基于语音识别的密语口令翻译系统
2020-12-24赵文杰薛永奎陈磊刘镇瑜霍烁烁
赵文杰 薛永奎 陈磊 刘镇瑜 霍烁烁
摘 要: 为解决军队在执行使用密语口令指挥的试验任务中,缺少对口令实时翻译显示的问题,将语音识别技术运用到密语口令翻译显示系统中,利用微软语音识别引擎对口令语音进行识别,根据口令对应的明语,将识别内容进行切词和翻译,并将翻译后的明文内容通过网络发送至显示端后投影至试验指挥所大屏,为指挥大厅内观摩人员提供试验参与装备、实施过程及结果等重要内容的显示,设计了一个密语口令语音实时识别翻译系统,实现了密语口令语音到明文显示。
关键词: 语音识别;密语口令;Speech SDK;口令识别
中图分类号: TP391.41 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.07.048
本文著录格式:赵文杰,薛永奎,陈磊,等. 基于语音识别的密语口令翻译系统[J]. 软件,2020,41(07):235-238
Password Translation System Based on Speech Recognition
ZHAO Wen-jie, XUE Yong-kui, CHEN Lei, LIU Zhen-yu, HUO Shuo-shuo
(Luoyang Electric Equipment Test Center, Henan Luoyang 471000)
【Abstract】: In order to solve the army in the use of secret password command test tasks, lack of password display real-time translation, translate speech recognition technology applied to secret password display system, using the Microsoft speech recognition engine to password voice identification, according to the password corresponding plain language, cut identify content words and translation, and will be translated clear text content through the network to show end projection to test after command post screen, for staff, command hall view test in equipment, process and result, etc, according to the important content of the design a secret password speech translation projection real-time identification system, It realizes the speech of password to plaintext display.
【Key words】: Speech recognition; Password recognition; Secret password; Speech SDK
0 引言
在軍队试验任务的组织实施中,试验指挥是通过密语口令下达试验命令的,且指挥口令以密语形式进行传播的。在试验任务实施过程中,指挥口令的翻译显示可以使指挥大厅内观摩人员掌握参试装备、试验过程、进度和结果等重要内容,是试验指挥显示中一个十分重要的要素。
当前试验任务中对仅为指挥大厅内部人员提供密语口令表,虽然可以根据此表对试验中的口令进行翻译,但是由于试验过程中指挥员口令的下达与自他参与者的回复都是十分迅速和频繁的,指挥大厅内除指挥员外的其他人对通过口令了解试验信息是十分困难的,这对试验任务组织实施和观摩造成很大不便。随着语音技术的发展,语音识别技术已进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域[1]。但是由于军用数字口令发音与正常数字发音不同,使通用语音识别程序不能达到军用口令识别的效果,本文主要工作是运用语音识别技术,构建了一个密语口令识别翻译系统,实时识别指挥语音口令并翻译为明文,而后再通过网络投影至指挥大厅观摩屏进行实时显示,为试验指挥大厅内部人员提供参试装备、试验实时进度、结果等的显示说明。
1 系统设计
1.1 需求分析
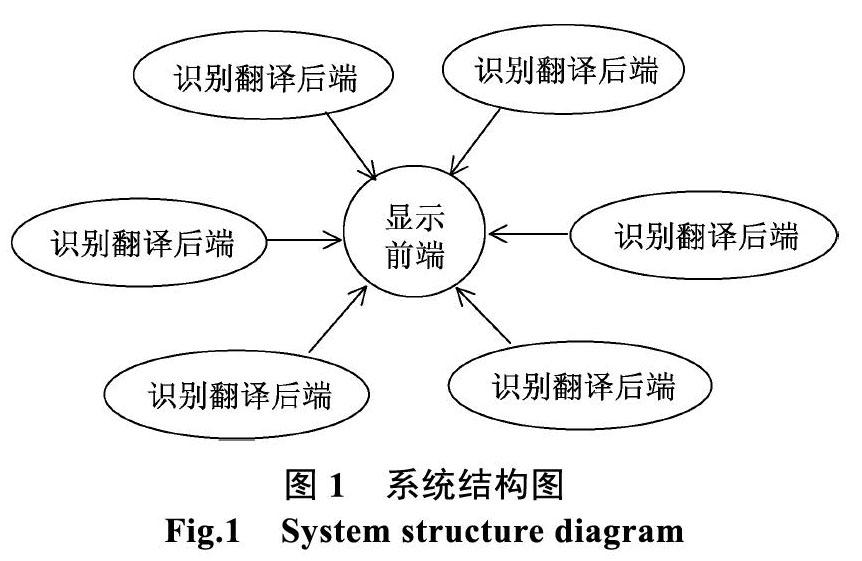
正文内容。在试验任务中,一般试验指挥人员是在指挥大厅内通过调度、电台等通讯设备进行指挥的,由于试验任务的复杂性,可能有多个试验指挥人员同时指挥不同的试验科目,参与的通信设备也可能有调度和多部电台同时使用,因此本系统需要同时具备多个口令语音识别的客户端同时运行,对翻译后的内容应按时间顺序进行汇总显示。因此本系统设计为可根据需要同时运行在多个计算机上的口令识别翻译后端软件和一个接收汇总翻译内容的显示前端软件。该系统结构图如图1所示。
1.2 功能设计
显示前端软件的主要功能为将接收到后端软件发送的信息进行解析、显示和存储。
口令识别翻译后端软件功能如下:
(1)加载密语库。加载试验口令的密语库,该库定义了口令和其对应的明文解释,是系统进行口令翻译的依据;
(2)语音口令识别。获取计算机系统外设语音拾取设备的语音信息,并对其进行识别;
(3)口令翻译。对识别后的口令语句进行切词,并依据密语库进行明文翻译;
(4)网络发送。将翻译内容通过试验网络发送至显示前端;
(5)信息存储。对前端地址以及发送的数据等信息进行存储。
2 系统关键模块实现
2.1 加载密语库
密语库定义了口令和其对应的明文解释,是系统进行口令翻译的依据。该库由试验师根据试验需要编订,主要用来存储密语口令的口令和明语信息,包括参与试验装备代号和名称、试验实施动作、装备工作方式、结果上报信息等。根据实际需要采用EXCEL表格作为密语库的载体,系统通过调用COM组件的方式读取EXCEL密语库的内容[2]。
2.2 口令语音识别
(1)识别引擎Speech SDK介绍
近些年来,语音识别技术在国内发展迅速,科大讯飞、搜狗、百度、腾讯等国内公司均推出了自己的语音识别引擎,大部分对中文识别率很高,但基本均需要互联网的支持,不支持离线,对于对保密要求严格的军队来说,都不是最佳选择。
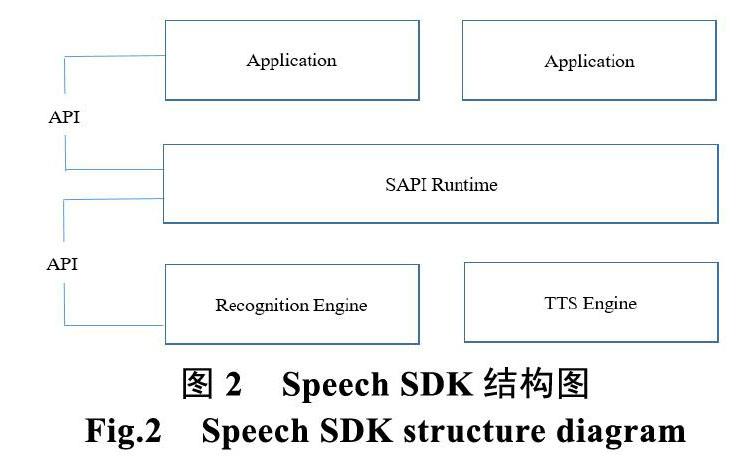
Microsoft Speech SDK是一套语音应用程序开发的软件开发资源包,它完全基于COM标准开发,底层协议以COM组件的形式完全独立于应用程序层,开发人员可以方便使用资源包中的资源开发语音识别和语音合成应用程序,而不必纠结于复杂的语音技术[3],而且Microsoft Speech SDK完全支持简体中文语音系统,且其工作过程可以完全离线,不需要连接互联网,因此,对于有保密要求的军队而言,是一个理想的开发工具。
其中,语音识别有识别引擎Recognition Engine负责,语音合成由语音合成引擎TTS Engine负责,结构图如图2所示。
(2)环境配置
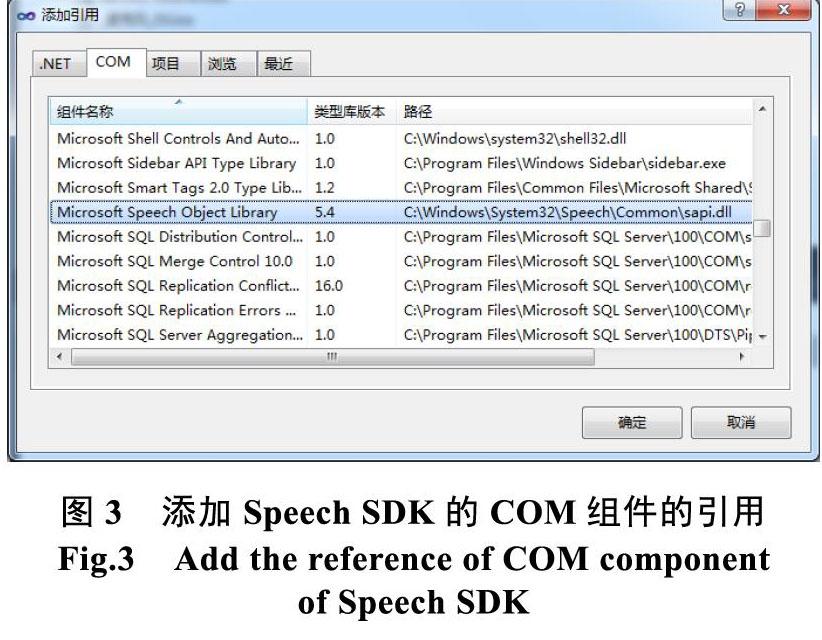
系统在Visual Studio 2010 C#开发环境下,使用Windows7自带的windows Speech SDK 5.4版本的开发包[4],项目创建后,首先需要在解决方案管理器中添加对SDK开发包的COM组件的引用,如下图2所示。
添加引用后在需要调用语音识别引擎的代码头部添加语音识别命名空间的using System.Speech. Recognition引用指令,在需要调用语音合成引擎的代码头部添加语音合成命名空间的using System. Speech.Synthesis引用指令[5]。
(3)语音识别分析
调用Speech SDK中语音识别引擎进行口令语音识别过程如下图4所示。
通过对SDK中SpeechRecognitionEngine类的研究,在以上识别过程中,需要调用Speech?Reco?gni?tionEngine构造函数构建语音识别器,通过Load?Grammar、UnloadAllGrammar等函数管理语音识别语法,通过SetInputToAudioStream、SetInputTo?DefaultAudioDevic等配置识别器输入,通过Recognize或RecognizeAsync方法执行启动单次或连续语音识别,通过设置EndSilenceTimeout等属性设置识别间隔,通过SpeechRecognizedEventArgs事件委托得到识别结果,通过RecognizeAsyncStop或RecognizeAsyncCancel方法停止语音识别,通过调用Dispose进行资源释放[6]。
(4)口令识别语法构建
在军队任务指挥中,口令主要由0-9的十个数字组合而成,但军语对十个数字的口令发音与正常普通话发音存在差异(区别见表1),因此本系统的语音识别任务为对十个数字口令军语发音的组合进行识别[7]。
识别语法构建有两种方式,一种是在XML文件中定义,一种则以编程方式生成[8]。密语口令中,每一句口令均由0-9的十个数字自由组合而成,因此构建语法规则中,关键词限定为:“幺”、“两”、“三”、“四”、“五”、“六”、“拐”、“八”、“勾”、“洞”。由于关键词数量少,选择以编程方式生成语法约束,生成方法为使用GrammarBuilder对象生成由Cho?i?ces包含备用关键词的层次结构树(其中Choices为同包含在System.Speech.Recogniton命名空间中表示可以具有若干值之一的短语集合)。主要代码如下:
string[] numStr = {“幺”,“两”,“三”,“四”,“五”,“六”,“拐”,“八”,“勾”,“洞”};
Choices numChoices = new Choices(numStr);
GrammarBuilder tempGrammarBuilder = new GrammarBuilder();
tempGrammarBuilder.Append(numChoices);
以上代码构建的语法约束仅满足识别单个数字的要求,本文要求识别可变长度的数字串,则需要调用GrammarBuilder类中的重载函数public void Append (GrammarBuilder builder, int minRepeat, int maxRepeat),其中builder为已生成识别单个数字的语法元素,minRepeat和maxRepeat分别表示必须发生构成匹配的语法builder的最小次数和最大次数,为满足可变长度的要求,此处minRepeat必须設定为0,maxRepeat设定为1。根据实际需要,最长识别长度设定为50,则满足识别需要的语法约束剩余代码如下,其中numGrammar为最终语音识别引擎需要加载的语法约束。
GrammarBuilder numGrammarBuilder = new GrammarBuilder();
for(int i=0;i<50;i++)
{numGrammarBuilder.Append(tempGrammarBuilder, 0, 1);}
Grammar numGrammar = new Grammar(numGrammarBuilder);
(5)识别结果处理
语音识别引擎通过LoadGrammar加载语法规则后,为语法的识别事件添加一个处理程序,主要代码如下:
numGrammar.SpeechRecognized + = new Event?Handler
void recognizer_Result(object sender, Speech?RecognizedEventArgs e)
{string result;result = e.Result.Text;//得到识别结果}
经过以上识别过程,通过麦克风拾取的语音信号便转换为文字信息,再根据表1中数字0-9发音对比表将识别结果中字符进行替换,将口令语音字符替换为数字字符,如将“幺”替换为“1”、“两”替换为“2”依次类推,由此得到一串类似于“01102”的识别结果。
2.3 口令翻译
通过语音识别得到一串数字组合的识别结果后,需要根据口令库对识别结果进行切词、翻译。
切词是使用递归算法[9]将字符串按字符顺序拆分为多个字符串子集,假如各子集在密语库中均有对应的翻译,那么该拆分组合便是一次成功的切词。如将“01102”根据密语库中的口令切词为“01,102”(其中“01”表示“装备1”,“102”表示“关机”),由此得出“01102”的明文为“装备1关机”的指令。切词成功后,依据密语口令库进行翻译。
2.4 网络发送与信息存储
网络发送主要是讲口令识别端将识别结果及翻译内容通过网络发送至前端,系统采用Windows操作系统提供的网络套接字(SOCKET)接口实现实时双端网络通信。考虑到系统需要无差错可靠的传输要求以及TCP面向连接的可靠性特点,本系统使用TCP[10]传输口令及相关信息。
信息存储主要是口令识别后端在向显示前端发送数据时将发送内容同步进行存储,存储内容包括发送对象、内容及时间信息等,存储方式采用同2.1中同样的调用COM组件的方式写入EXCEL文件[3],以便于根据保存的口令及翻译内容在需要时复盘整个任务口令的执行过程。
3 识别结果分析
经过对五次试验1020条试验密语口令进行识别测试,测试地点为有一定人声为噪音背景的办公室,麦克风为得胜PCM-5550手持录音麦克风,结果显示:识别正确974条,识别正确率为95.5%;识别错误46条,识别错误率为4.5%。
经过统计发现错误集中出现在以下几处:11(幺幺)识别为16(幺六)、55(五五)识别为5(五)、9(勾)识别为95(勾五),且在系统启动识别后前十条识别中识别错误率最高。分析主要原因除了系统语音识别算法自身原因外,对测试人发音是否标准也有很大关系,因此,若要提高识别正确率,首先发音应尽量标准、无拖音,其次密语库设计中应减少重复数字的出现。
4 结语
本文对语音识别技术应用于军用密语口令识别的可能性进行了研究,分析了密语口令翻译系统的功能需求,研究了微软Speech SDK里语音应用程序接口的结构和工作原理,设计和实现了军用密语口令识别翻译系统,并对系统进行了识别测试,识别正确率达到95.5%,对识别错误的口令进行统计并分析了识别错误的原因,为减少识别错误率提出了发音应标准、密语库中应减少重复数字口令出现等要求。
参考文献
-
高清伦, 谭月辉. 语音识别技术在军用话务台中的应用模拟系统研究[J]. 河北工业科技, 2007(5): 272-274.
-
林鸣霄. 基于SpeechSDK的语音识别技术在三维仿真中的应用[J]. 计算机技术与发展, 2011, 21(11): 160-162.
-
蔡小艳, 李龙腾, 葛玉,等. 基于C#的Excel数据导入导出研究与实现[J]. 智能计算机与应用, 2014, 4(5): 83-85.
-
熊凯. 用C#开发基于Microsoft Speech SDK的语音应用程序[J]. 计算机时代, 2007(2): 40-42.
-
Microsoft speech SDK 5. 4 help[EB/OL]. http://www.micro?soft.com.
-
https://docs.microsoft.com/zh-cn/dotnet/api/system.speech.recognition.speechrecognitionengine?view=netframework-4.8[OL]
-
劉春平. 基于Speech SDK的数字语音识别系统研究[J]. 工业控制计算机, 2012(7): 69-70.
-
黄旭. 基于HTK和Microsoft Speech SDK的连续语音识别系统的研究及实现[D]. 厦门大学.
-
吴素萍. 递归算法与高效算法[J]. 电脑与信息技术, 2007(5): 35-37.
-
赵文杰, 陈磊, 郑全普, 等. 虚拟语音会议系统设计与实现[J]. 软件导刊, 2018, 017(1): 132-134.