融合语言知识与深度学习的文本蕴含识别
2020-12-26郑德权王贺伟
郑德权,于 凤,王贺伟
1.哈尔滨商业大学 计算机与信息工程学院,哈尔滨150028
2.哈尔滨工业大学 计算机科学与技术学院,哈尔滨150001
1 引言
本文主要是对文本蕴含识别这一自然语言理解任务进行研究,文本蕴含这项任务最早由Dagan 等人提出[1],是研究判断前提和假说关系的问题,关系分为蕴含(Entailment)、对立(Contradiction)、中立(Neutral)。假设前提句记为P,假设句记为H,蕴含指的是由P可以推理H 正确;对立指的是由P 可以推理H 不正确;中立是指由P无法判断H的真假。
如表1 样例所示,对于前提句这一描述,因为能推断“People are riding bikes”,因此标签为蕴含关系;对于“Men are riding bicycles on the street”,前提句中并没有指明在何处骑行,但是人们在骑行基本是能推断,这种情况就是中立关系;而“A few people are catching fish”这一描述,主要对象是人和前提句一致,但动作是互斥的,因此这样的判断为对立关系。
文本蕴含技术在问答系统、信息抽取、机器翻译评价、学生评价系统、自动文本摘要中运用广泛,这些应用都面临着自然语言在表达形式上的多样性,即相同含义可以用不同的陈述形式来表达,同时需要一些广泛的知识才能推断文本之间的关系。在关系抽取领域,Romano等人将文本蕴含技术引用在模板抽取[2];在学生评分任务中,标准答案和学生回答的蕴含关系可以表明学生回答的完成情况,Nielsen 等人据此利用文本蕴含识别建立了一套学生作业评分系统,通过文本蕴含技术进行短文本的评分任务[3]。郭茂盛等人指出文本蕴含其实有三个研究问题:文本蕴含识别、文本对中蕴含关系抽取、文本蕴含生成,文本蕴含本身就是要实现一个基于文本的推理引擎用于语义相关的实际任务[4]。另外随着人工智能技术的不断加深,自然语言处理技术正不断地引用到真实生活中,出现了类似医疗助手和知识问答机器人的产品。
基于知识图谱的自然语言处理技术是目前的前沿话题,知识图谱不仅能有助于实现互联网语义搜索,提升搜索质量,在智能问答领域也有重要应用,其次知识图谱能有效地进行知识融合,将海量的知识转化为结构化的知识图谱,并提供知识查询服务。知识图谱和深度学习的结合就是如何用向量表示实体和关系,这方面,Bordes 等人提出的TransE模型将实体和关系进行向量化,并且转化成能计算的格式,然后通过输入到深度学习里进行下游任务的学习[5];Glockner 等人通过替换句子中词汇的方式检验文本蕴含模型对词汇推理的能力,并发现现有的模型并不能识别词汇关系[6],这就需要将知识引入到神经网络中,以提升文本蕴含中词对之间的推理能力。

表1 SNLI数据样例
2 相关研究
2.1 文本蕴含
早期对于文本蕴含的研究主要是基于统计的方法,如MacCartney 等人提出的基于短语对齐的文本蕴含模型[7],近几年得益于斯坦福大学Bowman 等人发布了570 000 的人工手写英文句子对的数据集SNLI[8],越来越多的基于深度学习的方法应用到文本蕴含的识别中。
Rocktäschel 等人首次将注意力机制引入文本蕴含识别,动机在于想找到假设句H中的第k个词与前提句P中最相关的词构成对齐,这样能加强糅合两个句子向量[9]。Chen 等人在Parikh 等人的基础上进一步加强了序列编码表示模型,提出了混合神经推理模型ESIM,使用BiLSTM网络对句子进行编码,同时发现把句法分析结果加入到蕴含识别中能进一步提高准确率[10-11]。随后Chen 等人又提出了知识增强的文本蕴含模型,将同义词、反义词、上位词、下位词等词汇资源以离散的方式引入到之前提出的ESIM 模型中,在小数据集情况下结果有较大的提升,证明了在数据集有限的场景下,引入词汇资源的可用性。Glockner 等人对现有的最高水平的文本蕴含进行测试,采用抽取前提句,替换其中词汇来构造假设句的方式,验证文本蕴含模型的词汇推理能力,实验表明当前最优的文本蕴含模型也下降了很多,证明了目前的文本蕴含模型缺乏词汇的推理能力[6]。
2.2 知识图谱向量化
知识图谱目前的主要表现形式是三元组的形式,包含头实体(也称作前件)、尾实体(也称作后件),例如(哈尔滨工业大学,地点,哈尔滨)。
如果使用词袋模型去表示实体和关系,由于实体的数量巨大,会出现数据的稀疏性,人们受到分布式词向量的启发,希望学习到实体和关系的低维向量表示。为了解决这个问题陆续出现了TransE、TransH、TransR、TransD 等有效的解决方案。Bordes 等人提出的TransE模型开创性地将实体和关系投影到同一个向量空间并能通过计算的方式转化,基本思想是前件的向量表示和关系向量的表示之和与后件的向量表示越接近越好[12]。Wang等人提出了TransH用于解决多对一以及一对多的多关系数据,并认为在不同的关系下实体应该有不同的表示[13]。Lin 等人提出了TransR 模型,此前的TransE 和TransH模型都假设实体和关系在同一个空间,但是不同的实体有不同的属性,不同的关系也侧重于实体中不同的属性,TransR的思想是先将实体从实体空间投影到关系空间,再对两个投影过后的实体进行平移操作。
3 词对知识向量获取
3.1 融合多特征及有监督的词对关系向量获取
主要研究的是在基于注意力机制和词到词推理的文本蕴含识别框架下,如何得到词对之间的关系,从而帮助识别整个句子的类别。这里的输入是句子之间的词对,输出是关系类别的概率分布,本质上也就是获得相关词对的向量表示,把之前从WordNet抽取得到的关系词对作为监督信息,构造分类器分类。
Glockner 等人通过词汇替换构建了需要词汇推理的数据集,之前的经典方法例如DAM以及Chen等人提出的ESIM在准确率上都出现了很大的下降,证明根据之前的SNLI数据集训练得到的文本蕴含模型不具有鲁棒性,词向量本身学习词汇关系的能力也受到质疑,所以目前的想法是希望通过例如Wordnet、FreeBase 等知识库学习到词对之间的推理关系。这里加入了三大类特征:一种是词中字符特征;第二种是加入了词之间的数学操作,为了加强词之间的比较过程;第三种是同义词簇特征,增加引入到神经网络的信息。如图1 所示,分为如下5个层次。

图1 基于有监督词对匹配模型
(1)融合字特征的词编码层
在加入Pennington等人预先训练好的Glove词向量的基础上[14],本文又加入了词字符特征。因为英文的词根特点,unknonw-know和unable-able构成反义词,在字符特征上有明确的特征,模型上本文借鉴了文献[15]在基于字符级卷积神经网的文本分类中提出方法,即采用Char-CNN对词的字符序列做表示学习,使用CNN对字序列抽取特征,本文使用多种维度卷积核进行单个字、相邻两个字的特征抽取,并使用多个过滤器filter,maxpooling做特征筛选,从而得到字符向量,再通过全连接层进行维度转换。其中,设置50维的字符向量表示,与词向量拼接得到最终的词表示。
(2)词簇编码层
实验发现,单独的词对信息量较少,不足以建模知识库中复杂的关系,另外无法利用词之间的关系,所以本文想到词簇的概念,引入词的同义词集的信息。通过WordNet 的同义关系,分别得到词a 和词b 的5 个同义词,同样借助卷积神经网和最大池化作为特征抽取器,抽取得到词簇向量,与之前得到的词向量拼接。
(3)投影层
该层作为词向量的映射,因为选择不修改词向量进行训练,因此加入了投影层,希望学习到词关于词对关系的向量表示,相比加入多层神经网络,本文选择加入highway 网络,原因是实验结果显示加入此结构效果相比全连接层较好。公式(1)中的WH表示隐层投影矩阵,之后又把输入词直接加入到输出中,类似LSTM网络结构中的输入门,能一定程度引入输入的信息,降低深度网络的梯度爆炸情况。

(4)比较层
受到Word2vec 中词类比的灵感,即:king-man+women=Queen,直觉上认为词汇关系也存在类似现象,同时也是对词之间差异的建模,所以将“词1-词2”、“词1*词2”这两个特征加入到输入中,更多地表示出两个词之间的相似程度。
(5)分类层
这里分类层使用多层神经网络加上Softmax进行分类。因为训练数据是多关系分类,即两个词对应多个类别,是多标签分类,有的词对既构成同义词关系,又构成同位词关系。公式(2)中的损失函数选择Hamming,表示样本数,nlabels表示标签数。

3.2 TransR词对关系表示获取
首先提出有效地构建知识图谱向量表示的是TransE 模型,对于知识图谱中的三元组(head,link,tail),其中head表示头实体,link表示实体对之间的关系,tail表示尾实体,TransE 的动机是希望把实体和关系建立在一个向量空间内,同时受到Word2vec中的平移不变性的激发,这里目标是让头实体和关系向量的和尽量与尾实体相接近,同时通过负采样构造负例让负例的距离足够得大。损失函数如公式(3)所示,通过这个损失函数,可以学习到实体和关系向量。但是通过实践发现,TransE 对于一对一的关系能很好地建模,但是对于WordNet 中常见的一对多或多对一的关系并不能进行很好地建模。
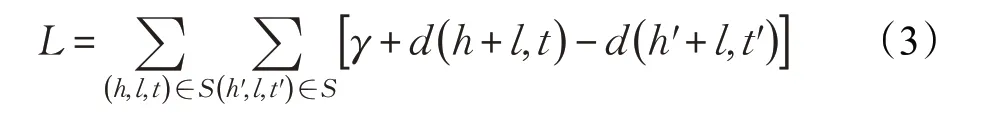
但是根据此前Chen 等使用TransE 的经验,发现在文本蕴含模型中作用并不大。Chen 等人分析是因为TransE 并不能建模“同位词”,或者是SNLI 测试集中不需要词汇推理,但是深入分析发现,TransE 并不那么适合建模WordNet中多对一和一对多的关系,特别针对想建模的同位词就是一对多的关系。例如水果和下位词苹果、香蕉的关系都是下位词,那么香蕉和苹果的实体向量就会非常近,因此选择了TransR 作为替代,TransR在TransE 的基础认为实体在不同关系的预测应该有不同的表示,这里为每个关系引入一个矩阵Ml,把实体向量映射到关系空间,如公式(4)所示:
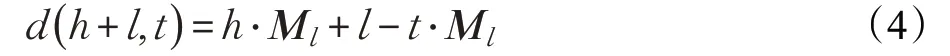
3.3 反义词向量表示获取
为了完善整个句子的推理能力,迫切地需要引入具有反义知识的词表示,根据调研发现有很多关于反义词检测的研究,这里主要是参考Ono等人提出的反义词建模方法[16]。该方法的思想很简单,词A和词B构成反义关系,所以词A 就和词B 的同义集中所有词构成反义;同理词A和词B构成同义关系,则词A和词B的所有同义词集构成同义关系。主要方法是通过降低训练集合中的反义词对之间相似度,以及增大同义集合相似度而得到。
首先,定义一个损失函数,如公式(5)所示。其中,V表示全体词的集合;Sw表示词w的同义词集合;Aw表示词w的反义词集合;sim(w,a)表示词w和词a的相似度。最终的目标是最大化这个目标函数,公式第一项是词w和它对应相似词的ln 概率之和,公式第二项是词w和词w对应反义词集的ln 负概率之和,目标是建模同义词的同时,也建模反义词,w是词w对应的词表示,在模型训练的同时参与参数的更新。
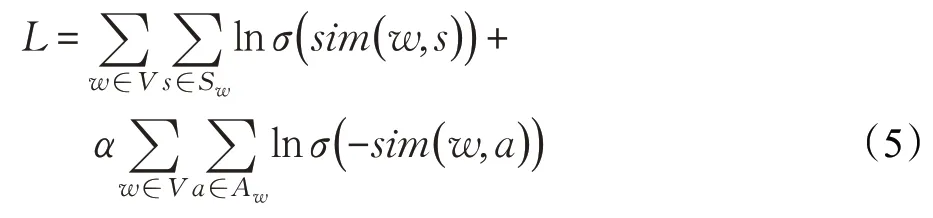
在向量词之间相似度的函数设计上,本文引入了一个非对称的相似度评价函数,使用点乘信息,即两个词的向量的点乘标量结果。另外对于两个词输入的顺序的不同,加入了一个偏置变量bw1,具体如公式(6)所示:

因为在比较操作中也有两个向量之差,然后取最大值作为差异性的变量,所以本文对相似性表达式进行了更新,如公式(7)所示。这样有助于在之后的词对比较中更好的表示出反义词。

4 文本蕴含识别模型
本文将第3章中提出的3种词对知识向量获取方法引入到文本蕴含识别模型中的词对齐和注意力机制部分,构建新的文本蕴含识别模型。
4.1 融合多特征及有监督的词对关系向量
在计算Attention时,假设句对中的两个对应的词a和词b满足指定关系中的一种,则引入神经网络的Attention值计算中加入一个权重λ。λ是一个超参数,在实验中设置的范围在0.001,0.01,0.1,1,10,20,50之间,表示引入知识向量的强度。如公式(8)所示:

其中,rab表示词a和词b的外部知识向量,引入方式是将两个词输入到词对关系预测模型中。
因为使用的是多标签分类,每个位置代表的是对应类别的概率,而每个类别对推理的权重需要学习,因此在公式中设置一个变量W ,这个变量的维度和关系向量维度相同,每个位置代表的是推理中这个维度的权重大小。
4.2 TransR词对关系表示
对于TransR的实体向量,按照之前的说明,头实体、尾实体之差为实体向量,因为在Attention 层,其实是希望输入两个词,得到这两个词的相关度或匹配权值,如公式(9)所示:

按照TransR的算法,首先将实体向量在每个关系空间内投影,例如:此前va维度是[1,100],在18个关系后投影是[18,100]的矩阵,表示向量在18 个关系下的投影,其中矩阵M 的维度是[18,100,100],是每个关系对应的实体投影矩阵。在va-vb后,得到的是在对应关系投影矩阵下的关系向量,之后再将这个关系向量和每个关系向量作乘积,就得到了对应关系的标量,也就是预测的关系向量[18,100],和真实关系向量[18,100]中的每个作乘法,最后得到了[18,100]的向量,每一个位置可以表示这个词对是这个关系的概率,最后与类别权值向量W 做乘法,得到了一个注意力标量。
4.3 反义词向量表示
对于反义词向量,根据反义词的向量乘积分布,对于同义词两个向量点乘接近1,对于反义词两个向量点乘接近-1,而无关系的词接近于0,因此加入两个向量乘积的绝对值,作为增加的偏置,如公式(10)所示:

Chen等人直接添加上有相关的实体向量的权值αai的求和,目的是想更多地引入对齐向量的权重信息,相当于引入了一个软对齐加权的特征向量求和。实际上是找到词对后,得到词对的关系向量,Chen等人提出的KIM方法的计算方式如公式(11)所示:

其中,ca表示假设句中词αai相对于整个前提句的表示,vai表示之前获得的词对向量,前提往往是已知两个词对存在关系然后判断两者的关系。
5 实验与分析
5.1 知识向量获取
5.1.1 词对关系向量
本文主要使用的词汇资源是WordNet,WordNet 是一个英文单词数据库,每个同义词集合对应一个基本的语义概念,并通过同义词集之间的语义关系链接在一起,于1985 年由普林斯顿大学创建,本文使用的是2012 年WordNet 3.1 版本,包含九类词汇结构:上下位关系(动词、名词)、蕴含关系(动词)、相似关系(名词)、成员部分关系(名词)、物质部分关系(名词)、部件部分关系(名词)、致使关系(动词)、相关动词关系(动词)、属性关系(形容词)。该资源包含155 327个词,175 979个同义词集,构建得到207 016 个词集对。为了便于构建词对关系识别模型训练集,从WordNet中抽取的词汇关系数量如表2所示。其中,同位词是为了文本蕴含任务设计的一种词汇关系,将具有相同上位词构成的词对称为同位词(co_hyponyms),以表示一种互斥的关系,这在“对立”推理中有重要应用。

表2 基于有监督词对匹配训练集
实验结果表明,加入多文本特征词对扩展的词对检测模型,相比只使用预训练词向量的基本模型准确率有明显提升,在5分类中达到了76.8%,结果如表3所示。

表3 基于有监督词对匹配结果
5.1.2 TransR知识向量
在使用TransR向量化WordNet知识库中,本文利用Bordes 等人提出的WN18 数据集,详细信息如表4 所示。该数据集包含18种关系,例如:上位词、下位词、蕴含词、反义词、包含词等,共有40 943 个实体,每个词原由至少一个词构成,共包含117 374 个词汇。WN18 主要的数据格式以三元组的方式,即:头实体、尾实体、关系,构成一个样本,该数据集广泛应用在知识向量化模型中,具有较广泛的应用价值。

表4 基于TransR实体学习训练数据
TransR评价指标有两种:其一是MeanRank,该方法保持头实体不变,尾实体依次替换成实体表中的所有实体,构成的样本进行预测,按照损失降序排序,所有正确尾实体在其中的排序均值作为指标;另一个是Hits@N,表示正确的实体排序在前N的概率。本文采用公式(12)的计算方法,通过遍历所有关系,找到一个损失最小的作为最终的词对关系向量。

相关实验表明,在需要预测的18 个关系中,TransE构建的关系MeanRank 为3.92,而TransR 平均排名达到了1.24,远高于TransE的结果。后面又统计关系排名在前2 的文本,达到了80%,这证明了TransR 得到的词对关系的可用性,结果如表5所示。

表5 基于TransR实体学习训练数据
5.1.3 反义词向量
在反义词向量表示的任务中,使用Mohammad等人提出的GRE 数据集[17],其中开发集为162 条,测试集为950 条。评价任务是每个目标词有5 个候选词,系统在候选词中返回相对目标词反义最强烈的词,按照之前的非对称相似度计算公式,来计算两个词的相似度,然后从中选择得分最小的词作为输出的反义词,为了进行对比实验,首先使用Glove 词向量作为基准模型,其中同义词对数为881 870,反义词对数为307 464。
在反义词向量建模任务中,本文针对GRE 三个任务集分别进行测试,结果表明,使用预训练Glove 词向量的效果明显低于使用反义词建模的结果,也证明了进行反义词建模的可用性。另外,针对预训练词向量对同义词数据集和翻译词数据集分开做了实验,并对词对的相似度进行了统计,结果如图2所示。

图2 反义词向量和Glove向量对比分布
图2 中,上半部分分别是预训练词向量的结果,横轴是相似度,纵轴是计数,可以看到同义词对的相似度成正态分布,因此并不能捕捉同义信息,同样反义词也类似。下半部分为训练好的反义词向量,清楚地表明,通过点乘的方式计算的相似度能明显区分同义词和反义词。
表6是反义词向量模型在GRE数据集中的结果,这里的Glove 代表的是直接使用预训练词向量与反义词向量模型对比,实验表明通过反义词向量训练得到的词向量能较好地区分反义词,可以作为知识资源引入到模型中。

表6 反义词向量实验结果 %
表7是本文给出的反义词向量结果样例,这里挑选了实验过程中的常见词对,可以看到使用Glove 词向量,通过计算向量夹角不能区分男人和女人、好和坏的反义关系,而反义词向量则能进行区分。

表7 反义词向量结果样例
5.2 融合知识向量的文本蕴含识别
首先,在英文数据集SNLI上,将Parikh等人提出的基于分解注意力的文本蕴含模型(本文简称为DAM)作为基线结果,分别比较了加入有监督词对向量、TransR知识向量以及反义词向量的文本蕴含模型,实验结果如表8所示。

表8 反义词向量实验结果
表8 中的DAM 是分解注意力模型,其他知识向量都是在此基础上加入。可以看出,加入反义词向量的文本蕴含模型提升较大,但是整体上在SNLI 的数据集上提升不明显。尝试了在ESI模型中加入知识向量,效果也不明显,分析可能是模型的复杂度较高,引入知识向量的难度较大造成的。
从570 000的人工手写英文句子对训练集中抽取了1%的数据进行训练,发现引入反义词向量虽然在之前的全量SNLI 训练集上没有效果,但是在“低资源”的条件下能提升模型的收敛速度和准确率,如图3所示。加入了反义向量的ESIM 模型准确率由60%提升到66%,证明反义词向量在数据量较小的条件下能一定程度地提升模型的效果。
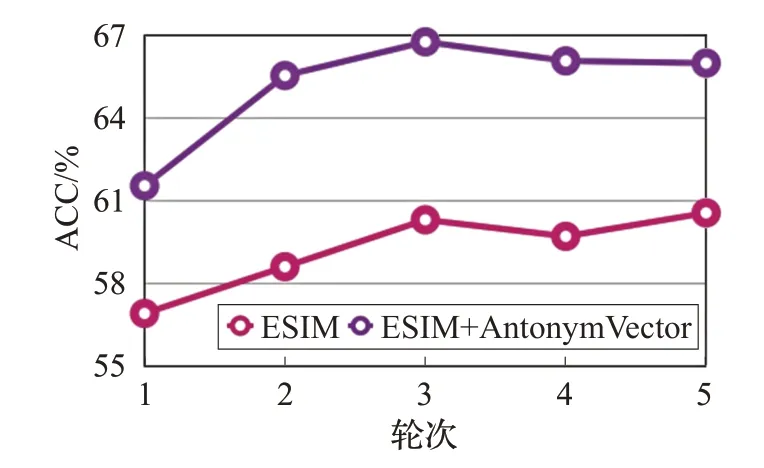
图3 SNLI1%数据集测试
其次,针对Glockner 等人提出的BreakNLI 数据集进行了测试,这个数据集就是针对词汇推理的数据集,该测试集有一个特点,因为构建数据集时是取前提句,将其中的部分词替换成同义词、反义词来依次构建蕴含、对立关系,因此相比SNLI的训练集前提句和假设句较为接近,很容易判断为蕴含关系,因此这就对反义词这种关系的识别能力提出了更高的要求。实验结果如表9所示,在基于分解注意力模型上依次添加三种知识向量表示。
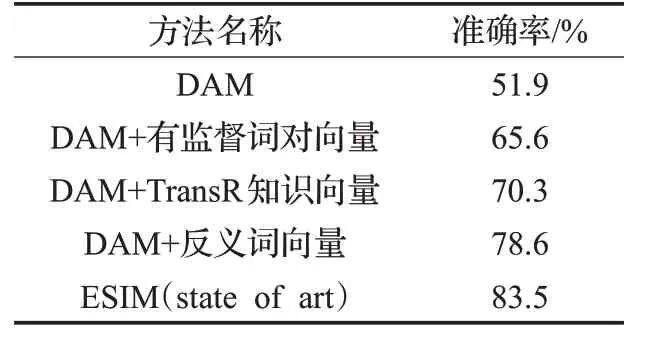
表9 反义词向量实验结果
可以看出,加入有监督学习的词对向量表示提升不大,可能的原因是使用分类向量作为关系向量,能表示的信息较少。引入反义词向量,模型的效果提升最大,可能的原因是通过对反义词建模,能通过向量之间的点积有效表示词对之间的关系,对反义推理的提升明显。进一步分析改进后的结果,有部分样例得到更正:在样例“korean”和“indonesian”的对立关系中,它们有共同的同位词“国家”会被识别成同位词;“south”和“north”是一种常识对立关系;“little”和“tiny”需要同义词信息;还有反义词向量能明显建模的“near”和“far”。
6 结论
在词对知识向量提取方面,相比关注度很多的词向量,本文更多关注词对的向量表示。在充分调研的基础上,本文首先提出了基于有监督和文本特征的词对关系分类模型,将词对关系分类的结果,也就是在各个类别的分布作为词对向量表示;其次,借助成熟的知识库向量化工具TransR对WordNet中的知识向量化,得到的实体向量作为具有知识的词表示,实体之间的差值作为词对表示;最后又专门针对文本蕴含中的反义词和同义词,构建反义词向量,得到新的词向量,将两个词向量的乘积作为表示反义和同义程度的表示。在构建这三种词对向量表示中,均有相应的数据集证明其表示的可用性,同时证明了相比预训练词向量在词对关系上的优越性。
