面向文本分类的transformer-capsule集成模型
2020-12-26王志舒冯美姗鲁明羽
唐 庄,王志舒,周 爱,冯美姗,屈 雯,鲁明羽
大连海事大学 信息科学技术学院,辽宁 大连116026
1 引言
文本分类是自然语言处理领域中一个经典问题,其核心任务是对文本的合理建模,提取到文本的特征表示,以便把数据集中的每个样本划分到正确的类别中去。
由于深度学习神经网络模型具有自学习、自适应和强大的泛化能力等优点,已被普遍应用于文本分类任务中。目前深度学习主流的神经网络模型包括卷积神经网络(Convolutional Neural Network,CNN)[1]、长短时记忆神经网络(Long Short-Term Memory Networks,LSTM)[2]以及两者的各种变体。CNN通过固定窗口大小的卷积核一次滑动多个单词,提取到局部短语特征,然后用最大池化选择最显著的特征,这会过滤掉许多底层信息。Sabour 等人提出胶囊网络(Capsule network)来解决上述信息损失问题,用矢量胶囊代替标量神经元[3]。
虽然胶囊网络改进了传统CNN 中的最大池化操作,但本质上依旧是通过卷积提取到文本的局部短语特征,忽略了上下文序列对当前词的影响;transformer 作为一种新型的网络模型,可以一次性遍历整个文本序列从而提取到全局语义特征,已广泛应用于序列编码-解码任务中[4],但缺点是面对长文本时不仅费时,且没有考虑到局部关键词对文本分类的重要性,难以捕获局部短语特征。本文结合了transformer 和胶囊网络两种模型各自的优点,通过集成的形式将两个模型分别提取到的局部短语特征和全局语义特征进行融合,从局部到全局两个层次对文本序列进行建模,从而提取到多层次的、更全面的文本特征表示。此外,本文针对传统胶囊网络模型中存在部分噪音胶囊干扰的问题,提出了基于注意力机制的动态路由算法,使得分类效果进一步提升。
2 相关研究
早期的文本分类任务采用词袋模型、N-gram和TFIDF 等特征作为各种分类算法的输入[5],如支持向量机(SVM)[6]、逻辑回归[7]、朴素贝叶斯[8]等。然而,特征提取过程不仅存在数据稀疏和维度爆炸问题,且随着数据量增大,处理海量数据过程会费时费力。
近年来,深度学习神经网络模型已被广泛应用于文本分类任务中。神经网络模型能从原始的数据中自动提取有用的特征,大大提高了文本分类任务的性能。Kim等人首次将卷积神经网络应用到文本分类任务中,提出了textCNN模型,该模型利用多个不同大小的卷积核提取句子的短语信息[9]。textCNN模型需要使用预训练好的词向量等信息,针对该问题,Zhang 等人提出字符级卷积神经网络CL-CNN,从字符层面训练神经网络,该方法的优点是不需要使用预训练好的词向量以及语法句法结构等信息[10]。Joulin等人提出快速文本分类算法fastText,该算法在保持较高分类精度的情况下加快了模型训练速度[11]。Conneau等人提出了一个具有29个卷积层的深度卷积网络VD-CNN用于文本分类,加深了网络结构[12]。张越等人在大规模弱监督数据上训练CNN模型,同时引入“预训练-微调”策略,减少了弱监督数据中的噪声干扰[13]。CNN 通过卷积提取到文本的局部短语特征,而LSTM则解决了循环神经网络中存在的长期依赖问题,主要针对时序性文本序列。Tai 等人结合了LSTM 和树形网络,提出了Tree-LSTM 模型,该模型在两个文本分类任务中取得了不错的效果[14]。传统的LSTM网络以时间顺序处理文本序列,但忽略了下文信息对当前词的影响,Zhang 等人提出双向LSTM 网络用于文本分类,该网络引入逆序遍历的LSTM 层,将每个单词前向和后向传递的信息合并,进一步提高分类效果[15]。李梅等人提出一种基于注意力机制的CNNLSTM 联合模型,将CNN 的输出作为LSTM 的输入,然后进行分类预测[16]。
除了CNN、LSTM 这两种网络模型,Sabour 等人在2017年底提出了一种名为胶囊网络的新型神经网络,用矢量输出胶囊代替了CNN 的标量输出神经元,并用路由协议机制代替了CNN 中最大池化操作,在图像领域MNIST 手写字符识别数据集上取得了很好的分类结果[3]。Zhao 等人在2018 年底首次将胶囊网络引入文本分类任务中,在多个数据集上分类性能超过了CNN 和LSTM[17]。

图1 集成模型框架图
3 transformer-capsule集成模型
基于transformer-capsule 集成模型的文本分类框架如图1 所示,以处理Reuters-21578 数据集为例,本文提出的模型包括以下四个部分:向量表示、特征提取、特征集成以及文本分类。
(1)向量表示:使用预训练的词嵌入数据库word2vec,将原始文本序列映射为300维的词向量矩阵。
(2)特征提取:将词向量矩阵作为胶囊网络和transformer 的输入,其中胶囊网络首先用256 个3×300 的卷积核、步长为2 做卷积运算,经过挤压函数后形成16 维主胶囊层,经过一次基于注意力机制的路由协议后连接分类胶囊层,得到文本的局部短语特征;而transformer模型通过增加单词位置编码、残差连接、层归一化、前馈连接等操作处理输入序列并将序列信息压缩成固定长度的语义向量,提取到全局语义特征。
(3)特征集成:将提取到的局部短语特征和全局语义特征进行拼接融合,综合得到文本的词法、句法和语义信息。
(4)文本分类:通过一层全连接层将集成特征输入到分类器中,单标签分类用softmax分类器,多标签分类用sigmoid分类器。
transformer-capsule 集成模型框架图中采用上下双通道的形式对文本序列进行建模,上通道为胶囊网络模型,下通道为transformer 模型,下面对这两种模型进行介绍。
3.1 transformer模型
传统的LSTM 由于在序列化处理时依赖于前一时刻的计算,并行效率低,模型运行速度慢。transformer模型通过多头自注意力机制可以在并行计算的同时捕获长距离依赖关系,充分学习到输入文本的全局语义信息。transformer 模型主要用于seq2seq,采用编码器-解码器结构,本文用作文本分类任务只用到了其中的编码器结构,通过增加单词位置编码、残差连接、层归一化处理、前向连接等操作处理输入序列并将序列信息压缩成固定长度的语义向量。transformer 模型中位置编码计算公式如下:

其中,pos是指当前词在句子中的位置,i是指向量中每个值的索引,dmodel是指词向量的维度,在偶数位置使用正弦编码,在奇数位置使用余弦编码。将位置向量与词向量相加得到融合词向量,丰富了文本词向量的表示。transformer模型中多头自注意力机制计算公式如下:
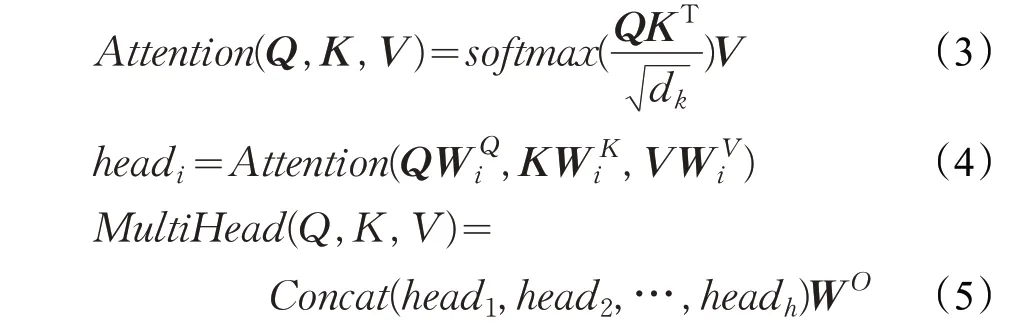
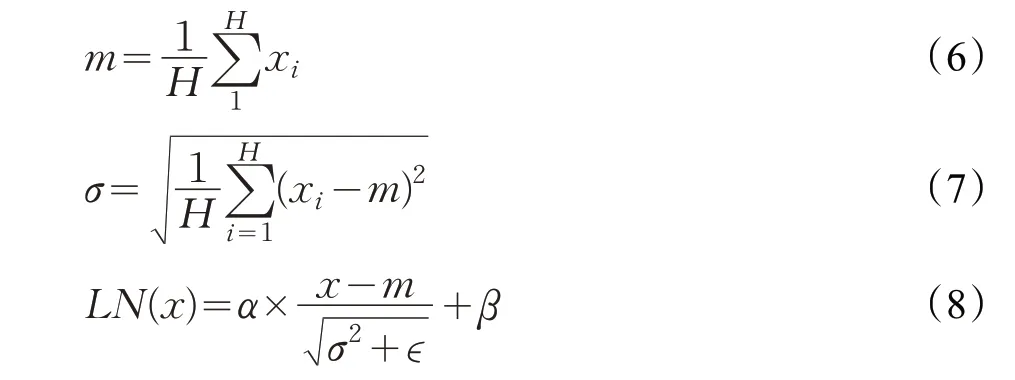
其中,xi表示融合词向量x 的第i维,m表示输入x 的均值,σ表示输入x 的标准差,α、β是可学习的参数,ϵ是为了防止除数为0 而设置的小数。层归一化旨在增强反向传播信息流动性,加快训练收敛速度,解决网络训练困难,难以拟合的问题。transformer模型中前向连接计算公式如下:

其中,y是经过层归一化后的输出向量,e为偏置项。在多头自注意力模块后跟两个全连接,中间加一个relu激活函数,构成双层前馈神经网络。
3.2 胶囊网络模型
传统的CNN通过卷积核来提取文本序列的底层局部短语特征,最大池化操作虽然减少了网络层神经元数量,但却造成了信息损失。胶囊网络使用一组向量神经元(胶囊)来替代传统神经网络中的标量神经元节点,改变了传统神经网络标量与标量相连的结构。在各个网络层中每个胶囊携带的信息从1 维增加到了多维。下层胶囊通过动态路由机制(Dynamic Routing)将该层胶囊保存的计算结果传递给上层胶囊,从而实现在提取局部短语特征的同时减少信息的损失。
由于文本中存在着与分类标签无关的词语,比如停用词和连接词等,下层胶囊中不可避免地会出现噪音胶囊,这些胶囊携带的信息对分类结果的准确性会造成一定的影响,因此本文对传统的动态路由机制做出了改进,提出基于注意力机制(attention)的动态路由算法,利用两层全连接神经网络产生每个胶囊的注意力值,归一化后作为最终的注意力值,再乘以原始胶囊的输出。这样可以降低噪音胶囊的权重,减少噪音胶囊传递给上层胶囊的信息。动态路由算法描述如下:

其中,sj为上层胶囊的输入,u为下层胶囊的输出,M为相邻两层之间的权值矩阵,cij为耦合系数,表示下层胶囊i激活上层胶囊j的可能性,bij初始值设置为0,通过动态路由更新cij从而更新bij,挤压函数squash 及更新bij的计算公式如下:
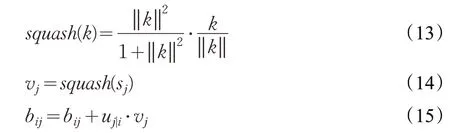
其中,vj为上层胶囊的输出,由于胶囊输出向量的模长代表类别的概率值,挤压函数将向量的模长限定在[0,1]区间,输出向量的模长越大,代表文本所属该类的概率越大。
3.3 模型集成
胶囊网络在提取文本局部短语特征的同时减少了信息损失,transformer单元通过自注意力机制遍历整个文本序列,从而提取到全局语义特征。本文采用的集成模型可以结合胶囊网络和transformer各自的优势,综合考虑到文本的局部短语信息和全局语义信息,提高分类效果。
由于分类标签数固定,胶囊网络和transformer具有相同的输出维度,因此本文在模型集成阶段采用合并拼接的方式,即拼接两种网络生成的特征向量,再通过一层全连接层映射到最终的分类向量中。假设胶囊网络的输出向量为HC=(hC1,hC2,…,hCn),transformer 单元的输出向量为HT=(hT1,hT2,…,hTn),集成后的特征向量为H ,计算公式如下:
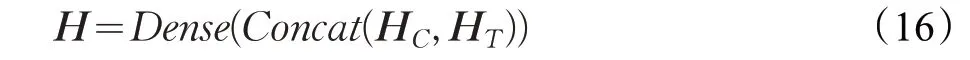
其中,Dense是一个映射到类别数上的全连接层。对于单标签数据集,对集成后的特征向量H 使用softmax分类器得到每个类别的概率值,选择其中数值最大的对应类别为预测的分类类别;对于多标签数据集,对特征向量H 使用sigmoid分类器,设置阈值为0.5,所有概率值大于该阈值的则给该样本添加对应的标签。
4 实验与分析
本文在4个单标签数据集和1个多标签数据集上进行实验,单标签数据集包括电影评论MR(Movie Review)、观点分类Subj(Subjectivity dataset)、问题分类TREC(TREC question dataset)和新闻分类AG。多标签数据集为路透社新闻语料库Reuters-21578。各个数据集划分为训练集、验证集、测试集以及类别数,如表1所示。
4.1 实验设置
本文实验基于TensorFlow实现,使用300维word2vec向量来初始化词嵌入向量,使用Adam 优化器,学习率为0.001,模型具体超参数设置如表2所示。

表1 数据集类别划分

表2 实验超参数设置
4.2 评价指标
本文实验中单标签数据集分类性能评价指标是分类精度(Accuracy),多标签数据集评价指标包括准确率(Precision)、召回率(Recall)、F1 值(F1 Score),F1 值计算公式如下:
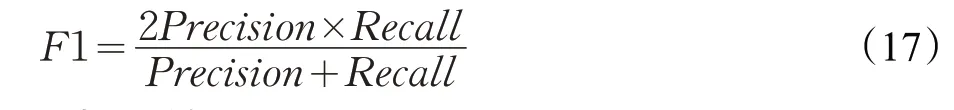
4.3 实验结果
为验证本文提出的transformer-capsule 集成模型的有效性,本文在单标签对比实验上选取深度学习领域比较主流的几个基线模型:LSTM、BiLSTM、Tree-LSTM、CNN、CL-CNN、VD-CNN,在多标签Reuters-21578 数据集上添加了胶囊网络Capsule-A、Capsule-B以及具有代表性的机器学习模型Binary Relevance(BR)[18]、Classifier Chains(CC)[19]、Label Powerset(LP)[20]进行实验。两个胶囊网络模型都采用了较复杂的两次路由迭代机制,唯一区别是两者在N-gram 卷积时N的取值不同。Capsule-A 中N取值为3,每次滑动三个单词,而Capsule-B 中N分别取值3、4、5,最后结果为三种取值下各自实验结果的平均值。本文的capsule模型简化了一次路由操作,因此减少了一层卷积胶囊层,但结合了注意力机制,大大缩短了实验时间。
实验中四个单标签数据集分别为MR、Subj、TREC和AG,实验结果如表3所示,表格内容为分类精度。多标签Reuters-21578数据集评价指标为准确率、召回率和F1 值,实验结果如表4 所示,其中加粗数值为该数据集的评价指标在所列模型中的最大值。
从表3和表4可看出,与传统的CNN和LSTM等神经网络模型相比,本文提出的transformer-capsule 集成模型在三个单标签数据集上分类性能较好。在Reuters-21578 多标签数据集上,本文提出的transformer-capsule集成模型在三个指标准确率、召回率以及F1 值上相比于传统的CNN和LSTM等神经网络模型以及机器学习模型性能提升很多,其中在F1 值上相比于胶囊网络Capsule-B模型提升了3.6%,并且本文的模型在保证高准确率的同时其召回率相比于Capsule-B模型提升了6.0%。
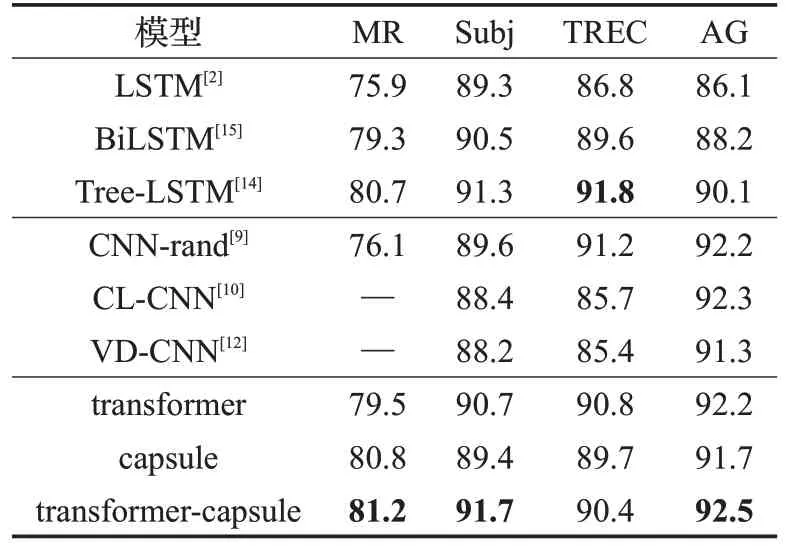
表3 单标签数据集分类精度 %
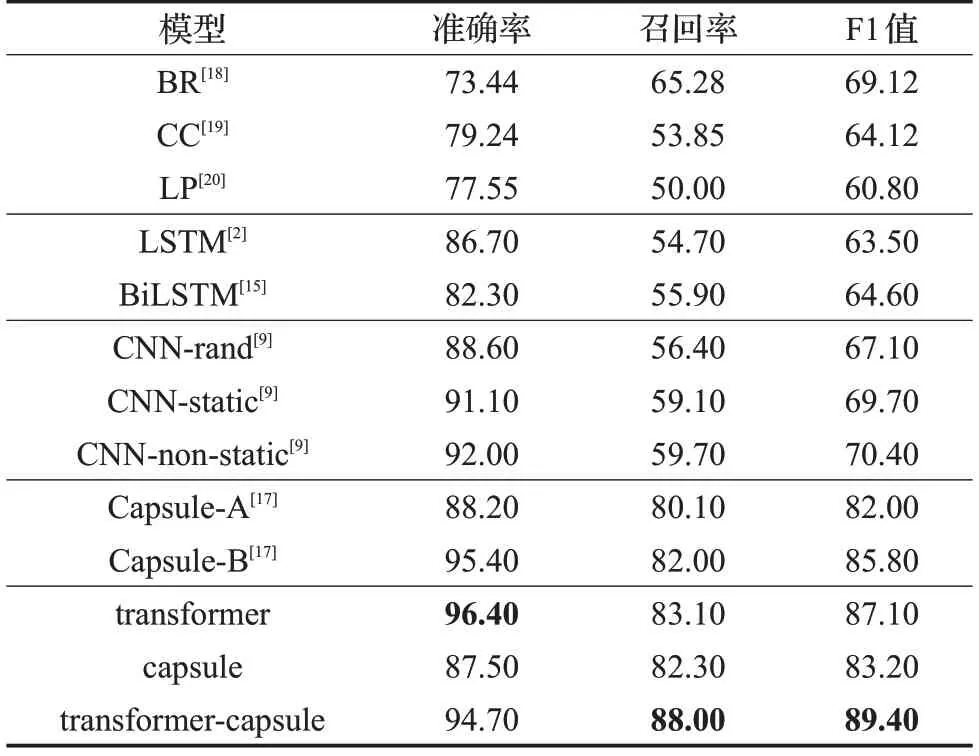
表4 Reuters-21 578数据集准确率、召回率及F1值%

图2 P值、R值、F1值随路由次数变化图
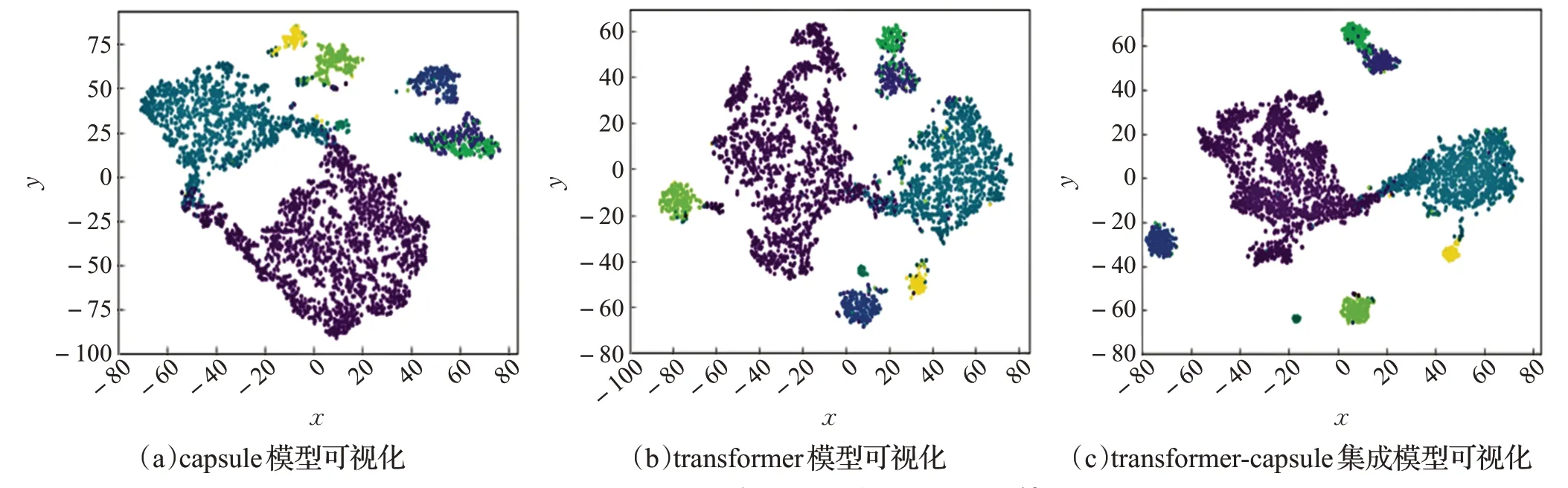
图3 Reuters-21578数据集上文本特征可视化结果图
为了验证本文提出的基于注意力机制的动态路由算法的有效性,在Reuters-21578数据集上设置了两组对比实验,对transformer-capsule 集成模型分别使用原始路由算法(routing)以及基于注意力机制的动态路由算法(ATT-routing)进行实验,准确率P 值、召回率R 值和F1 值随路由迭代次数的实验结果分别如图2 中(a)、(b)、(c)所示。
从图2(a)中看出,使用原始路由算法和基于注意力机制的动态路由算法的transformer-capsule集成模型在第二次迭代时的分类准确率最高,但随着路由次数增加,原始路由算法的准确率迅速下降,而使用注意力机制的路由算法则相对平稳。从图2(b)和(c)看出,路由迭代次数设置为3时的分类性能最好,且基于注意力机制的动态路由算法在每次迭代时的R值和F1值都要明显优于原始路由算法。
为了得到一个更直观的比较结果,在Reuters-21578数据集上进行了结果可视化实验,使用t-SNE算法分别将transformer、胶囊网络capsule以及transformer-capsule集成模型学到的文本特征映射到二维空间进行对比,实验结果分别如图3中(a)、(b)、(c)所示,每种颜色代表一个类别,每个节点代表所属该类的一个样本。
从图3中看出,单独胶囊网络学到的文本特征效果不是很好,多个类别样本之间存在着高度重合情况,而transformer 模型存在的缺点是类内样本点分布较为散乱。从图3(c)中看出,transformer-capsule 集成模型学习到的文本特征更加丰富,不仅类间样本重合较少,且具有高度类内聚合性,这表明该模型能够有效地结合胶囊网络以及transformer的优点,充分学习到文本的局部短语特征和全局语义特征。
5 结束语
本文针对文本分类任务,提出了一种基于transformercapsule的集成模型,在几个文本分类通用语料数据集上获得了较好的性能。胶囊网络可以有效地捕获文本中的局部短语特征并且减少信息损失,transformer通过多头自注意力机制遍历整个文本来提取全局语义特征,通过特征集成得到文本的多层次、更全面的特征表示。此外,本文针对文本中存在停用词等与分类结果无关词语形成噪音胶囊的情况,提出基于注意力机制的动态路由算法,降低噪音胶囊的权重,减少其传递给后续胶囊的干扰信息,有效地提升了分类性能。
