基于YOLOv3和YCrCb的人脸口罩检测与规范佩戴识别
2020-12-24肖俊杰


摘 要: 2020年初,新冠病毒席卷全球,为防止其传播,在很多公共场合要求佩戴口罩。利用计算机视觉检测人脸是否佩戴口罩以及识别是否佩戴规范,可以避免检测人员与他人接触感染的风险且更加高效。针对人脸口罩检测问题,提出了基于YOLOv3的目标检测算法,实现对佩戴口罩的人脸和未佩戴口罩的人脸的检测。针对口罩规范佩戴识别问题,则基于前者检测结果,提取佩戴口罩的人脸区域,利用YCrCb的椭圆肤色模型对该区域进行肤色检测,依据人脸中鼻和嘴周围区域的皮肤暴露状况来判断口罩是否佩戴规范。实验结果表明,人脸口罩检测的mAP达到89.04%,口罩规范佩戴的识别率达到82.48%,满足实际应用的需求。
关键词: 人脸口罩检测;口罩规范佩戴识别;YOLOv3算法;YCrCb椭圆肤色模型
中图分类号: TP391.4 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.07.033
本文著录格式:肖俊杰. 基于YOLOv3和YCrCb的人脸口罩检测与规范佩戴识别[J]. 软件,2020,41(07):164-169
Masked Face Detection and Standard Wearing Mask RecognitionBased on YOLOv3 and YCrCb
XIAO Jun-jie
(College of Computer Science and Technology, Wuhan University of Technology, Wuhan 430070, China)
【Abstract】: In early 2020, 2019-nCoV swept the world, and masks were required to wear in many public places to prevent its spread. Using computer vision to detect whether a face wears a mask and recognize whether the mask is properly worn will avoid the risk of contact with others and be more efficient. To solve the masked face detection, a algorithm based on YOLOv3 is proposed to detect faces both with masks and without masks. For the problem of standard wearing mask recognition, masked face area is extracted from the former result and the skin of this part could be detected by YCrCb ellipse skin model, and whether the mask is properly worn is judged according to the skin exposure around nose and mouth in the face. The experimental results indicate that the mAP of masked face detection reaches 89.04%, and the recognition rate of standard wearing mask achieves 82.48%, which can meet the requirements of practical application.
【Key words】: Masked face detected; Standard wearing mask recognition; YOLOv3 algorithm; YCrCb ellipse skin model
0 引言
新型冠狀病毒在全球范围内蔓延,人们的健康受到严重威胁。为了防止病毒在人群中的肆意传播,社会要求人们出行、工作时务必佩戴好口罩。因此,在疫情时期检测是否佩戴口罩,以及口罩是否正确佩戴成为了刚性需求。本文提出利用计算机视觉来进行口罩佩戴和佩戴规范性检测,不仅能避免检测人员和他人接触感染的风险,也能提高检测效率。它可用于机场车站、街道、公园等人员流动较密集场所的监控系统,检测人们佩戴口罩的情况,也可用于小区人脸门禁、企业人脸打卡这类系统,识别人们是否规范佩戴了口罩。此外在日常时期,这些技术仍有用武之地,比如可以检测佩戴口罩的可疑人员、识别医护人员在工作时是否规范佩戴了口罩等。
人脸口罩检测技术可利用深度学习的方法实现。基于深度学习的目标检测算法十分丰富,有YOLO[1-3]、SSD[4]等one-stage系列算法,也有Fast R-CNN[5]、Faster R-CNN[6]等two-stage系列算法。one-stage具有出色的检测速度,却存在较低检测精度的问题。相反,two-stage具有优良的检测精度,但是由于其复杂的网络结构,在检测速度方面却逊色于one-stage。然而,one-stage中的YOLO算法经历了几代的更迭改进之后,逐渐弥补了自身的众多不足之处。从YOLOv1[1]、YOLOv2[2]到YOLOv3[3],在保持速度优势的前提下,不仅在检测精度方面 有了明显的提高,而且对小目标的检测性能有大幅提升。兼顾检测的实时性和准确性两方面,本文 选择了效果优良的YOLOv3算法来实现人脸口罩 检测。
另一方面,关于口罩规范佩戴识别的研究近年来还很少,但受到文献[7]中利用皮肤来检测人脸口罩的启发,联想到可以通过检测人脸中鼻和嘴周围皮肤的暴露状况来判断口罩是否佩戴规范。皮肤检测主要有基于RGB、基于HSV和基于YCrCb的检测算法[8,9]。前人实验研究发现单纯基于RGB或HSV颜色空间来判断皮肤的方法容易受到亮度的影响,鲁棒性較低,而在YCrCb颜色空间中肤色像素具有一定聚类性,分布相对集中,不易受到亮度的干扰,更适合应用于皮肤检测。因此,本文提出利用基于YCrCb颜色空间的椭圆肤色模型[10,11]来解决口罩规范佩戴识别问题。
综上,针对人脸口罩检测和规范佩戴识别问题,本文方法的优势和创新在于:YOLOv3算法检测速度快且精度较高;创新性地利用皮肤检测来判断佩戴口罩的规范性;YCrCb椭圆肤色模型减轻了光线亮度对皮肤检测的干扰,增强了鲁棒性。
1 人脸口罩检测模型
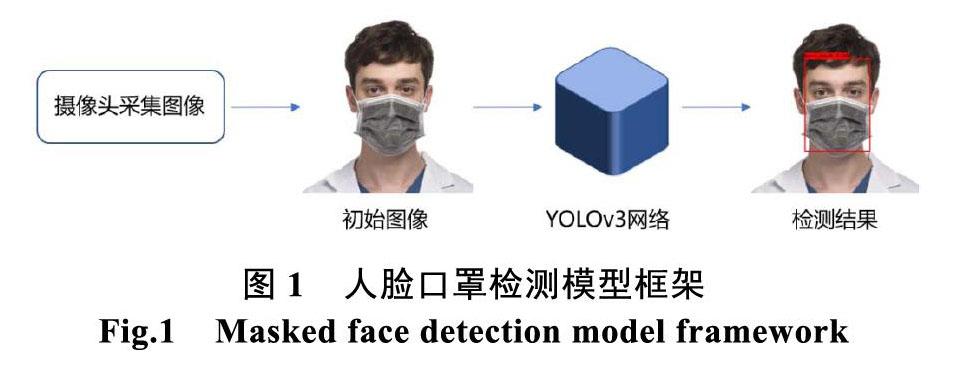
本文采用基于YOLO3算法进行人脸口罩检测。首先可以通过摄像头获取初始图像,在检测时,直接将图片输入事先用特定训练集训练好的YOLOv3模型,快速检测出图像中的佩戴口罩和未佩戴口 罩的人脸。在输出的图像中用不同颜色的检测框框选出对应目标,并标注对应的类别。该部分模型基本框架如图1所示。本节具体从YOLOv3的网络结构以及先验框的尺寸设置来展开介绍YOLOv3算法。
1.1 YOLOv3网络结构
YOLOv3算法和前面两代相比,做出了些许的改变,在保持速度优势的前提下也提升了检测的精度和检测小目标的性能。YOLOv3网络结构如图2所示,主要由两大部分构成:DarkNet53网络和多尺度预测。DarkNet53的作用是对图像进行特征提取,输入该网络的图片大小为416×416。它主要由一系列的1×1和3×3的卷积层构成,一共53个(不包括残差块中的卷积层)。其中每个卷积层后都会跟有一个BN层和一个LeakyReLU层。此外,它借用残差网络的做法,在一些层使用了残差块。每个残差块包含有2个卷积层,所作的工作是先进行一次1×1的卷积,在此基础上,再进行一次3×3的卷积,并将此结果加上原来残差块的输入作为最终结果输入到下一阶段。经过DarkNet53的特征提取后,则是利用多尺度特征图进行对象预测。在该部分,YOLOv3提取了3个不同尺度的特征图,分别位于中间层、中下层、底层。其中,底层进行一系列卷积后,一部分会再经过后续处理作为结果输出,另一部分再做卷积和上采样操作并与中下层的特征图融合,得到中下层粒度较细的特征图。然后将该特征图经过同样的处理,输出对应结果同时再进行卷积、上采样和中间层特征图融合。在中间层只需将融合的图进行卷积操作后输出结果即可。最终,一共会得到3个对应不同尺度的预测结果,每个结果中包含3个先验框的预测信息,每个先验框的预测信息对应7维,分别是坐标值(4)、置信度(1)、种类(2)。关于种类,针对人脸口罩检测种类只有戴口罩和未戴口罩2种。
1.2 先验框尺寸设置
由于人脸口罩检测的环境比较复杂多样,图像中的人脸大小有大有小,使得精准预测物体位置的难度变大。然而YOLOv3算法的anchor机制能够很好解决该问题。在YOLOv3算法中,每个特征图都被划分成多个单元,每个单元会预测多个边框。通过设置先验框的尺寸,会改变这些单元预测框的大小。总共可设置9种尺度的先验框,在13×13,26×26,
52×52的特征图中,分别设置3种先验框,对应地分别适合检测较大的对象,中等大小对象,较小对象。关于这9种先验框尺寸的具体设置,YOLOv3提出的方案是利用K-means聚类算法针对特定的训练集中目标物体大小来确定。在人脸口罩的训练集上,聚类得出的先验框尺寸如表1所示。这样的设置可以检测到绝大多数尺寸的人脸,满足人脸口罩检测各种应用场景的基本需求。
2 口罩规范佩戴识别模型
口罩规范佩戴识别是基于人脸口罩检测结果进行的,该部分的输入是人脸口罩检测的输出且是有佩戴口罩的人脸。首先,将人脸部分的图像提取出来;然后映射到YCrCb颜色空间并进行非线性变换,经过椭圆肤色模型检测后输出一张灰度图,其中皮肤部分像素点为255(白色),非皮肤部分像素点为0(黑色);最后再通过遍历人脸中鼻和嘴周围的像素点,得到皮肤暴露状况,从而判断是否规范佩戴口罩了。识别模型结构如图3所示。本节具体介绍了YCrCb椭圆肤色模型、人脸中鼻和嘴部分的划分、以及通过肤色状况判断是否规范佩戴口罩的逻辑关系。
2.1 YCrCb椭圆肤色模型
YCrCb椭圆肤色模型[11]是Hsu等人所提出的,它能够很好地利用皮肤在YCrCb颜色空间聚类的特点进行皮肤检测,并且降低光线亮度对检测的影响。构建该模型,首先需要将肤色检测的图片从RGB颜色空间转换到YCrCb颜色空间,具体转换公式如下:
得到了原始图片在YCrCb颜色空间的映射之后,还需要对其中Cr和Cb色度进行一系列非线性变换,得到Cr′和Cb′,即得到新的YCr′Cb′颜色空间。与此同时,还要去掉高光阴影部分,采用四个边界限制肤色聚类区域,以此适应原始图片中亮度过明或过暗的区域。皮肤信息在YCr′Cb′颜色空间中会产生聚类现象,其分布近似为一个椭圆形状,如图4所示。
该椭圆区域即为椭圆肤色模型,其计算公式如公式(2)所示,x、y的取值如公式(3)所示。
对于皮肤的检测,只需要求出原始图片中某个像素点在YCr′Cb′颜色空间中的映射Cr′和Cb′,然后根据公式(3)求出对应坐标,再依据公式(2)判断该点是否落在该椭圆区域内即可。如果是,则该像素点判断为皮肤,否则判断为非皮肤。
2.2 人臉区域划分及识别判断
一般来说,人们佩戴口罩不规范的情况可能是将鼻子露出,或是嘴巴露出,或是鼻子嘴巴都露出。所以,识别一张佩戴有口罩的人脸是否将口罩佩戴规范了,可以通过检测其鼻子周围和嘴巴周围的皮肤情况,来判断这些部位是否暴露在外面。要完成该过程,就涉及到鼻子和嘴巴部分的区域划分。经过大量观察并测量人脸口罩检测结果的检测框发现,人脸中,鼻子周围部分所在位置大约在47%~ 67%的高度,嘴巴周围部分所在位置大约在67%~ 95%的高度。这两部分的宽度与检测框的宽度相同。如图5(a)所示。
nose_ymin、nose_ymax分别表示Nose part框的最小纵坐标和最大纵坐标。mouse_ymin、mouse_ ymax分别表示Mouse part框的最小纵坐标和最大纵坐标。width、height分别表示整个人脸图像的宽度和高度。
将人脸口罩检测框部分的图片经过YCrCb椭圆肤色模型处理后,得到一张对应的灰度图,如图5(b)所示。检测为皮肤的像素点设为255(白色),检测为非皮肤的像素点设为0(黑色)。在该灰度图上,遍历鼻和嘴周围部分的所有像素点,得出在对应部分范围里皮肤所占的面积百分比。经过反复的实验测试发现鼻子部分阈值设置为30%,嘴巴部分阈值设置为25%时合理性最高。在进行口罩佩戴规范情况识别时,如果鼻子和嘴巴部分皮肤所占百分比超过对应的阈值,就说明该部分暴露在外面,再基于下面的命题逻辑表达式进行整体判定。
其中,表示佩戴口罩,表示鼻子暴露在外面,表示嘴巴暴露在外面。由于该识别是在已佩戴口罩人脸的基础上,所以一直为true。当表达式(7)真值为true时,识别结果为口罩未规范佩戴;真值为false时,识别结果为口罩已规范佩戴。
3 实验
3.1 数据集
实验采用了WIDER FACE数据集[12]和MAFA数据集[13]进行训练,验证和测试。WIDER FACE是一个比较成熟的开源人脸检测数据集,包含3万多张图片,近40万个人脸,其中,佩戴口罩的人脸不多,但是可以采集到大量没有遮挡的人脸。而相反,MAFA是一个人脸遮挡的数据集,其中大部分的遮挡物为口罩,因此可以从中选取出许多佩戴口罩的人脸。
针对本次的实验,在WIDER FACE数据集中选取了3292张没有佩戴口罩的人脸图片,在MAFA数据集中,选取了3741张包含有戴口罩的人脸图片,一共7033张。对应地,数据集图片里的标签也有2类:have_mask和no_mask。其中,4676张图片用于训练。520张图片用于验证。1837张图片用于测试。
3.2 人脸口罩检测实验结果
将训练后YOLOv3网络模型,在测试集上进行人脸口罩检测的测试,对测试结果从多个方面来进行评价。其中,正确检测表示检测结果和测试样本的类别一致,误检表示将其他物体检测为该类别,漏检表示将该类别的测试样本检测为其他类别或未检测出类别,AP表示该类别的检测准确率均值,mAP表示所有类别检测准确率均值的平均值,即have_mask和no_mask两个类别的平均准确率均值。具体结果如表2所示。
由表2的结果可以看出,在该测试集上have_ mask和no_mask两个类别的准确率均值分别为92.67%和85.41%,它们的平均准确率均值为89.04%,在准确度方面达到了优良的水平。由此可以说明YOLOv3算法检测人脸口罩的准确性有一定的保障。此外,关于检测的速度,可以达到35FPS左右,满足实时性检测的需求。具体检测效果样例如6图所示。红色框为佩戴口罩人脸,青色框为未佩戴口罩人脸,检测框上的数字为置信度。
3.3 口罩规范佩戴识别实验结果
口罩规范佩戴识别是在人脸口罩检测基础上进行的,其测试集从人脸口罩检测的测试集中进一步筛选。筛选的标准是检测结果为有佩戴口罩,人脸正对且倾斜幅度不大。一共选取了451张图片,其中规范佩戴的图片有251张,未规范佩戴的图片有200张。对应识别类别也有两类:masked_well和masked_wrong。测试结果用混淆矩阵表示,如图7所示。
由混淆矩阵可知,规范佩戴口罩类别的识别率可达87%,未规范佩戴口罩类别的识别率略低,只有76%。整体的识别率为82.48%。由此可看出,虽然未规范佩戴口罩的识别率不高,但整体的识别率还是比较理想的,识别效果达到了一定水平。具体识别效果样例如图8所示。绿色框表示识别结果为规范佩戴口罩,红色框表示识别结果为未规范佩戴口罩。
4 结束语
为了解决疫情时期在要求佩戴口罩的场合检测人们是否佩戴了口罩以及识别是否规范佩戴的问题,本文提出了基于YOLOv3的深度学习算法用于人脸口罩的检测,并且可以在该检测结果的基础上,将佩戴有口罩的人脸框部分映射到YCrCb颜色空间并进行非线性变换,通过椭圆肤色模型来检测该人脸框中鼻和嘴部分的皮肤暴露的状况,进而识别出是否规范佩戴了口罩。利用公开数据集对模型进行训练和测试,实验结果显示,人脸口罩检测和佩戴规范识别都具有较高的精度,具有较高应用价值。
但本文的方法仍存在不足之处,当人脸区域比较小时,仍存在漏检的情况。此外,口罩规范佩戴识别对于异常角度和倾斜的人脸错误率较高。因此,提高对人脸区域较小的口罩检测的性能,以及加强口罩规范佩戴识别的鲁棒性,是未来进一步研究的方向。
参考文献
-
Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016.
-
Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016.
-
Redmon J, Farhadi A. YOLOv3: An Incremental Improvement[C]//2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
-
Liu W, Anguelov D, Erhan D, et al. SSD: single shot multibox detector [C]//Proc of European Conference on Computer Vision. Springer, 2016: 21-37.
-
Girshick R. Fast R-CNN[C]// 2015 IEEE International Conference on Computer Vision (ICCV). IEEE, 2016.
-
Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
-
Nieto-Rodríguez, Mucientes M, Brea V M. System for Medical Mask Detection in the Operating Room Through Facial Attributes[C]//Iberian Conference on Pattern Recognition and Image Analysis. 2015.
-
刘萌. 基于肤色HSV彩色模型下的人脸检测[J]. 商洛学院学报, 2012, 26(02): 46-50.
-
邱迪. 基于HSV与YCrCb颜色空间进行肤色检测的研究[J]. 电脑编程技巧与维护, 2012(10): 76-77.
-
赵杰, 桑庆兵, 刘毅锟. 基于分裂式K均值聚类的肤色检测方法[J]. 计算机工程与应用, 2014, 50(1): 134-138.
-
Hsu R L, Abdel-Mottaleb M, Jain A K. Face Detection in Color Images[J]. Journal of Chengdu Textile College, 2002, 24(5): 696-706.
-
Yang S, Luo P, et al. WIDER FACE: A Face Detection Benchmark[C]//IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2016.
-
Ge S, Li J, Ye Q, et al. Detecting Masked Faces in the Wild with LLE-CNNs[C]//IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2017.
![]()