基于极限学习机的迁移学习算法
2020-12-24金培源金杭森高波涌陆慧娟
金培源,金杭森,高波涌,陆慧娟
(1.中国计量大学信息工程学院,浙江 杭州 310018;2.西安机电信息技术研究所,陕西 西安 710065)
0 引言
三维模型数据库的日益增多,如何复用这些已经存在的三维模型数据库成了一个热门的研究课题。三维模型检索技术旨在从大量的已有的三维模型库中快速、准确地找到目标模型。三维模型分类技术作为三维模型检索中重要的一步,对检索的准确度起着重要作用。三维模型分类技术,是将一部分已标记的三维模型作为训练样本,通过机器学习算法对其进行训练,得到最优的空间划分,从而得到求解问题的分类器[1]。因此,运用三维模型分类技术可以缩小原先的检索范围,只在特定的模型类别中检索,从而实现对模型的快速检索。
上述的这些分类技术主要是对针对平衡数据,往往能取得较好的效果。而对于类不平衡问题,并没有过多的涉及。针对机器学习算法在类不平衡的数据集上容易受到选择性偏差的影响,本文将迁移学习思想与极限学习机(ELM)结合,提出了一种具有迁移能力的TransELM算法。
1 极限学习机
文献[8]提出了ELM这一种新的神经网络算法。ELM是一种有效的单隐层前馈神经网络算法,通过最小二乘法计算出输出权值便可以完成训练,在分类问题中,同神经网络和支持向量机(SVM)相比,ELM的学习速度和泛化能力都比较优异,在分类应用中优势显著。ELM由于随机给定权值,对分类精度会产生影响。利用鱼群和黄金分割优化极限学习机的办法,也获得了较高精度[9-10]。
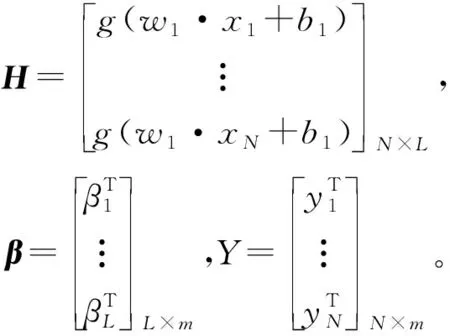
对于任意N个各不相同的样本(xi,yi),其中xi=[xi1,xi2,…,xin]T∈Rn代表输入,yi=[yi1,yi2,…,yim]T∈Rm代表输出,则极限学习机的网络模型可表示为:
(1)
式(1)中:wi=[wi1,wi2,…,win]T是连接第i个隐层神经元的输入权值;bi是第i个隐含层神经元的偏差;βi=[βi1,βi2,…,βim]T为连接第i个隐层神经元的输出权值;g(x)为隐层神经元激活函数。如果这个具有L个隐含层结点的前馈神经网络能以零误差逼近样本,式(1)可以简化为:
Hβ=Y
(2)
式(2)中,
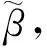
(3)
2 基于极限学习机的迁移学习算法
本文提出一种具有迁移能力的ELM算法,将ELM算法直接应用于迁移学习中,此时源域带标签数据Ds={(xs1,ys1),…,(xsn,ysn)},目标域中部分带标签样本Dt={(xt1,yt2),…,(xtn,ytn)},当然目标域中带标签的样本是少量的,将这些样本作为ELM的输入矩阵。由于源域数据与目标域数据通常存在一定关联性,所以得到的分类器会在目标域中有较好的分类效果。这种方法称为TransELM算法。
ELM算法的判别函数可以简化为f(x)=Hβ,本文算法的理论依据是:若两领域相关,则两域分类器各自的β值应相近。通过计算||βt-βs||2项来实现两域间迁移学习,其中,βs为源域带标签数据应用ELM算法得到的输出权值矩阵,βt为目标域带标签样本应用ELM算法得到的输出权值矩阵。||βt-βs||2表示两域分类器的差异程度,该值越大则两领域间的差异越大,反之越小。已知目标域Htβt=Yt,源域Hsβs=Ys,假设目标域与源域是同一种事物的不同表示,即Yt=Ys,则:
Htβt=Hsβs
(4)
(5)
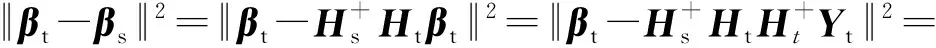
(6)
为推测换乘时间,需要获取出发站点到换乘站点的距离. 利用A*最短路径算法,搜索出轨道任意站点OD之间的最短路径和距离(表3),将该路径作为乘客出行路径,添加TRACE字段以记录该路径.
TransELM算法流程:
1) 设定阈值μ,N;
2) 从源域数据集Ds中随机选取M个样本组成的子集Hs,从目标域数据集Dt中随机选取M个样本组成的子集Ht;
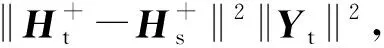
4) 重复第二步和第三步直至得到N个Hs;
5) 删除Hs中相同的样本,并与Ht融合形成新的目标域;
6) 结束。
3 实验分析与结果
3.1 数据集
本文实验使用的三维模型库是Princeton 3D Shape Benchmark Database(PSB),如图1所示。PSB模型库有161个子类共1 814个三维模型,每个类别至少包含4个模型。
图1 PSB模型库Fig.1 PSB model database
实验选择了Car Vehicle、Car Vehicle、Spaceship Aircraft以及Desk Furniture这四种模型样本进行分类识别,其中Desk Furniture这一类只有4个样本,明显少于其他三类的样本数,所以这是一个类不平衡问题。由于Table Furniture和Desk Furniture属于同一级语义粒度所细分的两个小类,可以通过迁移Table Furniture的知识来对Desk Furniture进行分类。
3.2 实验设置和实验结果
为了证明本文所提算法的有效性,实验设置5个对照组,分别为S-ELM、G-ELM、ST-ELM、SMOTE-ELM和TransELM。其中S-ELM表示不做任何处理,直接在目标域数据集上运用ELM算法进行分类;ST-ELM表示在目标域与辅助域合并的数据集上进行分类;G-ELM表示先对数据集进行欠抽样再分类;SMOTE-ELM表示先用SMOTE(synthetic minority over-sampling technique)算法调整数据集样本分布再分类;TransELM表示从辅助域迁移学习知识来对目标域进行更好的分类。其中ELM的隐含层节点数设置为20,阈值μ,N分别设为0.1和10。实验环境: Intel Core i5-3470 CPU 3.2 GHz,4 GB RAM,Windows 7, Matlab R2010。为了体现每种算法的泛化能力和避免各算法不稳定的情况,实验进行了3折交叉验证,将样本分成3份,轮流使用其中的2份作为训练集,剩下一份作为测试集,并重复实验10次,得到每种算法精度(Accuracy)和方差(S2)的平均值。表1和图2显示了5种算法在实验数据集上的结果,其中图2的横坐标代表实验次数,纵坐标代表算法精度。
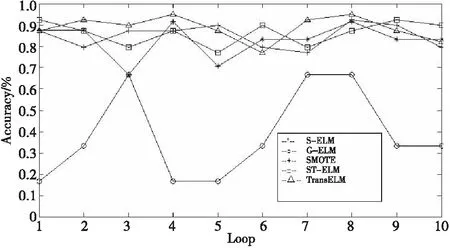
图2 算法分类效果比较Fig.2 Comparison of classification effects
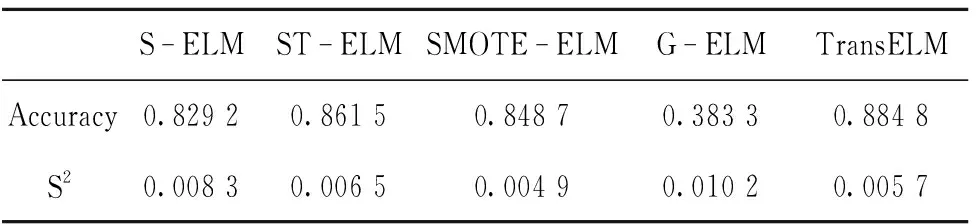
表1 不同算法的分类精度与方差Tab.1 Classification accuracy and variance of different algorithm
从实验数据可以看出,S-ELM列仅用目标域少量已标签样本进行分类,分类精度较低,说明少量目标域已标签样本不能很好反映该类样本特性,分类效果不显著。
ST-ELM列的分类精度优于S-ELM列,说明源域对目标域的分类可起到一定作用,但提高程度取决于两域相关性。G-ELM对数据进行欠抽样,使得各类的样本数减少了,丢失了大量信息,故分类精度最低,方差也最大。SMOTE算法根据一定的规则随机制造生成新的少数类样本点,并将这些新合成的少数类样本点合并到原来的数据集里,生成新的训练集,分类精度与ST-ELM算法不相上下,算法最稳定。TransELM算法并不直接将源域和目标域合并,而是将其中相关性大的一些样本进行合并,因此,迁移学习算法性能优于两域合并训练,分类效果较为理想,同时算法也较稳定。
4 结论
本文提出了一种基于极限学习机的迁移学习算法。该算法利用大量已标签的源领域数据与只有少量样本的目标域数据之间的相关性,通过计算源域中的输出权值βs与目标域中的输出权值βt,利用||βt-βs||2项来实现两域之间迁移学习,找出源领域与目标领域中相关的样本,从而提升迁移学习对非平衡样本的学习能力,建立分类模型。该算法应用于三维模型分类,能够有效利用源域中的大量数据来帮助训练,通过迁移学习三维模型库中同一粒度集下相似模型的数据,可解决类不平衡问题。实验结果表明,该算法在普林斯顿三维模型数据库上的分类结果的精度和稳定性优于传统的ELM分类方法。
