基于DeepLab V3模型的图像语义分割速度优化研究
2020-12-26司海飞胡兴柳杨春萍
司海飞,史 震,胡兴柳,杨春萍
1.金陵科技学院 智能科学与控制工程学院,南京211169
2.哈尔滨工程大学 智能科学与工程学院,哈尔滨150001
1 引言
在移动机器人等移动端系统中,快速精准的环境感知是研究重点。为了实现快速准确地理解外界环境,让移动端有效精准地实现人机及场景交互,传统方法是给移动端搭配超声波、视觉传感器或者激光雷达等多种传感器获取四周的场景信息[1-3],即基于人工特征提取的图像语义分割。近年来,为了节省成本且不丢失任何场景相对的位置信息,大量学者致力于利用神经网络算法实现图像语义分割技术,为移动端的信息决策提供参考,达到准确理解环境信息[4-7]。
在2006年深度学习理论被提出后[8],卷积神经网络的表征学习能力得到了关注,并随着数值计算设备的更新得到发展[9]。美国加州大学的Long等[10]在全球首次提出了全卷积神经网络算法(Fully Convolutional Network,FCN)。此算法基于VGG-16 网络结构[11],舍弃了VGG的最后全连接层fc6和fc7,这种方法在精度和速度方面都大大超过了传统的分割方法,但对微小的物体分割还是有局限性。SegNet网络也是一种和FCN原理类似的方法,由Badrinarayanan等[12]提出,SegNet模型具有较少的参数,更容易进行端到端的训练,分割精度比FCN稍好一些,总体效率也比FCN略高。Noh等[13]基于SegNet公布了反置卷积(DeconvNet)模型,在特征映射方面取得优势,分割效果要比FCN-8S愈加精密和细致,但精度较差,模型的综合性能并不强。
DeepLab 网络是由Chen 等人与google 团队[14]于2014年提出的,是一个专门用来处理语义分割的模型。目前推出了4 个版本[15]:DeepLab V1、DeepLab V2、DeepLab V3、DeepLab V3+,它们是目前语义分割领域中最新颖优秀的一个系列分割算法。对于语义分割任务来说,DeepLab V3+算法已经能够满足高精度输出结果的要求,然而对于移动端的实时分割还远远不能达到要求。本文旨在保证精度的同时寻求更快的分割速度便于移动端设备的应用,基于DeepLab V3 算法进行改进和调优,设计出新的轻量化网络结构,在运行速度方面显著提升,能够使卷积神经网络更好地服务于移动端。
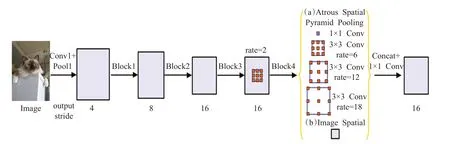
图2 DeepLab V3模型结构
2 DeepLab V3系列网络
2.1 DeepLab V3网络
V3 加入图像级别(image-level)的带膨胀卷积的空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)[16]。ASPP 是一种能够获取多尺度上下文的架构,能够让任意大小的特征图利用多尺度特征提取都有确定大小的特征向量来表示。获取上下文信息的ASPP手段方式如图1所示。
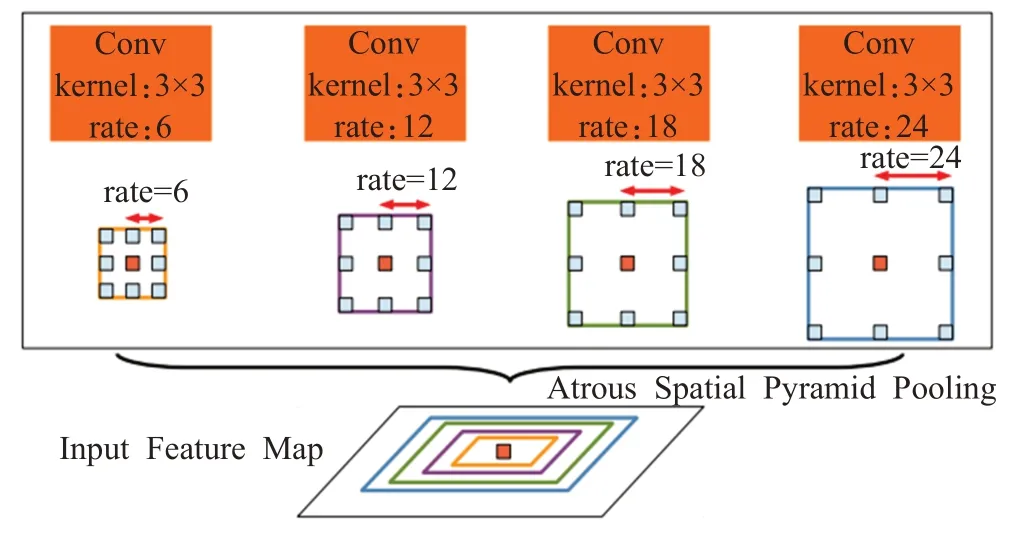
图1 ASPP模块
DeepLab V3编码部分采用预训练的ResNet-50/101来提取特征,DeepLab V3 模型结构如图2 所示。修改了第4 个残差块,采用膨胀卷积(模块内的三个卷积采用不同的膨胀率)方法,并且把批量归一化(BN层)加入ASPP模块进行优化。
2.2 DeepLab V3+网络
DeepLab V3+是把V3 作为编码部分的结构,添加了解码部分[17],构建了一个带空洞的空间金字塔池化编码-解码结构,如图3所示。先对输入的空间分辨率进行降采样,得到较低的分辨率特征图,经训练可快速地区分类别的特征图,然后进行上采样过程,再将特征表示为完整分辨率的语义输出图。
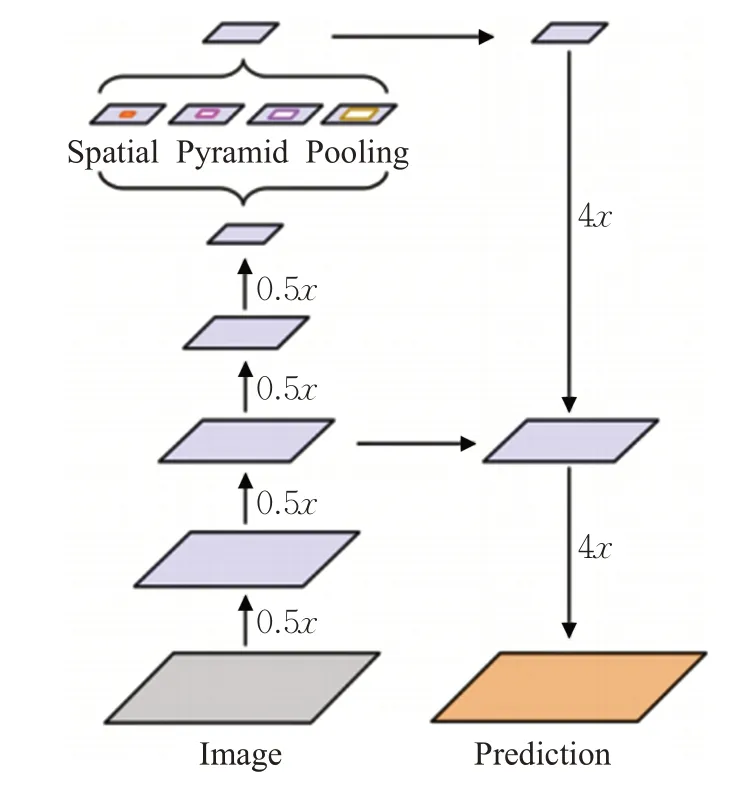
图3 DeepLab V3+编码-解码结构
DeepLab V3+特别注重目标边缘的分割,优化细分结果。而且,利用这种编码-解码的构造,可使准确率和运算时间综合性能最优,可以通过选择空洞大小更便捷地确定要提取的编码部分输出特征分辨率的大小。
DeepLab V3+总体模型结构如图4所示。DeepLab V3+采用将带空洞的卷积块并连在一起,作为编码部分,接着连接的是编码结构的ASPP模块,DeepLab V3+将深度可分离结构的Xception卷积改进应用其中,并且解码器模块同样应用到,使这种编码-解码结构的模型与V3 相比分割速度更快,分割性能更强。编码部分主干网络Xception 由Entey flow、大量的Middle flow 和Exit flow组成,且编码部分空洞rate大小采取6、12、18、24四个分支与一个池化层(最大化法)来控制特征图的输出率。因考虑到高采样比率提取的特征图信息较少,所以去掉最后一个分支,并且最大池化部分均采用stride=2 的深度卷积替换,每次深度卷积3×3卷积之后都引入了BN和ReLU。其次,在引入底层特征进行多尺度融合时全部首先采取1×1卷积对输出通道做降维操作。
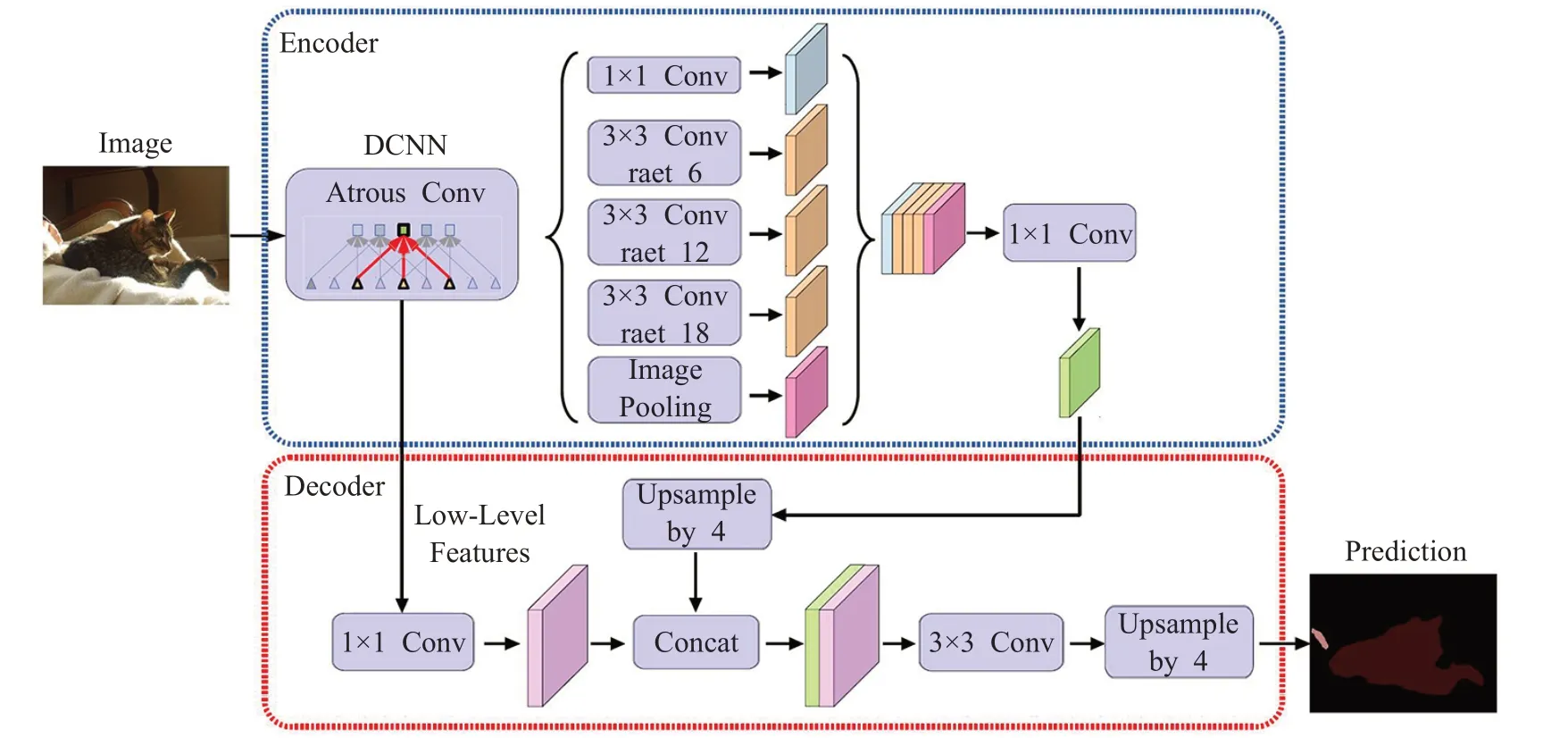
图4 DeepLab V3+的整体编码-解码模型结构
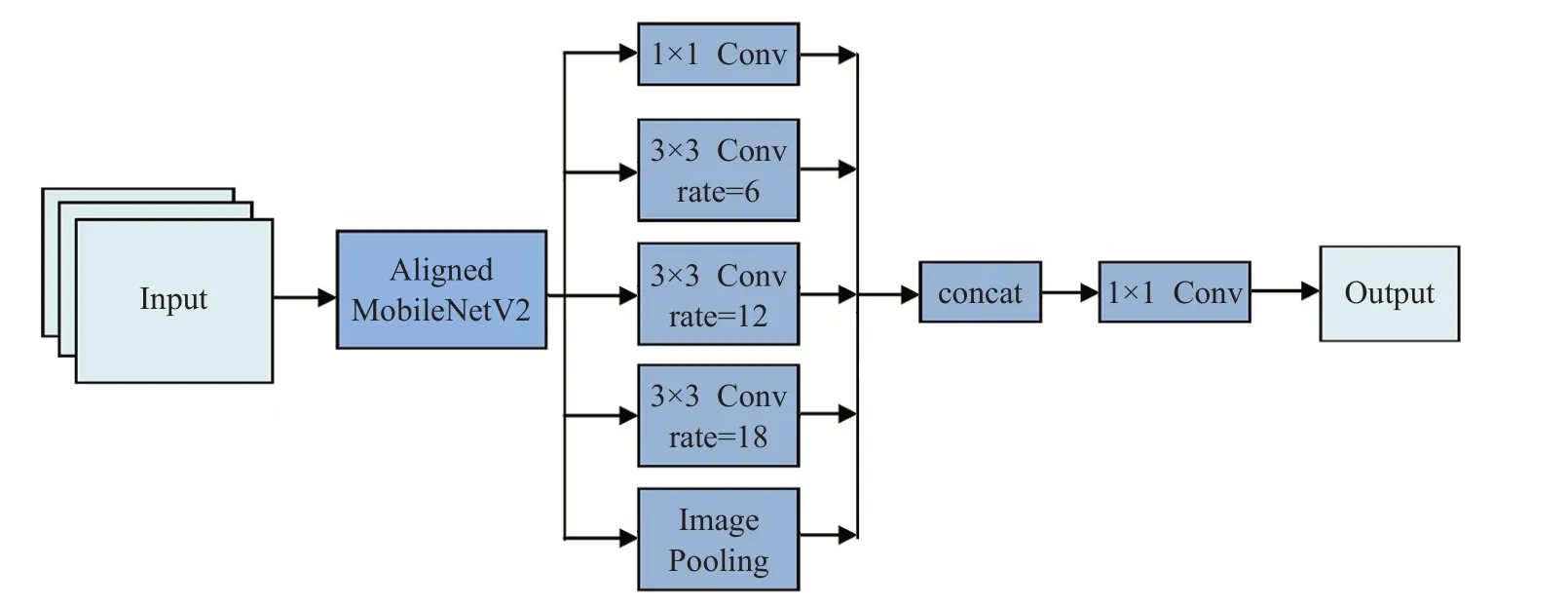
图5 改进的DeepLab V3网络结构图
3 改进的DeepLab V3网络
3.1 DeepLab V3网络的轻量化设计
对于语义分割任务来说,DeepLab V3+算法已经能够满足高精度输出结果的要求,然而对于移动端的实时分割还远远不能达到要求。本文为保证精度的同时寻求更快的分割速度便于移动端设备的应用,通过引入并改进了2017年由谷歌团队创作的一种适用于可移动设备的轻量化网络MobileNet[16],替换掉DeepLab V3模型编码部分的ResNet结构,没有解码模块,从而使DeepLab V3 网络变得轻量化,该网络可以大大减小计算量从而使运行速度方面效果显著提升,能够将卷积神经网络更好地服务于移动端。本文主要使用2018 年更新的V2版本。在面向以移动端为基础上进行的语义分割领域,MobileNet V2 无疑会是一个高效模型的首选。改进的整体网络结构如图5所示。
MobileNet V2 在深度卷积前面增添了逐点卷积的改进,之所以这么做,由于DW 卷积的输出通道数只由输入通道数决定,自身无法更改通道数。这面临的一个问题就是假如上层输出的输入通道数过少,则深度卷积仅仅可以对空间中维度较低的特征进行提取并且激活函数不可以有效地发挥在高维空间进行非线性变换提取多样特征,输出效果必然不会令人满意。所以为了处理这个现象,MobileNet V2先构建一个升维系数是6的PW特意用来期望提升通道维度在高维提取特征,后面再结合一个DW卷积。经历了这样的阶段,无论输入通道数多大,深度卷积都可以通过逐点卷积在更高的维度工作来提取特征。
3.2 基于Swish非线性激活函数的精度补偿
由于利用轻量化结构MobileNet V2替换了特征提取器,使改进后的DeepLab V3 模型的分割速度大幅增加,然而精度不可避免地会下降。因此考虑到防止精度下降过于严重,为使模型的综合性能达到最佳,更好地平衡模型的分割精度和速度,在MobileNet V2 中又引入了一种新的非线性激活函数Swish,Swish 函数在2017年10月份由谷歌提出。Swish的定义如下:

非线性激活函数对于深层神经网络的训练能否成功起着关键的作用。常见的激活函数一般有下面几种。
Sigmoid函数:

公式(2)中,σ(x)是Sigmoid函数,β是一个常量或者变量。若β为0,则Swish为一个线性函数;若β趋于无穷大,Sigmoid函数则接近于0-1函数,Swish则变成了ReLU非线性激活函数。Swish曲线图如图6所示。
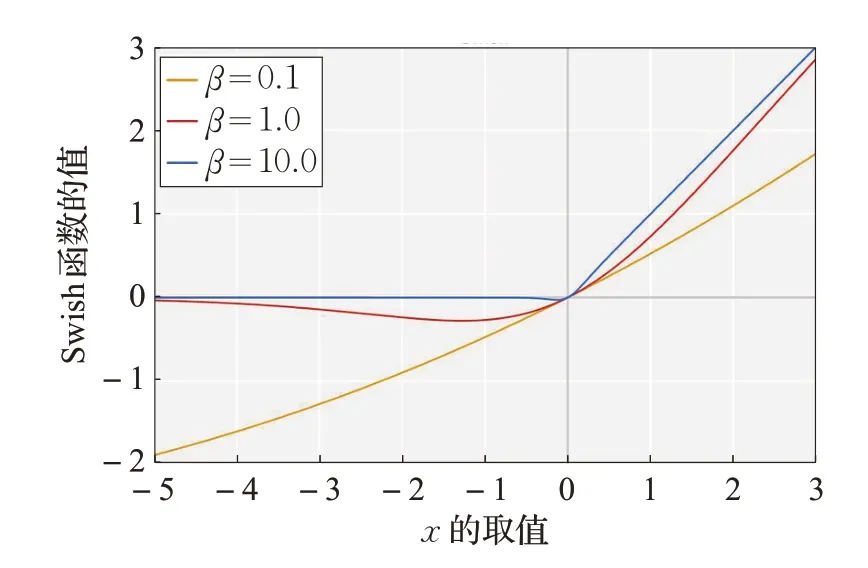
图6 不同β 值的Swish激活函数
Swish 激活函数和ReLU 激活函数相同的是,曲线上方不受限制,下方受到限制。而不同的是,Swish 和ReLU 相比的特点是曲线非单调性且曲线光滑不饱和。实践证明,当β等于1 时,使模型性能最好[17]。β值不同时在ResNet网络上的预测性能结果如图7所示。
图7 中,横坐标代表β值的选取,纵坐标代表模型预测的性能。可以发现令β为1,普遍模型效果最佳。因此本文选取Swish激活函数的定义中β取值为1。
谷歌在公布的论文中已经说明Swish 激活函数的性能要优于当前的所有激活函数,谷歌团队在大量实验中经证实Swish 函数对于深度卷积神经网络的匹配度和效果要胜过ReLU 很多,只是相对会造成一些延迟。例如,在ImageNet 网络竞赛上,将ReLU 用非线性激活函数Swish 的替换,使Inception-ResNetV2 的准确性可以提高大约1%,移动端的NASNet-A 在top-1 上分类的准确性可增加1.3%。
由于网络层数越来越深,会使输入特征图的分辨率逐渐减小,考虑到要减弱应用非线性激活函数的成本,因此在MobileNet V2 网络的深层部分将ReLU 激活函数用Swish 替换。谷歌经过改变带有Swish 和ReLU 激活函数的全连接层级数,测试其在MNIST 数据集上的性能变化(取三次运行的中位数),如图8 所示,如果全连接网络的层级在40 层以内,那么不同激活函数所表现出的性能没有显著性区别。而从40 层增加到50 层中,Swish要比ReLU表现得更加优秀,因为随着层级的增加,优化将变得更加困难。在非常深的网络中,Swish相对于ReLU 能实现更高的测试准确度。因此本文把MobileNet V2 的最后一行序列的激活函数进行替换。Swish 在网络深层部分表现比较明显,虽然会带来一点延迟,但可以弥补只用ReLU激活函数的MobileNet V2产生的潜在精度损失。
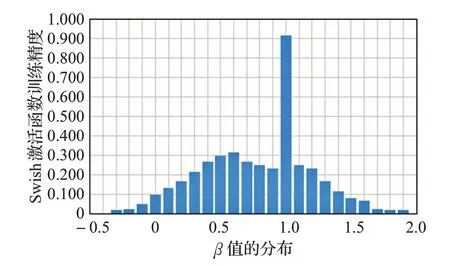
图7 在ResNet-32上的不同β 值的预测性能

图8 Swish和ReLU激活函数的层级数与性能关系图
4 实验结果与分析
4.1 DeepLab V3网络模型训练
本文模型训练主要基于Tensorflow 框架工具和OPenCV视觉库实现。在2015年11月份,Tensorflow被谷歌团队开源用于实现CNN算法的一种非常优秀的计算框架。Tensorflow 相比于其他框架的模型可以实现分布式计算、易用性高、计算速度快、灵活性强和兼容性强,算法更多并且系统也更稳定。Tensorflow 是通过计算图上每一个节点来进行模式表达和运算的编程体系[18],通过会话(Session)机制建立运行模型,此外它还可通过Tensorboard 机制提供清晰的可视化界面,更方便参数调节。
需要注意的是在应用Tensorflow工具时,需要将输入数据的格式规范地转化为TFRecord 形式,这样有两处便利,其一是方便将一个样本不同的数据类型所有信息统一起来以二进制数据形式进行存储;其二是可以利用文件队列的多线程操作,使得数据的读取和批量处理更加方便快捷[19]。
OpenCV 因为API 丰富、性能优异,属性友好,目前是最受欢迎的计算机视觉库。OpenCV 目前有OpenCV2 和OpenCV3 两大版本,考虑到版本兼容性和上手装置困难程度,本论文研究应用OpenCV2 版本。依照功能与需求的差异,OpenCV2有许多差别的API接口,例如core核心模块,imgproc图片处置模块,highGUI具备管理者界面和文件读写的API 接口函数等一系列非常有用的函数接口。
本文实验的具体软硬件环境配置见表1。
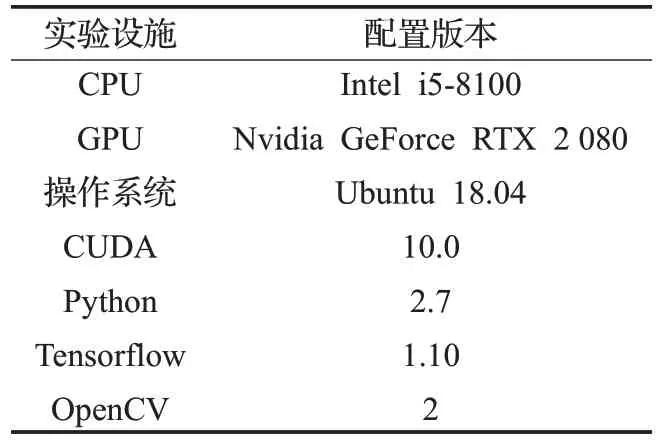
表1 实验软硬件环境配置
如图9所示,为软件运行界面及实时分割效果图。
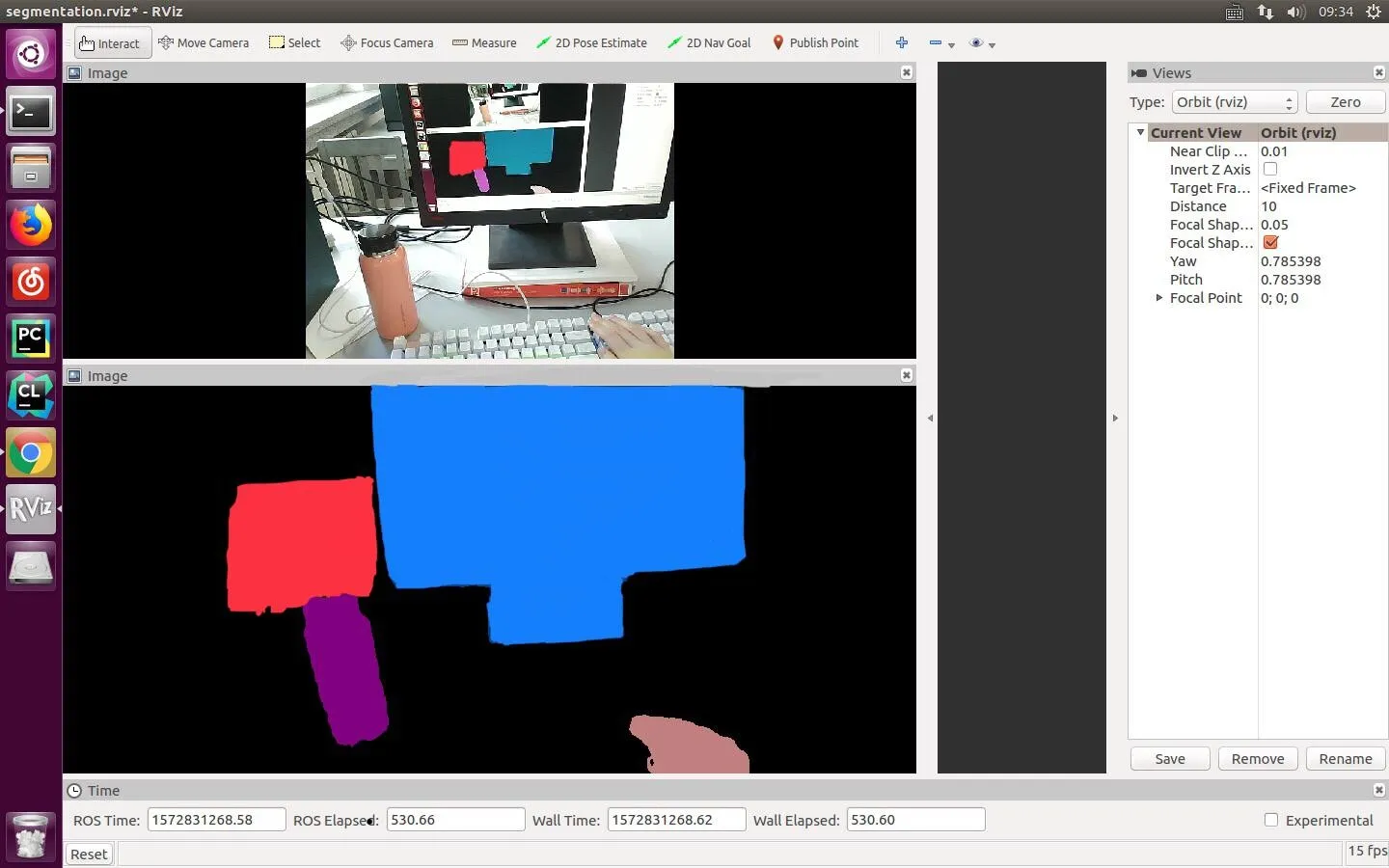
图9 软件运行界面及实时分割效果图
在实验的过程中,最终模型训练需要的其他固定参数见表2。
本文所有训练的实验在把训练集输入到网络之前,先规定batch尺寸为8,即将训练集的随机8张图片构成一个批次,接着随机random为每张图片在[0.5,1.5]范围之间选择任意一种尺度比例进行缩放处理;然后再按照0.5 的概率大小对全部图片做左右变换的翻转处理;最后一步是将训练图片的大小都统一裁剪成513×513。这样使训练样本的图像尺寸和形状更丰富,更具有随机性,从而避免模型造成过拟合的效果。
模型的训练流程如图10所示。
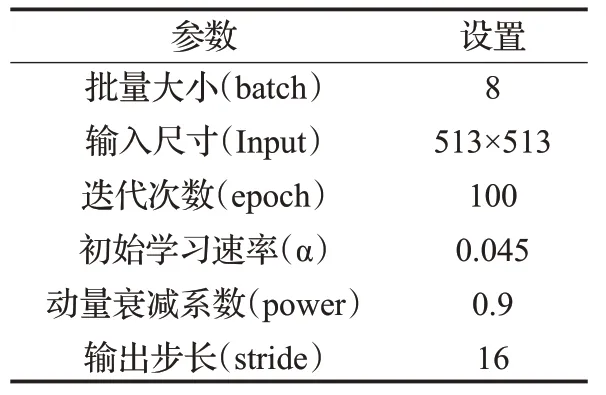
表2 超参数设置
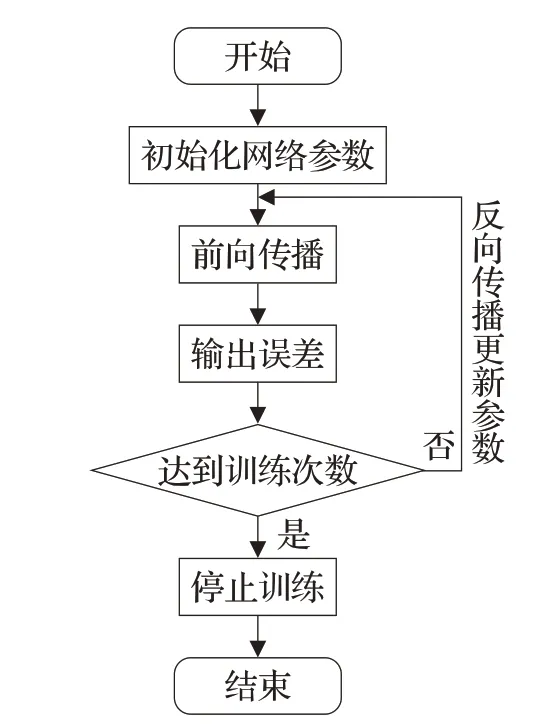
图10 网络训练流程图
实验采用基于Imagenet数据集进行预训练的模型,基于预训练模型checkpoint 在VOC2012 和Cityscapes基础上分别进行了30 000 次迭代训练得到最终各自的DeepLab V3+模型。
本文中,基于ImageNet 数据集上获取了三个不同通道的期望值与方差,对应三通道的期望值分别为0.475、0.466、0.416,标准差分别为0.239、0.234、0.235,最终让训练数据的全部通道均满足期望值和方差分别是0和1的正态分布。
4.2 实验结果及对比
DeepLab V3+和改进之后的DeepLab V3参数设置相同,然后选择训练好的DeepLab V3+模型和改进的DeepLab V3模型分别在VOC2012和Cityscapes上进行测试,基于VOC2012 数据集的测试对比可视化结果如图11所示。
从图11测试结果中可以明显看出,DeepLab V3+算法将第一张测试图片中的小男孩和马分割得特别清楚,与标签图片几乎重合,然而本文设计的算法还存在标记分割颜色重叠的问题,在小男孩(浅粉色)的身上出现了一点马(深粉色)的标记颜色,此外,对马分割的边缘相比DeepLab V3+不够平滑。第二张测试图片中的自行车,DeepLab V3+算法与标签还算贴近,然而由于车体零件比较复杂,对于车链、脚蹬颜色不明显的物体并没有分割出来,本文算法也存在同样的问题,另外还存在对于车轮(绿色)分割不完整的问题。但是本文算法与DeepLab V3+对比对于物体的整体轮廓分割并没有相差太多,改进之后的模型依然可以分割出物体的边界,清晰识别出物体的种类。
基于Cityscapes数据集的测试对比可视化结果分别如图12所示。从图12测试的可视化结果中,可明显看到DeepLab V3+算法分割精度相对较好,其中路灯(白色)、行人(红色)、车辆(蓝色),标志(黄色)、树木(绿色)和房屋建筑物(灰色)都分割得较清晰,与标签十分贴近。甚至远距离微小物体都可以分割清楚,但是由于路灯颜色较浅与背景建筑物颜色十分相近,对于路灯(白色)和不明物体(黑色),DeepLab V3+算法也没有全部分割清楚。本文算法也同样没有解决这个分割问题,对于远距离的人(红色),本文分割出大概轮廓,从两张测试图片中还可以看到,对于右边车辆(蓝色)和树木(绿色)的分割染上了指示牌的颜色(黄色),但物体的总体轮廓都能分割清楚,图片也相对清晰。
本文算法的分割效果与DeepLab V3+算法有略微差距,大致轮廓的分割效果相同。然而在具体训练模型的过程中,本文设计的新的轻量化网络具备能够非常快速地完成分割任务的特点显而易见。具体对比测试结果见表3,其中运行时间代表的是计算机处理一批(batch=8张)图片所需要的时间。
从表3可以看出,VOC数据集因为每张图片内容简单因此训练都要比Cityscapes 快得多,并且以Xception结构为编码部分骨干的DeepLab V3+的分割精度较好,但模型占内存最大,运行时间最久。相比较而言,改进后的DeepLab V3 模型缩小了很多,因此运算速度明显提升。利用改进后的DeepLab V3 模型比DeepLab V3+的模型精度保持基本不变的情况下,计算参数量下降了约96%,Cityscapes 数据集上运行时间为0.8 s,VOC2012数据集上可达0.1 s,满足实时性要求,模型的综合性能达到最优。本文算法在VOC2012和Cityscapes数据集上的可视化收敛曲线,分别如图13和图14所示,其中,横坐标为迭代次数,纵坐标为损失值,初始学习速率α=0.045。

图11 基于VOC2012两种算法对比分割结果
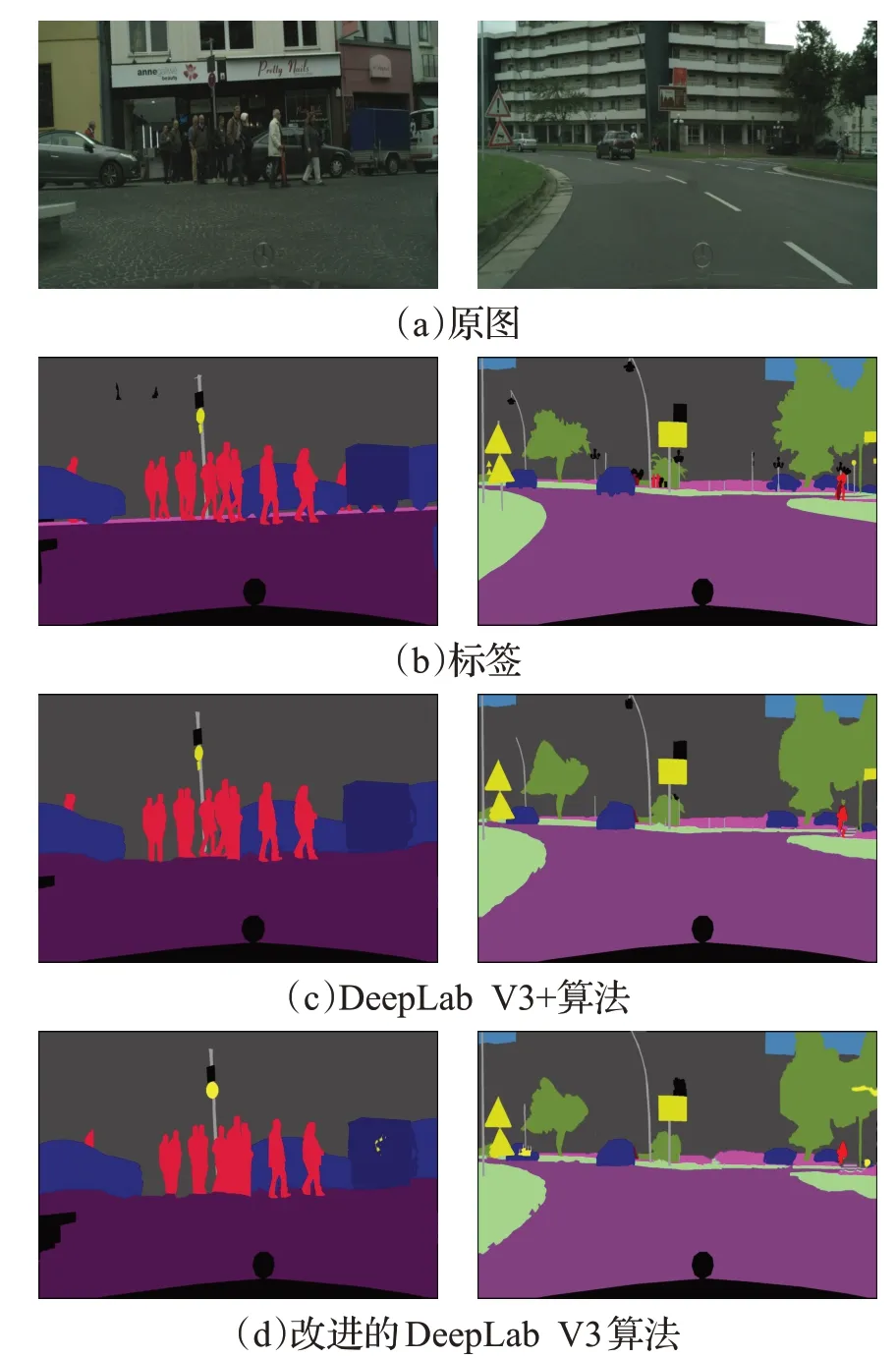
图12 基于Cityscapes两种算法对比分割结果

表3 两种算法对比测试结果
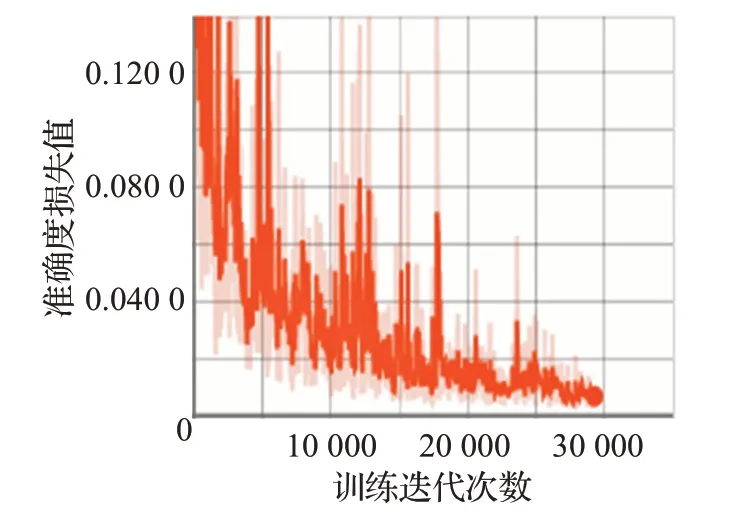
图13 基于VOC2012改进的DeepLab V3收敛曲线
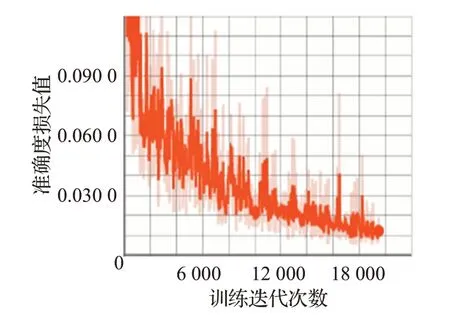
图14 基于Cityscapes改进的DeepLab V3收敛曲线
5 结束语
本文在研究DeepLab V3系统网络的空洞卷积和编码-解码结构的基础上,将MobileNet V2 网络结构部分进行改进,将原有的非线性激活函数部分替换成新的Swish 激活函数进行精度补偿。采用改进后的轻量化MobileNet V2 结构替代DeepLab V3 原有的特征提取器,在Cityscapes和VOC2012标准数据集上分别验证了改进的DeepLab V3 和DeepLab V3+算法的效果。测试结果显示,在Cityscapes 标准数据集上,模型大小从439 MB下降到15 MB,运行时间从5 s缩短至0.8 s。在VOC2012标准数据集上,模型大小同样从439 MB下降到15M,运行时间从0.9 s缩短至0.1 s。并且,频权交并比和平均交并比变化都不大。因而,改进的DeepLab V3 网络模型能在维持一定精度的前提下,参数量和计算复杂度大大减小,计算速度有了明显提升。经对比测试实验,可以得出改进的DeepLab V3 算法在模型精度和占用内存上可以达到综合最优,满足应用移动端设备实时分割的要求。该算法在精度方面的优化提高是今后进一步深入研究的主要方向。
