基于MCFFN-Attention的高光谱图像分类
2020-12-26程文娟陈文强
程文娟,陈文强
合肥工业大学 计算机与信息学院,合肥230000
1 引言
高光谱图像(HSIs)一般由数十甚至上百个窄谱带组成[1],具有很高的光谱分辨率[2-4]。它与传统的全色和多色光谱遥感图像相比,蕴含的空谱信息更多,对不同地物目标的识别精度更高。高光谱图像丰富的光谱带在精细分类方面具有独特的优势[5-6],在农业开发[7]和矿产资源开发[8]方面也有广泛的应用。同时,由于其高维的特性和样本量少,容易产生Hughes现象,导致分类精度随着参与运算波段数目的增加而先增后降。因此,对高光谱图像进行准确分类极具挑战性,吸引了越来越多的学者进行探索。
近年来,由于深度学习的快速发展,它已经作为一种重要的手段来解决计算机视觉问题,如图像分类、语义分割等。其中的深度卷积神经网络利用逐层结构叠加的特性,来自动提取物体的特征[9],它在普通图像分类等任务中已经取得了不错的成果。自然地,也可以应用于高光谱图像分类,它能提取出更多隐含的特征[10]。文献[11]首次将深度学习的概念引入到高光谱图像分类中,提出了一种新的基于光谱信息的分类方法。它利用自动编码器提取原始数据信息和PCA 降维后的信息,最后利用SVM 对其进行分类,达到了当时最好的分类效果。但是这种方法只利用了高光谱图像的光谱信息,并没有利用空间信息。紧接着,Makantasis 等人[12]提出了一种基于卷积神经网络(2D CNN)的分类方法,它首先利用主成分分析法(PCA)来降低数据的维度,同时由于相邻像素大概率属于同一类别,所以利用周边像素将中心像素填充成一个固定大小的块,输入到2D CNN中自动提取空间信息,最后送入多层感知器进行分类。同样地,它主要利用了高光谱数据的空间信息,但却忽略了光谱信息。基于这些因素,文献[13]提出了一种基于3D CNN的高光谱图像分类方法,输入的一个3D块,它同时具有空间信息和光谱信息,再利用3D CNN直接对空间和光谱维度进行卷积来提取特征,获得了优良的分类效果。为了更好地提取不同的特征,文献[14]利用了多尺度卷积的策略,卷积核仍然是3D CNN,但不同大小的卷积核可以在不同的感受野上对物体进行卷积,再将得到的特征进行整合和池化,最后进行分类。
尽管深度学习的方法已经较好地应用在高光谱图像分类领域,但仍然存在一些问题。首先,由于高光谱图像样本较少,如何利用少量的样本重复提取有效的特征是一个难题。其次,样本少和复杂的网络结构容易导致过拟合。最后,虽然3D CNN可以提取出较为良好的特征,但提取的特征仍然是相对粗糙的,有噪声的特征图依然会影响最终分类结果。
为了解决这些问题,提出了一个多尺度跨层特征融合注意力机制(MCFFN-Attention)方法进行高光谱图像分类。采取跨层特征融合的方式,对所获得的中间特征图进行反复的利用,使其在网络的训练过程中持续传递,可以有效地缓解梯度消失现象,抑制过拟合。同时结合空谱注意力机制,对所获得的特征图进行特征选择,能够使提取的特征更具识别力,从而提高分类效果。
2 MCFFN-Attention的高光谱图像分类
本章主要介绍MCFFN-Attention 方法的思想,包括多尺度空谱特征提取、跨层特征融合,以及提出的适用于高光谱图像的空谱注意力机制。最后,总体说明MCFFN-Attention的具体实现方法。
2.1 多尺度空谱特征提取
多尺度(Multi-scale)结构包含了丰富的上下文信息,在处理高光谱图像分类方面具有天然的优势。高光谱图像不断增长的空间分辨率和像元之间的关联性越来越大,使得所需要提取的特征越来越多。首先,由于高光谱图像高维的特性,在维度过高时,分类的精度会降低。为了尽量保存原始数据的信息和降低维度,需要利用PCA 将高光谱图像的光谱维度降至20 维。然后,将降维后的数据输入不同大小的三维卷积核,大小分别是1×1×1、3×3×3和5×5×5。将一个原始3D块输入不同的卷积核就能自动提取不同的光谱信息和空间信息。
2.2 跨层特征融合
在高光谱图像数据的处理中,融合不同尺度的特征是提高分割性能的一个重要手段。低层特征分辨率更高,包含更多位置和细节信息,但是由于经过的卷积更少,其语义性更低、噪声更多。高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。利用跨层特征融合(Cross-layer Feature Fusion Network)的方法,将多个特征融合可以改善模型的学习能力。
对多尺度空谱特征提取的特征图进行concat级联,作为第一层特征,将其分别用2个3×3×3的3D卷积核进行卷积,得到第二层和第三层的特征。再将第一层和第二层特征进行对应元素相加,得到融合的特征,第二层和第三层特征进行对应元素相加得到另外一个融合的特征。随后将这两个融合的特征进行空间注意力机制的选择,再将得到的两个特征分别送入2个3×3×3的3D卷积进一步的特征抽象。最后对得到的两个特征进行相同方法的融合。则最终融合的特征既包含低层的空间信息又包含高层的语义信息。相对于通过卷积核直接提取的特征,融合后的特征信息更加丰富,有利于特征的识别。
2.3 注意力机制
随着深度学习在图像分类方面愈加广泛的应用,注意力机制(Attention mechanism)作为一种辅助手段越来越多地用在深度网络中来优化网络结构[15-17]。它更像人眼观察事物的模式,使网络更加有侧重的学习,以此提高网络的学习能力。通常通道注意力机制(Channel Attention,CA)是对同一个特征图的不同通道进行选择优化,获取重校订的通道信息;空间注意力机制(Spatial Attention,SA)则是对同一个特征图的所有空间位置重新分配权重,然后通过Sigmoid 函数来激活得到非线性的重校订上下文信息。本文中提出了改进的CA 和SA方法应用于高光谱图像处理。CA 方法如图1 所示,对于一个给定的中间特征图X(L×H×W×C;L、H和W代表特征图的空间维度,C代表通道数),其原理如公式(1)~(3)所示:
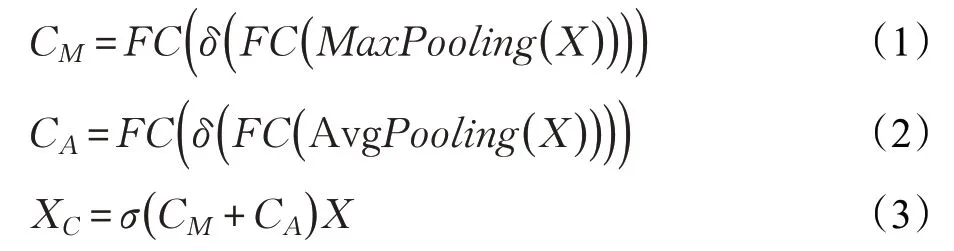
MaxPooling和AvgPooling分别代表空间方向上全局最大池化和全局平均池化,δ是RELU激活函数,σ表示Sigmoid激活函数,FC为全连接层。
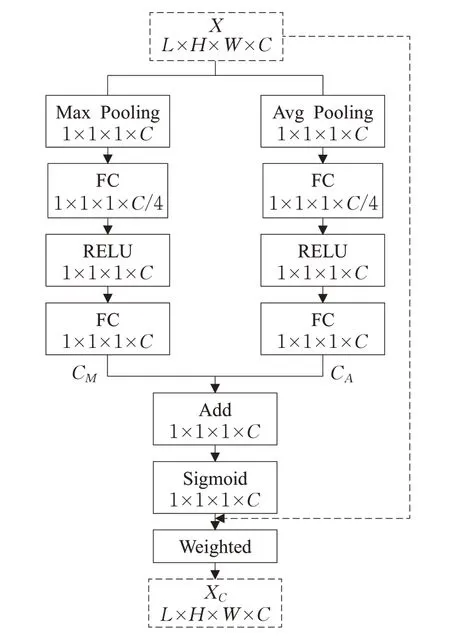
图1 Channel Attention结构示意图
SA 方法如图2 所示,对于一个给定的中间特征图X(L×H×W×C),其过程如公式(4)~(6)所示:

MaxPooling和AvgPooling分别是沿着通道方向上的全局最大池化和全局平均池化,Concat表示通道方向上的级联,Conv是一个三维卷积(3×3×3)。
2.4 MCFFN-Attention方法
考虑到高光谱图像的复杂性。本文将多尺度空谱特征提取、跨层特征融合和Attention 结合起来,提出了一种基于MCFFN-Attention 的高光谱图像分类方法。该方法的步骤如图3所示,首先对高光谱图像在光谱带方向上进行PCA 降维,再取一个3D 块作为原始输入,大小为s×s×d,其中s×s表示块的大小,d表示降维后的维度。将大小为11×11×20的原始输入分别送入三个卷积核大小不同的分支中,卷积核大小分别为1×1×1、3×3×3 和5×5×5。将得到的特征图进行级联,再顺序通过2个3×3×3的卷积层。然后根据特征重复利用融合的思想分别进行跨层相加融合。对于第一次的两个融合,由于其获得的特征图主要包含空间位置信息,因此对融合后的特征进行空间注意力机制处理,使其不同区域获得不同的权重,在网络的训练过程中可以有选择地学习。将空间优化后的特征再次跨层融合后分别送入两个卷积层中,获得更强的语义特征,因此对其采用通道注意力机制的处理,对不同的通道分配不同的权重。以上所有的卷积层后都连接批正则化和RELU激活,可以加快收敛速度。最后,将获得的特征送入全连接层中进行分类。分类的损失函数采用交叉熵损失函数,如公式(7)所示:

tk是标签,yk表示网络的输出。

图2 Spatial Attention结构示意图
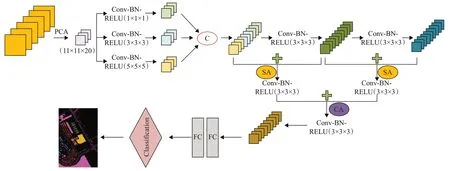
图3 MCFFN-Attention方法结构图
3 实验与分析
本实验所采用的计算机硬件环境Intel Core i7-8700 CPU 3.20 GHz、内存8 GB,软件环境为Spyder TensorFlow1.8。实验以2 组高光谱图像数据集来验证本文方法的有效性,通过平均分类精度AA(Average All)、总体分类精度OA(Over All)和Kappa 系数对分类结果进行评价。
3.1 数据集介绍
印第安松树数据集包含16 类不同的地物目标,由145×145 个像素组成。它有200 个光谱带,覆盖范围为0.2~0.4 μm,空间分辨率为20 m。如表1 所示,对于16类不同地物目标的样本,大于400个样本数的随机选取200个,小于400个样本数的随机选取一半作为训练集,余下的作为测试集。最终,训练集总数为2 309个像素,测试集总数为7 940个像素。 帕维亚大学数据集有9类不同的地物目标,由610×340 个像素组成。它包含103个光谱带,覆盖范围为0.43~0.86 μm,空间分辨率为每类1.3 m。如表2 所示,对每类地物目标样本随机选取200个作为训练集,余下的作为测试集。最终,训练集总数为1 800个像素,测试集总数为40 976个像素。

表1 印第安松树训练集和测试集样本

表2 帕维亚大学训练集和测试集样本
3.2 实验结果与分析
为了验证实验的有效性,将本文提出的MCFFNAttention 方 法 与CNN[12]、3D CNN[13]、M3D CNN[14]和MCFFN 方法进行对比。其中,MCFFN 方法是去除了Attention 部分,其余与MCFFN-Attention 方法的网络结构保持一致,这是一组消融实验,目的是验证Attention的有效性。为了保证对比实验的公平性,所有的实验都在相同的硬件下执行,所采用的训练集和测试集大小也完全相同。本文设定的实验参数为PCA降维的维度为20,原始输入的3D 块的大小为11×11×20,其中,11×11表示3D 块的长和宽,20 表示降维后的光谱维度。网络结构的全连接层中的Dropout正则化大小为0.5,迭代次数epochs 大小为60。所有实验都进行了10 次,选取最优结果。两种数据集的实验结果如表3 和表4 所示,标签和分类结果图如图4和图5所示,全图分类效果如图6和图7所示。
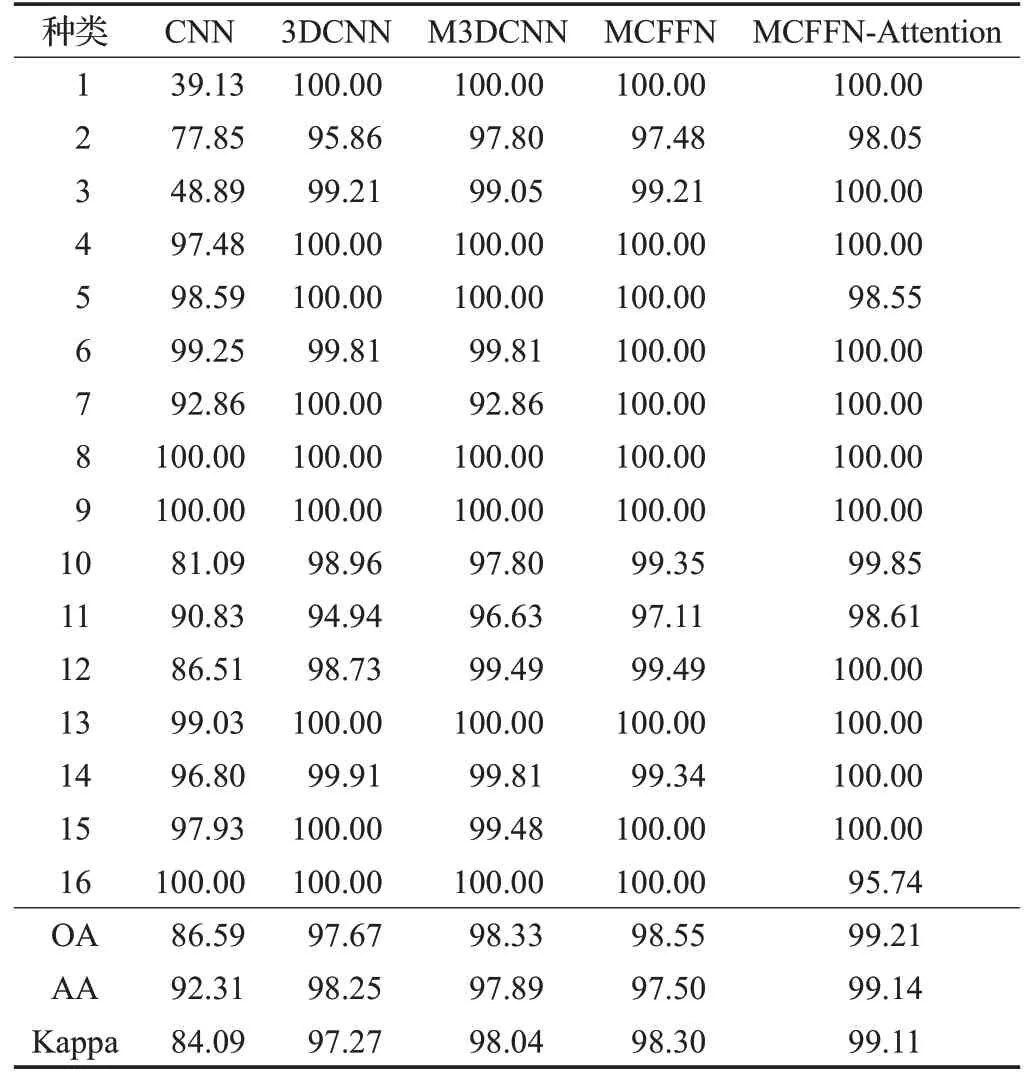
表3 印第安松树测试样本分类精度 %

表4 帕维亚大学测试样本分类精度 %

图4 印第安松树数据集标签和分类结果图

图5 帕维亚大学数据集标签和分类结果图

图6 印第安松树数据集全图分类效果图

图7 帕维亚大学数据集全图分类效果图
在印第安松树数据集或帕维亚大学数据集中,本文提出的MCFFN-Attention 方法的都是五种方法中效果最好的。在印第安松树数据集中,与3D CNN 方法对比,OA、AA和Kappa值分别提升了1.54、0.89和1.84 个百分点,MCFFN与3D CNN相比OA与Kappa分别提高了0.88和1.03个百分点。由此可以得出结论,多尺度跨层特征融合通过重复利用特征,有效地抑制了梯度消失,提高了分类精度。本文提出的方法与效果最接近的MCFFN 方法对比,OA、AA 和Kappa 值也分别提升了0.66、1.64和0.81个百分点。由此可以看出,通过采用空间注意力机制赋予低层特征不同的空间权重,采用谱注意力机制赋予高层特征不同的通道权重,优化了特征图,进行特征选择,对最终的分类结果起到了促进作用。另外一个直观的现象是,所有的基于3D CNN的方法的效果都要远远好于CNN方法,可以表明,同时提取空谱信息有助于提升分类精度。在帕维亚大学数据集的情况中,有着同样的现象,本文方法的OA、AA 和Kappa同样是最高的。与M3D CNN方法对比,OA、AA和Kappa值分别提升了0.42、0.77和0.56个百分点;与最接近的MCFFN 方法对比,OA、AA和Kappa值分别提升了0.31、0.86和0.41 个百分点。在训练时间方面,CNN、3D CNN 和M3D CNN 的时间相差不大。但由于本文的方法加入了Attention机制,在两种数据集上的训练时间都有小幅度增加。
为了更直观地显示结果,本文对结果进行了可视化。在印第安松树中,如图4,16 种不同的颜色代表16种不同的分类,(a)代表原始标签,(b)~(f)依次表示不同的结果分类图。在图6 中,(a)~(e)依次表示不同的全图分类效果图。可以看出,本文的方法得到的结果最接近原始标签,也更加平滑。帕维亚大学的分类结果如图5和图7所示,在图5中,(a)仍然是原始标签图,其他与图4一样,依次是不同方法的分类结果。图7也与图6一样表示不同的全图分类效果。本文的效果仍然是最好的,从图中心橘黄色区域和右下角粉红色区域可以很明显地看出本文分类的错误是最少的,也与原始标签是最接近的。
4 结束语
本文提出了一种MCFFN-Attention 方法,通过多尺度结构充分提取了高光谱图像的空谱信息,并且对空谱信息进行融合。更重要的是,对融合的特征进行空间和通道上的感知,赋予它们不同的权重并自动更新这些权重,使整个网络更有倾向性地学习重要的特征而忽略噪声。最终得到更具有分辨力的特征,用于最后的分类。在两个公用数据集上的实验结果表明,提出的网络极大地提升了分类精度,并且为高光谱图像分类提供了一个新的思路,即在训练过程中对特征进行选择。但本文的方法仍有不足,所有的权重更新都是在一个网络中完成的,而使用一个网络去指导另一个网络的权重更新将更加快速和有效。未来将进行这方面的探索。
