一种古籍汉字图像的多属性模糊检索模型
2020-12-28齐艳媚田学东张充李亚康
齐艳媚,田学东,张充,李亚康
(1. 河北大学 网络空间安全与计算机学院,河北 保定 071002;2. 河北大学附属医院 信息中心,河北 保定 071000)
汉语言文字研究的深入带来了对文献数字化、信息化处理的更高要求.古籍汉字多为结构复杂、书写风格多样的繁体字,加之年代久远对字形存在形态所带来的影响,如噪声和断笔等情况,导致传统的基于内容的图像检索技术和文字识别技术在对古籍汉字图像进行检索时,难以取得理想的结果.因此,根据古籍汉字的特点,研究、提取有效的古籍汉字图像特征并建立相应的匹配算法,是古籍汉字图像检索研究中的重点和难点.
近年来,针对古籍汉字图像检索的研究相对较少,可供参考的主要有脱机手写汉字图像的检索与识别方法.张睿[1]和姜文[2]等介绍了方向线素法,通过抽取汉字轮廓,考察像素点的8邻域内像素在0°、±45°、90°4个方向上的分布情况,虽然方向线素特征同时兼顾了统计特征和结构特征的优势,但其维数较多增加了识别难度.冉耕等[3]介绍了一种弹性网格法,利用弹性网格对图像进行分块,获取弹性网格特征,能较好地反映汉字的结构细节和字符特征,克服手写汉字由于书写风格多样造成的字体变形和数据采集造成的样本变形等问题.
除了传统特征提取方法,卷积神经网络也被引入到汉字识别领域中来.毛晓波等[4]提出一种新的卷积结构,将当前层与前一层特征图叠加,用于对脱机手写汉字的识别,不但减少了参数数量,对梯度消失的问题也有所缓解.刘虹等[5]提出将余弦相关性加入卷积神经网络的算法,使卷积神经网络的特征提取能力增强,能够在恶劣环境下达到较高的识别效率,增强了网络结构的模式检测能力,获得了更快的收敛速度.郭利敏等[6]利用卷积神经网络的分类问题替代古籍汉字识别问题,通过深度学习构建分类器,用于汉字图像与汉字字符的分类,进而提升古籍汉字的识别率.
由于手写汉字大多存在字体复杂多变、风格多样等问题,因此,在汉字图像检索时引入了模糊特征理论.Zhou等[7]针对笔触的交集和交集之类的含糊区域会给手写汉字的笔画提取带来困难的问题,设计了一种借助模糊区域信息来进行汉字笔画提取的方法,首先获取汉字骨骼上模糊区域的笔画子段间的连接系数,然后修改骨骼上的变形,检测突然的转折点,获得最终行程:该方法提取的笔画保持良好的形状,能正确反映笔画之间的位置关系,可用于手写汉字的相关研究.魏玮等[8]提出了一种模糊双弹性网格的特征提取方法,在特征提取时加入了模糊特征和双弹性网格划分,能够更有效地提取汉字“撇”和“捺”方向的特征.Mapari等[9]针对手写化学结构或符号难以被有效识别的问题,提出了一种基于模糊规则和SOM(self organization map)的模型,在进行模糊图像分割时运用低模糊规则和高模糊规则方法,提高了手写体化学符号和结构的识别率.柴彦立[10]在模糊特征基础上引入犹豫模糊集理论,融合结构与统计特征,提出一种面向古籍汉字图像检索的犹豫模糊特征提取算法,提升了古籍汉字图像的检索查全率和查准率.
由于古籍汉字具有结构繁杂多变、笔画风格多样、年代久远等特点,导致上述方法在处理古籍汉字图像检索时难以取得理想效果.鉴于模糊集理论的单一隶属度导致其无法完整有效地处理古籍汉字在笔画以及结构特征方面的信息,本文在对古籍汉字图像检索时引入犹豫模糊集理论[11],利用其在处理多隶属度方面的优势,来适应古籍汉字风格多样、结构多变的特点,充分考虑汉字笔画和角点的构成特征,从多角度出发,建立融合古籍汉字图像笔画特征和角点特征的多属性模糊检索模型,更好地满足古籍汉字研究过程中专家对古籍汉字图像检索的实际需求.
1 古籍汉字图像的特征分析
1.1 古籍汉字图像的角点特征分析

1.2 古籍汉字图像的弹性网格划分

1.交叉点;2.端点;3.拐点.图1 古籍汉字图像的角点特征Fig.1 Corner feature map of ancient Chinese character images

a.纵横弹性网格划分;b.规范化对角弹性网格划分.图2 古籍汉字图像的重叠规范化双弹性网格划分Fig.2 Overlapping normalized bi-elastic mesh division diagram
1.3 古籍汉字图像的笔画方向分解
汉字大多由“横”、“竖”、“撇”、“捺”4种笔画组成,因此,汉字的基本特征可以用这4种笔画进行有效地表示.F(x,y)表示细化后的二值图像,对汉字细化后采用“OR”[12]技术进行分解的规则如表1所示.

表1 汉字笔画分解规则
2 古籍汉字图像的相似度评价
本文引入犹豫模糊集理论,利用其在处理多隶属度决策方面的优势,从古籍汉字图像的多角度属性出发,完成古籍汉字图像间的匹配检索.
2.1 犹豫模糊集
犹豫模糊集[11]是由Torra对模糊集[13]进行推广而提出的新理论,设U是一个非空集合,则称
F={
(1)
为U上的犹豫模糊集,hF(x)表示[0,1]上的非空集合,是x∈U对集合F的多个可能隶属度的集合,犹豫模糊集中隶属度是若干可能值的集合,而不是一个确定的值或者分布[11].
文献[14]在进行距离测度计算时考虑到了权重的影响,根据评价对象属性的重要程度,在加权平均算子的基础上,给出了犹豫模糊加权距离测度的计算公式.
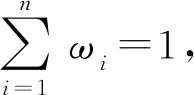
(2)

2.2 古籍汉字图像相似度评价属性
定义2设Ir表示输入的古籍汉字图像,Irj表示数据集中任一古籍汉字图像(j= 1, 2, 3, …,m.m为数据集中古籍汉字图像的总数).
2.2.1 笔画属性
下面以在规范化对角双弹性网格下对“横”笔画子图的特征分析为例,给出在纵横弹性网格下的“横”笔画像素对应的隶属度函数的定义,并求出在当前网格下的隶属度值.
1)数量特征

定义3“横”笔画像素的数量特征隶属度函数为
(3)
其中tolH表示“横”笔画子图中“横”笔画像素的总数.分别计算Gi内(k=H、S、P、N)(分别表示“横”“竖”“撇”“捺”像素)的隶属度,加权平均即为当前网格在笔画数量特征下的隶属度值.
2)位置特征
利用Gi内的笔画像素与其周围网格的相交情况,作为评估2幅古籍汉字图像相似程度的标准.如果网格Gi内的所有笔画均不存在与周围网格相交的情况,则笔画像素在Gi内的位置特征对应的隶属度值为1.
横笔画像素在纵横弹性网格下的位置特征图如图3a所示,Gi内笔画1和笔画2皆与周围网格有相交情况,笔画3与任何网格均无相交情况,因此横笔画像素在Gi内的位置特征对应隶属度值为(m1+m2+l3)/(l1+l2+l3).
横笔画像素在规范化对角弹性网格下的位置特征图如图3b所示,Gi内的所有笔画皆与邻接网格有相交情况,因此横笔画像素在Gi内的位置特征对应隶属度值为(m1+m2+m3)/(l1+l2+l3).如果2幅图像在网格Gi内所有笔画像素点与同本网格有交叉的所有笔画长度总和的比值越接近,说明它们的相似程度越大.
定义4“横”笔画像素的位置特征隶属度函数为
(4)

3)距离特征
将Gi内笔画像素到邻近网格的最短距离作为评估不同古籍汉字图像间相似程度的标准.
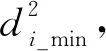

a.纵横弹性网格;b.规范化对角弹性网格.图3 弹性网格下“横”笔画像素的位置特征Fig.3 Location feature map of “horizontal” stroke pixels under elastic grid

a.纵横弹性网格;b.规范化对角弹性网格.图4 弹性网格下的“横”笔画像素的距离特征Fig.4 Distance feature map of “horizontal” stroke pixels under elastic grid

定义5“横”笔画像素的距离特征隶属度函数为
(5)

2.2.2 角点属性
组成汉字的元素除了笔画外,角点也占了很高的比重,古籍汉字的结构信息能够通过角点得到很好的展现,因此本文将汉字笔画的交叉点、拐点、端点在汉字图像中的数量分布以及位置信息作为古籍汉字的角点特征.
1)角点距离特征

定义6角点的距离特征隶属度函数定义为
(6)

2)角点分布特征
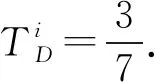

a.纵横弹性网格;b.规范化对角弹性网格.图5 弹性网格下的古籍汉字图像角点距离特征图Fig.5 Corner distance feature map of ancient Chinese character images based on elastic grid

a.纵横弹性网格;b.规范化对角弹性网格.图6 弹性网格下的古籍汉字图像角点分布图Fig.6 Distribution characteristics of corner points in ancient Chinese character images under elastic grid
定义7角点的分布特征隶属度函数定义为
(7)

2.3 基于犹豫模糊集的古籍汉字图像检索
对古籍汉字图像Ir和Irj经过多隶属度评价后,形成犹豫模糊集合fr和frj,其中f由隶属度集合Ufn、Ufp、Ufd、UfT_J、UfT_F构成,任一评价属性Ew(w=1,2),w=1和2分别表示笔画属性和角点属性,犹豫模糊集合对应的犹豫模糊元素集合为hfr和hfrj,hfr和hfrj中元素为Ir和Irj在属性Ew包含的各个特征下的隶属度值的集合,利用犹豫加权测度公式进行处理,如式(8)~(10)所示.
(8)
(9)
sim(Ir,Irj)=1-d(Ir,Irj),
(10)

(11)
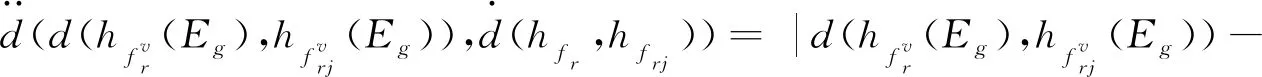
(12)

.
(13)
3 实验结果及分析
3.1 数据集介绍
为了验证古籍汉字图像的多属性模糊检索方法的有效性,本文从已实现数字化的四库全书文渊阁中的经、史、子、集中共选取92幅版面图像,对其切分获得11 574幅单字图像作为古籍汉字图像检索的实验样张,采用13位编码进行标注,如表2所示(例如:GJHZ_0000030011012表示文渊阁经部第0003册001页下第012个单字图像).
将数据集中所有单字图像按字形结构划分为左右结构(A)、上下结构(B)、独体结构(C)、包围结构(D)4大类,部分实验样张如表3所示.

表2 古籍汉字图像数据集编码格式

表3 古籍汉字图像检索实验样张
3.2 隶属度函数中的参数设置
为了确定公式(7)中的权重系数α和β,归纳总结11 574幅单字图像在每个弹性网格和其八邻域情况下的角点分布对检索结果的影响程度,得出α的值为0.465,β的值为1.625.
为了分析古籍汉字图像的多属性模糊检索方法的有效性,选择查全率和查准率对图像的检索结果进行评价.
定义8查全率(recall rate,简称R),表示检索结果中与输入图像相似的图像数量NS占数据集中所有相似图像数量NT的百分数.
(14)
定义9查准率(precision ratio,简称P),表示检索结果中与输入图像相似的图像数量NS占全部检索结果图像数量NR的百分数.
(15)
3.3 古籍汉字图像检索性能分析
通过归纳重叠规范化双弹性网格下古籍汉字图像的笔画属性和角点属性的犹豫模糊集合,从多角度出发考察古籍汉字特征,同时引入犹豫模糊加权距离测度,考虑了不同属性所占比重不同的问题.为了验证本文方法的可行性,构造传统特征提取算法中的基于重叠规范化双弹性网格的梯度特征提取方法[3]作为对比算法1,基于手写体汉字双弹性网格模糊特征算法[8]作为对比算法2;构造卷积神经网络类检索算法中的基于卷积神经网络的古籍汉字识别算法[6]作为对比算法3,结合余弦相关性的卷积网络识别汉字的算法[5]作为对比算法4,对其网络模型稍作修改,使其能更加适用于古籍汉字图像检索.
设NS为与待检索图像相似度高于某一阈值T/%时检索出的图像数量;NR为检索出的所有图像的数量.以常见的左右结构图像“”(编码为GJHZ_0000010100161)为例,根据查准率计算法则(例如,当阈值设置为90%时,其输出图片数量为11,其中相似图片为9幅,则查准率为9/11=0.818)计算相应的P(查准率)值,如表4所示.

表4 本文与模拟实验算法在不同阈值下的参数统计结果
从表4可知,相比传统检索类算法中的梯度特征(算法1)和模糊特征(算法2)方法,本文方法在面对古籍汉字图像检索时能达到更高的查准率和查全率,这是由于本文利用犹豫模糊集理论在处理多属性决策方面的优势,从多角度出发提取古籍汉字图像的特征,定义相应的隶属度函数,并且通过相应权重更新算法考察了不同特征所占比重不同的问题,更加适用于古籍汉字图像检索;在不同阈值下本文方法与卷积神经网络类方法的查准率基本保持在80%左右,当阈值T为85%和80%时本文方法略显优势,但是在其他情况下出现了本文参数略低于模拟系统的情况,这是由于古籍汉字图像大多结构繁杂多变、存在状态较差等因素,导致本文算法在对古籍汉字图像进行特征提取时较卷积类算法略显劣势,造成了本文算法的查准率出现略低于模拟系统的情况.但是,总体来说本文方法在对古籍汉字图像检索时,能够取得较好的效果.
为进一步验证本文实验的有效性,考察本文算法与模拟实验算法在不同汉字字形结构下的查全率与查准率间的差异.不同字形结构下的查全率和查准率的值由组内全部图像(20幅图像)的平均值得出,几种方法的平均查全率和平均查准率对比结果如表5所示.
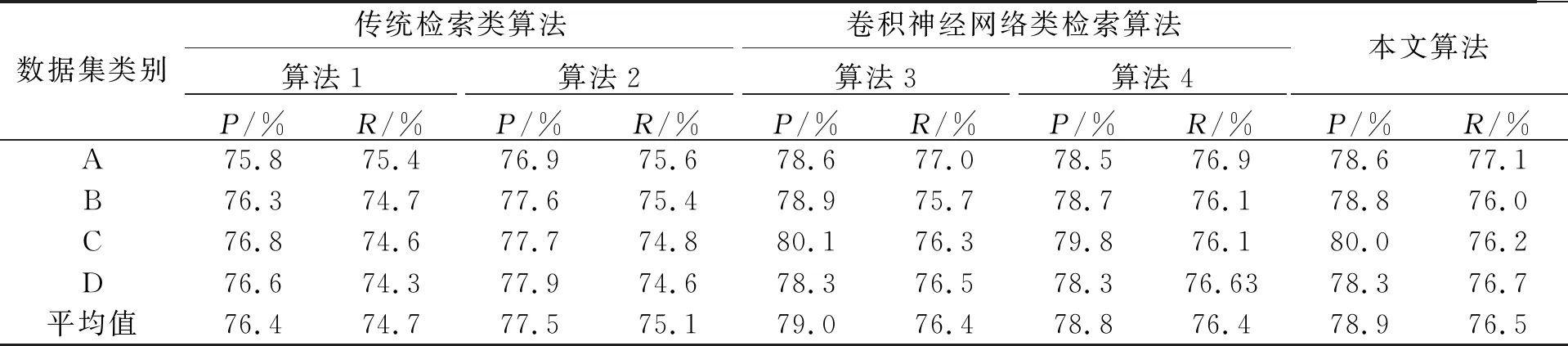
表5 本文与模拟实验算法在不同字形结构下的检索结果对比
表5中的平均查全率和平均查准率表示了整个测试数据集的最终评价值,由表4可知,无论在何种情况下,本文算法的查全率、查准率均高于算法1和算法2 两种传统检索类算法;本文算法的平均查全率分别比算法3和算法4高0.1%和0.1%,平均查准率比算法3低了0.1%,比算法4高了0.1%.在类别B和类别C下算法3的查准率略高于本文算法,类别C下算法3的查全率略高于本文算法,这是由于在进行特征提取时,基于犹豫模糊集的图像检索算法与基于卷积的图像检索算法的侧重点不同,导致了在面对古籍图像书写质量较差以及纸张破损严重等问题时,本文算法的查准率和查全率存在略低于对比算法的情况.综合实验结果,本文算法的总体效果基本达到了预期目标.
3.4 古籍汉字图像检索结果分析

a.本文检索结果top10;b.算法1检索结果top10;c.算法2检索结果top10; d.算法3检索结果top10;e.算法4检索结果top10.图7 古籍汉字图像检索结果Fig.7 Image retrieval results of ancient Chinese characters

图8 5种算法检索时间对比Fig.8 Five algorithms retrieve time comparison
由图7可知,5种算法检索结果前8张图像均与目标图像有较高的相似度,且图7a中的后2张图像相似度明显高于图7b和图7c,说明本文古籍汉字图像的多属性模糊检索算法能达到相对较好的检索效果.
3.5 古籍汉字图像检索速度分析
对算法运行时间进行统计,结果如图8所示.由图8可知,虽然由于本文引入犹豫模糊集理论,从多角度出发进行图像检索相似度的计算,造成了时间复杂度略高于算法1和算法2的结果,但在可接受范围之内;本文方法运行时间明显优于算法3和算法4 2种卷积神经网络类方法,原因是卷积神经网络在对图像进行检索时需要提取自适应特征并不断训练数据集图像,导致其运行时间较长.
综上所述,本文算法在运行速度上相比传统特征提取算法虽有一定劣势,但是由3.3可知本文算法在查全率和查准率上均有一定程度的提高;此外,从3.3和3.4可以看出本文方法与卷积神经网络类特征提取算法在检索准确率和检索结果上无明显差异.虽然卷积神经网络算法对手写汉字识别与检索能够达到较好的效果,但其无法满足汉字研究专家需要实时获得古籍汉字研究时出现的新字形的需求,且卷积神经网络不仅需要高配置的硬件,还需要搭建复杂的网络模型,因此,在查全率、查准率无明显差异的情况下,本文算法更加适用于古籍汉字图像检索.
4 结束语
古籍汉字图像检索是辅助古籍汉字研究的重要手段,为了更好地满足古籍汉字研究的需求,本文采用融合结构与统计特征的图像检索,设计了一种多属性模糊的古籍汉字图像检索方法.首先提取汉字图像的笔画和角点等多特征信息,存入特征数据库;然后利用犹豫模糊加权距离测度公式计算图像间的距离测度,并按相似度进行初步排序,得到最终检索结果.实验结果表明,所提出的算法在对古籍汉字图像检索中取得了较好的效果.
鉴于古籍汉字结构多变、风格多样的特点,本文方法还有很多有待改进之处.首先,需进一步完善权重模型,使其能更加适用于古籍汉字图像检索;其次,隶属度函数的定义和相应评价属性的选择需要优化,通过建立更加适合古籍汉字的特征索引来减小时间复杂度,进一步提高检索系统性能.
