引入词向量和双注意力机制的图像语义理解*
2020-12-23王玉德
董 冰,王玉德
(曲阜师范大学,山东 曲阜 273165)
0 引言
近年来,国内外学者对深度神经网络技术研究不断深入,极大地促进了图像语义理解技术的研究与发展。2014 年,Kiros 等人提出基于深度神经网络的图像语义理解算法[1],并成功将图像和它的描述文本等多模态信息进行融合,用于生成图像描述语句。2015 年,Xu 等人提出一种基于注意力机制的图像语义理解模型[2],第一次尝试将注意力机制引入图像语义理解任务中,使图像生成的描述的每一个单词都对应到图像的某一个区域,从而更加符合生物视觉,也提升了生成的图像描述效果。2017年,Chen 等人提出了空间和通道敏感注意力机制[3](Spatial and Channel-Wise Attention,SCA)。该机制除了利用图像的空间信息外,还考虑了特征图的通道信息。文中提出的“通道-空间”(Channel-Spatial,C-S)模型和“空间-通道”(Spatial-Channel,S-C)模型相比于其他模型,性能提高显著。2018年,Anderson 等人提出了使用自下而上(Bottom-Up)的特征作为模型[4]的输入。该特征结合了图像检测的方法,将图像的关键物体通过物体检测器进行检测,以提取候选框来提取特征,最终作为模型的输入。
尽管当前工作已经取得了一定进展,但传统的注意力模型还存在对图像信息和语义信息利用不充分,不能够将注意力信息贯穿于整个解码过程的问题。为解决该问题,提出了一种引入词向量和双注意力机制的图像语义理解算法,在数据集MS COCO2014 上进行训练和测试,该方法能精确识别图像中的物体,并生成更准确的语义描述。
1 理论基础
1.1 Resnet 网络
Resnet 结构在传统卷积神经网络中加入残差学习的思想,在加深卷积网络的同时实现对网络复杂度的控制,使网络更易于训练优化,解决了深层网络中梯度消失的问题。
残差在深度网络中表现为跨层连接,即将局部网络处理后的图像特征与处理前的原始特征进行组合,如:

式中,F(x)指局部网络层的运算操作。
Resnet 网络中卷积层大致分为5 组,每组由若干残差结构组成,且不同组卷积输出的特征图大小存在差异。与VGG16 使用池化层进行降采样不同,Resnet 通过设置连接处卷积操作的步长实现下采样,以尽可能减少信息损失。Rsenet-50 网络结构如图1 所示。
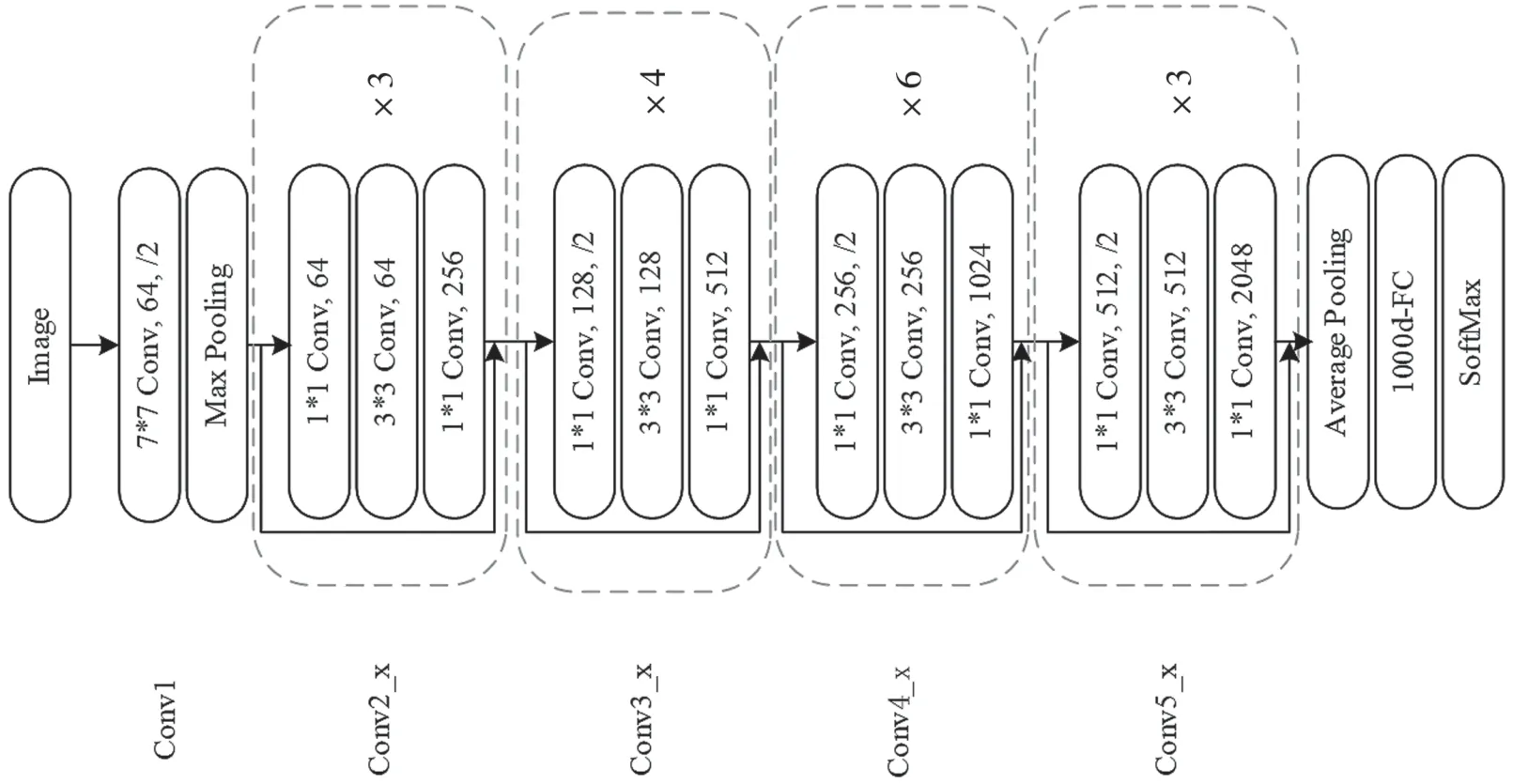
图1 Resnet-50 网络结构
1.2 LSTM 长短期记忆网络
循环神经网络具有记忆功能,但只能记住短期信息,并不能解决长期信息依赖问题,于是产生了长短期记忆网络,简称LSTM。LSTM 包括3 个门结构,分别为输入门、输出门和遗忘门,以此保护和控制细胞状态。它的结构如图2 所示。
遗忘门、输入门、输出门的输出由前一时刻的输出和当前时刻的输入决定,定义为:

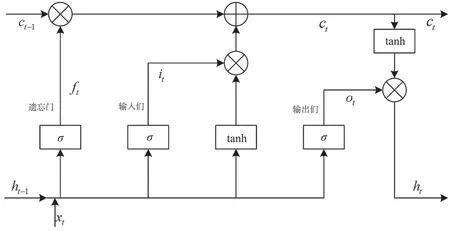
图2 LSTM 结构

ct和ht的更新公式为:

式(2)~式(6)中:σ表示sigmoid 激活函数,σ∈(0,1);xt表示当前时刻t的输入;ht-1和ht分别表示上一时刻t-1 和当前时刻t的隐藏状态;ft、it、ot分别表示t时刻LSTM 中遗忘门状态、输入门状态、输出门状态;ct表示记忆单元状态;Wi和bi分别表示输入门的权重和偏置,其中输入门决定了LSTM 把哪些新的信息添加到细胞状态中;Wf和bf分别表示遗忘门的权重和偏置,其中遗忘门决定了LSTM 从细胞状态中舍弃哪些信息[5];Wo和bo分别表示输出门的权重和偏置,其中输出门用来控制细胞状态中的哪些信息用于当前的输出。
1.3 注意力机制
人类在处理外界输入时不会立刻处理全部输入,而是会关注输入的某一个部分来获取相关信息。比如,在观察一个人时,人们会更多关注他的脸部而不是整个身体,在各个时间段获取各种局部信息后将这些信息结合起来,进而引导眼球移动并做出对应的决策。注意力机制基于这一特性,在处理图像时虽然“看到了”全部画面,但在某一特定的时刻只聚焦于图像的某一部分。将它应用到图像语义理解,就是在解码过程中的特定时刻可以关注特定的图像区域,进而生成更准确的语义描述。引入注意力机制后,一方面可以在大量信息中更关注于重要的信息,提高任务处理的准确性;另一方面可以减少对无关信息的关注度,进而减少冗余信息量,提高任务处理的效率。注意力机制内部结构如图3 所示。

图3 注意力机制内部结构
首先,软注意力机制的上下文向量ct定义为:

式中,g为注意函数,V={v1,v2,…,vL}为空间图像特征,每个特征都对应于图像某一部分的d维表示,ht-1是t-1 时刻的隐藏状态。
空间图像特征和隐藏状态通过单层神经网络和一个softmax 函数,生成图像K个区域的注意力分配:
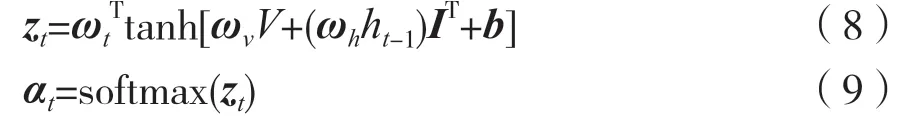
式中,ωt、ωv和ωh是一组需要学习训练的权重参数,b为偏置向量,I为元素全部为1 的向量,zt为权重矩阵,αt是图像特征的注意权重。根据得到的注意力权重的分布,图像上下文向量为:

1.4 评价指标
目前,常用的评价图像语义理解准确度的指标有BLEU[6]、METEOR[7]、ROUGE-L[8]和CIDEr[9]。
1.4.1 BLEU
BLEU(Bilingual Evaluation Understudy)评测方法由IBM 在2002 年提出,通过统计候选句子(待评价的句子)与参考句子(人工标注的句子)中同时出现的n元组的个数来进行评测,计算公式为:
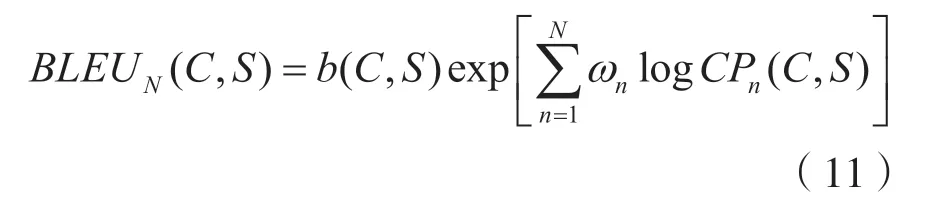
式中,N可取1、2、3、4,权重ωn=1/N。
1.4.2 METEOR
METEOR 是将候选句子和参考句子的词进行逐一匹配,计算对应待评价的候选句子和人工标注的参考句子之间的准确率和召回率的调和平均,计算公式为:

式中,Pen为惩罚因子。
1.4.3 ROUGE-L
ROUGE-L 是一种基于最长公共子序列的测量方法,计算公式为:

式中,β表示常系数,Rl和Pl分别为召回率和准确率。
1.4.4 CIDEr
CIDEr 是专门用于图像语义理解算法的评价指标,通过计算每个n元组的词频-逆文档频率权重来衡量图像语义理解的一致性,计算公式为:

式中,权重ωn=1/N。对于长度为n的n元组,CIDErn(ci,Si)可以用候选句子和参考句子之间的平均余弦相似度来计算。
2 系统框架
系统采用编码器-解码器结构,编码器端采用已经预训练好的Resnet-50 网络来提取图像特征向量。为了更好地利用图像空间特征,移除原网络中的全连接层和平均池化层,使用该网络第5 层卷积层输出的特征图生成图像的空间特征,尺寸为7×7×2048。所以,图像特征矩阵V={v1,v2,…,vL}的大小L×d为49×2048,每个区域对应的特征向量νi的维度d=2048。
针对在单注意力机制中仅考虑了如何在LSTM的输入阶段利用图像的局部信息,而对图像信息利用不充分的问题,提出采用双注意力机制来更好地使用图像局部信息,以进一步提高图像语义处理的效果。长短期记忆网络输入阶段注意力机制用t-1时刻的隐藏状态ht-1和编码器得到的图像特征V获得当前图像的上下文向量cit。输出阶段的注意力机制将由隐藏状态ht-1和图像特征V处理得到的cit输入到LSTM,得到t时刻的隐藏状态ht,并利用当前隐藏状态ht和图像特征V获得输出阶段上下文向量cot。与输入阶段注意力机制输入隐藏状态ht-1不同,ht直接用于单词生成。将ht引入注意力机制,会使得到的注意力更多地与当前的单词信息有关。生成的上下文向量cot将当前时刻的LSTM 隐藏单元和空间向量相结合,相当于在生成阶段增强了对图像空间信息的利用。另外,对解码部分进行改造,在多层感知机的输入阶段加入词向量xt,在单词生成过程中增强了对图像语义信息的利用。单注意力机制网络和引入词向量的双注意力机制网络如图4和图5 所示。
引入词向量和基于上下文信息的双注意力机制的模型如图6 所示。待处理图像经过Resnet-50 网络提取图像特征,在LSTM 输入阶段使用注意力机制将图像空间信息与LSTM 相结合,提高了模型对图像底层特征的利用。在LSTM 输出阶段使用注意力机制,提高了对文本信息的利用。另外,在多层感知机部分引入词向量,提高了对语义信息的利用。
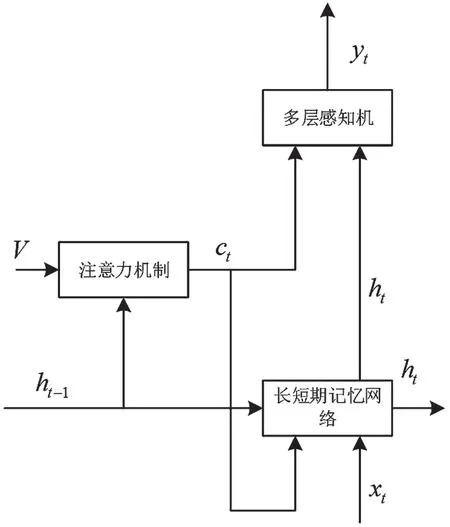
图4 单注意力机制网络
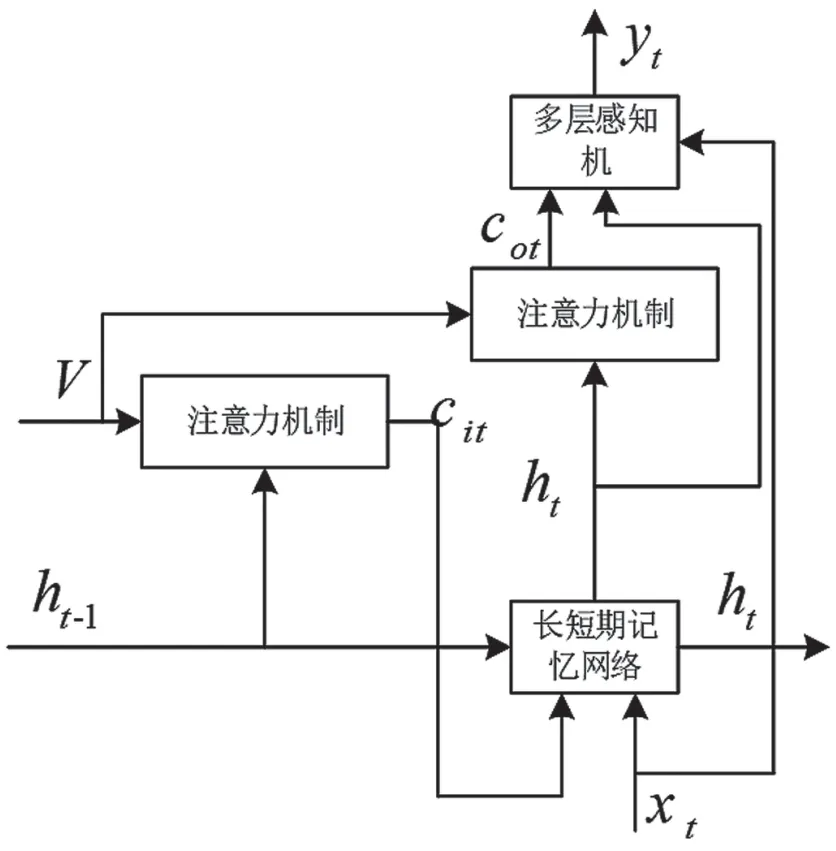
图5 引入词向量的双注意力机制网络
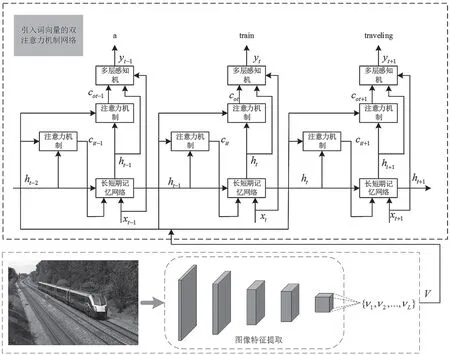
图6 引入词向量和双注意力机制的图像语义理解模型
3 实验与结果分析
3.1 实验条件
实验采用MS COCO2014 数据集,包括训练集图像82783 张,验证集图像40504 张,测试集图像40775 张。实验中采用NeuralTalk2 的划分方法划分数据集[10],其中训练集图像113287 张,验证集图像和测试集图像各为5000 张,且为每张图像提供了至少5 个文字描述句子。LSTM 隐藏层维度设置为512,迁移使用已经预训练好的Resnet-50模型,仅对解码部分的模型参数进行训练。模型训练使用Adam 算法[11],学习率设置为0.0001,批大小设置为64,最大迭代周期设置为40 epochs,词汇表大小设置为10000,最大序列长度设置为20。在测试阶段生成句子时,采用束搜索的方法,并将其大小设置为3。
3.2 实验与结果分析
选取BLEU、METEOR、ROUGE-L 和CIDEr 这4 类指标评价算法效果。获得的分数越高,表明生成的句子质量越好。在数据集MS COCO2014 上进行训练和测试,分别对Google NIC(基于编码-解码框架的图像语义描述算法)、Soft-attention(基于软注意力机制的图像语义描述算法)、Aligning-ATT(基于注意力机制的图像语义描述算法)以及所提算法进行对比实验分析,实验结果如表1 所示。其中,符号“—”表示结果未知。

表1 实验结果
从表1 可以看出:提出的方法与Google NIC、Soft-attention、Aligning-ATT 相比较,BLEU-1 参数值为69.6%,较Google NIC 提高3.0%,略低于另外两种方法;BLEU-2~BLEU-4 参数值分别为52.5%、38.9%、28.8%,较另外3 种方法提高0.6%~6.4%;METEOR 参数值为22.9%,略低于Soft-attention 和Aligning-ATT 方法;ROUGE_L参数值为51.2%,较Aligning-ATT 提高了0.3%;CIDEr 参数值为84.3%,较Aligning-ATT 提高了0.5%。本文模型在BLEU2~BLEU-4 上的分数较好。BLEU 分数表征了算法得到的语义描述语句和数据集给出的人工标注语句中n元组的共现程度,说明模型生成的句子在词组方面与人工标注的句子有更高的相似度。
图7 为所提算法在测试集上实验得到的图像语义理解生成结果。从图7 看出,训练后的模型生成的句子长短适中,语句结构更加完整,能准确描述图像的内容。图7(a)中,提出的算法可以准确识别图中主体物品“plate”“sandwich”和“coffee”,并利用“with”“of”等介词将图像中的内容准确地描述出来,生成描述“a plate with a sandwich and a cup of coffee”;图7(b)中,模型可以准确识别图中场景为“street”,以及场景中的主要人物“people”和主要物体“bike”,并利用动词“riding”和介词“on”将图像描述成一个完整且符合逻辑的句子,给出描述“a group of people riding bikes on a street”。

图7 图像语义理解结果
4 结语
本文提出了引入词向量和基于上下文信息的双注意力机制的图像语义理解算法。模型采用深度卷积神经网络Resnet-50 提取图像空间特征,获得图像特征后使用LSTM 模型生成图像语义描述。为了生成更加合理准确的图像语义描述语句,采用引入词向量和在LSTM 网络的输入阶段、输出阶段加入了基于上下文信息的注意力机制。在数据集MS COCO2014 上进行训练和测试,结果表明,本文模型能够关注图像的合理位置,准确挖掘整个图像的场景信息,生成更准确、更完整、更有意义的图像描述语句。
