基于并行卷积核交叉模块的卷积神经网络设计
2020-12-28王新娇曾上游魏书伟
王新娇 曾上游 魏书伟

摘 要: 针对卷积神经网络结构单一,模块中卷积核使用单一,网络特征提取不充分导致图片分类准确度不够,以及模型大的问题,提出卷积核交叉模块的网络设计。此模块先将输出特征图分成两组,每一组采用不同数量、不同大小的卷积核进行特征提取,然后将分组得到的特征图进行级联操作后再通过1×1的卷积核进行整合。该文设计的卷积神经网络与传统的网络相比,在食物101_food数据集上将识别精度由56.7%提升至72.63%;在交通GTSRB数据集上将识别精度由96.3%提升至98.41%。实验结果表明,该文设计的网络结构性能优越,且网络模型较小。
关键词: 卷积神经网络; 网络改进; 卷积核; 图像分类; 特征提取; 结果分析
中图分类号: TN926?34; TP391.4 文献标识码: A 文章编号: 1004?373X(2020)24?0182?05
Design of convolution neural network based on parallel convolution kernel cross module
WANG Xinjiao, ZENG Shangyou, WEI Shuwei
(School of Electronic Engineering, Guangxi Normal University, Guilin 541004, China)
Abstract: In allusion to the problems of insufficient accuracy of image classification caused by the single structure of convolution neural network, single use of convolution kernel in the module and insufficient extraction of network features, as well as large model problem, a network design of convolution kernel cross module is proposed. In this module, the output feature map is divided into two groups, each group uses convolution kernels with different number and size for the feature extraction, and then the grouped feature map is cascaded and integrated through 1×1 convolution kernels. In comparison with the traditional network, the recognition accuracy by the convolution neural network designed in this paper can be improved from 56.7% to 72.63% in the food 101_food dataset, and from 96.3% to 98.41% in the traffic GTSRB dataset. The experimental results show that the network structure designed in this paper has superior performance and smaller network model.
Keywords: convolution neural network; network improvement; convolution kernel; image classification; feature extraction; result analysis
0 引 言
随着互联网的快速发展和大数据时代的到来,深度学习已经成为当前人工智能领域研究的热点[1]。人工智能的发展是当今世界研究的主流,国家也在强调“互联网”时代,而深度学习在图像识别、语音处理、数据挖掘、自然语言处理以及其他相关领域都取得了很多成果。深度学习是一个复杂的机器学习算法,解决了很多复杂的难题,使得人工智能技术取得了很大进步。
卷积神经网络(Convolutional Neural Network,CNN)是深度學习算法中一种重要的算法。在2006年深度学习理论被提出后,卷积神经的表征学习能力开始被大家关注,随着数值计算的更新得到发展。2012年ImageNet大规模视觉挑战赛(ILSVRC),AlexNet开始得到GPU计算集群支持并多次成为ImageNet视觉识别竞赛的优胜算法[2],使得之后各类深度网络结构相继诞生,包括2014年的VGGNet[3]、GoogLeNet和2015年的ResNet。
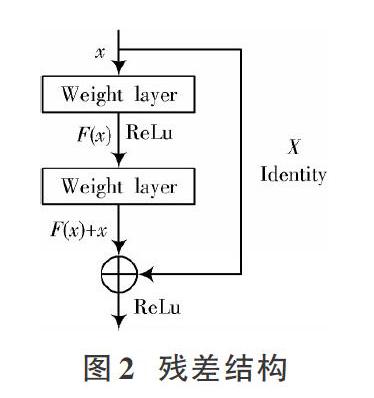
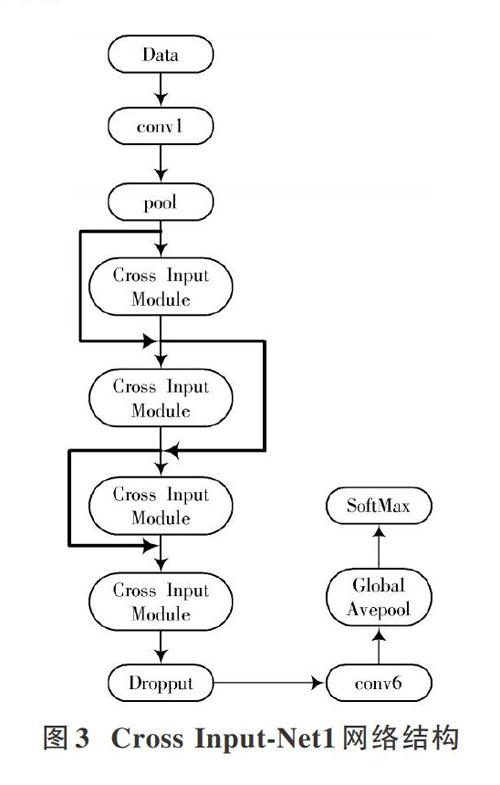
AlexNet相比于之前的LeNet网络具有更深的网络结构,使用层叠的卷积层来学习更丰富更高维的图像特征,通过数据增强的方式来扩增数据集。AlexNet中重要的一点是使用ReLu[4]函数代替Sigmoid函数,很好地解决了梯度饱和导致训练收敛慢的问题,大大提高了训练效率。但同时网络结构的加深使得参数量加大,使网络训练强度增大并且模型增大。针对这个问题,本文卷积神经网络结构使用Cross Input?Net,利用Min Lin等提出的Network in Network中1×1的卷积核,将模块中分组获得的图像特征实现整合然后进行降维,模块中采用不平等分组,1×1,3×3和5×5卷积核的交叉使用,使得特征提取更加准确,网络中使用ResNet结构,最后用全局平均池化代替全连接,可轻松训练非常深的CNN架构的同时大大提高了网络训练的准确度。
3 实 验
3.1 实验设置
实验环境:本实验所有网络都是基于Caffe[14]深度学习框架基础上进行的,各模型实验结果在计算机i7?6700k 4核CPU、Ubuntu 14.04操作系统、32 GB内存以及NVIDIA?GTX1070的GPU上完成的。
参数设置:网络训练参数的调试对网络性能优劣至关重要,学习率是网络训练中的重要一步,学习率过高或过低都会对网络产生一定影响。本次实验2个网络均采用相同的参数设置,根据网络和数据集设置的学习率参数及变化值:在101_food数据集上训练时,学习率大小设置为0.005,学习率采用多步变化,迭代次数设置为40 000,80 000和120 000,最大迭代次数为150 000;在GTSRB上训练时,学习率大小设置为0.005,学习率采用多步变化,迭代次数设置为24 000和48 000,最大迭代次数为60 000。
数据集介绍:实验所用的数据集是GTSRB和101_food,GTSRB交通标志数据集总共51 831张交通图片,分为43类,其中,训练集有39 209张图片,测试集有12 432张图片,所有图片都是在复杂背景下拍摄见图5。
101_food总共101 000张食物图片,分为101类,每类有1 000张图片,其中,训练集有75 750张图片,测试集有25 250张,如图6所示。
预处理:对图片进行左上角、右上角、左下角、右下角和中间进行不同程度的裁剪,大小裁剪为227×227,对数据集进行数据增强;然后进行归一化和去均值处理,通过水平翻转等方式增加数据集的数量。
3.2 实验结果及分析
本文实验在AlexNet基础上将卷积层进行替换,又通过使用BN、ResNet、Avepool以及Dropout等来优化网络,通过对比AlexNet网络,网络1和网络2不管是在准确率还是模型大小上都有很大的改进,其中,网络2的性能更优越。
表1和表2分别表示网络在101_food和GTSRB上的精确度和实验模型大小,图7和图8分别展示了各模型在数据集上变化的准确率曲线。
由表1和表2可知,Cross Input?Net1和Cross Input?Net2都有较好的精确度,网络整体模型大小也减小很多。传统网络和AlexNet网络结构较浅,网络整体参数较小,所以训练时间比较短,本文网络每个模块中从不同通道使用了不同的卷积核进行卷积,2条支路的使用相当于支路参数的累加,网络的加宽、加深也使得网络整体参数增加不少,导致网络训练时间相对较长。
整体来说,网络的加深、加宽对BN层及激活层的计算增加了不少,使得相同时间迭代下网络训练加长,但是全局平均池化代替全连接又减少了大量的卷积层参数,同时不同通道卷积核的交叉混用使得特征提取更充分,网络训练精确度更高。Cross Input?Net2的网络在综合对比下性能也更优越。
4 结 语
本文通过对AlexNet基础网络进行改进,提出双通道卷积交叉网络模型,使用不同卷积核进行特征提取,充分提取特征的同时也增加了网络的深度和宽度,使用BN进行归一化处理,用ResNet残差消除梯度问题,用Dropout来防止过拟合,用全局平均池化代替全连接减少网络参数。在101_food和GTSRB数据集上进行训练,实验结果表明,本文网络性能优越,在提高网络识别精度的同时减小了网络模型大小。虽然网络在一定程度上有很大改进,但是后续工作仍需要继续对网络结构进行改进,网络加深、加宽带来的网络模型大,训练时间长问题还需要进一步优化,同时网络需要在更多大型数据集上进行训练,将其运用到更多方面,提高应用性能。
注:本刊通讯作者为曾上游。
参考文献
[1] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks [J]. Science, 2006, 313: 504?507.
[2] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// International Conference on Neural Information Processing Systems. Boston: Massachusetts Institute of Technology Press, 2012:1097?1105.
[3] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large?scale image recognition [J]. Computer science, 2014(7): 21?34.
[4] 周飞燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报,2017,40(6):1229?1251.
[5] 李策,陈海霞,汉语,等.深度学习算法中卷积神经网络的概念综述[J].电子测试,2018(23):61?62.
[6] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [J]. Computer science, 2015(11): 102?110.
[7] 杨远飞,曾上游,周悦,等.基于轻量型卷积神经网络的图像识别[J].电视技术,2018,42(3):40?44.
[8] 周悦,曾上游,杨远飞,等.基于分组模块的卷积神经网络设计[J].微电子学与计算机,2019,36(2):68?72.
[9] SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions [C]// IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1?9.
[10] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770?778.
[11] 潘兵,曾上游,杨远飞,等.基于双网络级联卷积神经网络的设计[J].电光与控制,2019,26(2):57?61.
[12] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks [C]// European Conference on Computer Vision. Zurich: Springer, 2014: 818?833.
[13] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting [J]. Journal of machine learning research, 2014, 15(1): 1929?1958.
[14] JIA Y Q, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding [C]// ACM International Conference on Multimedia. Xiamen: Springer, 2014: 675?678.
作者简介:王新娇(1995—),女,山东潍坊人,硕士,研究方向为人工智能深度学习。
曾上游(1974—),男,工学博士,教授,研究领域为非线性动力学、计算神经科学。
魏书伟(1994—),男,山东临沂人,硕士,研究方向为人工智能深度学习。