基于民调与网民情感倾向性的选情预测模型
2020-12-26林倩茹刘云清刘小煜刘威鹏
林倩茹,王 博,刘云清,刘小煜,刘威鹏
1.长春理工大学 电子信息工程学院,长春130022
2.北京信息技术研究所,北京100089
3.哈尔滨工业大学 经济与管理学院,哈尔滨150000
1 引言
世界主要国家或地区的政党轮换与领导人更替,可能会在军事、外交、贸易、科技等方面对局部地区甚至整个世界带来重要影响。准确预测指定国家或地区的选举结果,是制定针对性应对策略、行动、计划的重要支撑。然而,选举预测的影响因素多、不确定性大、信息迭代速度快。当前,迫切需要利用大数据等技术手段推动选情预测工作,由“人工定性分析”向“计算机辅助定量分析”转型,由“事后分析”向“事前预测”的“预报分析”转型。
传统的选情预测研究模型主要基于经济数据、历史数据或者民调数据[1-2]。2008 年田兴玲等人[3]提出基于小世界网络的差额选举模型,研究了刻画网络结构的近邻数和重新连接概率以及选举的差额度对选举的影响。2015 年陈陆辉等人[4]基于民意调查数据分析台湾选举,利用“涵盖率模型”结合媒体民调结果、民调中未表态或拒访网民投票意向,以及无法被电话调查到的网民投票意向,对选前媒体民调与历史选举结果进行了对比研究。Wright 等人[5]基于早期选举和2016 年竞选活动数据,采用平滑混合效应模型进行结果聚合。2019年Gaxiola 等人[6]采用粒子群优化方法,预测了尼日利亚Akwa Ibom州的一次选举活动。
随着社交网络的快速发展,越来越多的网民在网上发表政治意见并参与时事讨论,出现了利用社交媒体信息进行选情研究的模型[7-9]。在2008 年美国总统大选中,Williams 和Gulati 仅仅根据Facebook 网站上的支持率就成功地预测了总统大选结果[10]。2013 年Gaurav 等人[11]基于候选人在Twitter上的人气预测选举结果,利用候选人的名字在选举前被推文提及的次数,设计了一种基于预定义的关键字技术,成功地预测了2013年2月至4月在拉丁美洲举行的三次总统选举的获胜者。路凯丽[12]研究了候选人社交媒体使用情况对选举结果的影响,发现候选人的网站价值是预测其最终得票数的有效指标,说明候选人对竞选网站的使用水平确实会对选举结果产生影响。2018年Xie等人[13]利用Facebook、Twitter、谷歌媒体数据预测台湾总统大选,从“信号”角度考虑网络异构信息,并采用卡尔曼滤波器融合多个信号以预测候选人的得票率。
上述方法虽然在一定程度上刻画了真实民意,但影响选举结果的因素是多方面的,采用单一的经济数据、历史数据、民调数据或社交媒体数据预测选举结果,并不能全面反映选民的政治倾向,为此,本文提出基于民调与网民情感倾向性的选情预测模型。针对民调数据,由于不同民意调查机构具有不同的倾向性,为避免机构倾向性导致的误差,建立基于时间序列的数据修正模型和反向归一化方法对数据进行修正;针对社交网络数据,基于Facebook上网民对党派候选人的评论建立网民情感分类量化模型以分析网民的情感倾向性。最后,为提高选举预测的准确性,利用熵值法融合修正后的民调结果和网民情感倾向性分析结果。

图1 选情预测模型总体框架
2 总体模型框架
选情预测模型总体框架如图1所示,主要包括三个部分:民调数据归一化修正模型、网民情感分类量化模型和基于熵值法的选情融合预测模型。
其中,民调数据归一化修正模型包含基于时间序列的数据修正模型和反向归一化方法,其作用是分别对民调机构数据的倾向性进行纠偏以及对未表态人群的政治态度进行推理。网民情感分类量化模型主要包含词典创建、情感分类和情感量化三个部分,其首先将输入的社交媒体数据进行预处理,并结合情感词典、否定词词典和程序词词典进行情感倾向性计算,然后进行情感分类,最后对情感分类结果进行量化分析得到网民情感倾向性分析结果。基于熵值法的选情融合预测模型则是将修正后的民调预测结果与网民情感倾向性分析结果通过信息熵进行融合,从而得出最终的选情预测结果。
3 民调数据归一化修正模型
民调数据归一化修正模型包含基于时间序列的数据修正模型和反向归一化方法两部分。
3.1 基于时间序列的数据修正模型
利用多家民调机构数据,分析不同民调机构对于同一党派候选人的民调结果偏差。将多家民调机构结果的平均值作为民调结果的基准值,并以此计算各个民调机构的历史偏差序列,再利用时间序列方法,预测当前时刻各民调机构对该党派候选人的偏差,对民调结果进行修正。
3.1.1 时间序列方法
移动平均(MA)是给定m个数据点组成的序列{x1,x2,…,xm}和移动平均参数n,通过滑动窗口方式计算得到新的序列,如式(1):

式(1)中,xi(i=1,2,…,m)表示原始序列第i个值,则移动平均模型的输出序列为{x1,x2,…,xn,x'n+1,x'n+2,…,x'm}。
指数移动平均(EMA)是以指数式递减加权的移动平均[14]:
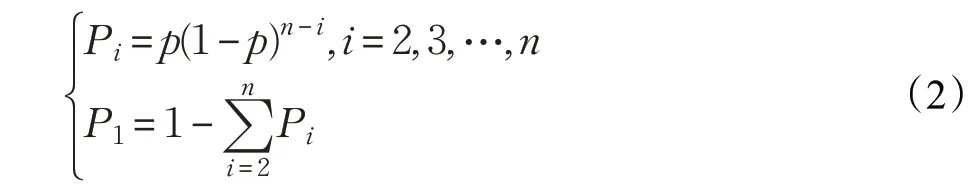
式(2)中,参数p为指数衰减因子,给定m个数据点组成的序列{x1,x2,…,xm}和移动平均参数n,则:

3.1.2 民调数据修正模型
为减少不同的民调机构orgk(k=1,2,…,K)对不同的党派候选人parr(r=1,2,…,R)的倾向性,采用时间序列方法对民调数据进行修正,如表1所示。

表1 民调机构数据
表1 中,设在选区c,民调机构orgk调查出ta时刻支持党派候选人parr的选民比例为,未选择支持任何党派候选人的选民比例为wbtk。基于时间序列对以上结果进行修正,得到修正后的党派候选人parr支持率为。修正的过程分为5个步骤:
(1)将所有民调机构orgk(k=1,2,…,K)对党派候选人parr的支持率取平均值:

式(4)中,表示民调机构orgk给出的党派候选人parr的支持率,表示将所有民调机构对parr调查结果的平均值作为民调基准值。
(2)对民调机构orgk,党派候选人parr历史支持率序列为:{(t1,pollk,1),(t2,pollk,2),…,(tA,pollk,A)},由式(1),得到修正后的新序列:{(t1,poll'k,1),(t2,poll'k,2),…,(tA,poll'k,A)}。
(3)对于民调机构orgk,计算ta时刻对党派候选人parr的偏差:Biask,a=poll'k,a-,则所有时间的偏差组成一个序列:B={(t1,Biask,1),(t2,Biask,2),…,(tA,Biask,A)}。
(4)对于偏差序列B,利用式(2)和式(3),得到新的偏差序列B′={(t1,Bias'k,1),(t2,Bias'k,2),…,(tA,Bias'k,A)}。
(5)ta时刻的民调数据修正:k,a+Bias'k,a,为民调机构orgk对党派候选人parr修正后的支持率。
3.2 反向归一化方法
设未表态受访者符合沉默螺旋理论的推论[15],即选民对党派候选人parr支持率与未表态选民对党派候选人parr支持率,呈反比关系。基于该假设,本文采用反向归一化方法,对未表态选民的倾向性进行推理,过程如下:
(1)设在选区c,ta时刻民调机构orgk对各党派的修正数据序列为{},未表态数据为wbtk,按降序排列,得到新序列:{}。
(2)将未表态数据wbtk通过公式(5)分加给R个党派候选人,得到所有党派候选人的推理支持率:{}。

式(5)中,dt_sortR-r+1表示分加给党派候选人parr的未表态比重,表示考虑未表态选民的倾向性后,选民对党派候选人parr的支持率。
(3)将K个民调机构对党派候选人parr的推理支持率求平均值,并做归一化处理,如式(6)、式(7)所示。

4 网民情感分类量化模型
网民情感分类量化模型包括3个部分,首先构建情感词典、否定词词典和程度词词典,在此基础上,将爬取的评论语料进行预处理;然后基于情感词典、否定词词典和程度词词典进行情感倾向性计算,将网民情感分为积极情感和消极情感;最后,通过移动平均累计概率(MAPP)方法将网民情感进行量化,得到选民情感倾向性预测结果。
4.1 词典构建
将知网HowNet 词典中的正负情感词典、清华大学李军中文褒贬词典、大连理工大学情感词汇本体(DUTIR)和台湾大学情感词典(NTUSD)中的积极词和消极词去重后融合[16],得到通用情感词典WT。程度词词典来自于知网词典库(表2)。由于社交媒体评论中存在表情符号,对积极含义的表情符号和消极含义的表情符号构建表情符号词典WE,部分表情符号情感极性如表3所示。

表2 部分词典类型及权重示例

表3 部分表情符号情感极性
由于通用情感词典对情感词的概括是有限的,缺乏部分选情领域的情感词,还需对选情评论中出现频数较高的词进行情感识别。本文利用点互信息(Pointwise Mutual Information,PMI)算法对通用情感词典进行扩充[16],计算选情领域新词与已知情感词之间的语义正相关度,确定新词的情感极性。利用互信息找到与新词最正相关的情感词,然后将该词的情感极性作为新词的情感极性,词语w1、w2之间的互信息的计算公式如下:

式(8)中,p(w1,w2)表示(w1,w2)两个词共同出现的概率,{p(w1),p(w2)} 分别表示w1、w2单独出现的概率。PMI(w1,w2)表示{w1,w2}之间的互信息,若PMI(w1,w2)>0 ,则p(w1,w2)>p(w1)p(w2) ,说明两个词语具有相关性,值越大,相关性越大。本文从选情领域网民评论数据中选取了30对高频情感词,构成正向情感词集合WP和负向情感词集合WN,并利用这30对种子词,计算未包含于通用情感词典的词语w∉WT的情感极性,判断公式如(9)所示:

式(9)中,若SO_PMI(w)的值大于0,新词w的极性为正向;等于0,新词w的极性为中性;小于0,新词w的极性为负向。
最终的情感词典是通用情感词典、领域情感词典、表情符号词典的并集。情感词典的种类及积极词、消极词数量如表4所示。
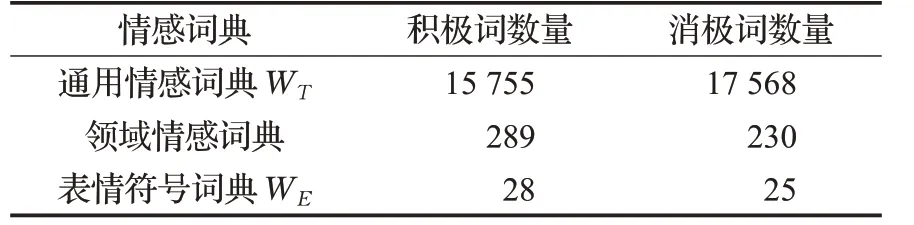
表4 情感词典种类及积极词、消极词数量 个
4.2 网民情感分类
利用网民在社交媒体Facebook 上对各党派候选人的评论数据,将网民的情感分为积极和消极两类,步骤如下:
(1)评论文本预处理。将同一账号针对党派候选人parr的评论去重、合并,利用“jieba库”进行分词,并采用哈工大停用词库,将对情感分析无影响的词过滤掉,得到每个账号的关键词集合。
(2)反向遍历关键词集合,将当前词wi与情感词典进行匹配,若为积极词,则情感值为1;若为消极词,则情感值为-1。再以wi为基准向前寻找程度词和否定词,若含有否定词和程度词,则词wi的情感得分ei为情感值与否定词、程度词权重之积。
(3)计算每个账号评论的情感得分:

式(10)中,如果a >0 表示此网民对党派候选人parr的情感极性为积极;a=0 表示其情感极性为中性;a <0表示其情感极性为消极。
4.3 网民情感量化
网民情感量化处理详细步骤如下:
(1)计算党派候选人parr在时间t获得网民的支持率:

式(11)中,supr,t表示党派候选人parr在时间t获得网民的支持率,posr,t表示党派候选人parr在时间t情感极性为积极的网民数,totalr,t表示党派候选人parr在时间t的总评论数。
(2)计算移动平均累积概率MAPP,将党派候选人parr在某一时间段[t-T,t-1]内网民的平均支持率作为其在t时刻选民支持率的估计[14]:

5 基于熵值法的选情融合预测模型
为尽可能提升模型的预测精度,本文将基于民调的预测结果和基于网民情感倾向性的预测结果进行融合,利用熵值法[17]确定各个模型的权重,以克服人工赋权无法避免的主观性,以及解决多变量间的信息重叠问题。基于熵值法的选情融合预测过程如图2所示。

图2 基于熵值法的选情融合预测过程
如图2所示,基于熵值法的融合预测过程如下:
(1)将第j个模型对党派候选人parr的支持率预测结果归一化:

(3)计算信息熵冗余度:

式(13)至(17)中,hrj表示第j个模型对党派候选人parr的支持率预测结果,J为模型个数,党派候选人个数R >1,常数q=1/lnR。
6 实验
6.1 数据集
民调数据来源于维基百科“某地区直辖市长及县市长选举”网站,时间范围为2017 年5 月4 日至2018 年11月13日,民调机构个数为30,本文重点研究了其中的14个选区。对于社交媒体数据,编写爬虫定向采集Facebook上网民对14 个选区的30 个党派候选人的评论,评论发布 时 间 为2018 年9 月1 日 至2018 年11 月23 日,共 计458 217条数据。数据集信息如表5所示。

表5 数据集信息
6.2 实验设置
每个选区每个党派只考虑一个候选人。民调数据修正模型中,只对民意调查次数大于4的民调机构数据进行修正(小于5次不做修正),移动平均模型和指数移动平均模型的滑动窗口n大小设为3,指数衰减因子p设为0.7。情感量化过程中,移动平均累积概率的窗口T设为5。基于熵值法的选情融合预测模型中,模型数为3(民调数据修正模型、反向归一化方法和情感分类量化模型),每个选区包括3个党派的候选人。
本文采用准确率和相对误差两种指标衡量选情预测的效果,准确率定义为预测正确的选区个数与总选区个数的比值,用Accuracy表示;预测结果与真实结果之间的差异程度用相对误差(RE)和平均相对误差(MRE)评价。

式(18)至(20)中,Acurracy表示模型j的预测准确率,Ctrue表示预测正确的选区个数,C表示选区总数;yc,r表示模型j在选区c对党派候选人parr的预测结果,bc,r表示在选区c党派候选人parr的真实结果;REc,r表示模型j在选区c对党派候选人parr预测的相对误差,MREr表示模型j在所有选区对党派候选人parr预测的平均相对误差。
6.3 实验结果及分析
6.3.1 民调数据预测结果对比分析
原始民调数据如表6所示,基于时间序列的数据修正模型预测结果如表7所示,反向归一化方法预测结果如表8所示。其中,par1、par2、par3分别表示党派1、党派2、党派3;“—”表示未参选;在准确性一列中,1 表示预测结果与真实结果相同,0则反之;后文与此相同。
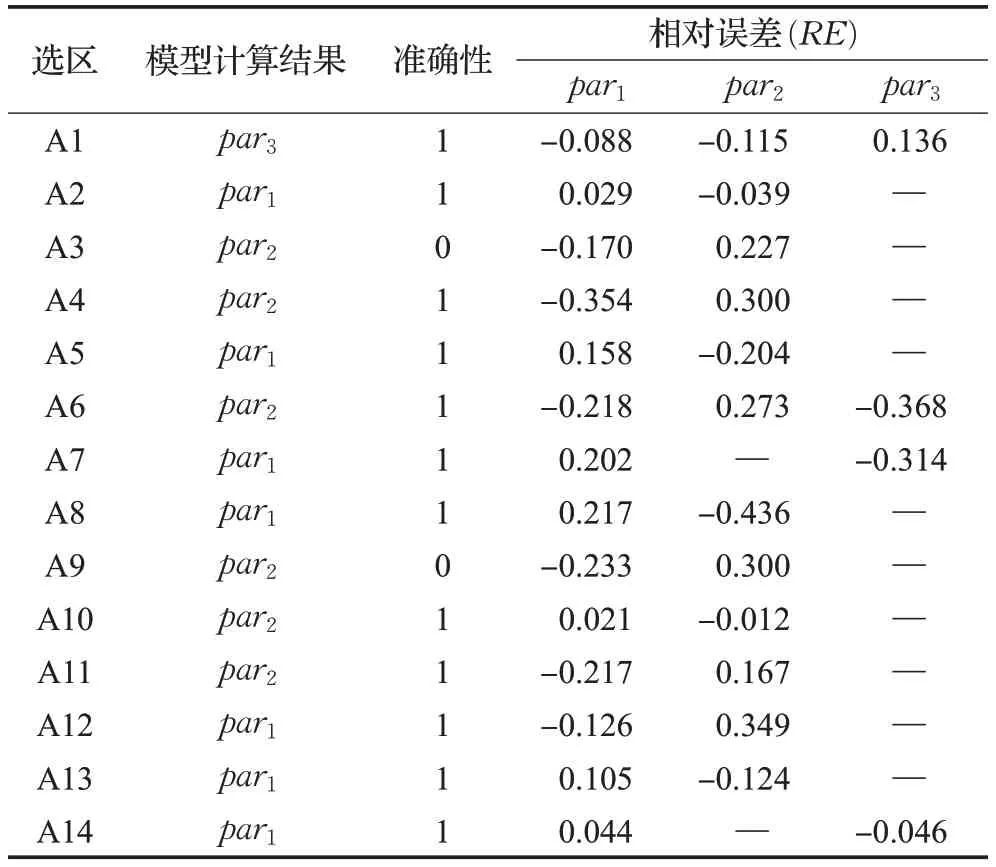
表6 原始民调预测结果

表7 基于时间序列的数据修正模型预测结果

表8 反向归一化方法预测结果
由表6、表7 和表8 可知,在研究的14 个选区中,原始民调、基于时间序列的数据修正模型均在相同的2个选区出现错误预测,准确率为85.71%,但后者的相对误差有所减小。反向归一化方法对1个选区预测错误,准确率提升到92.86%。
6.3.2 情感分类量化预测与民调预测结果对比分析
网民情感分类量化结果如表9所示,在研究的14个选区中,5 个出现预测错误,预测准确率约为64%,相较于基于民调的结果而言,准确率偏低。此外,如图3 所示,M1表示民调归一化修正模型,M2表示网民情感分类量化模型,M1par1、M1par2、M1par3表示民调归一化修正模型对党派parr的相对误差;M2par1、M2par2、M2par3表示情感分类量化模型对党派parr的相对误差。其总体相对误差比民调归一化修正模型大。该模型预测效果不佳,一方面可能是社交媒体信息搜集不全或“网络水军”带政治风向导致;另一方面是本文方法对社交媒体数据的处理仍存在一定的缺陷性,需要进一步考虑评论中的语义关系及优化网民政治情感倾向的计算方法。

表9 网民情感分类量化模型预测结果

图3 M1 模型与M2 模型的相对误差比较

表10 选情融合预测模型准确性和相对误差
6.3.3 民调和网民情感倾向性融合预测结果
民调和网民情感倾向性融合预测结果如表10 所示。对比表8、表9和表10,可知反向归一化方法在选区A9预测错误,而在其他13个选区均预测正确;网民情感分类量化模型在选区A9 预测正确,而在其他选区的预测效果不佳;基于熵值法的选情融合预测模型则在研究的14 个选区中均预测正确,说明选情融合预测模型实现了不同模型之间的优势互补,有效地提高了选举预测的准确率。
6.3.4 预测结果对比分析
表11 对比了5 种模型的预测准确率和平均相对误差。在平均相对误差指标上,5种模型对所有党派的预测误差都在22%以下,基于熵值法的选情融合预测模型最小;par3的平均相对误差小于par1和par2,可能是par3的样本数量较少导致的。在预测准确率指标上,基于熵值法的选情融合预测模型的准确率最高,达到了100%。综合而言,利用熵值法融合修正后的民调信息与网民情感倾向性信息,可以有效地提升选举预测准确率及减小平均相对误差。

表11 5种模型预测准确率和相对误差对比
7 结束语
针对基于单一来源数据预测选情不能全面反映选民政治倾向的问题,本文提出了包括基于时间序列的数据修正模型、反向归一化方法、网民情感分类量化模型和基于熵值法的选情融合预测模型在内的基于民调与网民情感倾向性的选情模型框架。以某地区真实历史选举结果为基准的实验表明,利用基于时间序列的数据修正模型和反向归一化方法修正后的民调数据,能够有效地提升预测准确率;根据社交媒体信息得到的网民情感倾向性分析结果较差,不能很好地支持选举预测;相对比于民调结果和社交媒体情感倾向性分析结果,基于熵值法的选情融合预测模型将二者的部分结果进行了优化,减小了平均相对误差,提升了总体预测准确率。
下一步工作包括扩充社交媒体语料库、进一步丰富词典、考虑评论中的语义关系、探索新的情感分类方法和网民政治倾向性计算方法等,以有效提升基于社交媒体信息的网民情感倾向性预测效果,从而提升选情融合预测模型的总体预测效果。
