融合知识图谱与协同过滤的推荐模型
2020-12-16张亚钏卜荣景
康 雁,李 涛,李 浩,钟 声,张亚钏,卜荣景
(云南大学 软件学院,昆明 650500)
0 概述
随着大数据时代的到来,互联网公司尤其是电商网站对数据的需求不断增加,因此,基于数据的推荐算法成为研究热点。目前,针对个性化推荐的研究成果较多,推荐算法主要可分为协同过滤推荐算法、基于内容的推荐算法和混合推荐算法[1]。协同过滤推荐算法[2-4]利用人群意愿进行推荐[5],虽然在推荐准确性上取得了显著的提升效果,但与许多基于内容的推荐算法相比解释推荐结果时不直观[6]。基于内容的推荐算法[7-8]通过各种可用的内容信息对用户和物品进行特征建模。由于物品内容对用户而言比较容易理解,因此在基于内容的推荐中,通常可以直观地向用户解释为何该物品被推荐。
在不同的推荐背景下收集所需要的内容信息是一项耗时的任务[6],这成为基于内容推荐算法的瓶颈。而构建知识图谱只需要利用实体与实体之间的关系,可减少提取内容信息的工作量。因此,知识图谱作为一种新兴的辅助数据,引起了学术界和工业界学者的广泛关注[9]。
近年来,深度学习因其强大的表示学习能力,在图像处理、自然语言处理和语音识别等领域得到成功应用,也为推荐系统研究带来新的思路。但现有基于深度学习的推荐算法[10-12]多利用矩阵分解思想,只考虑了用户与物品的评分数据,抑制了推荐效果[13]。
混合推荐算法[14-15]通过结合多种推荐算法的优点,能够得到更好的推荐效果。因此,本文构建一种结合知识图谱、深度学习和协同过滤的混合推荐模型HCKDC,其中包含RCKD和RCKC两个子模型。RCKD结合知识图谱推理与深度学习,得到第1种预测评分,RCKC将协同过滤思想结合知识图谱表示学习的语义相似性,得到第2种预测评分。预测评分的准确性决定了其对整体模型的重要程度,按此重要程度将两个子模型相互融合,得到可解释的推荐结果。使用MovieLens-100K数据集进行实验,将HCKDC与可解释推荐模型RKGE[16]和RippleNet[17]进行对比,以验证其有效性和先进性。
1 相关研究
1.1 协同过滤推荐
文献[2-3]分别提出了基于用户和基于物品的协同过滤算法,而将协同过滤算法与潜在因子模型(Latent Factor Model,LFM)[4]相结合,能够进一步提升推荐效果。文献[4]提出一种将LFM和邻域模型相互融合的协作过滤模型。协同过滤一定程度上可以根据其算法设计的原理进行解释。例如,基于用户的协同过滤推荐可以解释为:推荐的物品是与该用户类似的用户喜欢的物品。而基于物品的协同过滤可以解释为:推荐的物品是与用户喜欢的物品类似的物品。但与许多基于内容的推荐算法相比,协同过滤推荐的解释推荐结果不直观。
1.2 基于内容的推荐
基于内容的推荐利用各种可用内容信息对用户和物品进行特征建模,如文献[7-8]提出的基于内容的协同过滤系统。虽然基于内容的推荐具有较好的可解释性,但在不同的推荐背景下收集所需要的内容信息十分耗时。
1.3 基于知识图谱的推荐
知识图谱包含用户和物品的丰富信息,这些特性也可为推荐物品的生成提供更直观、更具针对性的解释,并且构建知识图谱只需要利用实体与实体之间的关系,这将很大程度减少基于内容推荐时提取内容信息的工作量。
将知识图谱引入推荐系统的研究,有以连接两个实体的路径代表不同语义的扩展潜在因子模型[18],如文献[19]中的元路径方法。这种方法有助于根据物品相似性推断用户偏好,从而生成有效的推荐。然而,元路径方法严重依赖于手工制作元路径的特性,需要额外领域的知识,并且手工制作的元路径特性往往不完整,很难覆盖所有可能的实体关系,从而阻碍了推荐质量的提升。与元路径方法相比,知识图谱表示学习能够自动学习获得知识图谱中实体的语义嵌入,具有更好的推荐效果[16]。目前,基于知识图谱表示学习的研究成果较多[20],其中备受关注的有Translating系列表示学习算法。文献[21]提出了TransE算法,其基本原理是给定三元组(h,r,t),以关系r向量作为头实体h向量和尾实体r向量之间的平移。
1.4 基于深度学习的推荐
在基于深度学习的推荐方面,文献[10]提出一种基于受限玻尔兹曼机的协同过滤模型,文献[11]提出一种深度结构化语义模型,文献[12]结合多层感知机模型和广义矩阵分解模型,提出一种神经协同过滤算法,进一步提升了推荐模型的性能。但上述算法模型均利用矩阵分解的思想,只考虑了用户与物品的评分数据,抑制了模型的推荐效果。
1.5 混合推荐
混合推荐算法同时综合多种推荐算法的优点,能够得到更好的推荐效果,如文献[14]将协同过滤推荐算法和基于知识图谱表示学习语义邻近推荐算法进行融合,文献[15]以4种方式对矩阵分解和RNN模型进行融合,均有效提升了推荐准确率。
2 混合推荐模型HCKDC
本文提出的HCKDC模型由知识图谱与深度学习结合模型RCKD和知识图谱与协同过滤结合模型RCKC构成。利用RCKD模拟知识图谱中的推理过程,解决信息提取困难和可解释性不高的问题,同时利用RCKC较好的可解释性,进一步提高推荐质量。HCKDC整体模型架构如图1所示。

图1 HCKDC模型架构
2.1 RCKD模型
RCKD结合知识图谱与深度学习方法,首先获取知识图谱推理路径,然后基于知识图谱表示学习TransE算法将推理路径嵌入成为向量,最后运用深度学习捕获路径推理语义进而获得预测评分。
2.1.1 推理路径生成及推理描述
本文首先利用已知的所有三元组(h,r,t)构成图,然后通过构建图的方法搜索知识图谱中的推理路径。具体地,将实体映射为图中的点,将关系映射为图中的边,通过指定两个实体遍历整个图就能得到两个实体的所有路径。这些路径即为两个实体之间的推理路径。
图2为一个知识图谱局部图,可以看出,u186到i322的生成的推理路径共有6条,分别为“u186→i1042→g3→i322”“u186→i79→g3→i322”“u186→i291→g3→i322”“u186→i55→g3→i322”“u186→i540→g3→i322”和“u186→i540→a152→i322”。其中:推理路径“u186→i540→g3→i322”可以表示用户u186喜欢电影i540,电影i540属于g3流派,电影i322也属于g3流派,因此,用户u186也可能喜欢电影i322;推理路径“u186→i540→a152→i322”可以表示用户u186喜欢电影i540,电影i540的演员有a152,电影i322也被a152演过,因此,用户u186也可能喜欢电影i322,……。该例强调了连接同一个实体对的不同路径通常带有不同语义关系。通常,它们在描述用户对物品的喜好方面具有不同的重要性。区别这些路径的重要性并综合这些路径的推理结果得到预测评分,可使推理过程具有较好的可解释性。RCKD模型即使用深度学习的方式模拟这些路径的推理过程,再对其重要性加以区分,最后综合这些路径的推理语义得到预测评分。
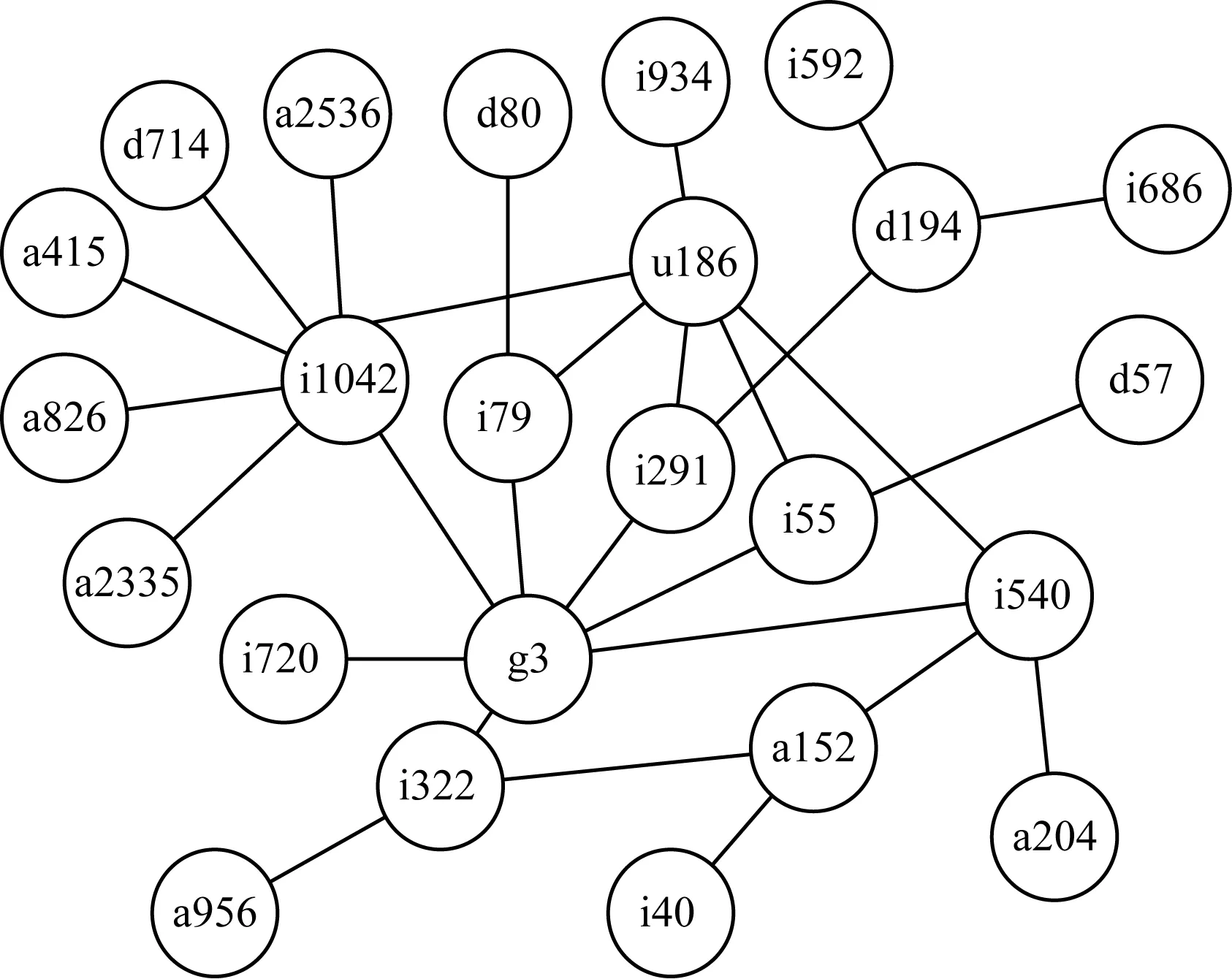
图2 知识图谱局部图
2.1.2 推理路径嵌入向量生成
深度学习在自然语言处理、图像处理等领域的成功应用得益于其强大的表示学习能力。因此,本文利用知识表示学习TransE算法得到知识图谱推理路径嵌入向量。TransE的基本原理是给定三元组(h,r,t),以关系r的向量lr作为头实体向量lh和尾实体向量lt之间的平移。TransE的损失函数定义为:
lossr(h,t)=|lh+lr-lt|L1/L2
(1)
即lh+lr到lt的L1或L2距离。
在实际训练过程中,为加强知识表示的区分能力,TransE采用了最大间隔方法,定义了优化目标函数:
(2)
其中,S为合法三元组的集合,S-为错误三元组的集合,γ为合法三元组得分与错误三元组得分之间的间隔距离。
错误三元组并非随机产生。为选取有代表性的错误三元组,TransE将S中每个三元组的头实体、关系和尾实体其中之一随机替换为其他实体或关系来得到S-。
通过TransE对所有三元组的训练,每一个实体k可以表示成为一个向量ek。一对实体u-i第m条路径的嵌入表示如式(3)所示:
puim=[euim1,euim2,…,euimn,…]
(3)
其中,euimn表示用户u到物品i的第m条路径中第n个实体的嵌入向量。
2.1.3 预测评分的生成
在生成预测评分时,首先通过长短期记忆(Long Short-Term Memory,LSTM)[22]和soft attention[23]机制捕获路径的推理语义,然后通过maxpooling操作区分不同路径推理语义的重要性,最后用全连接汇集池化向量并经sigmoid函数生成预测评分。
以推理路径“u186→i540→g3→i322”为例,此路径表示用户u186喜欢电影i540,电影i540属于g3流派,电影i322也属于g3流派,因此,用户u186也可能喜欢电影i322。这个推理过程是逐步得到的,因此,可以采用循环神经网络(Recurrent Neural Network,RNN)捕获推理的语义。本文选取的是能够有效解决RNN梯度消失和梯度爆炸问题的LSTM机制。
LSTM单元如图3所示,其中包含3类门控,即输入门、遗忘门和输出门,分别使用i、f和o来表示。此外,LSTM中还包含记忆单元c和输出值h。
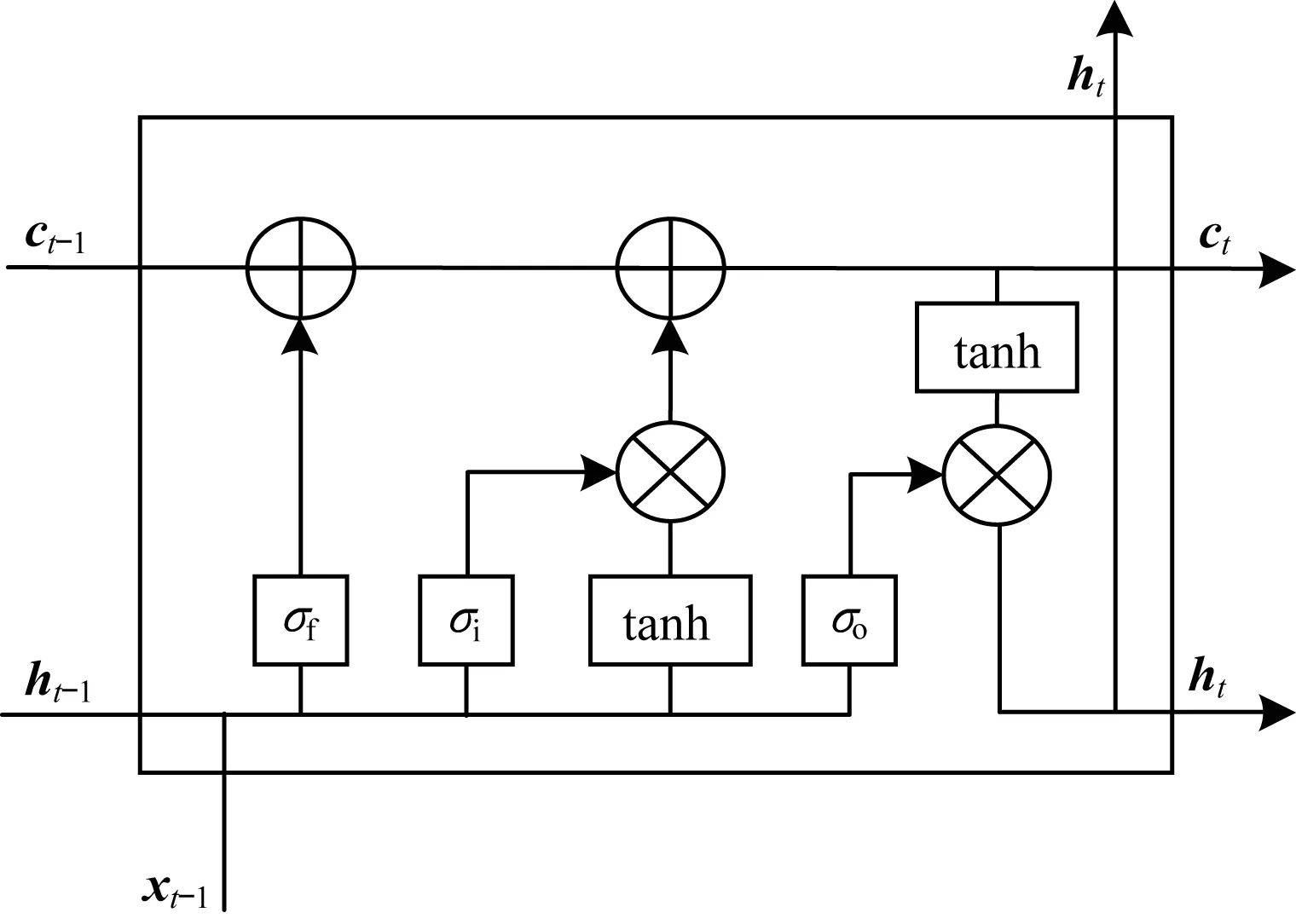
图3 LSTM单元
LSTM迭代的第t时刻各值的计算公式如下:
it=σ(Axixt+Ahiht-1+bi)
(4)
ft=σ(Axfxt+Ahfht-1+bf)
(5)
ot=σ(Axoxt+Ahoht-1+bo)
(6)
ct=ft⊙ct-1+it⊙tanh(Axcxt+Ahcht-1+bc)
(7)
ht=ot⊙tanh(ct)
(8)
其中,A和b分别为LSTM的权重矩阵和偏置向量,⊙表示Hadamard乘积。
为避免网络过拟合,本文对每条路径都采用同一个LSTM捕获语义。将已嵌入的路径向量puim输入LSTM,能够得到LSTM推理中每一次迭代的推理语义,实体对u-i第m条路径的输出语义可表示为:
huim=[huim1,huim2,…,huimn,…]
(9)
为使最后推理的语义与推理过程中每次迭代得到的推理语义关联性更强,本文使用了soft attention机制。通过此层能够求得LSTM每一次迭代推理得到的语义对最后一次迭代推理语义的影响度,并总结出这个路径的最终语义。假设对于实体对u-i第m条路径有l个实体,对于LSTM第n次迭代推理语义的attention权重Wuimn计算公式如下:
suimn=huiml·huimn
(10)
(11)
此条路径经过soft attention处理后得到的最终语义可由式(12)得到:
(12)
为区分路径推理语义的不同重要程度,本文选择了池化操作。池化操作能够关注向量最重要的特征或综合的特征,符合本文需要关注路径语义不同重要性的要求。经实验验证,maxpooling效果优于avgpooling,因此,选取maxpooling池化操作。最后通过全连接层汇聚所有路径的池化向量,经过sigmoid函数产生u-i的预测评分Dui,如式(13)所示:
(13)
其中,mpooling_con的mpooling和con分别代表maxpooling操作和全连接操作。
2.2 RCKC模型
协同过滤方法虽然不能解释推荐结果,但具有较高的推荐准确率。为使协同过滤具有更好的解释性,本文提出了RCKC模型。RCKC结合知识图谱与协同过滤方法,采用TransE方法得到知识图谱中实体语义表示向量,再利用协同过滤思想根据向量的相似性推荐与用户喜欢物品语义相近的物品。
根据2.1.2节可知,每个实体都可以用TransE算法得到对应的语义表示向量。RCKC根据这些语义表示向量计算每个物品和其他物品的语义相似性。对物品i和物品j的语义相似性进行评分,计算公式如下:
(14)
以I表示整个语义相似矩阵,Iij表示物品i和物品j的语义相似性评分,||ei-ej||1表示ei-ej的L1范数结果,即将ei-ej向量的每个分量的绝对值相加。
假设用户u历史评分集为Tu,需要预测的物品集为Eu,对于itemk∈Tu,itemi∈Eu,用户u对物品itemk的评分为Ruk,物品itemk和itemi语义相似性评分表示为Iki,预测用户u对物品i的评分为Cui。用户u对物品i的预测评分计算公式如下:

(15)
RCKC模型中预测评分列表生成方法如算法1所示,其中,Eu={item1,item2,…},Tu={Ru1,Ru2,…}。
算法1RCKC评分列表生成算法
输入历史评分集Tu,需要预测的用户物品集Eu,语义相似矩阵I
输出RCKC预测评分列表C
1.for Eu∈{E1,E2,…,En} and Tu∈{T1,T2,…,Tn} do:
2.for itemi∈Eudo:
3.for Ruk∈Tudo:
4.Cui←Cui+Ruk×Iki
5.end for
6.end for
7.end for
RCKC推荐的评分预测利用知识表示学习的语义相似性推荐与用户历史喜好的最接近物品,具有较好的可解释性。
2.3 HCKDC模型
HCKDC模型为融合RCKD模型和RCKC模型的总体模型。本文借鉴了文献[15]中的第1种融合策略,即将矩阵分解和RNN推荐对应预测评分相加,经过sigmoid函数产生最终的预测评分。用户u和物品i的RCKC预测评分是Cui,RCKC模型的预测评分是Dui,最后融合生成的预测评分计算公式如下:
(16)
其中,α、β分别为RCKC预测评分Cui和RCKD的预测评分Dui的比例系数,b为偏置项。
融合策略的训练过程根据RCKC和RCKD预测得分的准确性自动调整其对最终模型的影响程度,同时优化RCKC和RCKD的内部参数,因此,具有很好的可解释性。
用户的推荐列表通过用户对物品最后预测评分从大到小排序得到,用户推荐列表生成算法如算法2所示,其中,Eu={item1,item2,…}。
算法2HCKDC推荐列表生成算法
输入需要预测的物品集Eu,RCKC推荐预测评分列表C,RCKD预测评分列表D,RCKC比例系数α,RCKD比例系数β,偏置项b
输出HCKDC推荐列表L
1.for Eu∈{E1,E2,…,En} do:
2.for itemi∈Eudo:
3.Lui←α×Cui+β×Dui+b
4.end for
5.sort(Lu)
6.end for
3 实验与结果分析
3.1 数据集
本文实验使用MovieLens-100K数据集。在此基础上,在IMDB中爬取电影流派、导演、演员信息作为辅助信息,以此扩展知识库,使知识图谱能够获得更好的性能。
MovieLens-100K数据集包含943个用户、1 682个电影和100 000个评分。去除缺失数据后的数据集如表1所示。这些数据映射到知识图谱后,共包含7 746个实体、8种关系和202 183个三元组。其中,三元组不包含测试集中正样本集的评分与被评分关系三元组。

表1 去除缺失数据后的数据集Table 1 Data set after removing the missing data
在协同过滤中测试考虑评分值和不考虑评分值的情况,可知推荐效果差距很小,甚至考虑评分后还有推荐效果下降的趋势。因此,实验不考虑评分值,即如果用户对某个电影有评分,就假设为该用户喜欢该电影,评分置为1。将该用户不喜欢的电影评分设为0。
为使实验数据具有可比性,对所有的实验都采用相同的训练集和测试集。产生的训练集和测试集的正样本是对加入辅助信息后的99 975个评分数据以4 ∶1的比例进行拆分得到的。测试集正样本的作用是检验模型产生的推荐列表中物品是否准确。
对于训练集中负样本的选取,本文采用随机抽取的方式。为使模型能够学到更多的负样本信息,设定对每个用户抽取的负样本数据量是训练集正样本的120%。
由于随机选取了一些负样本作为训练集,如果不把这些负样本纳入测试集,相较于协同过滤等方法,会使得到的测试集中可能包含的负样本更少,影响预测结果的真实性,因此,将除训练集中正样本的其他所有样本作为测试集。
3.2 路径抽取
文献[19]已证明,越短的路径对推荐结果越重要,并且路径长度超过5时会引入噪声。为加速路径抽取过程和训练过程,本文对每一对user-item最多只挖掘5条最短的路径,即最多挖掘5条长度为3的路径。
在路径抽取时,先抽取训练时所用到的正负样本的路径,再抽取用户到其他物品的路径。
3.3 评价指标
实验采用的评价指标为precision@N和MMR@N。precision@N表示每个用户推荐列表前N项在测试集正样本中出现的概率的均值,N取值包括1、5、10。MMR@N定义如式(17)所示:
(17)
其中,N设定为10,vj是在top-N推荐列表中正确出现在测试集正样本的项,rank(ui,vj)表示vj在用户ui推荐列表的位置数。
3.4 模型设置
考虑到所有user-item路径数量的不确定性,在池化操作中如果用相同池化窗口和池化步长会引起数据维度不一致。因此,根据路径数量动态地调整池化窗口和池化步长,大小均为(paths_size,1)。
为保证RCKD有效性,本文设置预训练次数,即在不融合的情况下单独训练RCKD的次数。实验中RCKD训练6次时效果最好,因此,将预训练次数设置为6次。α、β、b初始值均为0。LSTM隐藏单元数为64,学习率为0.1,优化方法采用随机梯度下降法。
针对RCKC和RCKD不同推荐列表的预测评分差异性问题,同时考虑到RCKD模型的预测评分属于[0,1]范围,在得到RCKC模型的所有推荐结果后,对推荐列表从前到后以1到0递减的顺序重新设置评分。
3.5 结果分析
在公开数据集MovieLens-100K中进行实验,比较方法为近期比较先进的可解释推荐方法RKGE和RippleNet。此外,选取经典的协同过滤算法进行对比。实验结果如表2和表3所示,其中:User-based-CF表示基于用户的协同过滤算法;User-based-CF-CR表示考虑评分值的基于用户的协同过滤算法;Item-based-CF表示基于物品的协同过滤算法;Item-based-CF-CR表示考虑评分值的基于物品的协同过滤算法。由表3可见,基于用户的协同过滤考虑评分值时各性能指标轻微下降,基于物品的协同过滤考虑评分值时precision@10指标也有所下降。
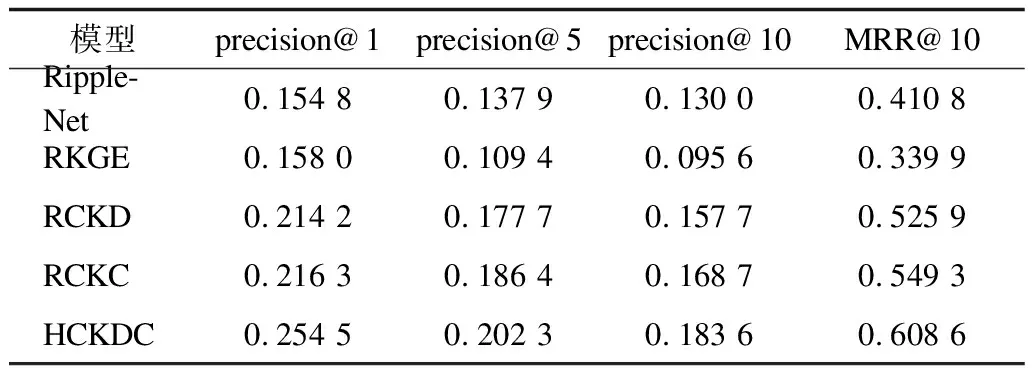
表2 本文模型与RKGE和RippleN的实验结果Table 2 Experimental results of the proposed model,RKGE and RippleN
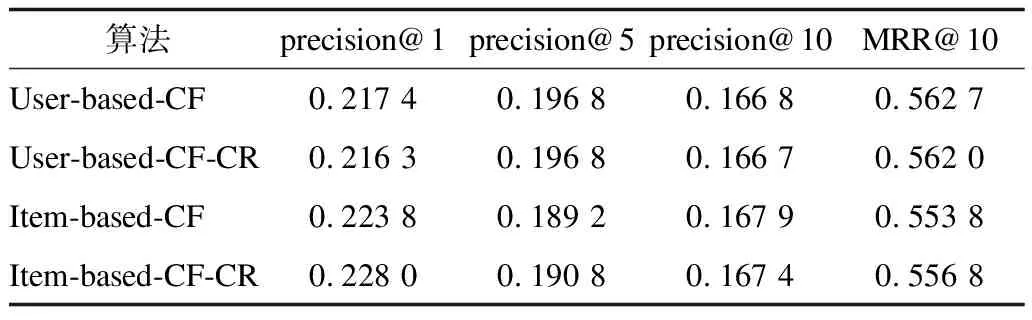
表3 经典协同过滤算法的实验结果Table 3 Experimental results of classical collaborative filtering algorithms
从表2和表3可以看出,本文HCKDC模型的推荐准确性在所有比较方法中最高,协同过滤、RCKC、RCKD其次,RippleNet和RKGE最差。可以发现,可解释推荐算法RippleNet和RKGE虽然对其推荐可解释性较好,但推荐效果不如协同过滤。在同时具有较好可解释性情形下,RippleNet和RKGE推荐效率也低于本文的RCKD和RCKC模型。此外,很容易观察到RCKC和RCKD在融合之后推荐准确率得到进一步提高,这证明了融合策略的有效性。本文模型的可解释性已在上文第2节具体描述,由实验结果可知,该模型取得了最高的推荐准确率,证明其在有较好可解释性的情况下具有更高的推荐准确率,验证了其先进性。
HCKDC训练过程中各数据如图4~图6所示。

图4 HCKDC训练过程中precision的变化

图5 HCKDC训练过程中MRR@10的变化
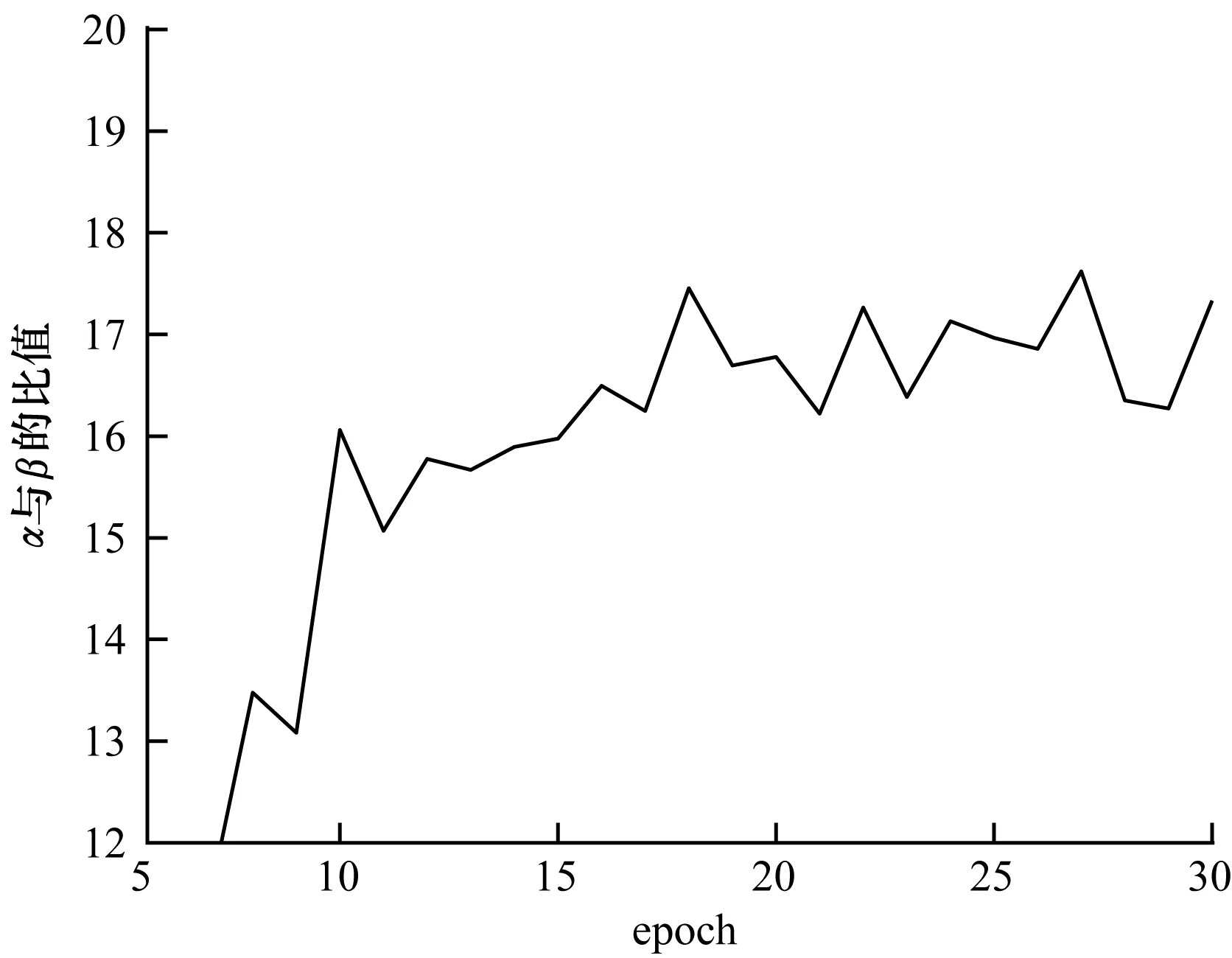
图6 HCKDC训练过程中α与β比值的变化
由图4和图5可以看出,MRR@10和precision在epoch为28左右时最好。由图6可以看出,当训练次数为15次左右时,α和β比值基本维持在16.5左右,可见RCKD对整个模型的影响程度很小。但RCKD和RCKC融合后整体推荐效率提高,说明RCKD有效修正了融入知识图谱后协同过滤的推荐结果。
4 结束语
本文构建一种结合知识图谱、深度学习和协同过滤的混合推荐模型HCKDC,其由RCKD和RCKC模型构成。RCKD模型将知识图谱推理结合深度学习模拟得到预测评分,RCKC模型将知识图谱表示学习结合协同过滤思想得到预测评分。把两种推荐模型得到的同一用户对同一物品的不同预测评分分别乘以系数相加,再加上一个偏置项,把所得结果作为用户对该物品的最终喜好程度,并通过对用户按物品预测评分从高到低排序得到最终的物品推荐列表。实验结果表明,相较于RKGE、RippleNet模型和经典协同过滤算法,HCKDC模型在可解释的情况下能够达到更高的推荐准确率。下一步将引入电影海报等更多内容信息,以扩大本文模型的推荐范围。
