基于深度极限学习机的水质预测研究
2020-12-26边冰赵明政
边冰,赵明政
(华北理工大学 电气工程学院,河北 唐山 063210)
0引言
水是人类生存和发展的必要资源,同时也是经济发展过程中的命脉[1]。随着我国工业进程的不断推前进,水资源匮乏加剧、饮用水和生活水需求增加,水质、水源和原水的复杂化、分散化和多样化等问题日益加剧,使得传统的生活用水生产方面面临着巨大的挑战[2]。水质预测是指通过大量的历史监测和检测数据,寻求一种合适的数学模型,来分析水质中各指标的变化规律,从而能够准确地对水质进行预测判断,并能及时的地了解水质的现有状况及未来的发展趋势,为水质的预警等方面提供科学的依据。目前,水质预测的方法有数理统计法、人工神经网络法、水质模拟模型法、小波分析法等。李娜等[3]将BP神经网络应用在象山港水环境承载力研究中,结果表明BP神经网络的数据结果直观可靠,可以应用在象山港水环境承载力研究中。费丹[4]通过BP神经网络对大伙房水库进行水质预测,研究表明BP网络在水质预测方面效果良好。查木哈等[5]通过双隐含层BP网络并结合拉格朗日插值法对老哈河中的化学需氧量、生化需氧量、高锰酸盐指数和总磷浓度行了预测分析,研究结果表明该模型的预测性能较好,尤其对总磷浓度预测效果更为明显。Singh K P等[6]使用了11个不同水质指标的数据为依据,构建了2个隐藏层不同的BP神经网络模型,通过对印度某河2个不同的指标进行计算,从而间接地推断出水质好坏。该研究针对河北省某水厂2015年到2016年2年的数据进行分析处理,然后结合天气情况,通过深度极限学习机对NTU、耗氧量、pH值3个指标进行分类预测,对水质的变化采取有效的防御措施从而减少损失。
1极限学习机的理论研究
1.1 极限学习机
极限学习机[7]是一种针对单隐含层前馈神经网络的分类算法,它采用的训练方式为批处理,不需要迭代,隐含层的权值和偏置都是随机选取的,通过计算输出层权值完成学习。根据极限学习机基础依据,它的L1正则化目标函数可表示为:
s.tβTh(xi)=yi-ξ?i,∀i
(1)
(2)
其中训练输出矩阵由H=[h(x1),…h(xn)]T∈Rn×|h(?)|表示。对于测试样本x经由ELM分类输出。其表达式为:
f(x)=β*Th(x)
(3)
1.2 深度极限学习机
深度极限学习机[8]是由多个极限学习机自编码器(auto-encoder,AE)堆叠而成的深度网络。ELM自编码器其实就是令Y=X,从而使得极限学习机的输入与输出相等,那么隐含层特征H就成为了输入训练样本中的一种编码,它的输出权值矩阵如以下公式:
(4)
自编码器可以通过输出权值矩阵将隐含层特征映射为样本,还可以将样本映射为隐含层特征,将多个ELM-AE叠加起来组成多层网络特征提取模型,每层输出特征用公式表示为
Hi=h(βTHi-1)
(5)
其中第i层ELM-AE的特征用Hi来表示,第i-1层ELM-AE的特征用Hi-1表示。随着层数的递增,学习到的特征Hi将变得越来越少。将提取的特征Hi经过分类器进行分类,这样的深度网络称为深度极限学习机,D-ELM的结构图如图1所示。
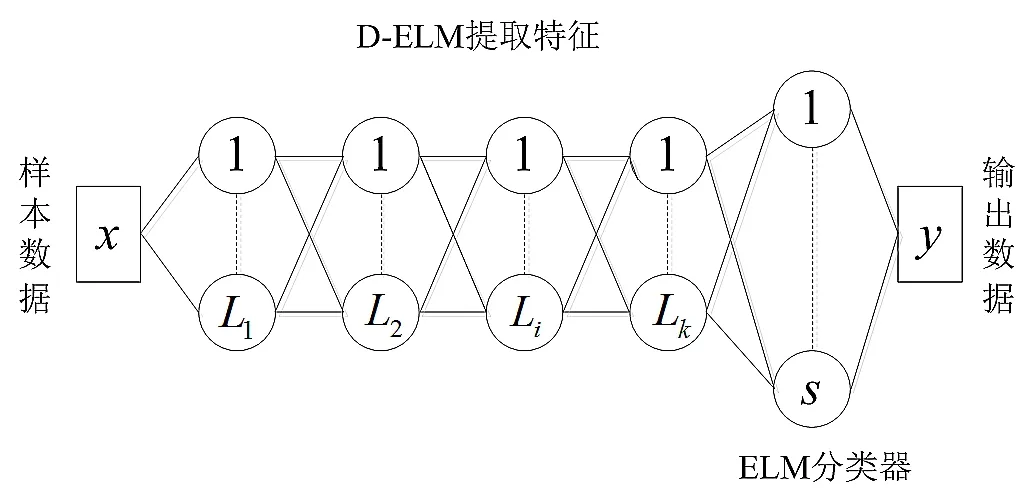
图1 D-ELM结构图
2 实例应用
2.1 研究区域概括
该水厂的位置处于东部季风区,气候属于暖温带滨海半湿润气候,该市平均降水量约为622.2 mm。全市人均饮用水和生活水的占有量为340 m3,大约占我国人均水资源的16.7%[9]。
近几年来,随着经济快速的发展,“四点一带”的建设使国家对水资源提出了更高的要求,从而使水资源的供应与需求的矛盾逐渐增加。随着逐年增加的用水需求和废水、污水量,迫使地表水资源环境发生巨大的改变。从而导致水资源越发紧缺,生态环境破坏加剧,出现了一系列水环境污染问题,进而造成了水资源环境的持续恶化[10]。
2.2 数据采集与处理
该数据资料来源于河北省某水厂在2015~2016年水质日监测汇总表。以2015~2016年2年的监测数据为分析依据,选取表1中耗氧量、pH值和NTU 3个指标因子作为参考对象,采用D-ELM模型对水质进行预测分类。
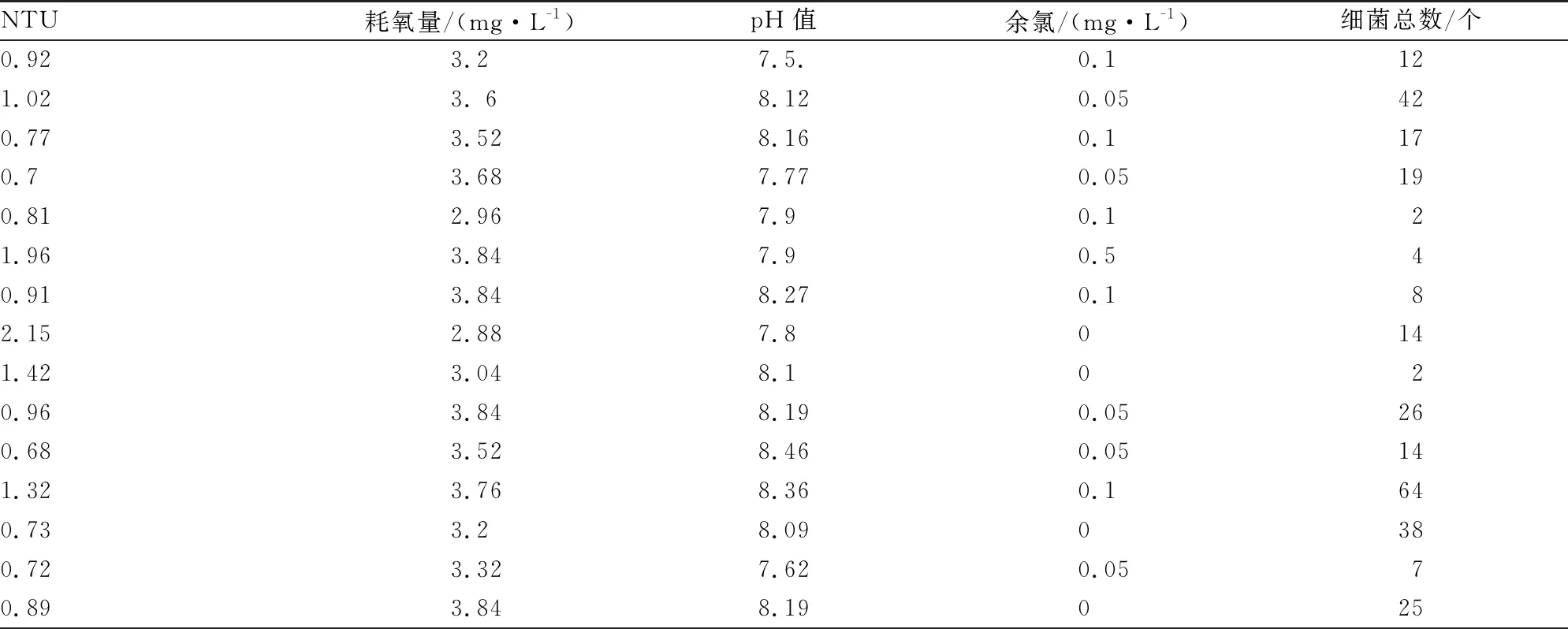
表1 水厂部分指标检测值
针对水质中NTU、耗氧量和pH值的变化,将水质分成了3个等级分别是1级、2级和3级。其水质等级划定如表2所示。

表2 水质等级划定/(mg·L-1)
由于该项研究所得数据中pH值均是大于7的偏碱水,所以在1级中pH值没有设置下限。并且每一级中耗氧量、NTU、pH值均必须在表2中所对应的范围内,如果其中有一项超标都会被分到下一级去。例如耗氧量为1.20 mg/L,NTU为3.0,pH值为7.8,这组数据的水质将被定为2级,而不是1级。
2.3 输入量的确定
由于本实验是用NTU、pH和耗氧量3个指标作为输出量,所以NTU、pH值和耗氧量都必须作为输入量。而一年四季中阴晴雨雪,对NTU这一指标具有很大的影响,故而天气变化也必须作为输入量。该实验对水厂数据利用MATLAB进行线性拟合来判断输入量与输出量相关度的高低,从而确定其它几个指标是否合适。其拟合图如图2~图4所示。
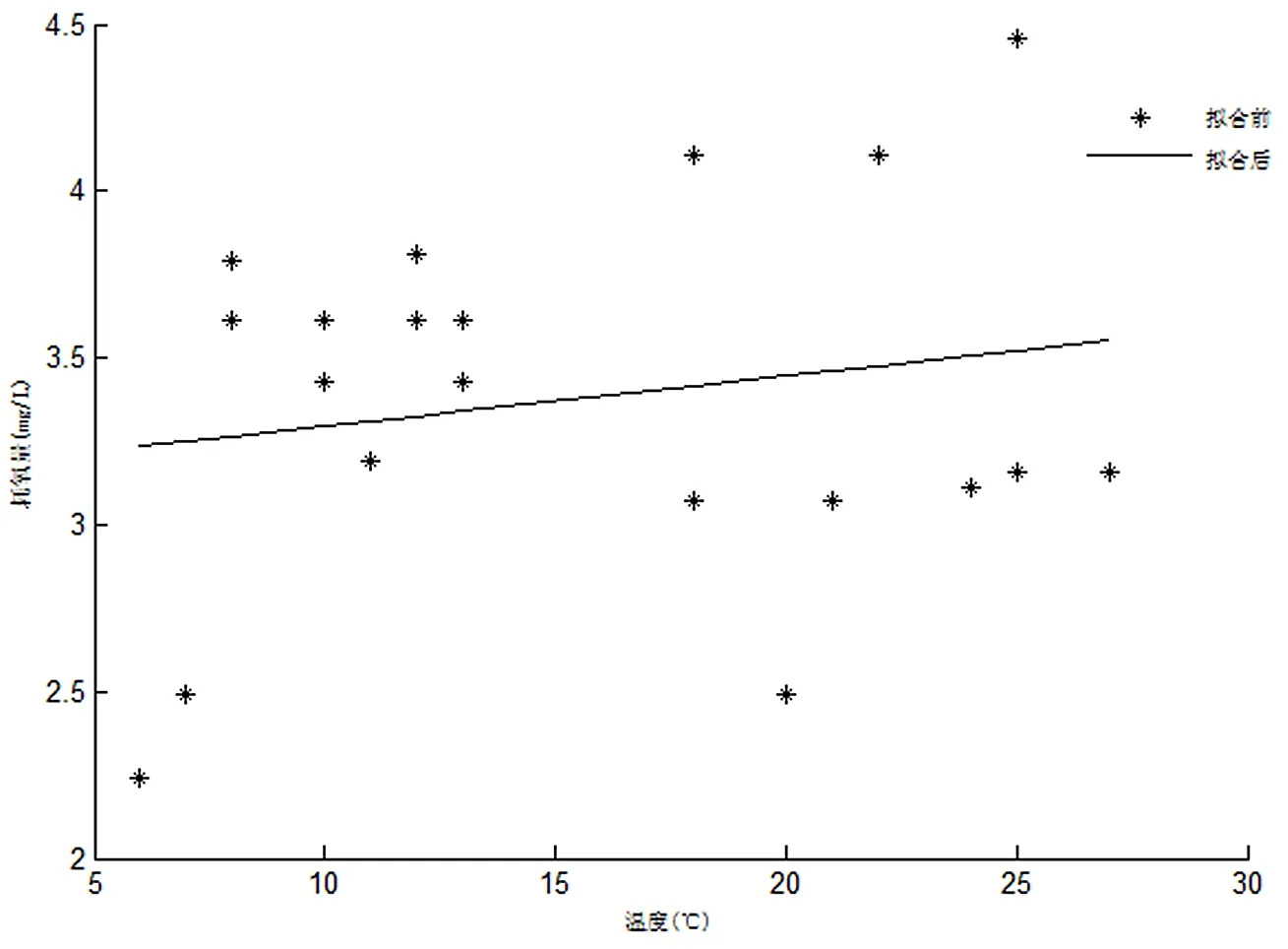
图2 温度与耗氧量的拟合图线
根据图2可知,当温度上升时,水的耗氧量会逐渐上升,从而可以判断出温度与耗氧量的相关度很高,所以温度可作为输入量。
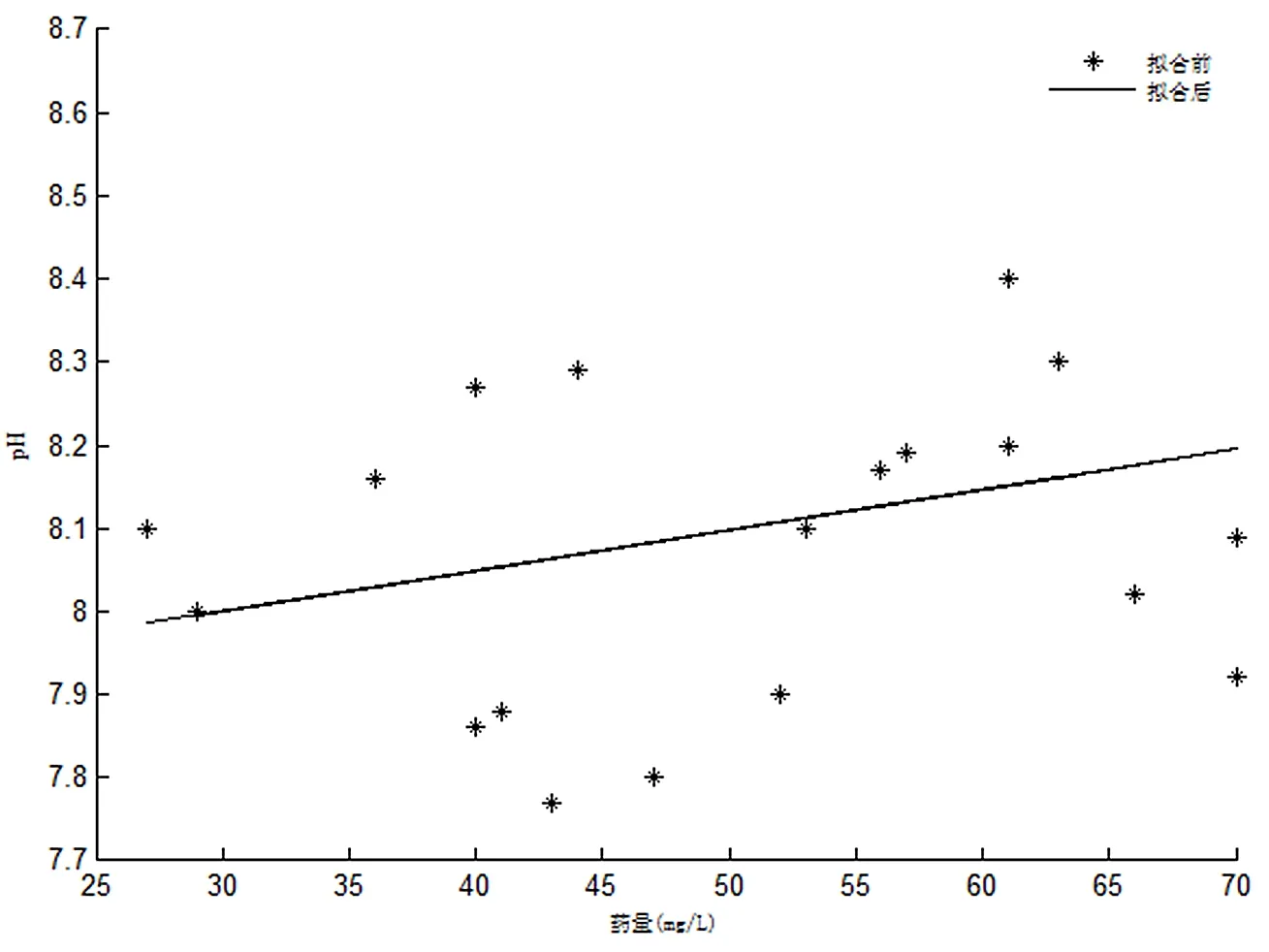
图3 药量与pH值的拟合图线
根据图3可知,当水中投入的药量增加时,水中的pH值也会随之增加,从而可以判断出药量与pH值的相关度很高,所以药量也可作为输入量。
根据图4可知,当余氯的浓度增高时,水的pH值会逐渐下降,从而可以判断出余氯与pH值的相关度很高,所以余氯可作为输入量。
综上所述,本实验输入量的指标分别是天气、余氯、pH值、温度、药量、NTU和耗氧量。
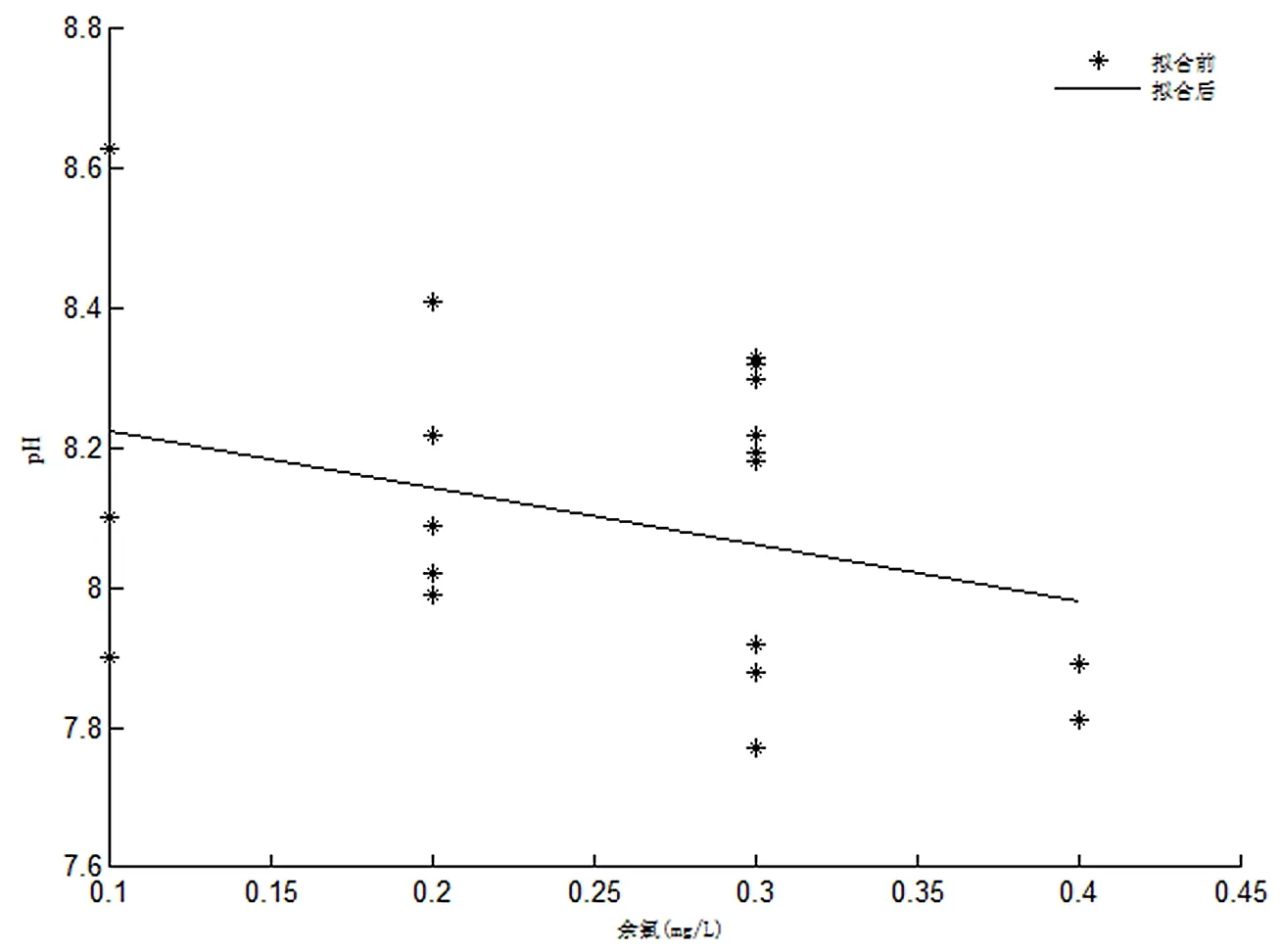
图4 余氯与pH值的拟合图线
2.4 仿真与分析对比
该研究共采用了50组数据,训练样本为系统任意抽取的35组,剩余15组作为测试样本。为了能清晰直观地分析对比仿真结果,该实验通过MATLAB进行仿真,首先给出了深度极限学习机、极限学习机和BP神经网络的误差曲线图。如图5~图7所示。
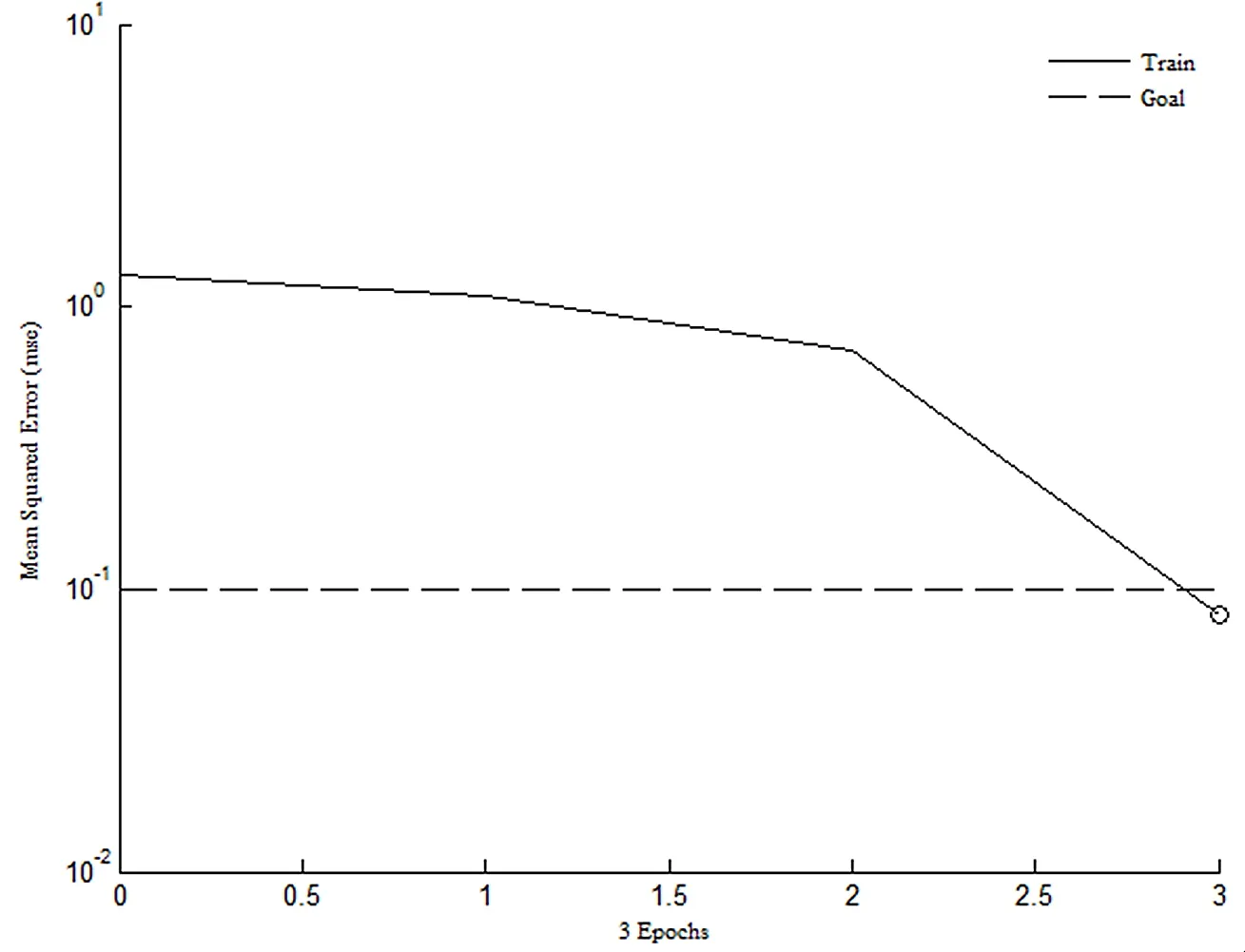
图5 深度极限学习机误差曲线图
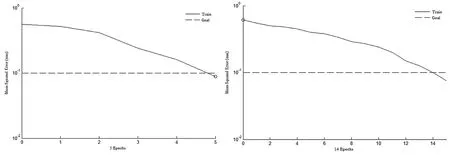
图6 极限学习机误差曲线图 图7 BP网络误差曲线图
通过对图5~图7的进行比较可知,深度极限学习机经过3次训练就可达到误差精度的要求,而极限学习机和BP神经网络要分别经过5次和14次训练才能达到误差精度的要求。
为了进一步确定深度极限学习机与极限学习机和BP神经网络的预测分类效果,将训练好的D-ELM、ELM及BP网络数据输入到测试组,其结果显示如表3和表4所示。
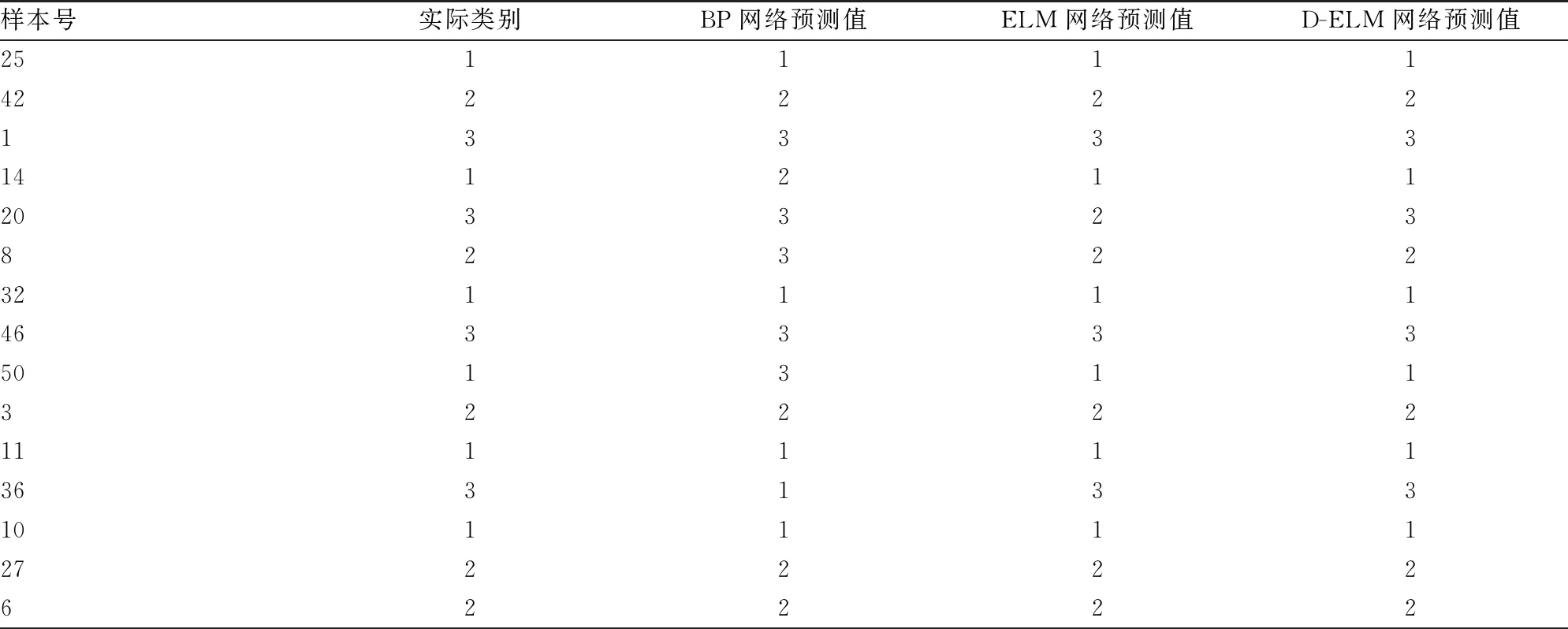
表3 仿真结果1

表4 仿真结果2
由表3和表4可知,从时间上来看,D-ELM的预测时间最短,ELM预测时间居中,而BP网络的预测时长是最长的。从正确率上来看,D-ELM的正确率最高,ELM的正确率次之,而BP网络的正确率最低。
3结论
(1)由仿真分析可以得出,在水质预测方面,D-ELM的准确性和快速性最好,ELM的准确性和快速性次之,BP网络的准确性和快速性最差。
(2)通过3种网络的比较,D-ELM在预测时间和正确率上优于ELM和BP网络,说明D-ELM对水质预测分类方面具有很高的可信度,这给水质预测分类提供了一种简单而又快捷的方法,从而减轻了相关工作人员的压力,也使人们的生活用水得到了保障。
