基于GRU 神经网络的智能家居用户行为识别方法
2020-12-25高建清陈星娥
高建清, 陈星娥
(福建江夏学院 电子信息科学学院, 福建 福州 350108)
0 引言
随着物联网技术的发展, 各种智能产品在家庭环境中得到广泛应用。 在智能家居中, 通过非视觉传感器而不是摄像头来采集数据和识别用户的行为, 有助于消除用户隐私方面的顾虑, 也不受光线条件的影响。 而人口老龄化也是当前社会面临的问题, 提高智能家居环境中的用户行为识别的效率和准确性, 可以提升老年人的用户体验, 减少护理成本[1-4]。
基于传感器的用户行为识别主要有数据驱动和知识驱动两种方法[5]。 常见的数据驱动方法包括朴素贝叶斯( Naive Bayes)、 支持向量机(SVM)、 隐马尔可夫模型(HMM)、 条件随机场(CRF)以及神经网络(Neural Network) 等。 巩莉提出了一种基于改进的支持向量机模型( CSSVM)的日常行为识别算法, 比单独核函数的性能更好[6]。 仝钰采用了基于特征合并的条件随机场行为识别方法, 提高了模型训练效率和行为识别的准确性[3]。 包晓安等提出了一种以基于长短期记忆网络(LSTM) 改进的递归神经网络模型, 预测准确度高于误差反向传播神经网络(BP)模型与递归神经网络(RNN)模型[7]。 薛铭龙等提出一种引入惩罚项的随机森林算法, 具有更高的分类精度与噪声鲁棒性[8]。 数据驱动方法能够处理不确定性和时间信息, 但需要大量数据集进行训练和学习。 知识驱动方法通过构建日常行为领域知识库, 采用本体或者规则的形式进行行为建模和推理。 Chen 等在领域专家先验知识的基础上, 使用基于逻辑的方法进行行为识别[9]。 苏雷等改进了马尔可夫逻辑网络中势函数的计算方法, 对于包含错误的数据集也能达到较高的准确率[10]。 知识驱动方法易于理解和使用, 但是不能处理不确定性和时间信息。
近年来, 在计算机视觉、 音频和语音识别等应用中, 深度学习技术已经超过了其他机器学习算法[11]。 深度学习是神经网络方法的总称, 它基于对原始数据的学习表示, 包含多个隐藏层。 针对序列化的数据常用的神经网络有RNN[5]、 LSTM 以及门控循环单元(GRU)[12], GRU 比LSTM 结构更简单, 训练速度更快, 因此本文提出一种基于GRU的神经网络模型来进行用户行为的识别。
1 GRU 神经网络
新一代的循环神经网络GRU, 是RNN 体系结构的一种变体, 使用门控制机制来控制和管理神经网络中细胞之间的信息流, 解决了传统RNN 的梯度消失或者爆炸问题。 GRU 的结构允许网络自适应地从大量数据序列中捕获依赖项,而不丢弃序列早期部分的信息。 GRU 与LSTM很相似, 但是去掉了细胞状态, 直接使用隐藏状态来进行信息的传递。 GRU 只包含重置门和更新门, 其单元网络结构如图1 所示。
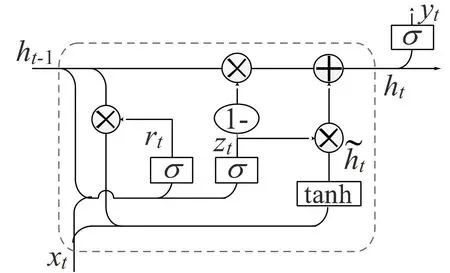
图1 GRU 单元网络结构
重置门用于决定遗忘先前信息的程度, 如图1 中的rt, rt向前传播的计算如式(1) 所示:

式(1)中: σ 为激活函数, 例如sigmoid 函数, 用来将值压缩到0 和1 之间, 为0 则表示这部分信息会被遗忘, 而为1 则表示信息会被保存下来;ht-1是前一步的隐藏状态值, xt为当前的输入数据, Wr为重置门的连接参数矩阵。
更新门用于决定要忘记哪些信息和哪些新信息需要被保留, 如图1 中的zt, zt向前传播的计算如式(2)所示:

式(2)中, Wz为更新门的连接参数矩阵。
候选集ht˜的计算方法如式(3) 所示:
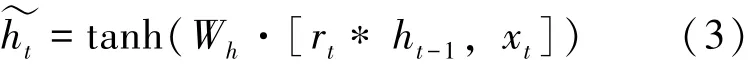
式(3)中, Wh为候选集连接参数矩阵, tanh 函数用来将值始终限制在-1 和1 之间。
下一步的隐藏状态值ht的计算方法如式(4)所示:
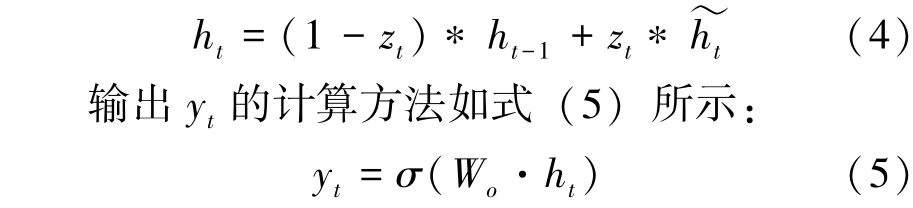
式(5)中, Wo为输出连接参数矩阵。
2 智能家居用户行为识别方法
2.1 智能家居行为识别步骤
智能家居用户行为识别过程一般包括数据采集、 数据预处理、 模型建立与训练、 行为识别5个步骤。 数据集可以通过传感器设备进行采集,也可以采用公开的数据集。 原始数据需要经过预处理, 解决数据冗余、 缺失、 格式非法等问题。此外, 由于使用模型的不同, 提取的数据特征也会不相同, 数据也必须经过处理后才能输入模型。 对于数据序列的分割处理, 常见的方法有基于行为的窗口、 基于时间的窗口以及基于传感器的窗口[6], 本文采用了基于时间的窗口分割方法。
2.2 数据集选取
美国华盛顿大学的CASAS 数据集[13]( http:∥casas.wsu.edu / datasets/)是一种公开的基于传感器的智能家居用户行为数据集, 本文选取其中的Milan 数据集作为实验数据。 该数据集记录了一位女性志愿者和一条狗在公寓里面3 个月期间的日常行为传感器数据, 其中包含门、 运动以及温度3 种类型的传感器共33 个, 包含Master-Bedroom-Activity、 Bed-to-Toilet、 Sleep、 Morning-Meds、 Watch- TV、 Kitchen- Activity、 Chores、Leave- Home、 Read、 Guest- Bathroom、 Master-Bathroom、 Desk-Activity、 Eve- Meds、 Meditate 以及Dining-Rm-Activity 共15 种行为, 其数据格式如图2 所示。
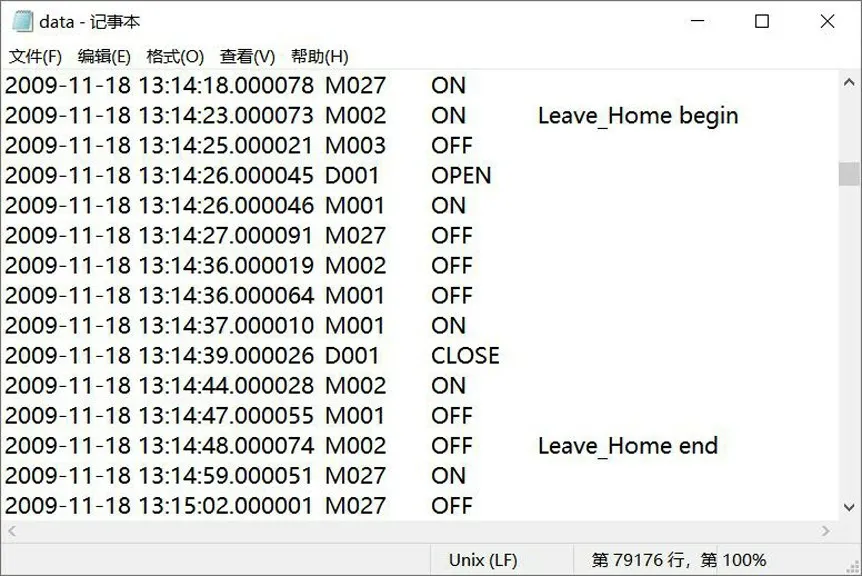
图2 Milan 数据集格式
2.3 行为数据预处理
数据集中的行为标注为文本形式不利于分类处理, 因此对所有的行为依次采用0 到14 进行编号。 每一种行为的标注有开始和结束时间, 而行为识别重点关注的是行为何时开始执行。 数据中所有包含“begin” 的行为标注的时间点就是行为的触发时刻, 提取出所有这些时刻的行为数据, 并把行为编号作为样本的标签值。
2.4 传感器数据预处理
数据集中出现了3 种异常的传感器数据“ON0” “ON`” “O”, 需要全部替换为“ON”。门和运动的传感器记录数据包含打开状态的“ON” 和 “ OPEN”、 关闭状态的 “ OFF” 和“CLOSE”, 全部转为数值表示, 打开状态用1表示, 关闭状态用0 表示。 而温度传感器的数据是实际温度值, 需要进行归一化处理, 采用式(6)进行计算:
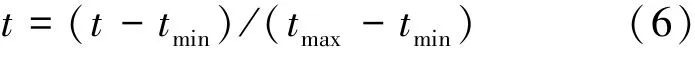
式(6)中: t 为当前时间的温度值, tmax和tmin分别为数据集中的最大温度值和最小温度值。 换算后的温度值再与阈值0.5 比较, 大于阈值的为1,否则为0。
接着, 对于两个行为之间的各个时间点的传感器数据进行合并处理, 以33 维的特征值来表示, 每个特征值为1 或者0。 合并后只保留行为触发时刻的传感器值, 与行为标签一一对应, 而其他时刻只做传感器值的更新。 经过处理后的某个时刻的传感器数据用xt表示, 则xt={s0, s1,…, sm} , 其中0 ≤m ≤32, sm的值为1 或者0。样本数据用at表示, 则at={xt, yt} , 其中0 ≤yt≤14, 表示该时刻对应的行为编号。
2.5 基于GRU 的行为识别神经网络模型
基于GRU 的行为识别神经网络模型包含了2 层的GRU 神经网络, 128 个隐藏节点, 以及一个全连接层, 如图3 所示。 GRU 神经网络对序列数据进行预测时, 可以设定序列数据的窗口大小, 本文选取的窗口大小为3。 如果用Xt表示当前的输入数据, Yt表示当前期望输出, 则Xt={at-2, at-1, at}, Yt={yt} 。 因此, 输入层的数据为1*3*33 的三维张量, 也就是每批一个样本, 样本里面有3 个时间点的33 维的传感器特征值。 GRU 神经网络输出的隐藏状态的值作为下一步的部分输入数据, 实现网络的记忆功能,而当前的网络输出结果通过Softmax 函数实现离散化概率分布, 再通过全连接层输出1*15 的二维张量。 输出二维张量中的第二维的15 个数值,表示每一种行为的预测概率, 最大值的下标即为预测结果, 也就是对应行为的编号。
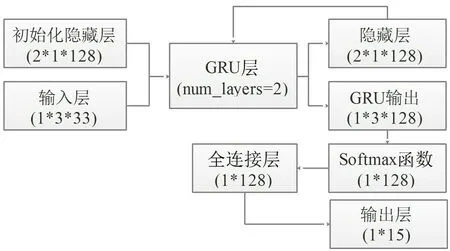
图3 基于GRU 的行为识别神经网络模型
因为是多分类输出, 所以网络模型预测效果的衡量采用了交叉熵损失函数, 该网络模型训练2 000 步的loss 值的变化情况如图4 所示, 可见网络模型的loss 值在500 步左右就能很快地下降到较低点, 对于训练集已经能够达到较好的预测结果。 网络的梯度更新规则采用了RMSProp 优化器, 克服在更新中摆动幅度过大的问题, 进一步加快收敛速度。
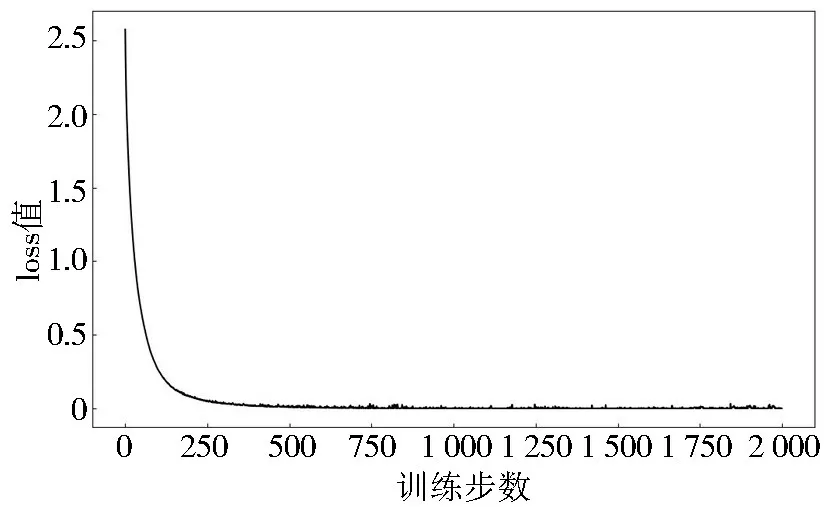
图4 loss 值变化曲线图
3 实验与结果分析
3.1 数据选取与评估方法
通过对Milan 数据集的预处理, 并去掉刚开始时部分传感器未有值的数据, 得到22 278 个样本数据。 按照时间顺序选取其中的20%作为测试数据, 剩下的80%作为训练数据, 测试和训练的样本个数分别为455 和1 823。
为了测试行为识别的效果, 本文采用Precision、 Recall、 F-Measure 和Accuracy 等4 个指标来衡量, 各个指标的计算方法如下:


式(6) ~(9) 中: TP 代表正确识别的个数、 FP代表错误识别的个数、 FN 代表没有识别出的个数, Total 为总的样本数。 Precision、 Recall 和FMeasure3 个指标是先对每一个行为的识别结果进行计算, 然后再按照每一个行为的样本比例进行加权平均, 而Accuracy 指标是对所有行为的识别结果进行计算。
3.2 结果分析
实验环境采用python 开发语言, 结合pytorch神经网络框架来实现基于GRU 的行为识别神经网络模型算法( 本文算法) 和RNN 算法, 使用Sklearn 机器学习工具包来实现Naive Bayes 与SVM 算法。 GRU 和RNN 算法的输入窗口大小为3, 输入特征维数input- size 为33, 批次大小batch-size 为1, dropout 为0.2, 隐层单元个数hidden-size 为128, 层数num- layers 为2, 输入大小output- size 为15, 学习率learn- rate 为0.0003。 Naive Bayes 算法采用多项式模型, 参数alpha 设置为1.0。 SVM 算法采用高斯核函数和一对多策略, C 值为1.0, gamma 值为0.5。
4 种算法对各种行为识别的F-Measure 值如图5 所示, Naive Bayes 有5 种行为未能识别,SVM 有3 种行为未能识别, 而RNN 算法和GRU只有两种行为不能识别。 本文算法有7 种行为的识别效果优于其他方法, 而RNN 算法和SVM 算法都只有3 种行为的识别效果比其他方法好。 4种算法的平均识别效果如表 1 所示, 从Precision、 Recall、 F-Measure 和Accuracy 等4 个衡量指标来看, 本文算法都比其他算法更好。
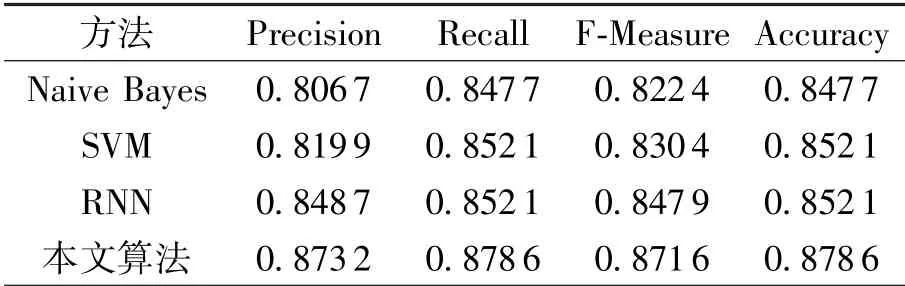
表1 四种方法的识别效果对比

图5 4 种方法的各种行为识别的F-Measure 值对比
4 结语
基于GRU 的行为识别神经网络模型能够记忆具有时序特征的传感器数据, 通过对预处理后的智能家居行为数据集的对比实验, 本文算法的识别效果优于Naive Bayes、 SVM 以及RNN 算法。采用神经网络方法可以不用通过先验知识去分析和提取数据特征, 适应性更强, 但是也存在训练时间较长的问题。 本文算法和RNN 训练2000 步的用时分别为7 h 和9 h 左右, 而Naive Bayes 与SVM 在1 s 以内就能完成。 此外, 本文只研究了智能家居环境中的单用户行为的识别方法, 下一步将继续改进模型, 进行多用户行为以及异常行为等方面的识别研究。
