环境及设置
实验的硬件环境如下:CPU 为Intel Xeon,内存为62.8 GB;显卡为Titan XP,显存为12 GB;实验编程环境选用GPU 版本的tensorflow1.8.0 和Keras2.2.4,英伟达并行计算架构(Compute Unified Device Architecture,CUDA)版本为8.0。
在对RGB 图与深度图分别进行特征提取以及融合的阶段,不同于MobileNetV3 传统的输入,本文采用归一化后尺寸为112×112 的图像作为输入尺寸。优化方法采用Adam,初始学习率设置为1E-4,衰减率设置为5E-3。
3.2 与其他活体检测网络的比较
在对比实验中,评估指标采用文献[22]中提到的评估方式,在CASIA-SURF以及CQNU-LN数据集上进行评估。
本文以错误接受率(False Acceptance Rate,FAR)、真正类率(True Positive Rate,TPR)、等错误率(Equal Error Rate,EER)、半错误率(Half Total Error Rate,HTER)作为评估指标。FAR表示为算法在所有的假体人脸数据集中将假体人脸判断成活体人脸的比率。TPR 表示为算法在所有的活体人脸数据集中把活体人脸判断为活体人脸的比例。EER表示为在受试者工作特征曲线(Receiver Operating Characteristic curve,ROC曲线)上错误拒绝率(False Rejection Rate,FRR)与FAR 相等时的均值。半错误率HTER 表示为测试集中FRR 与FAR 的均值。
不同模型在CQNU-LN 数据集的结果如表5 所示。训练的方式为将深度图与RGB 图特征融合训练。ResNet18 为文献[20]的活体检测网络,该网络采用参数量较大的ResNet18作为主要的框架,采用多模态特征融合的方式进行活体检测训练。其他对比方法为近年来流行的轻量级卷积神经网络,其中FeatherNetA、FeatherNetB 为文献[10]中轻量级活体检测网络。实验结果表明,轻量级卷积神经网络更适用于本文所制定的活体检测任务。ShuffleNetV2[17]在TPR@FAR=10E-4上达到了精度为95.49%,是目前最优的活体检测网络模型,本文方法在TPR@FAR=10E-4 达到95.54%,相较于ShuffleNetV2提升了0.05%。

表5 不同卷积神经网络在CQNU-LN数据集上的指标Tab.5 Indicators of different convolutional neural networks on CQNU-LN dataset
不同模型在CASIA-SURF 数据集的结果如表6 所示。效果最好的模型为ShuffleNetV1[18],在TPR@FAR=10E-4指标上达到95.01%,本文方法在TPR@FAR=10E-4 指标上达到了95.15%,相较目前效果最好的方法提升了0.1%。
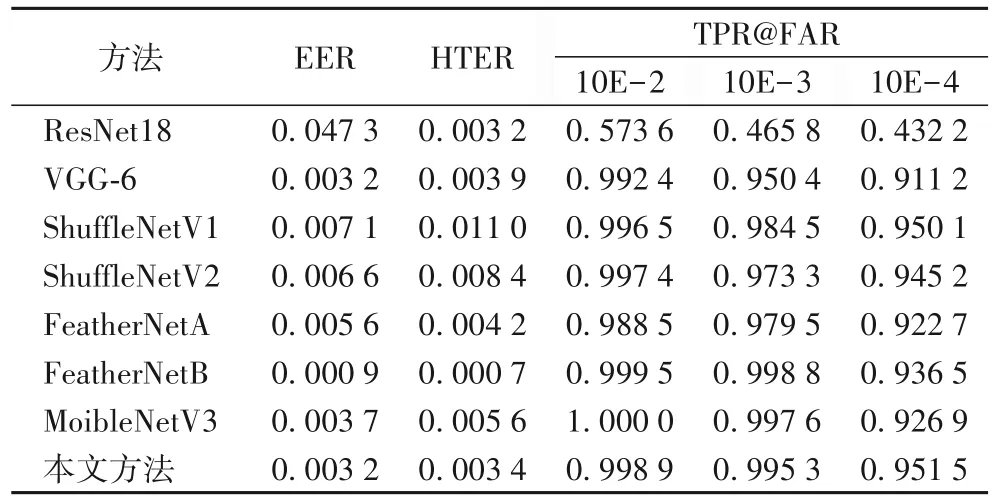
表6 不同卷积神经网络在CASIA-SURF数据集上的指标Tab.6 Indicators of different convolutional neural networks on CASIA-SURF dataset
3.3 多模态鲁棒性实验
为了进一步验证多模态特征融合是否具备鲁棒性,本文采取分别训练RGB 和深度图与特征融合后的RGB 和深度图进行比对,三个模型的超参数设置相同。
表7~8分别为本文方法在CQNU-LN 以及CASIA-SURF数据集上各种模态的网络效果对比。
实验结果表明,在CQNU-LN 数据集上,RGB+Depth 的方式在TPR@FAR=10E-4 指标相较仅训练RGB 的方式提升了10.9%,相较仅训练Depth 的方式提升了4.1%。在CASIASURF数据集上,RGB+Depth 的方式在TPR@FAR=10E-4指标相较仅训练RGB 的方式提升了10.4%,相较仅训练Depth 的方式提升了1.9%。

表7 CQNU-LN测试集上各种模态的测试效果Tab.7 Test results of various modalities on CQNU-LN test set
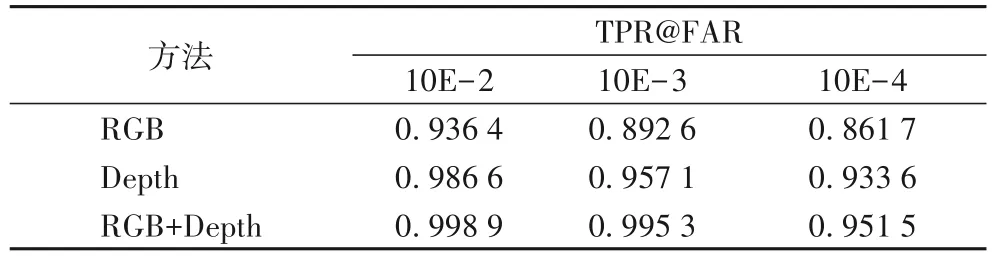
表8 CASIA-SURF测试集上各种模态的测试效果Tab.8 Test results of various modalities on CASIA-SURF test set
为了进一步验证网络是否具备嵌入式的条件,表9 为模型轻量级指标,以Keras 生成的网络模型参数文件大小(Parameter),每秒浮点数运算量(FLoating-point Operations Per second,FLOPs)和模型预测单张图像所需要的时间来恒定反映各网络参数规模。本文方法在模型参数量上与FeatherNet以及MobileNetV3 一致,模型预测时间一致,在FLOPs 上虽然不及FeatherNet,但是与ResNet 与VGG-6 相比较低。综合各指标可知本文方法符合在嵌入式设备中运行的标准。
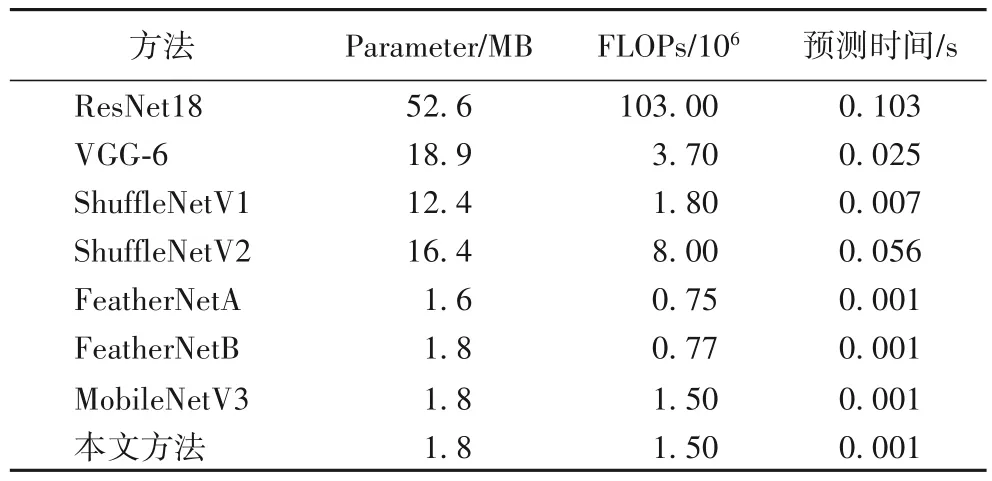
表9 不同模型轻量级指标Tab.9 Lightweight indicators of different models
3.4 3D攻击防御手段
人脸活体攻击并非仅存在打印式的照片、视频的攻击,随着3D 打印技术的不断发展和成熟,制作出价格低廉、形象逼真的人脸3D 的攻击手段已经可以实现,如3D 面具、头模和头套,3D 的攻击方式已逐渐成为人脸认证系统的新威胁。然而,许多以前提出的攻击检测方法在面对3D攻击手段的攻击时基本失去效果,同样本文在2D手段上的防御模型也无法解决3D 攻击。针对上述问题,本文同样以RGB 与Depth 图像为输入进行特征融合的方式来构建针对3D 攻击的活体检测模型,虽然3D 攻击手段不再是平面的图像,利用深度特征难以辨识,但是深度特征会对光照具有一定的鲁棒性,再加上采集数据集时考虑到光照信息,同时训练RGB 图能够使模型关注到图像的颜色以及纹理上面的差异,从而使模型更加鲁棒。本文方法在CQNU-3Dmask上进行多模态鲁棒性实验,结果如表10所示。
由表10 可知,在TPR@FAR=10E-4 指标上,训练RGB 图加Depth 图的精度相较仅训练RGB 图提升了0.9%,比仅训练深度图提升了6.2%。
在实际应用场景中,本文采取一种级联的手段防御2D、3D 攻击:网络首先会给出2D 模型的判断,若2D 模型给出标签为假,最终结果则为假;若2D 模型判别结果为真则调用3D模型所预测的结果作为最终判断。级联方法如下代码所示,融合之后的实机演示图如图6所示。

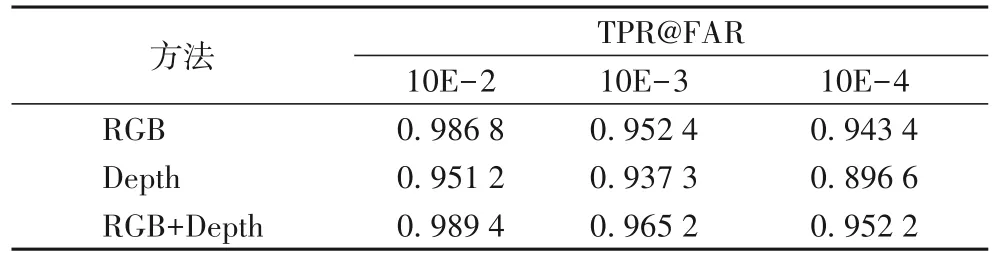
表10 CQNU-3Dmask测试集上各种模态的测试效果Tab.10 Test results of various modalities on CQNU-3Dmask test set
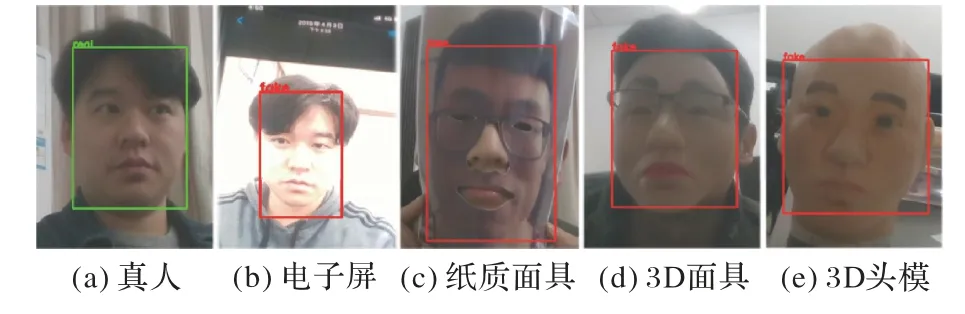
图6 实机演示效果Fig.6 Real machine demonstration effect
4 结语
针对非交互、静默式活体检测算法,在MobileNetV3 的基础上本文提出了一种全新的深度卷积神经网络模型。为保证特征的多样性,该模型以RGB 以及深度图作为输入特征,并且对两种特征进行融合,在结构上丰富了提取特征,提高了特征表达的能力;为了保证精度且减少网络计算量,在网络尾端采用Streaming Module 替换传统的全局平均池化模块以达到减少计算量的目的。在数据集上分别采集了针对2D 攻击手段的CQNU-LN 和针对3D 攻击手段的CQNU-3Dmask 数据集。实验结果表明本文方法具有良好的检测效果。
虽然本文所提出的方法在活体检测任务上较为全面,但是也有不足之处:1)对于3D 的攻击手段的表现并不那么稳定,由于光照、面部细节等影响,在实际的使用过程中还是会出现错误的预测,研究者们可以手工提取特征或者基于注意力机制去解决这一系列由外部影响所带来的问题。2)白盒、黑盒的对抗攻击方式在近年来也一直是研究的重点,卷积神经网络的模型普遍存在着通过一个扰动即可以攻击整个网络,使模型出现预测偏差。如何让活体检测网络对于卷积神经网络的对抗攻击性更加鲁棒,也是接下来值得深入研究的一个方向。
