基于YOLO-TridentNet的车辆检测方法
2020-12-24朱茂桃方瑞华
朱茂桃,邢 浩,方瑞华
(1.江苏大学,江苏 镇江 212013;2.上海干巷车镜实业有限公司,上海 201518)
近年来,随着人工智能的飞速发展,基于计算机视觉的目标检测技术在精度和实时性方面都取得了极大的进步,这对高级辅助驾驶系统(advanced driving assistant system)技术的研究和发展具有重要意义。
传统的目标检测方法需要人工设计如SIFT、ORB、HOG等特征算子[1-3],再通过SVM以及Adaboost这些分类器实现目标检测[4-5],泛化能力差,难以同时保证精确度和实时性要求。
2012年,在ImageNet图像识别竞赛上,Hinton及其学生 Alex Krizhevsky提出了 AlexNet[6]卷积神经网络(convolutional neural networks,CNNs),并以巨大的优势获得了竞赛冠军,基于深度学习的目标分类和检测方法也随之成为主流。目前,基于深度学习的目标检测方法大体分为两种:一步法(one-stage)和两步法(two-stage)。一步法即通过一个神经网络结构完成目标检测任务。Redmon等提出了 YOLO系列算法[7-9],将 GoogLeNet[10]作为骨干网络直接对图片进行特征提取和目标预测。YOLO算法的检测速度非常快,可以达到实时性要求,同时具有较好的泛化能力,但是其精度相对较低,有时会导致定位不准确,在检测一些小目标时难以获得令人满意的效果。两步法主要包括R-CNN系列算法,R-CNN[11]使用 CNN网络进行特征提取,再通过SVM分类器完成检测任务;Fast R-CNN[12]使用了softmax层对目标进行分类,提高了检测速度;Faster R-CNN[13]使用了 RPN网络代替了选择性搜索(selective search),进一步提高了检测性能。相比一步法,两步法能够获得较高的精度,定位更加准确,但总体检测速度较慢,无法应用于一些对实时性要求很高的场景。
综上所述,为满足车辆检测算法在实时性和准确性上的较高要求,基于YOLOv3[9]和 Trident-Net[14]网络,设计了一种 YOLO-TridentNet网络结构,并对网络层的参数进行调优。然后采用KITTI[15]车辆数据集,分别训练了 YOLOv3和YOLO-TridentNet车辆检测模型,实现了车辆检测任务,同时与原来的YOLOv3算法进行对比,结果表明:在能够保证实时性的前提下,基于YOLOTridentNet的车辆检测方法在检测远处车辆以及小尺度目标时能够得到更高的检测精度。
1 YOLOv3算法
YOLOv3算法在 YOLO9000[8]算法的基础上加以改进,具有更深的网络结构,通过聚类的方法获得了锚框(anchor box)尺寸,在预测边界框内目标置信度得分时则使用了逻辑回归(logistic regression)方法。YOLOv3对损失函数做了修改,主要是在预测置信度和类别损失时,使用了二元交叉熵函数,从而可以进行多标签分类。
相比传统的目标检测方法,YOLOv3算法更简洁、迅速,总体来说只需3步即可完成检测任务:①调整图片分辨率大小;②CNN网络提取图像特征,输出预测结果;③ 使用非极大值抑制(nonmaximum suppression,NMS)[16]的方法过滤掉冗余的预测框,输出最终检测结果。
通过对文献[9]总结,给出如图1所示的具体YOLOv3网络结构,其在Darknet-19的基础上重新规划了网络层布局。与之前不同,YOLOv3类似于一个全卷积网络,网络层中并没有加入池化层而是使用了步长为2的卷积层实现了降采样过程,同时在一系列连续的1×1和3×3卷积层中加入了类似 ResNet[17]的跨层连接方式(shortcut connection),防止网络逐渐加深时发生梯度消失或梯度爆炸的现象。
YOLOv3运用了类似特征金字塔(feature pyramid networks)的方法[18],进行了多尺度预测,最后输出了3种不同大小的特征张量。输入图像经过5次下采样及一系列卷积处理后,通过路由(route)层,将浅层网络的特征图与经过上采样后所输出的特征图相结合再输入至下一层网络,从而获得更加丰富的特征信息,改善了小目标的检测效果。
2 基于 YOLO-TridentNet的车辆检测方法
2.1 模型训练
2.1.1 YOLO-TridentNet网络结构
文献[14]提出的TridentNet网络结构反映了不同的感受野(receptive field)对不同尺度目标的检测效果,研究表明较大的感受野在检测大尺度的目标时能获得更好的效果,对小尺度目标的检测则无法得到令人满意的效果;感受野较小时,检测效果则与之相反。TridentNet网络具有3个平行分支网络,除了扩张率(dilation rate)[19]不同外,每一个分支的网络层参数都进行了共享,减少了计算量的同时也改善了最终的检测效果。
本文中将 Darknet-53作为骨干网络(backbone),前53个卷积层布局与之相同,只修改了一些参数,之后借用了TridentNet网络权重共享的想法,设计了如图2所示的YOLO-TridentNet网络层结构。与图1所示结构不同,3个Yolo层与骨干网络之间设计了3个平行分支网络,各个分支都由一定数量的1×1卷积层、3×3卷积层、BN层、shortcut层以及激活函数组成。每个分支的扩张率不同,Yolo1至Yolo3层所在分支卷积层的扩张率大小分别为3、2、1。Yolo1层的扩张率最大,感受野也最大,适合检测尺度较大或者距离较近的目标;Yolo2层的扩张率最小,感受野也最小,适合检测尺度较小或者距离较远的目标。当输入图片的分辨率大小为416×416时,图像经过网络层处理,最终输出了3种尺度的特征图分别为:13×13(dilation rate=3)、26×26(dilation rate=2)、52×52(dilation rate=1)。
2.1.2 损失函数的定义
本文中的损失主要由3部分组成:边界框坐标坐标的预测损失,目标置信度得分损失和目标所属类别的预测损失。如果某个边界框没有分配给待检测的目标,则不会产生边界框的坐标损失和分类损失,只会计算目标置信度损失。具体的损失函数式如下:
式(2)是目标的分类损失,同样使用了二元交叉熵函数,这有利于多标签的分类,在同一个网格中可以检测出属于不同类别的目标,比如可以识别出是轿车还是卡车等。y∈{1,0},y代表待检测的目标是否为汽车,是则为1,否则为0;pi(c)表示当前目标属于汽车类或者其他类别的概率。
式(3)是目标置信度的损失,分为两部分:含有待检测目标的置信度损失和不含待检测目标的置信度损失。定义这两部分损失时使用了二元交叉熵函数,当目标物落在第i个网格中,从B个边界框中选择与标注框交并比即IOU值最高的一个作为有目标物的置信度损失,剩下的边界框的置信度作为第2部分不含待检测目标的置信度损失。若舍去的某个边界框的IOU值大于设定的阈值,却又不是最大值,则该边界框置信度得分不参加任何部分损失的计算,直接忽略。
由于不含目标的网格一般占整张图片的大部分区域,往往使得置信度的得分趋向于0,无法保证模型的稳定性,从而在训练初期就发生离散现象。因此,人为定义参数λcoord=5,增加边界框坐标的损失,定义λnoobj=0.5,减少不含目标的网格带来的置信度损失。
2.1.3 训练参数
训练一个单类检测模型,设定最大迭代次数为4 000次,基本可以保证模型达到收敛。受限于笔记本显卡性能和内存大小,一次只加载32个样本,分32次完成前向传播。使用数据增强的方法,改变待训练图片的曝光度、色调以及饱和度,从而生成更多的训练样本。设置初始的学习率为0.001,训练到3 500次后,学习率衰减10倍,继续训练至结束。部分训练参数如表1所示。
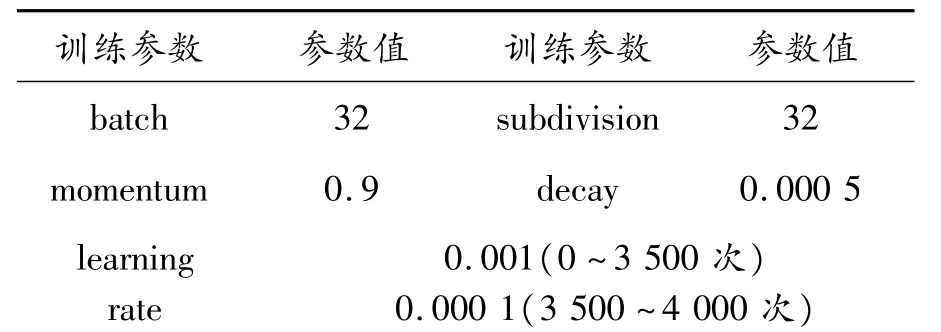
表1 部分训练参数
2.1.4 数据集构建和处理
利用KITTI车辆数据集进行实验,共选取了7 480张图片,按照7∶2∶1的比例,分为训练集:5 240个样本,测试集:1 500个样本和验证集:740个样本。训练集用于训练 YOLO-TridentNet和YOLOv3网络模型,测试集用于测试训练得到的模型的精度,验证集主要用于评估训练得到的模型的泛化能力。
数据集构建完成后,为获得锚框的尺寸,使用K-means聚类的方法,得到了9种锚框尺寸,尺寸选取较大的3个锚框分配给Yolo1层,尺寸较小的3个锚框分配给Yolo3层,剩下的3个锚框分配给Yolo2层,具体实现步骤如下:
步骤1 根据数据集中标注框坐标信息分布情况,选择 9个聚类中心(Wi,Hi),i∈{1,2,…,9},其中,Wi和Hi为锚框的宽和高;
步骤2 计算每个标注框和每个聚类中心的距离d,计算公式如下:
其中:IOU表示交并比;anchor表示锚框;truth表示标注框,计算公式如下:
其中:分子表示锚框和标注框相交的面积大小;分母表示锚框和标注框相并的面积大小。当IOU值最大时,即标注框和锚框匹配得最好,此时d最小,将标注框分配给该聚类中心;
步骤3 将所有标注框分配完毕后,分别计算每个聚类中心所属的标注框宽和高的平均值,作为新的聚类中心;
步骤4 重复步骤2和步骤3n次,直到dndn-1趋于0时,输出聚类结果。
2.1.5 模型训练步骤
步骤1 采用在ImageNet数据集上预先训练好的Darknet模型参数作为初始化权重进行训练,以减少训练时间;
步骤2 将训练集中的图片输入YOLO-TridentNet网络中,自动调整图像分辨率为416×416,卷积层对图像特征进行学习,Yolo层对边界框坐标、目标置信度和类别进行预测;
步骤3 输入参数经过Yolo层时,特征图被划分成13×13个网格,根据标注框的坐标信息对锚框位置进行回归,得到锚框相对于标注框的偏移值:tx,ty,tw,th,具体计算公式如下:
其中:Gx和Gy表示特征图中标注框的中心点坐标;Gw和Gh表示特征图中标注框的宽和高;Cx和Cy表示特征图中grid cell的左上角坐标;Pw和Ph是锚框映射到特征图上的宽和高;
步骤4 训练集中的图片经过步骤2)和3)处理后,最终学习到的参数包括:卷积层参数、BN层γ和β参数、锚框的偏移值、目标置信度和类别标签。
2.2 模型检测
基于Darknet深度学习框架,通过训练得到的YOLO-TridentNet车辆检测模型,实现了一种端到端(end-to-end)的目标检测,具体检测流程如下:
步骤1 将测试集中的图片大小调整为416×416,输入YOLO-TridentNet车辆检测模型中;
步骤2 车辆检测模型直接给出目标的置信度得分,同时对输入的图片进行特征提取,然后输出锚框相对于标注框的偏移值,经过计算再得到输出的边界框的位置信息,具体表达式如下:
其中:W和H是输入Yolo层中特征图的大小;bx,by,bw,bh即输出的边界框。
步骤3 预测时,类似于模型训练的处理过程,输入Yolo层中的特征图同样会被划分为13×13个网格,每个网格都分配了3个锚框。通过非极大值抑制的方法,过滤掉冗余的窗口,得到最优的边界框。
2.3 评价标准
实验采用查准率(precision)、查全率(recall)和平均精度(average precision,AP)对最终的检测结果进行评价。计算式如下:
其中:TP为真正类(True Positives),即汽车类被正确地识别为汽车;FP为假正类(false positives),即目标不是汽车却被错误地识别为汽车;FN(false negative)为假负类,即目标是汽车却被错误地识别为非汽车类。平均精度的值相当于求查准率和查全率关系曲线与坐标轴围成的面积,它近似于不同阈值下求得的查准率再乘以查全率的变化率,最后进行累加所得到的结果。式(16)中N为所收集的样本的数量,P(k)表示识别出k张图片时的查准率,Δr(k)表示识别出的图片数量从k-1变化到k时,查全率的变化值。
3 实验及结果分析
实验硬件配置为:英特尔i5-7300HQ处理器;NVIDIA GTX1050Ti 4GB显卡;8 GB内存。在Ubuntu 16.0.4系统下,使用Darknet深度学习框架,实现了整个算法流程,并利用CUDA加速模型的训练。
将训练集中的5 240张图片输入YOLOv3网络和YOLO-TridentNet网络中,经过训练后,学习到了各卷积层、BN层以及Yolo检测层的权重参数,最终得到了2个不同的车辆检测模型。
在测试集中随机选取几张图片进行检测。图3为测试集中选取的待检测的4张图片,将待检测的图片分别输入YOLOv3和YOLO-TridentNet模型中,获得了如图4、5的检测结果。
如图 4(a)所示,待检测样本图 3(a)经过YOLOv3模型处理后,最终只检测到了一个目标;如图5(a)所示,待检测样本图3(a)经过 YOLOTridentNet模型处理后,还能够检测到另一个较远处的小尺度目标。同样的,待检测样本图3(b)、(c)、(d)经过 YOLOv3模型处理后,都漏检了一些尺度较小或者距离较远的目标,而图5中的漏检现象明显少于图4所示的YOLOv3模型的检测结果,说明 YOLO-TridentNet模型具有更高的查全率,在检测小尺度以及较远处的车辆时,能够获得更好的检测效果。
图6 中的实线和虚线分别是YOLO-TridentNet和YOLOv3模型的损失曲线,横坐标为训练次数。模型损失随着训练次数的增加,总体呈下降趋势,当训练次数达1 000次左右时,模型的损失变化趋于平缓,基本达到收敛;当训练次数达到4 000次时,YOLOv3车辆检测模型的损失为0.76,YOLOTridentNet车辆检测模型的损失为0.74,两种模型的损失不再变化,此时停止训练即可获得稳定的模型权重。
图7为YOLOv3和YOLO-TridentNet车辆检测模型的P-R曲线图,即查准率和查全率关系曲线,分别由虚线和实线表示。由图可知:模型的检测精度会随着查全率的增加而降低,当查全率为75%左右时,查准率约为98%,此时模型既能保证较高的检测精度,又具有良好的查全率。当查准率相同时,相对于YOLOv3模型,YOLO-TridentNet模型能够获得更高的查全率,即在给定的测试集中能够检测到更多的车辆。图4和图5所示的模型的检测结果也是图7两种模型曲线关系的一种直观体现。
表2是两种网络结构在Darknet深度学习框架下,基于KITTI车辆检测数据集训练了4 000次后,所得到的模型的查准率、查全率、平均精度和每秒帧数。由表2可知:YOLO-TridentNet模型的查全率为76.5%,比YOLOv3提高了2.2%,漏检情况得到改善,虽然每秒识别帧数相对于YOLOv3降低了2帧,但仍能基本实现实时检测的效果。在IOU≥0.5时,YOLO-TridentNet车辆检测模型能够获得92.35%的平均精度,比YOLOv3提高了1.06%。

表2 实验结果
上述结果表明:本文中所提出的YOLO-TridentNet网络在准确率和实时性方面得到了更好的平衡,该网络训练得到的模型不仅能够满足实时检测的需求,而且能够获得更好的检测效果,尤其是在检测远处小目标时,漏检率更低。
4 结论
基于YOLO-TridentNet的车辆检测方法获得了76.5%的查全率和92.35%的平均精度,在相同的交通场景中,能够检测到更多的车辆目标,特别是较远处和小尺度的目标,进一步提高了驾驶的安全性。为了能够在嵌入式设备上实现高精度的实时检测,下一步可以考虑使用模型剪枝算法对YOLO-TridentNet模型进行压缩,减少计算量,同时与行车预警机制相结合,从而减少交通事故的发生,保障生命财产安全。
