流内编码中考虑链路相关性的机会路由机制
2020-12-26陈朝辉
陈朝辉,杨 湘,李 鹏,何 亨
武汉科技大学 计算机科学与技术学院,武汉430065
1 引言
传统的路由机制中,转发路径是确定的。由于无线链路的广播特性,非转发节点也有可能监听到数据包,但这些节点必须丢弃掉已收到的数据包,即使它们可能更“接近”目的节点。这显然会导致网络资源的浪费。对此,Biswas 和Morris 两人提出了机会路由ExOR[1],允许任何监听到数据包并且更“接近”目的节点的中间节点参与数据包的转发。由于要从多个候选节点中选取出最“接近”目的节点的那一个,机会路由在Mac层上引入了严格的调度机制,带来了比传统固定路径的无线路由更高的传输可靠性和端到端的吞吐量[2],但是这种严格的调度机制使得协议的设计与实现变得很复杂并且难以拓展到多播网络中。Chachulski首次将随机线性网络编码和机会路由相结合,提出一种节点间无需严格调度的路由机制MORE[3],在引入网络编码后有效地解决了数据传输过程中节点协作难的问题,并且支持多播网络。
目前,结合网络编码与机会路由的研究需要解决的问题是中间节点需要转发多少数量的编码包。因为理想数量的编码包不仅能避免重复传输,也能保证目的节点成功解码[4]。解决方案主要有两种:第一种方法是基于平均链路丢包率计算期望转发次数,在这种情况下,需要端到端地反馈来确认目的节点是否成功解码。例如,针对MORE协议要求源节点只有在目的节点成功解码出原数据包后才发送下一批编码包的缺陷,CodeOR[5](Coding in Opportunistic Routing)提出通过滑动窗口的机制让源节点同时发送多批次的编码包。PipelineOR[6]受MORE协议的启发,提出让中间节点代替源节点进行数据包的传输。SlideOR[7]中提出了一种每个batch中数据包的数目(即batch size)可调节的流内编码机会路由机制,根据接收端的反馈信息自适应地调整batch size的大小。第二种方法要求中间节点实时检测链路的质量并逐跳反馈在数据包上。例如CCACK[8](Cumulative Coded ACKnowledgment)通过逐跳反馈的方式让上游节点获悉下游节点接收线性无关编码包的情况,并及时停止当前“块”编码包的发送,以减少不必要的编码包传输,提高网络的吞吐量。这种通过下游节点逐跳反馈的方式,能够帮助上游节点检测链路质量并充分利用有限的网络资源。但是,以上这些结合网络编码的机会路由机制均是在假设链路丢包相互独立的基础上进行设计的。
已有研究[9-11]表明无线网络中的链路之间呈现相关性:无线网络中相邻的接收节点可能会受到相同干扰源的影响,因而链路的丢包是相关的。链路相关性会导致机会路由、网络编码、协作转发等机制在计算相关指标时出现误差,从而影响协议的性能。目前已有研究人员结合链路相关性对现有协议做出改进。文献[12]分析了链路相关性对机会路由机制中节点转发次数的影响,提出LCAOR 机制,通过选取低相关性链路的节点作为转发节点以提高机会路由的性能。文献[13]考虑链路相关性,结合网络编码提出一种机会路由中的分布式算法,可以适应无线信道中丢包率的变化以及链路相关性的影响,用来确定中间节点转发编码包的数量。文献[14]提出LCOR 机制,在机会路由机制中考虑链路相关性,使用联合丢包率衡量多条链路之间的相关性,同时提出子集质量指数(SQI)用来衡量无线mesh 网络中节点集的质量,进而选取转发节点。以上机制或是仅在路由机制中考虑链路相关性而未结合网络编码,或是仅仅考虑节点需要转发多少编码包而未说明如何选取转发节点。
对此,本文提出了一种考虑链路相关性的网络编码机会路由机制:NCCLCOR(Network Coding based Opportunistic Routing Considering Link Correlation),在计算节点转发次数与选取转发节点集合时考虑链路丢包率与链路相关性。本文的主要研究工作分为以下三个部分:
(1)分析链路相关性对节点转发次数以及转发节点选取的影响。
(2)考虑链路相关性,提出更合理的节点转发次数计算方法以及转发节点选取算法。
(3)进行实验分析改进后的算法性能。
2 链路相关性对节点转发次数与转发节点选取的影响
2.1 链路相关性
由于无线网络自身通信信道易变的特性以及外界环境的干扰等因素,无线网络中的链路丢包率可能会发生改变。ExOR协议以及后来结合网络编码的机会路由协议却都是在忽略链路相关性的前提下进行设计的,而ExOR 的作者在文献[1]中的5.6 节也提到:如果所有的丢包都是由低信噪比与多径衰落引起的,那么链路丢包相互独立的假设是合理的。但是实际上多个接收节点的丢包率可能存在相关性,因为它们可能受到同一个干扰源影响造成同时丢包。相关性指不同链路之间丢包相关的程度,分为正相关和负相关。产生链路相关性的原因主要来自两方面,共享频段中的交叉网络干扰(cross-network interference)和动态环境中的相关性衰减(correlated fading)[15]。交叉网络干扰指的是:由于当前许多无线技术共享了一些非授权频段,在这些频段上多条数据流同时传输会相互干扰,导致数据包在相邻的链路上同时丢失。而相关性衰减则是指由于障碍物等因素的存在,无线电波会出现屏蔽衰减(shadow fading),从而使得局部网络中的数据丢失呈现相关性。
交叉网络干扰如图1(a)所示,当干扰源出现时,图中两个终端同时丢失数据包。当干扰源消失时,两个终端又同时接收到数据包。这种两个接收终端要么同时收到、要么同时丢失数据包的情况称为正相关。相关性衰减如图1(b)所示,左边终端正常接收数据包,右边由于出现移动障碍物而丢失数据包。当障碍物移动到左边时,又导致左边丢失而右边能正常接收,这种情况称为负相关。

图1 正负相关示例
2.2 链路相关性对节点转发次数的影响
流内网络编码中,中间节点并没有特定的下一跳节点。因此如何确定节点的转发次数,使得转发节点既不会转发重复的数据包,又能确保下一跳节点收到足够的数据包是流内编码机制中的重点。而链路相关性对转发次数的计算有很大程度的影响。
下面以图2 为例详细说明链路相关性对转发次数计算的影响。
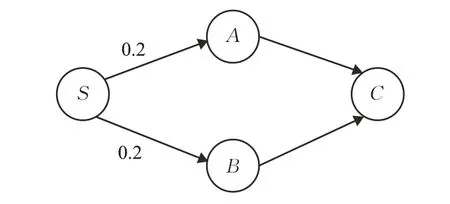
图2 链路相关性对节点转发次数影响示例
如图2所示,节点S为节点A和B的上游节点,节点C为节点A和B的下游节点。现假设节点A和B丢失节点S发送的数据包的概率均为0.2。在S→A与S→B两条链路丢包相互独立、正相关和负相关的三种情况下分别计算节点S成功发送数据包到节点A和B的期望转发次数。
(1)当S→A与S→B两条链路丢包相互独立时,即节点A和B接收数据包互不影响,则节点A和B同时丢包的概率为0.2×0.2,那么节点A和B中任一节点成功接收到节点S发送的数据包的概率为1-0.2×0.2,故节点S所需的平均转发次数为1/(1-0.2×0.2)=1.04。
(2)当S→A与S→B两条链路丢包呈正相关时,由于节点A和B收到的数据包是相同的,则两个节点同时丢掉S发送的数据包的概率为0.2那么节点A和B中任一节点成功接收到节点S发送的数据包的概率为1-0.2,故节点S所需的平均转发次数为1/(1-0.2)=1.25。
(3)当S→A与S→B两条链路丢包呈负相关时,即节点A和B中任一节点收到数据包而另一个未收到,则节点A和B同时丢包的概率将小于0.2×0.2,那么节点A和B成功接收到节点S发送的数据包的概率将大于1-0.2×0.2,故节点C平均发送次数将小于1/(1-0.2×0.2)=1.04。
对比链路独立与链路相关的两种计算结果不难发现,基于链路独立的计算结果与基于链路相关的计算结果相比存在误差,这种误差势必会导致网络吞吐量下降。原因在于,若某些链路接收数据包呈正相关,链路独立的假设会使得中间节点转发的线性无关的数据包个数不够,进而导致目的节点无法解码出原数据包。这时源节点不得不再发送同批次的数据包,这些数据包再经过中间节点的转发才能最终到达目的节点,导致网络吞吐量下降。若链路接收数据包呈负相关,中间节点会转发多余的数据包给下游节点,这同样会导致网络吞吐量下降。
2.3 链路相关性对转发节点选取的影响
链路相关性不仅会影响转发节点转发次数的计算,还会影响转发节点的选取。下面以图3 为例详细解释链路相关性对转发节点选取的影响。

图3 链路相关性对转发节点选取影响示例
假设源节点s要将一个数据包发送给目的节点d,需要从f1、f2、f3三个节点中选取两个节点作为转发节点。图中两个节点连线上的数字表示两个节点之间成功转发数据包的概率,例如Ps,f1=0.5 表示节点f1成功接收到节点s发送的数据包的概率为0.5。在链路独立与链路相关的两种情况下分别计算节点s和选取的转发节点所需的转发次数之和。
(1)链路独立:首先选择第一个转发节点。分别选择f1、f2、f3作为转发节点,计算得到各自的期望转发次数分别为:αf1=1/0.5+1/0.6=3.67,αf2=1/0.5+1/0.6=3.67,αf3=1/0.4+1/0.6=3.89,因此选择f1或f2中的一个节点作为第一个转发节点。这里选择节点f1作为第一个转发节点。
接着选择第二个转发节点。若选择节点f2,因为要保证节点f1和f2中至少有一个节点能接收到节点s发出的数据包,则节点s的期望转发次数为:αs=1/(1-(1-Ps,f1)(1-Ps,f2))=4/3 ≈1.33,其中1-Ps,f1和1-Ps,f2分别表示链路s→f1和s→f2的丢包率,因为这两条链路丢包相互独立,所以公式中(1-Ps,f1)(1-Ps,f2)表示节点f1和f2都没有接收到节点s发出的数据包的概率。节点f2收到的数据包个数为αsPs,f2,则它将这些数据包转发给节点d的期望转发次数为αf2=(αsPs,f2)/Pf2,d≈1.11;由于s→f1与s→f2两条链路丢包率相同,可直接得到节点f1期望转发次数为αf1=1.11;因此选择节点f1和f2作为转发节点集合的期望转发次数之和为αs+αf1+αf2=3.55。
若选择节点f3作为第二个转发节点,同理可得αs=1.43,αf1=1.19,αf3=0.95,因此选择节点f1和f3作为转发节点集合的期望转发次数之和为αs+αf1+αf3=3.57。
显然,链路独立的情况下选择节点f1和f2作为转发节点所需的转发次数更少。
(2)链路相关:首先选择第一个转发节点,这里选择节点f2。同链路独立的情况类似,接着考虑节点s的期望转发次数。由于考虑了链路相关性的存在,这里假设s→f1,s→f2两条链路丢包呈正相关,s→f2和s→f3两条链路丢包依然相互独立。若第二个节点选择f1则节点s的期望转发次数为:αs=1/(1-P(。
其中Ei,j表示节点j成功接收到节点i发出数据包的事件,由于s→f1和s→f2两条链路丢包呈正相关,即节点f1和f2要么同时丢包要么都未丢包,故节点f1和f2同时丢包的概率为P(=0.5 ,所以αs=2 ,αf1=αf2=(αsPs,f1)/Pf1,d≈1.66。因此选择节点f1和f2作为转发节点集合的期望转发次数之和为αs+αf1+αf2=5.32。同理可得选择节点f2和f3作为转发节点集合的期望转发次数之和为αs+αf2+αf3=3.57。
显然,链路相关的情况下选择节点f2和f3作为转发节点所需的转发次数更少。
对比上述两种情况下选取的转发节点不难发现,链路独立的假设会影响转发节点的选取,使得选取的转发节点的总转发次数更多。
3 考虑链路相关性的节点转发次数计算与转发节点选取
通过前文的分析,可以明确的是在计算节点转发次数以及选取转发节点时不能假设链路丢包相互独立,应该考虑链路相关性的影响。下面将讨论在考虑链路相关性的基础上,如何准确地计算节点期望转发次数以及选取转发节点集合,并在此基础上提出链路相关性指标的计算公式。
3.1 考虑链路相关性的节点转发次数计算
在传统的基于网络编码的机会路由机制中,普遍依据ETX(the expected transmission count metric)来进行节点转发次数的计算以及转发节点的选取。ETX 由DeCouto等人提出,用于在无线多跳网络中衡量链路质量,定义为在无线链路上传输一个数据包到目的节点所需要的期望传输次数[16]。具体来说,某条传输路径的ETX 值就是在该路径上每跳的ETX 值的总和,某一跳的ETX 在数值上等于该跳的链路丢包率的倒数。某个节点的ETX 值即经由该节点到目的节点的路径上所有跳的ETX 之和。以图3 为例,节点f1的ETX 值为1/(1-0.6)=2.5。
单纯依靠ETX值无法准确计算节点的期望转发次数,下面介绍考虑链路相关性的节点转发次数计算方法。
假设网络中存在N个节点,源节点为s,目的节点为d。对于任意两个节点i和j,i <j表示i比j更靠近目的节点,或者说节点i的ETX值比j小。Pi,j表示节点i和j之间的丢包率。Zi表示节点i为了将一个数据包成功从节点s发送到节点d所需的期望转发次数。考察源节点s发送一个数据包到目的节点d的情形,计算节点j的期望转发次数。容易得到节点j从ETX 值比它大的节点i处收到的数据包个数为(1-Pi,j)。对于节点j收到的每个数据包而言,仅当ETX 值比它小的节点都没有接收到该数据包时,节点j才转发。
由于考虑到链路相关性,这里定义事件Ei,j,表示节点j成功接收到节点i发送的数据包的事件。节点集合φj表示ETX值比j小的集合。这样节点j需要转发的数据包个数Lj(或者说节点j收到的数据包个数)为:

其中,概率P表示节点j成功接收到节点i的数据包,而所有ETX 值比j小的节点k未收到这个数据包的概率。在计算出节点j收到的数据包个数后,便可以得到节点j所需的总传输次数为:

其中,概率P表示所有ETX 值比j小的节点k均未收到节点j发出的数据包的概率。

公式(3)中的TX_credit值为节点j从ETX值大于它的节点处收到一个线性独立的数据包时所需的转发次数均值。
3.2 考虑链路相关性的转发节点选取
由于通过穷举的算法得到所有可能链路集合的转发次数算法复杂程度过高,所以本文采用的思路为:先找到发送次数最少的单个转发节点,然后再循环往节点集合中加入转发次数更少的转发节点,最终便可得到总转发送次数最少的转发节点集合,或者转发节点集合的大小达到预定值。
首先引入文献[17]中的EAX(expected number of any-path transmissions)值这个概念。EAX 用来衡量传输开销,它的含义是源节点到目的节点的多条路径上所有节点总的传输次数。EAX(Fs,s,d)的定义为:考虑给定的具有链路相关性的转发节点集合Fs,从源节点s成功传输一个数据包到目的节点d,整条路径上所有节点总的期望转发次数。EAX 的意义与ETX 类似,不同的是ETX 反映的是单条路径的传输开销,而EAX 值则反映了源节点到目的节点具的多条路径同时传输数据时所有传输路径总的传输开销。EAX(Fs,s,d)的计算公式为:

公式(4)中α为转发节点集合{ }1,2,…,N中至少有一个节点接收到节点s发出的一个数据包所需的转发次数,β为转发节点集合中的所有节点把数据包转发给目的节点所需的转发次数。α与β的计算公式如下:

公式(5)中Es,i为转发节点i成功收到节点s发出的数据包的事件,公式(5)、(6)中N为转发节点集合Fs中的节点个数,公式(7)中Ps,i为节点s到转发节点i的成功接收概率。
以图4为例介绍EAX值的计算。在图4中,源节点s有数据包要发往目的节点d,Fs={ }1,2,…,N为源节点s的一个转发节点集合。

图4 EAX值计算示例
网络中节点s周期性收集其所有下游节点成功收到数据包的信息,将此信息发送给各下游节点,所有下游节点根据此信息计算包含自己在内的节点集合{ }1,2,…,N中节点均未能收到某个数据包的概率P()。
EAX值的计算从目的节点d开始。显然d的EAX值为0,由此可以计算出节点d的上一跳节点的EAX值,并由此依次循环计算出所有节点的EAX 值。此外在EAX(Fs,s,d)的计算中,对于相同的节点s和d,由于转发节点集合F的选取不同,会存在多个不同的EAX值,因此选取其中的最小值作为这个节点的EAX值。
在计算出某个节点i的所有转发节点集合Fi的EAX 值后,便可以选择转发节点集合。具体过程为先找到EAX值最小的转发节点集合EAXmin以及EAX值小于等于1.1 ⋅EAXmin的所有转发节点集合,再统计这些转发节点集合中两两节点互不为邻居的个数Nneighbor,最后选取Nneighbor值最大的转发节点集合作为节点s的转发节点,若Nneighbor值相同,则选择EAX 值较小的转发节点集合。
3.3 链路相关性指标的计算
在3.1 节与3.2 节中已给出转发节点的期望转发计算公式以及基于EAX 值选取转发节点集合的方法,然而其中关于链路相关性的部分并未给出具体计算方法。因为在考虑了链路相关性之后,公式(1)、(2)、(5)、(7)中的几个概率无法仅仅通过链路丢包率计算得到,需要进一步收集链路信息才能得到链路相关性指标。
关于链路相关性指标的衡量方式,现有的研究有如下几种。文献[9]中提出条件包接受率(Conditional Packet Reception Probability,CPRP),定义为低接收率的节点在收到来自发送节点的数据包的情形下,高接受率的节点也收到发送节点的数据包概率。文献[10]定义汉明距离用来衡量链路相关性。通过位图(bitmap)记录两个链路对同一个发送者发送的广播包的接收情况,对比对应位是否相同,对应位相同则汉明距离加1,汉明距离即为两个位图不相同的位数和。汉明距离越大表示两条链路间相关性越小。文献[11]中作者提出用相关系数衡量链路相关程度,并利用其分布准确地估计了机会路由协议的性能,同时指出文献[9]中利用条件概率估计链路相关度存在偏见问题。因为CPRP 会受到链路不稳定性和链路突发性等因素的影响。作者此外还定义了相关性指标ρ用于表示两条链路间的相关程度。针对相关性指标ρ的取值范围不严密的缺点,作者又提出了归一化的相关性衡量指标K用于表示两条链路接收数据包的线性相关程度。K的取值范围为严密的[-1,1],不同的K值反应链路对的不同相关程度,K=0 表示两条链路相互独立,K>0 表示两条链路正相关,K<0 表示两条链路负相关。遗憾的是,上述指标只能衡量两条链路之间的相关性,并且候选转发节集合中节点个数不超过2。实际上在真实的无线网络场景中,在一定范围内多个转发节点接受数据包会受到同一个干扰源的影响。
在本文提出的机制中,为了衡量多条链路之间的相关性,转发节点会周期性地发送接收报告(reception report),每条接收报告记录了某个邻居节点发出的多个数据包在本节点的接收状态。例如,[f,50,11001001]表示某个节点最近收到的邻居节点f发出的数据包编号为50,接收到编号为43、44 和47 的数据包,而丢失编号为45、46、48和49的数据包,“11001001”称为“位串”。
在此基础上,链路相关性指标计算过程如下:设φi为ETX 值小于i的节点集合,Bij(ε)为上述位串中第ε位的值,表示节点j是否收到节点i发出的某个数据包。于是节点i和节点j之间的链路丢包率为:

其中,m为节点i发出的数据包个数,即位串的位数。为了计算节点j成功接收到节点i的数据包,而ETX值比j小的节点未收到这个数据包的概率,假设Aij(ε)=1表示节点j成功接收到节点i的第ε个探测包,同时ETX比j小的节点都没有接收到的情况,则有:

再计算ETX 值比j小的节点未收到节点j发出的数据包的概率,假设Ci(ε)=1 表示ETX 比节点i更小的节点都没有收到第ε个数据包的情况,则有:

下面以一个具体的例子使用上述公式计算链路相关指标。
如图5所示,节点s为节点i,j,k的上游节点,节点s发送8个数据包,节点i,j,k分别发送确认数据包。位串初始状态各位均为0,节点i,j,k每收到一个数据包就将位串中相应的位置1,最后将包含位串的接收报告进行广播。当节点s接收到这些接收报告后,便能根据公式(8)以及图中各个节点的位串计算得到Ps,i、Ps,j、Ps,k分别为0.5、0.625、0.375。假设ETXi>ETXj>ETXk,针对节点i,根据公式(9)和(10)计算得到其链路相关性指标如下:

同理可得其他链路之间的相关信息。利用这些链路相关性指标,便可计算出各个节点每收到一个数据包所需的转发次数TX_credit。
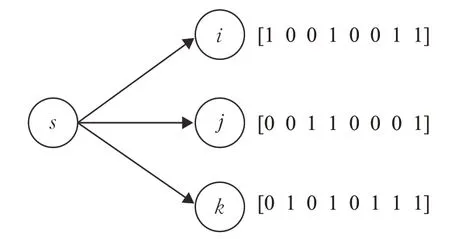
图5 链路相关性指标计算示例
4 算法实现
4.1 考虑链路相关性的节点转发次数计算方法的实现
源节点在开始发送数据包前发送一个泛洪请求,每个接收到这个请求的中间节点将与本节点相关链路的丢包率Pi,j发回给源节点。源节点收集到各条链路的丢包率Pi,j之后,计算出各节点到目的节点的ETX 值,以此确定转发节点,并将选取的所有转发节点记录在数据包头部的转发节点列表当中。此外,将每个转发节点按ETX值非降序排列,并依次编号为n,n-1,n-2,…,1,0,显然源节点编号为n,目的节点编号为0。
接下来设置源节点Ln=1,除源节点以外所有节点所需的发送次数Zi设置为0,源节点根据收集到的接收报告计算出Zn,并将其携带在需要发送的数据包中,然后将数据包发送出去。
对于每一个转发节点k,当收到一个新批次的编码包时,查看该数据包中的转发节点列表,找出它的所有的上游节点,并向它所有的上游节点请求链路相关性指标,收到之后利用公式(1)~(3)计算自己的TX_credit值和Z值。同时,节点k还会维护并更新所有上游节点Z值记录,并向Z值发生变化的上游节点请求新的链路相关性指标和链路丢包率等信息,以重新计算本节点的TX_credit值和Z值。当收到ACK数据包时,则清空当前的Z值记录、链路相关性指标以及各链路丢包率信息,并重新找出新批次的上游节点集合,开始计算新的TX_credit值和Z值。
另外,为了将本节点所需的转发次数Z值通知给下游节点,需要修改数据包编码层的头部格式,修改后如图6 所示,在每个TX_credit值后面加入一个字段用于存放Z值,其他字段的详细解释见文献[3]。
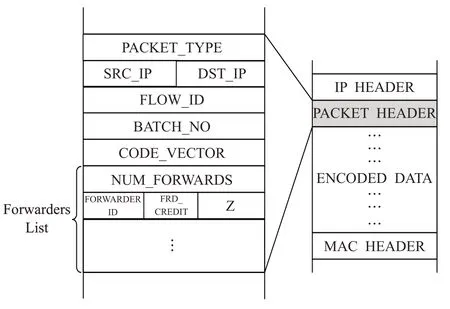
图6 修改后的数据包编码层头部格式
4.2 考虑链路相关性的转发节点选取算法
算法的核心思想是在多个转发节点集合中选取出一个具有最小EAX值的集合。由于EAX值的计算考虑了链路相关性,因此使用该算法选取的转发节点集合理论上具有更少的传输次数。转发节点集合选取算法如下所示,其中set_size表示假设的转发节点集合大小。N(s)为节点s的邻居节点,Fresult为选取出的转发节点集合。
算法1 转发节点集合选取算法FN_Select(s,d,set_size)
1. Fresult=Ø;Finitial=Ø;eax_min=∞;eax_temp=∞;
2. for all v ∈N(s) do
3. if ETX(v,d)<ETX(s,d) then
4. Finitial=Finitial∪v;
5. end if
6. end for
7. while| |
Fresult<set_size do
8. C_temp=arg minc∈Finitial{EAX(Fresult∪c,s,d)}
9. eax_temp=EAX(Fresult∪c_temp,s,d);
10. if eax_temp <eax_min then
11. Fresult=Fresult∪c_temp;Finitial=Finitialc_temp;
eax_min=eax_temp;
12. else
13. break;
14. end if
15. endwhile
算法1中1~6行在节点s的邻居节点中找出比节点s具有更小ETX 值的邻居节点并保存在集合Finitial中;在7~15行的循环中,每当寻找到具有更小EAX 值的转发节点集合,就将这个EAX 值以及此时的候选转发节点集合记录下来,直到找不到具有更小EAX 值的候选转发节点集合,或者转发节点数目达到了预先设定好的set_size值。退出循环后,集合Fresult为算法所得的转发节点集合。
考虑算法的开销,没有对转发节点集合大小set_size进行限制,即当set_size=n时(其中n为所有备选的转发节点的个数),由于c_temp=arg minc∈Finitial{EAX(Fresult⋃c,s,d)}暗含了一个循环结构,所以算法1的时间复杂度为O(n2)。显然当n的取值较大即网络中的节点分布紧密时,算法的时间复杂度会上升的很快,因此,为了降低转发节点选取的计算开销,取set_size=4。
4.3 算法开销分析
本节将对算法的通信开销进行分析,在NCCLCOR中引入的通信开销分为两部分:
(1)每个节点周期性地向邻居节点发送探测包,并接收邻居节点反馈的ACK 数据包,以计算与邻居节点之间链路的丢包率以及多条链路之间的相关性。
(2)每个节点周期性地向上游节点发送本节点到某个目的节点的EAX 值,以便上游节点计算自己到对应目的节点的EAX值,并且选择转发节点。
需要指出的是,(1)中的开销,其他协议(例如MORE、EXOR)也可能需要,而(2)中的开销,是本文提出的NCCLCOR协议所特有的。
针对(1)中所述的开销,分析如下:假设网络中有n个节点,每个节点的平均邻居节点个数为m,每次探测过程中节点都发送50个hello探测包,每个hello探测包及其ACK确认包的大小均为40 Byte。
因此在不考虑丢包以及冲突的情况下,通信开销为n×50×40+n×m×50×40=200×n×(1+m)Byte。假设时间周期T为30 s,n为25,m为4,则探测过程消耗的平均带宽为200×25×(1+4)×8/30 ≈6.67 kb/s。
针对(2)中的所述的开销,分析如下:假设网络中有l条流,所有流的平均跳数为h,每个节点的平均邻居数为m,那么每个时间间隔T内传输这些相关性信息平均所需的转发数据包个数为l⋅h⋅m个。
假设网络中节点个数为25,l为100,h为3,m为4,T为30 s,则每个通知数据包大小上限为(40+25×2)Byte,用于传递这些EAX 值所消耗的带宽约为100×3×4×(40+25×2)×8/30=28.8 kb/s。
为了验证本章对通信开销的分析,本文将在后续的仿真实验中对算法的开销进行验证分析。
5 仿真实验
对MORE[3]、LCAOR[12]以及本文提出的NCCLCOR进行仿真实验,并比较它们在整体吞吐量方面的表现。之所以选取LCAOR 协议,是由于它在选取转发节点时考虑了链路相关性的影响,实现了对机会路由机制的优化,但是并未引入网络编码,与之对比能看出在链路相关性感知的机会路由机制中引入网络编码技术所带来的吞吐量提升的程度。
本文参考MORE以及LCAOR中使用CDF(累积分布函数)来对比不同协议的吞吐量表现。CDF定义为对于实随机变量x,有F(x)=P(X≤x)。在仿真实验中,x轴为流的吞吐量,F(x)即为吞吐量低于x的概率。直观上来看,在CDF 中曲线越靠右意味着对应的协议中整体吞吐量更高。
同时,由于算法需要收集网络中的信息,这会造成额外的通信开销。为了分析并对比这种开销,5.2.4小节对实验过程中三种协议的额外带宽开销进行了对比分析。
5.1 实验环境和参数设置
由于NS2中的丢包策略为随机的,并且链路的丢包相互独立,因此需要在NS2中加入干扰模型实使链路丢包呈现相关性。同现实中的干扰源一样,在干扰源干扰半径内的所有节点接收转发数据包都会受到影响。离干扰源越近,受到的影响越大,如图7所示。

图7 干扰模型示例
为了考虑干扰源对丢包率Pi,j的影响,采用文献[18]中的链路丢包率概率计算公式:公式(11)。当链路受到干扰源影响时,噪声功率Nij会增加,其计算公式为公式(12)和(13)。
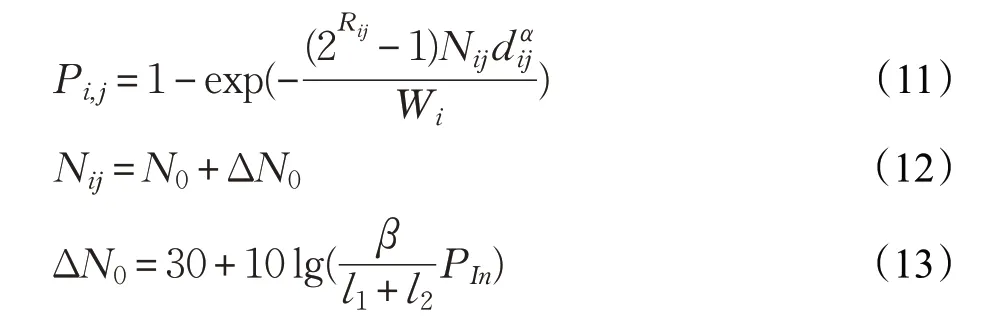
公式(11)中Pi,j为链路的丢包率,Rij表示节点i的发送速率(单位为Mb/s),dij表示链路i到j之间的距离,α表示链路丢失指数,Wi为发送节点的发送功率。
公式(13)中l1为干扰源到发送节点的距离,l2为干扰源到接收节点的距离,PIn为干扰源的功率。β为干扰系数。在后续的仿真实验中,取Rij=11 Mb/s,Wi=10 dBm,PIn=16 dBm,N0=-102 dBm,其中α=4,β=1。
实验环境和参数设置如下:在1 000×1 000 的区域内随机部署25 个节点,随机生成50 种拓扑结构。每个节点在数据链路层都运行802.11b 协议,转发队列缓冲区大小设为50 个数据包,链路带宽设为5.5 Mb/s,丢包率随机选取。随机选择源节点和目的节点,生成100条TCP流,每个数据包大小为1 500 Byte,每条流传输一个5 MB大小的文件。网络中收集下游节点成功收取数据包信息的时间周期T设置为30 s。在NCCLCOR 中,batch size设为32。随机生成50种拓扑结构,在每种拓扑中随机选择一对节点作为源节点和目的节点进行数据传输。
5.2 实验结果分析
现实情况中干扰源无处不在。因此在实验过程中考虑引入数量不等并且位置固定的干扰源,测试不同相关性程度下三种协议的表现。
5.2.1 单个干扰源
图8展示了干扰源为一个的情况下三种协议的所有100条流的吞吐量分布情况。观察图8可知,NCCLCOR大约90%的流的吞吐量要大于1 Mb/s,在该比例下,MORE 和LCAOR 分别仅为0.4 Mb/s、0.75 Mb/s 左右。这说明NCCLCOR的整体吞吐量更高,即NCCLCOR表现优于MORE以及LCAOR。

图8 100条流的吞吐量分布图
众所周知,无线mesh 网络存在连续多跳的情况下网络吞吐量下降会非常迅速。为了比较三种协议在多跳情形下的优劣,在所有100条流中选取出所有经过了4跳及以上且第一跳与最后一跳的传输互不干扰的流,再测试这些流的吞吐量分布情况,结果如图9所示。
图9 展示了干扰源为一个的情况下,上述100 条流中41条经过四跳以上的流的吞吐量分布情况。可以看到,与图8 相比,三种协议因为跳数增加的缘故整体吞吐量都有所下降。但更为明显的是,NCCLCOR所有流的吞吐量都大于1.3 Mb/s,而MORE 和LCAOR 仅大于0.1Mb/s以及0.6Mb/s。这说明在多跳的情形下,NCCLCOR的表现依旧优于MORE和LCAOR。
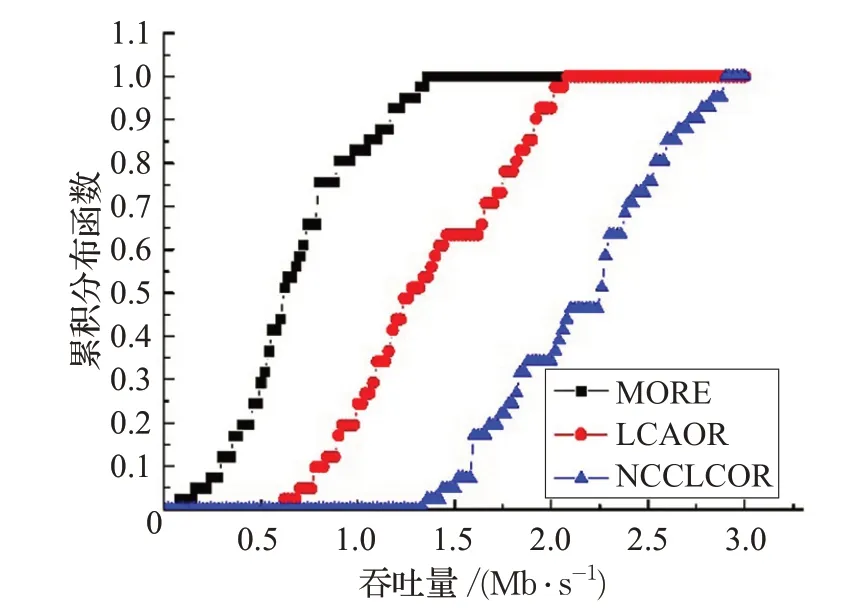
图9 41条4-hops流的吞吐量分布图
5.2.2 三个干扰源
图10展示了干扰源为三个的情况下三种协议的所有100条流的吞吐量分布情况。和图8中一个干扰源的情形相比,三种协议的整体吞吐量都有所下降。NCCLCOR超过90%的流吞吐量大于1 Mb/s,LCAOR 超过90%的流吞吐量大于0.6 Mb/s,MORE 超过90%的流吞吐量大于0.3 Mb/s。这说明,在多个干扰源存在的情况下,NCCLCOR表现优于MORE以及LCAOR。

图10 三个干扰源情形下100条流的吞吐量分布图
依旧从所有100 条流中选取出所有经过了四跳及以上且第一跳与最后一跳的传输互不干扰的流,再测试三个干扰源情形下这些流的吞吐量分布情况,结果如图11所示。

图11 三个干扰源情形下45条4-hops流的吞吐量分布图
图11展示了干扰源为三个的情况下,45条经过四跳以上的流的吞吐量分布情况。观察图11可知,NCCLCOR的45 条多跳流的吞吐量均大于1.3 Mb/s,LCAOR 仅大于0.6 Mb/s,而MORE 只大于0.125 Mb/s。这说明在多个干扰源存在并且经过多跳的情况下,NCCLCOR表现依旧优于MORE和LCAOR。
5.2.3 四个干扰源
图12展示了干扰源为四个的情况下三种协议的所有100条流的吞吐量分布情况。观察图12可知,NCCLCOR所有流的吞吐量均大于1 Mb/s,高于LCAOR的0.5 Mb/s和MORE的0.1 Mb/s。结论与图10所得一致。

图12 四个干扰源情形下100条流的吞吐量分布图
再从所有100条流中选取出所有经过了四跳及以上且第一跳与最后一跳的传输互不干扰的流,测试四个干扰源情形下这些流的吞吐量分布情况,结果如图13所示。
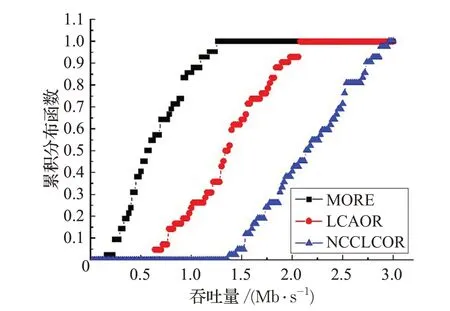
图13 四个干扰源情形下42条4-hops流的吞吐量分布图
图13 展示了干扰源为四个的情况下,42 条经过四跳以上的流的吞吐量分布情况。观察图13 不难发现,NCCLCOR 中所有流的整体吞吐量高于MORE 以及LCAOR,结论与图11所得一致。
以上结果说明NCCLCOR 在多个干扰源存在的无线网络中能够提高网络吞吐量。原因在于NCCLCOR能有效地降低节点的传输次数,由于采用了网络编码,下游节点收到足够的编码包时会通知上游节点停止发送,这样上游节点便能更多地发送其他流的数据包,而又不影响下游节点对编码包的解码。
5.2.4 开销结果及分析
在上述单个干扰源的仿真实验中,测量了单个节点的平均额外带宽开销以及所有节点总的额外开销,结果如表1所示。

表1 三种协议传输50 MB数据的开销统计
从表1的数据可以看出,单位时间内的开销,MORE协议最少。这是因为MORE 协议只需每隔一个时间间隔T传输50个hello探测数据包,然后根据返回的ACK信息统计各链路的成功传输概率,这部分开销统计值和4.3 节中计算得到的6.67 kb/s 相近;而NCCLCOR 协议的单位时间开销最大,这是因为在NCCLCOR中节点不仅需要定期发送hello 探测包,同时还需要定期传输各自到目的节点的EAX值。在NCCLCOR中,由于EAX值是携带在hello 探测包和ACK 包中进行传输的,因此额外通信开销的统计值与4.3节中分析所得的值有偏差。
从传输定量数据的总开销的角度来看,NCCLCOR协议所需的总通信开销只比MORE 协议稍多一点。这是因为NCCLCOR 的整体网络吞吐量相比MORE 协议高,故传输等量数据所需的时间比MORE协议少。
6 结束语
针对无线链路传输存在相关性的特点,本文首先分析了链路相关性对流内网络编码中机会路由机制中节点转发次数和转发节点选取的影响。接着在此基础上提出一种流内编码中考虑链路相关性的机会路由机制NCCLCOR。NCCLCOR在计算节点成功传输数据包所需的期望转发次数时,考虑了链路相关性的影响。通过统计链路的相关性指标,并根据计算出的节点期望转发次数选取出总转发次数最少的转发节点集合。理论上,NCCLCOR 能够有效降低无线网络中转发节点的转发次数,进而减少冲突发生的概率,最终提高网络的吞吐量。NS2上的仿真实验结果表明,NCCLCOR相比ETX机制以及LC 机制能有效降低节点转发次数,降低发送冗余,提高网络的整体吞吐量。
