基于数据集成的随机森林算法
2020-12-16容钰添胡奉平姚小龙
谢 坤,容钰添,胡奉平,陈 桓,姚小龙
(顺丰科技有限公司 大数据与区块链研发中心,广东 深圳 518000)
0 概述
销量预测是工业界中的重要研究问题,尤其在制造业、供应链等领域,它一般是预测未来一段时间内某产品的订单需求量,其时间跨度可用天、周、月或者年为单位,且预测结果对决策有决定性影响。然而,销量预测是一个非常困难的问题,在多数情况下,基于历史数据很难建立一个高效且精准的模型,导致该现状的主要原因有:缺乏历史数据,虽然目前处于大数据时代,但在多数情况下,仍然没有足够的数据量来预测未来趋势。历史数据不稳定,例如同一个产品前后几天的订单需求量可能相差很大,这意味着数据有较强的随机性,导致方差过大、不稳定。很多预测都偏向于长期预测,而长期预测本身比短期预测更加困难,例如,基于过去几天的天气状况以及温度数据,预测未来一个月后的天气和温度比预测一天后困难,因为第二天的天气和温度在某种程度上与刚过去几天的数据有较强的关联性。相反,预测周期越长,其准确率则难以保证。除了以上可能导致预测结果不准确的原因外,还有许多其他难以捕捉的因素也会对产品的未来销量造成影响,比如相似产品的价格竞争等。
在缺乏预测数据的情况下,传统机器学习与深度学习等算法预测效果较差,为此,本文提出一种基于数据集成的随机森林(Random Forest,RF)算法。该算法通过对模型特征进行随机重组,丰富训练样本的多样性。
1 相关工作
目前,工业界中提升销量预测准确率的方法主要在模型选择、特征工程与集成学习等方面。早期的销量预测主要以传统的时间序列预测方法为主,其中,代表性方法为指数平滑模型、差分自回归移动平均模型等,但它们都属于线性预测模型,并不具备非线性建模能力。很多研究将上述方法应用到气象[1]、经济[2-3]与网络流量[4]等领域进行分析预测,在实际生产环境中,实际值受到很多非线性关系的影响,因此预测效果较差。决策树(Decision Tree)、支持向量机(Support Vector Machine,SVM)等具备良好的非线性建模能力,因此基于机器学习的预测方法日渐增多[5-6]。
随着深度学习技术的快速发展,将深度学习相关技术应用到时间序列分析的研究越来越多。深度学习中的循环神经网络(Recurrent Neural Network,RNN)结构适合序列输入的特征,其中,以长短期记忆(Long Short Term Memory,LSTM)网络最具代表性,它能够避免原始RNN的梯度消失、爆炸以及遗忘长期记忆等问题[7],并广泛应用于语音识别[8]、机器翻译[9]和时间序列预测[10-11]等领域,且取得了显著效果。特征工程涵盖了特征提取、特征构造、特征编码、特征缩放与特征降维[12]等方面,特征工程与具体的预测任务紧密相关,不同的任务涉及到不同的特征工程,好的特征工程可以挖掘出与业务比较相关的因素,有效提升模型效果。
近年来,随着自动机器学习(Automatic Machine Learning,AML)的兴起,特征工程逐渐向自动化方向发展,但一部分特征工程任务还未实现自动化[13]。集成学习的思想主要是组合多个不同模型来提升单个模型的性能,代表算法有随机森林、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)等,这些算法可有效提高弱学习器的预测效果与泛化能力。差异性是集成学习能够提高其性能的重要因素[14],因此研究人员在度量模型间多样性和研究模型融合方法上做了大量工作[15-17]。不同于多数已有的研究工作,本文从数据角度出发,提出一种通用的数据集成方法,有效提升随机森林和其他模型的预测准确率。
2 基于数据集成的高维预测算法
2.1 问题定义
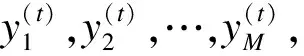
2.2 特征提取
根据历史数据序列{y(1),y(2),…,y(T)}预测y(T+D)的值,一般有2种方法:一是应用统计学中的时间序列预测模型(如ARIMA模型)直接预测下一个数值,但是对于长期预测问题,ARIMA模型的预测准确率不高;二是可以人为创建一个训练数据集,使用机器学习的相关算法进行预测。具体地,对于每一个目标值y,需提取出其对应的特征向量x以创建训练集{(x(t),y(t))},t=1,2,…,T。对于时间点t,本文将从2个维度对y(t)进行特征提取。一方面考虑历史数据值,使用最近一周的观测值作为目标y(t)的特征向量,即定义x(t)=(y(t-D-6),y(t-D-5),…,y(t-D)),其中,D+7≤t≤T(注意到本文的目标是预测时间段D后的Y值)。另一方面可以从时间信息的维度来增加特征,因为产品的订单需求往往与时间相关。产品的订单需求量可能取决于一周的第几天,甚至与月份、年份或者节假日有关,也会呈现周期性波动。因此,基于以上讨论,提取出表1中的信息并添加到特征向量中,对于非数值的分类特征,可以用One-Hot Encoding的方式进行编码处理。
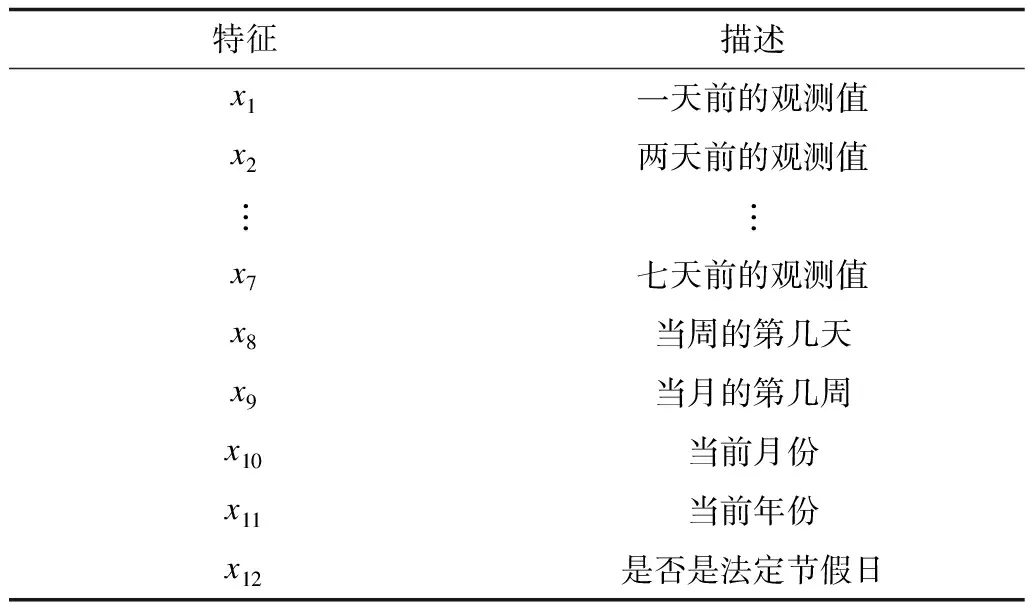
表1 基于历史数据以及时间维度的特征信息Table 1 Feature information based on historical dataand time dimension
2.3 本文算法
随机森林是用于分类或回归任务的一种集成学习算法,由一组决策树{h(x,Θk),k=1,2,…,K}组成,其中,x是输入的特征向量,{Θk}是具有独立同分布的随机序列,h(x,Θk)是第k棵树的预测结果。针对分类任务,随机森林采用投票机制,它参考所有决策树的分类结果,以得票最高的一类作为最终分类结果;针对回归任务,随机森林用所有决策树返回的平均值作为最终预测结果。
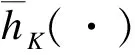
(1)
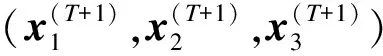
算法1基于数据集成的随机森林算法

步骤1将集合I={1,2,…,M}随机分割成S个子集I1,I2,…,IS,S为1到M之间的随机整数。
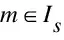
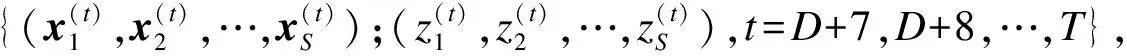
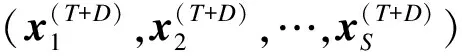
步骤5重复上述4个步骤N次。
步骤6返回N次结果的平均值作为最终预测值。
在讨论本文算法的收敛性之前,有以下3个问题需要特别说明:
1)本文选择随机森林作为基础模型进行研究,原因如下:文献[18]首次提出并证明了随机森林的收敛性定理,而本文算法是基于数据集成下的随机森林,其数据特征得到了增强,且同样继承了随机森林原本的收敛性质。由于随机森林的收敛性质,可避免模型过拟合。同时,随机森林的另一个重要特征是其并行性,因为每棵决策树之间相互独立,它们可以并行生成,能够节省大量的训练时间。因此,随机森林本身拥有的优点在基于数据集成的随机森林算法上都得到了良好继承。
2)本文采用数据集成思想对目标变量Y进行随机分割,该想法是受到了随机森林结构的启发,随机森林本身是一种对决策树的集成算法,多棵决策树共同做决定,相比于单棵决策树,模型最终的准确率、鲁棒性都得到了明显增强。本文将类似的集成想法应用到数据层面,模型的每轮拟合过程所用训练集都是在原始数据集上通过随机重组的方式而得到的新数据集,且数据重组的过程完全随机化,与先前训练集的生成过程相互独立。本文算法的最终预测结果也是采用平均值进行估计的,这点与随机森林相似。
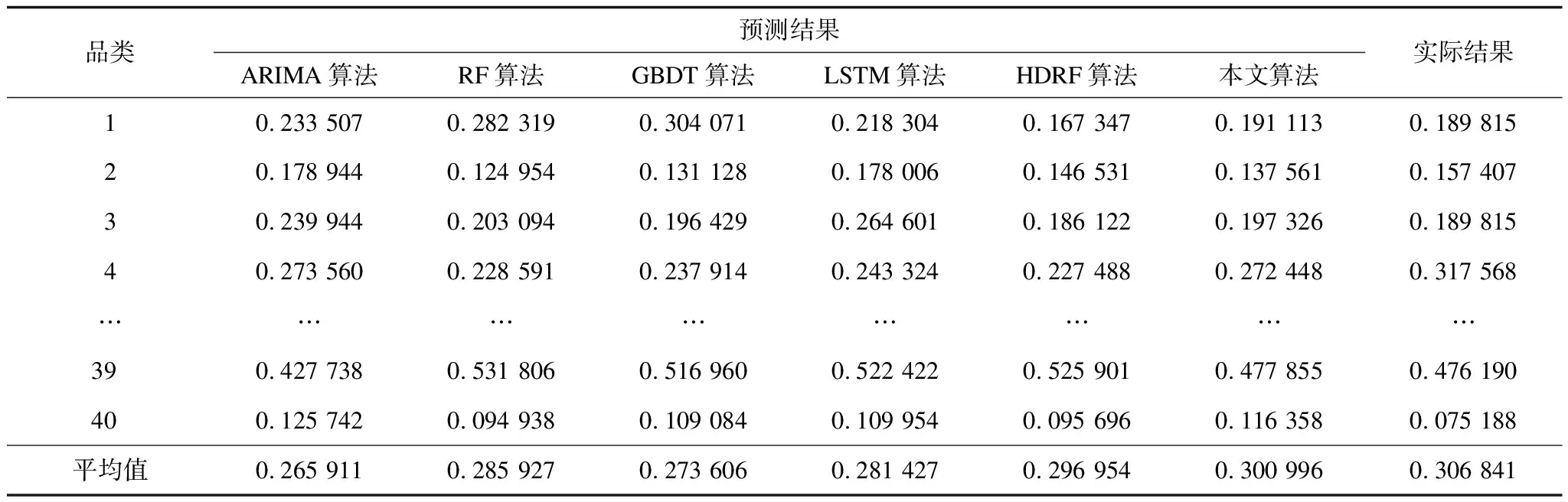
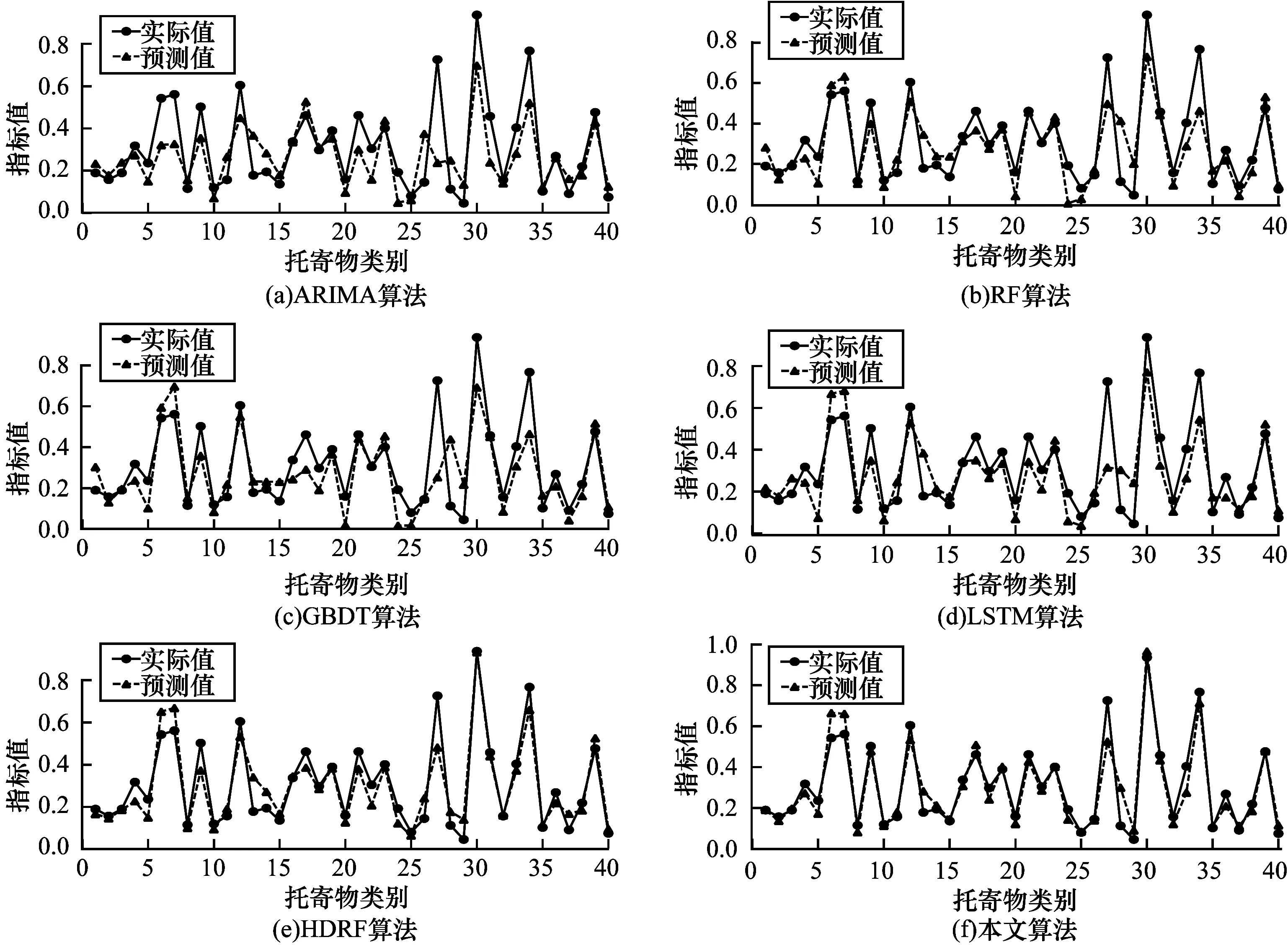
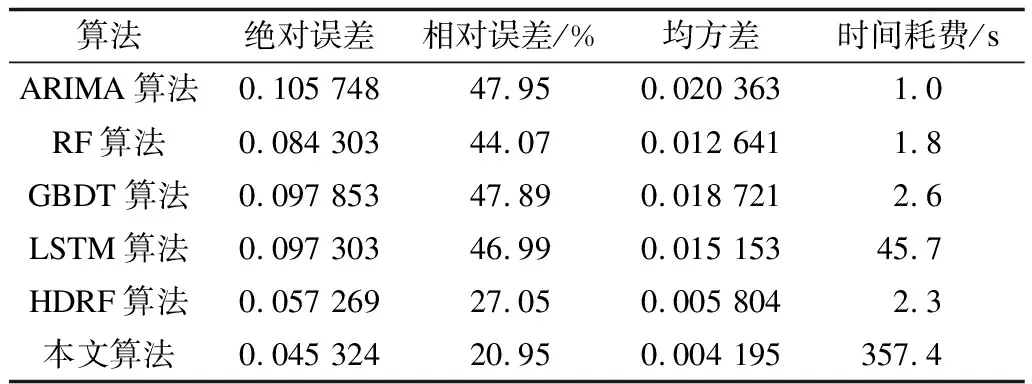
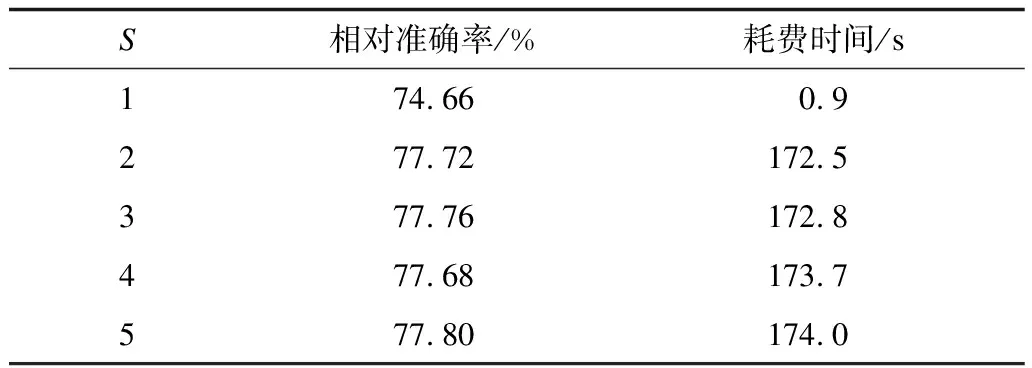
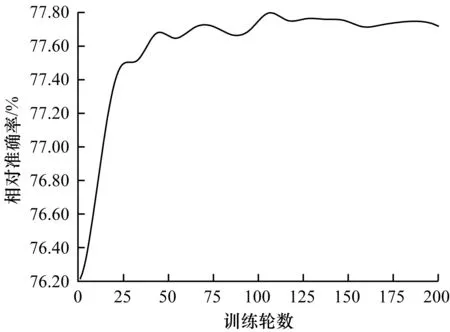
3)本文算法没有直接固定S=M,主要原因有2个:原因一是,如果固定S=M,该算法失去了算法1中数据集成的步骤1~步骤3,也没有重复过程(算法1中的步骤5),此时模型退化为随机森林,对准确率造成了影响;原因二是,如果固定S=M,则目标变量为M维向量(Y1,Y2,…,YM),该维度更高的M维向量比S(若S 根据文献[18],随着决策树数目的逐渐增多,随机森林的误差将会逐步收敛,基于随机森林的收敛性以及强大数定理,能够证明本文算法也有类似的收敛性质。 (2) 其中: (3) (4) 证明结合文献[18]中有关随机森林的收敛性定理,仅需证明对任意的输入向量x,以下收敛结果成立: (5) 将式(3)代入式(5)的左边部分,可得: (6) (7) 本文需要将M个指标随机分组成Sn个非空子集,用S(M,Sn)来表示其可能的所有分组结果数目。利用递归方法来求解S(M,Sn),具体可用式(8)、式(9)表示: S(M,Sn)=k·S(M-1,Sn)+S(M-1,Sn-1) (8) (9) 基于以上讨论,重新表示式(6)时,首先考虑Sn的取值,以NS来代表Sn取值为S的总次数(在N轮训练中),则有: (10) 因此,式(6)可重新表示为: (11) 根据式(11)可知,只需证明对任意的1≤S≤M,式(12)成立即可。 (12) 根据NS和Part(S)的定义可知,为了不失一般性,假设前NS个Sn的值均为S(如果不是则调整顺序),即对任意的1≤n≤NS,均有Sn=S成立,且对任意的NS (13) 式(13)最后一步的收敛是基于Sn在集合I={1,2,…,M}中的取值是完全随机且等概率的。对于任意固定的Sn=S,只需要证明以下收敛结果成立即可。 (14) |x,S,I1,I2,…,IS,Θ))= |x,S,I1,I2,…,IS,Θ)) (15) 其中,式(15)的收敛性来自于文献[18]中的定理2。 式(5)的右部分表达式为: |x,S,I1,I2,…,IS,ΘK))= (16) 其中,式(16)最后一步等式是因为所有决策树的预测结果的期望相同(独立同分布)。因此,当训练的轮数N逐步增大时,则有: LHS→RHS,N→∞ (17) 即式(5)成立,因此定理1成立。 2.4.1 本文算法的关键步骤 (18) 2.4.2 本文算法的复杂度分析 本文算法是一种集成方法,其基于随机森林总共训练N轮,且每轮训练相对独立,因此模型的训练耗时约为每轮随机森林耗时的总和。因为随机森林中的决策树通常是未经修剪的分类回归树,假设决策树的棵数、训练数据的样本量以及特征向量的属性个数分别为K、n和m,文献[19]表明该随机森林的算法复杂度为O(Knmlnn)。本文算法中每轮训练是数据的随机重组以及随机森林的拟合过程,数据重组的耗时与随机分割数S(S≤M)、训练数据的样本量n以及特征向量的属性个数m成正比,因此该步骤耗时为O(Mnm)。基于以上讨论,本文算法的复杂度为O(N(Knmlnn+Mnm))。此外,文献[20]表明,如果随机森林中决策树的棵数K较大,随机森林一般在达到该数目之前收敛。需特别说明的是,通常随机森林中决策树的棵数K以及样本量个数n远大于变量个数M,因此本文算法的复杂度可简化为O(NKnmlnn),其相当于重复了N次的随机森林。 本文实验的软件与硬件环境参数设置如表2所示,其中,实验选用Scikit-learn作为机器学习的主要框架。 表2 实验软件与硬件环境参数设置Table 2 Parameter setting of software and hardwareenvironment of experiment 本文的实验数据集来自顺丰科技有限公司2019年上半年广东省深圳市所有的快递运单数据,约1亿条运单,其中,每条运单均包含了托寄物品类的信息。由于同一类别的托寄物需要投入的人力、物力(纸箱、包装袋等)相似,该实验的目标是对于每一类托寄物,希望能提前预测出30天后的订单量,以便提前准备好应对措施。例如,对于手机品类,假定共有D种不同的手机品牌,可以定义Y=Y1+Y2+…+YD为手机品类总订单量,其中,Yd(1≤d≤D)为各手机品牌的订单量。结合顺丰科技有限公司所有的业务场景,实验总共对40个品类的托寄物进行建模、训练与预测。因为不同托寄物品类订单量的数量级级别不同,所以本文统一对数据进行相应的归一化处理,即用各品类托寄物的实际运单量除以2019年上半年该类别托寄物单天总单量的最大值。 利用顺丰科技有限公司截止到2019年6月30日深圳市所有运单数据来预测30天后各托寄物品类的运单量,实验选用的预测算法有ARIMA、RF、GBDT、LSTM与本文算法。其中,本文算法有2种不同的版本,一种是以Y=Y1+Y2+…+YD为目标变量,属于单维度预测,另一种是以(Y1,Y2,…,YD)为目标变量,属于高维度预测,并将预测出的高维向量求和作为最终预测结果。为了区分,本文称第2种算法为高维基于数据集成的随机森林(HDRF)算法,实际上HDRF算法是本文算法的一种特例。 除了时间序列算法ARIMA之外,RF算法、GBDT算法、LSTM算法、本文算法与HDRF算法在训练过程中均采用了交叉验证,其中,本文算法总共训练了200轮(即N=200),且其基础模型随机森林中决策树的数目为100、树的深度为10。6种算法的预测结果对比如表3所示,由于涉及公司商业机密,托寄物品类的名称以数字1~40替代。 表3 6种算法的预测结果对比Table 3 Comparison of prediction results of six algorithms 从表3可以看出,本文算法的预测结果与实际结果更为接近,这说明了相比于其他算法,本文算法的预测效果更好。为了更直观地看出上述6种算法的预测效果,图1对其在40种托寄物品类下运单量的预测值与实际值对比情况进行可视化,具体如图1所示。其中,每个分图对应一种预测算法。 图1 6种算法的预测结果与实际结果对比折线图Fig.1 Line chart of comparison between predicted results and actual results of six algorithms 从图1可以看出,本文算法的预测效果最好,其次为HDRF算法,这2种算法的预测结果与实际结果非常接近,在HDRF算法的基础上,结合数据集成方法后的本文算法表现更佳。本文从绝对误差、相对误差、均方差与时间耗费4个指标来对比所有算法的预测效果,结果如表4所示。 表4 6种算法的4种评价指标对比Table 4 Comparison of four evaluation indexes ofsix algorithms 从表4可以看出:相比于ARIMA算法、RF算法、GBDT算法和LSTM算法,本文算法的绝对误差至少提升了86%,相比HDRF算法,本文算法的平均绝对误差提升了26%;本文算法相比于其他算法,相对误差以及均方差的提升效果与绝对误差类似。绝对误差、相对误差、均方差是常用来评判模型效果的3个指标,这3个指标的对比结果说明了本文提出的数据集成思想的高效性。此外,表4反映的时间耗时与2.4节中对比分析RF算法、本文算法复杂度的理论结果一致。对于顺丰有限公司的每种托寄物品类的数据,半年的数据量实质上是一个不到200个离散点的时间序列,因此除了本文算法外,其他算法的训练时间都很短,本文算法的平均运行时间小于6 min,在时效牺牲不大的情况下,本文算法的预测准确率得到了大幅提升。 实验基于顺丰科技有限公司业务比较关注的托寄物类别中的手机类进行分析。为了验证数据集成的有效性,实验选取ARIMA算法为研究对象,分析数据集成下ARIMA算法的预测效果。手机类的运单数据较多且相对稳定,ARIMA算法自身的预测效果良好,相对准确率为74.66%,结合数据集成后,其相对准确率提高至77.74%,提升了3.08%。相比ARIMA算法,与数据集成相结合的ARIMA算法多出的时间耗费主要体现在其训练轮数上,该时间耗费的对比情况与下文中关于算法2的复杂度分析结果一致,在牺牲173.9 s的运行时间情况下,使得算法的预测准确率提高了3.08%。 为了研究随机分割数S对算法预测性能的影响,固定S值分别为2、3、4和5,用这些S值训练与数据集成相结合的ARIMA算法的预测相对准确率和时间耗费,训练轮数为200(N=200)轮,结果如表5所示。从表5可以看出,随机分割数S的大小对算法的预测相对准确率影响不大,在运用随机分割的思想(即S>1)下,与数据集成相结合的ARIMA算法的预测相对准确率提升了约3%。 表5 分割数S对算法相对准确率的影响Table 5 Influence of segmentation number Son relative accuracy of algorithm 同时,为了验证训练轮数N对算法预测效果的影响,实验记录了随着训练轮数的增加,ARIMA算法的预测相对准确率的变化过程,具体如图2所示。从图2可以看出,除了一些微小波动外,相对准确率随着训练轮数的增大呈现逐渐升高后趋于稳定的趋势。 图2 训练轮数对ARIMA算法相对准确率的影响Fig.2 Influence of training round number on relativeaccuracy of ARIMA algorithm 基于以上几组实验可以看出,将数据集成结合到其他预测算法中时,能够提升算法的预测效果,基于此,本文提出基于数据集成的通用预测算法,具体步骤如下: 算法2基于数据集成的通用预测算法 步骤1将集合I={1,2,…,M}随机分割成S个子集I1,I2,…,IS,S为1到M之间的随机整数。 步骤5重复以上4个步骤N次。 步骤6返回N次结果的平均值作为最终预测值。 算法2实质上是算法1的推广,两者的本质并无区别,它们的核心思想都在于预测目标变量以及训练集拆分后的随机重组过程(参照2.4节),不同之处在于后期基础算法的选择。算法1选择以随机森林作为基础算法,而算法2在算法1的基础上进行拓展,基础算法的选择自由度较宽泛,任意的预测算法都能适合。与算法1复杂度分析过程类似,算法2相当于是在数据随机重组的基础上将选择的基础算法重复训练N次。假设基础模型的参数为Θ,用函数O(f(n,m,Θ))表示其复杂度,则算法2的复杂度为O(N(f(n,m,Θ)+Mnm)。 将数据的随机重组与现有随机森林算法相结合,本文在数据层面上提出一种基于数据集成的随机森林算法,该算法保留了随机森林的收敛性质与优点。实验结果表明,相比未使用数据集成的预测算法,本文算法在绝对误差、相对误差与均方差指标上均有大幅提升。同时,拓展实验说明了数据集成还可以应用在ARIMA等其他算法上,且在不改变算法基本框架的条件下,仅对数据特征进行增强即可实现准确率约3%的提升。后续将利用大数定理、中心极限定理等理论知识对本文预测算法的收敛速度和准确率进行研究,并优化数据特征的随机重组方式,使算法在理论与实践中均取得较好的预测效果。



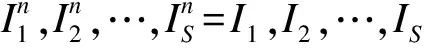
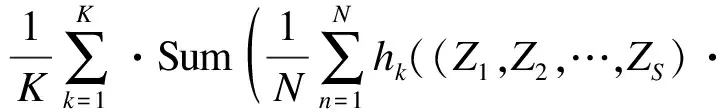
2.4 本文算法的关键步骤与复杂度分析

3 实验结果与分析
3.1 实验环境

3.2 实验数据集
3.3 各类预测模型的性能比较
4 基于数据集成的预测算法
4.1 数据集成在其他算法上的应用
4.2 随机切割数与训练轮数对算法的影响
4.3 基于数据集成的通用预测算法

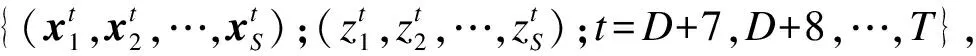
5 结束语
