多层级特征融合结构的单目图像深度估计网络
2020-12-16贾瑞明崔家礼王一丁
贾瑞明,李 阳,李 彤,崔家礼,王一丁
(北方工业大学 信息学院,北京 100144)
0 概述
深度图像包含场景的三维结构信息,广泛应用于三维重建[1]、语义分割[2]、机器人视觉[3]与智能驾驶[4]等图像处理任务中。采用Kinect或者激光雷达等硬件专用设备获取场景深度信息时,存在设备昂贵、采集成本高、捕获的深度图像分辨率低以及大面积深度缺失等问题。目前,分布较为广泛的视频监控系统、行车记录仪、手机与平板等电子设备中的摄像机多数是单目图像采集设备,因此,研究单目图像深度估计具有重要的实用价值和推广意义。
研究人员根据图像中包含的光学反射关系、几何位置等关系,提出多种用于估计图像深度信息的算法,根据是否采用卷积神经网络技术可以分为传统算法和基于深度学习算法。其中,传统算法获取深度图的方式可分为两类:一类是从单目图像中估计深度信息,利用图像中的物体结构特点以及物体与物体之间的相互联系,归纳出估计深度信息的相关规律,典型算法主要有从阴影中恢复形状算法[5]、从纹理中恢复形状算法[6]等,这些算法需要严格规定图像场景,比如从阴影中恢复形状算法需要假设场景中的物体都是朗伯辐射体,增加了算法的实现难度。另一类是从多目图像中估计深度信息,使用2个摄像头获取同一个场景的2幅图像,利用三角测量法将2幅图像间的匹配信息转化为深度信息,典型算法包括SGM算法[7]、ADCensus算法[8]等。利用多张图像中物体的相对位置来估计深度信息可提高预测精度,但是造成了计算量及复杂程度的增加。
采用深度学习算法获取深度图信息时,按照输入图像的数量可分为单目图像和多目图像2种。在基于深度学习单目图像预测深度图算法中,文献[9]提出利用卷积神经网络(Convolutional Neural Network,CNN)预测深度图,采用不同尺度的卷积核对RGB图像进行卷积,并将不同尺度的特征图相融合。文献[10]提出多任务网络结构,不仅可以预测深度图,而且可以预测表面法向量和语义分割。文献[11]采用ResNet50[12]作为编码器,利用上投影模块进行解码,进而获取深度图。文献[13]针对预测深度图像边缘较为模糊的问题,提出双流网络结构,一部分网络结构用来估计深度信息,另一部分用来估计图像梯度,将两者融合,从而确保深度图像边缘更加清晰。文献[14]更改了ResNet101网络结构,将6个不同尺度的输出相融合,并采用视野更大的空洞进行卷积。文献[15]通过网络获取深度图后,在频域内对其进行处理以提高深度图效果。在基于深度学习双目图像预测深度图算法中,文献[16]提出一种快速且精度较高的网络结构,通过计算网络输出结果的置信度来提高预测准确度。文献[17]提出一种基于深度学习改善的立体匹配算法,通过多级加权跳跃连接及汇聚视差来估计深度信息。文献[18]采用非监督方式将左右视图分别发送至网络进行训练,同时利用左右视图的深度图标签来约束网络输出结果。文献[19]将多张图片输入网络,经过特征提取后,通过计算图像的可微单应矩阵来构建代价量,由三维卷积网络优化得到三维概率空间,并基于参考影像估计出深度信息。
基于深度学习的估计深度图算法主要依赖于神经网络结构的性能,对图像采集场景没有严格要求,且在运行过程中不需要摄像机标定及图像校正等繁琐操作,因此其效率明显优于传统算法。然而,在单目估计深度、多目估计深度2个发展方向中,单目估计更具有实用性和推广价值,且二维图像的距离信息缺失使其更具有挑战性。
在单目图像预测深度图任务中,深度图的预测存在深度信息不精确、图像边缘模糊以及细节缺失等问题。基于此,本文提出一种多层级特征融合编-解码网络结构,单目图像经过卷积后得到低维特征图和高维特征图,利用低维特征图与高维特征图之间的空间关系,分别在编码器和解码器上设计2种不同形式的多层级特征融合结构,以提高深度图的预测精度。
1 多层级特征融合编-解码器网络
人类大脑在观察一张图像时,先会了解图像中场景的大致布局,再根据场景中物体的相对位置,推断出某一个物体的深度信息,经过不断地推断场景中物体的相对位置,进而获取场景中整个深度信息。本文提出一种多层级特征融合结构的神经网络,该网络采用端到端的编-解码器结构,其优势在于具备抽象和重建能力,且在编码器和解码器中分别添加多层级融合结构,以提高网络性能。
1.1 编码器多层级融合结构
目前,针对图像预测密集深度图像任务的研究中多数采用ResNet作为编码器,这是因为其对图像具有很强的抽象能力。本文采用ResNet101在ImageNet图像分类任务中训练得到的预训练模型作为编码器,采用迁移学习的方法加快网络收敛,并防止梯度爆炸和梯度弥散现象的发生。ResNet网络结构简单,残差块主要有BasicBlock和Bottleneck 2种形式,具体结构如图1所示。
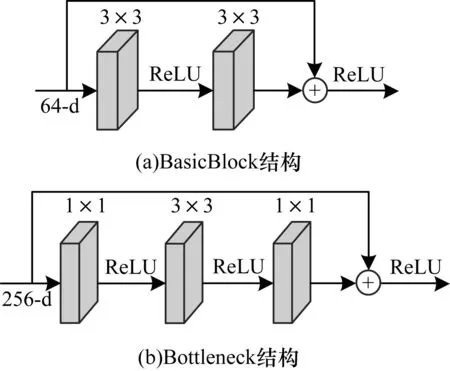
图1 残差块的2种结构形式Fig.1 Two structural forms of residuals block
本文采用Bottleneck结构,将2个1×1卷积层替换BasicBlock中的一个3×3卷积层,实现了数据的降维和升维,同时加深了网络结构,提高网络的特征描述能力。编码器的多层级融合思想主要来源于ResNet[12]网络结构,如图1所示,ResNet模块的结构是将经过卷积的特征图与恒等映射的残差块相加,相当于将卷积前的特征与卷积后的特征进行相加融合。本文在ResNet结构的基础上,提出一种在更大范围模块间进行融合相加的结构,称为多层级特征融合结构,具体如图2中的编码器(Encoder)部分所示。

图2 多层级特征融合编-解码网络结构Fig.2 Multiple level feature fusion encoder and decoder network structure
在编码过程中,随着卷积层数的递进,输出的特征图分辨率呈现从高到低的变化趋势,维度呈现从低到高的变化趋势,特征图的表征也从具象逐渐变为抽象。在特征图分辨率降低过程中,原始图像中场景的内在几何空间关系会被逐步削弱。为了保持这种空间位置关系,将原始高分辨特征图经过调整之后,叠加到当前输出特征图中,使得网络能够保留原始高分辨特征图中的空间关系,以提升网络对空间位置细节信息的保持能力。
编码器多层级融合结构是通过跨层级调整模块实现的,该模块对上一层级的特征图进行调整,并与当前输出特征图相加,实现特征图的多层级融合。该模块主要由一个1×1卷积层和一个最大池化层(Max-pooling Layer)构成,1×1卷积层提高了低维信息的通道数,与高维特征图融合时保证通道数一致;最大池化层将特征图的尺寸缩小了一半,与高维特征图大小保持一致。在以ResNet101为编码器的基础上,按一定形式添加多个跨层级调整模块,从而提高编码器的特征整合能力。编码器如图2中Encoder部分所示:单张RGB图像经过步长为2的7×7卷积以及批标准化(Batch Normalization,BN)层、线性整流函数(Rectified Linear Unit,ReLU)层与最大池化层,将特征图大小由304×228降为76×57,再发送至ResNet101残差块中,且从左往右依次是Block-i(i=1,2,3,4)输出端。在Block-1输出端,将特征图分别发送至Block-2及跨层级调整模块,经过跨层级调整模块调整通道数和降低特征图尺寸操作后,与Block-2输出端的输出相加,相加后的特征图分别发送至Block-3和跨层级调整模块中,接下来将跨层级调整模块输出与Block-3的输出相加并发送至Block-4中,经过Block-4编码后输出最终特征图。至此,完成一张图像的编码任务。
多层级融合的结构形式有很多种,图3、图4表示编码器的2种其他结构。图2采用了2个跨层级调整模块,分别应用在Block-1及Block-2输出端。在图3中,只保留了图2中Block-2输出端的一个跨层级调整模块。图4则在图2的基础上,在7×7卷积层输出端添加一个跨层级调整模块。下文将通过实验验证上述3种编码器结构的性能。

图3 编码器单层级融合结构Fig.3 Single layer level fusion structure of encoder

图4 编码器三层级融合结构Fig.4 Three layers level fusion structure of encoder
1.2 解码器结构
解码器对编码器输出的10×8@2 048多通道、低分辨特征图进行解码,逐步降低通道数、提高分辨率,最终得到160×128的单通道、高分辨率的深度估计图像。本文解码器由4个上投影(Up-projection)模块[11]构成,上投影模块结构如图5所示。该模块结构包含一个反池化(Un-pooling)操作、2个5×5卷积层与一个3×3卷积层的双路卷积结构,其中,反池化操作将图像放大一倍,双路卷积结构则对放大的图像进行调整。解码器如图2中Decoder部分所示:首先,编码器输出的特征图通过1×1卷积层调整通道数,从原来的2 048降至1 024;其次,将特征图依次输入4个上投影模块处理,接下来,对第2层、第3层上投影模块输出的特征图进行融合模块处理,并加权叠加到第4层上投影模块的输出上;最后,融合后的特征图经过一个3×3卷积输出单通道的深度预测图。其中,解码器第1层上投影的输出虚线S1并不能达到最优结果,因此最终网络结构中没有S1。

图5 上投影模块Fig.5 Up-projection module
1.3 解码器多层级融合模块
解码器的多层级融合思想主要来源于FPN网络结构[20],FPN通过构建特征图金字塔,融合多种分辨率下的特征,以提高获取更高级别图像语义的能力。在本文解码器中,上投影模块输出的特征图可看作是多分辨率下的特征,因此采用多层级融合结构融合多分辨率特征,以提升网络性能。
由于高维特征图的感受野较大,学习到的是局部特征组合而成的更加宏观、抽象的结构信息特征,而低维特征图的感受野较小,学习到的是图像的细节信息和局部特征。因此,将高维特征图中的空间信息与低维特征图的细节信息和局部特征相结合,通过优势互补,可以提高预测图像的质量。
解码器多层级融合模块结构如图6所示,第2层、第3层上投影模块的输出分别为S2、S3。其中,S3经过上采样、3×3卷积处理,再经过超参数λ1加权后,与S2经上采样、超参数λ2加权结果相叠加后输出。融合模块的目的是将感受野更大的S2和S3叠加至感受野较小的S4上,由于S3相对S2感受野小,因此在融合模块中对S3增加一个3×3卷积进行调整。如果融合模块的输出Sf与主干输出S4直接相加,Sf会干扰预测深度图的精度,因此本文使用2个较小的超参数λ1和λ2对S3和S2削弱,降低融合模块输出数据对主干数据的影响。

图6 解码器融合模块Fig.6 Fusion module of decoder
1.4 损失函数
选用L1范数作为网络结构的损失函数,用以约束标签与预测图像之间对应像素的差异来监督训练。L1范数定义如式(1)所示:
(1)
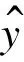
2 实验与结果分析
2.1 网络参数配置
本文实验在Ubuntu-16.04上完成,内存大小为16 GB,显卡使用NVIDIA Titan Xp,深度学习框架采用Pytorch-0.4.0。在训练过程中,编码器ResNet101的初始化采用在ImageNet图像分类任务获得的预训练模型,网络优化器采用SGD,动量(Momentum)设置为0.9,学习率初始设置为0.4,随着训练步数不断衰减,λ1和λ2超参数均设定为0.1。实验过程中采用边训练边测试的模式,大约经过40个Epoch后,网络才达到收敛状态,并选取测试最佳模型为最终结果。
2.2 评价指标
目前,预测深度图相关研究在评估预测深度图质量时,常采用平均相对误差(Average Relative Error,ARE)、对数平均误差(Logarithmic Mean Error,LME)、均方根误差(Root Mean Square Error,RMSE)与阈值准确率(Threshold Accuracy,TA)4种评价指标进行评价,其计算方法分别如式(2)~式(5)所示:
(2)
(3)
(4)
(5)
其中,y*为真实深度值,y为预测深度值,式(5)中的thr=1.25,1.252,1.253。在深度图质量评价指标中,δ1<1.25是评价深度信息准确度最重要的指标,其反映整个深度图中深度准确像素的占比。
2.3 数据集与预处理
基于深度学习预测深度图任务可采用的数据集包括有NYUv2[21]、KITTI[22]、Make3D、Places365与SUNCG等。目前,室内预测深度图多采用NYUv2数据集,室外预测深度图多采用KITTI数据集。NYUv2数据集包括3个城市的464个室内场景,总共有408 473张RGB-D图像对,数据集由Kinect采集生成,RGB图像分辨率为480×640×3,Depth图像分辨率为480×640。官方在464个场景中选取249个场景用于训练,其余215个场景用于测试。本文对数据集的划分和测试方式,与表1中列出的文献相同,在249个场景中等间隔抽取图像对来构建训练数据集,总共有47 584个未精标图像对;同样,在215个测试场景中选取654个精标图像对构建测试数据集。KITTI数据集通过激光雷达、光学镜头与摄像机等硬件设备采集了市区、乡村、高速公路与校园等总共61个室外场景。RGB图像分辨率为375×1 242×3,Depth图像分辨率为228×912。在KITTI数据集的选择上,本文从32个场景中取得46 413个图像对构建训练集,在29个场景中选取697个图像对构建测试集。
在数据预处理过程中,NYUv2和KITTI数据集改变图像大小后再发送至网络结构,并对RGB-Depth图像对进行随机旋转、水平反转等操作,以扩大数据集。
2.4 实验结果与对比
为了验证本文方法提出网络结构的有效性,分别在NYUv2和KITTI数据集上进行训练与测试,为保证对比的公平性,实验将深度距离上限设置为80 m,并将得到的实验结果与文献[9,11,13]、文献[23-25]、文献[26-28]方法进行对比,具体如表1、表2所示。其中,最优结果加粗表示。

表1 本文网络与先进网络在NUYv2数据集上的实验结果对比Table 1 Comparison of experimental results between the proposed network and advanced network on NUYv2 dataset

表2 本文网络与先进网络在KITTI数据集上的实验结果对比Table 2 Comparison of experimental results between the proposed network and advanced network on KITTI dataset
从表1可以看出:相比其他网络,本文网络在6个评价指标中,有4个指标结果最优,且最重要的δ1参数有较大提升;与文献[25]网络相比,本文网络的δ1提高了1.849%,RMSE降低了14.1%;与文献[24]网络相比,本文网络预测深度图的δ1提高了2.86%,RMSE降低了6.67%,这说明本文所提网络在NYUv2数据集上表现更佳。
从表2可以看出:与其他4种先进网络相比,本文网络在6种评价指标中,有4个指标结果最优,且最重要的δ1参数有较大提升;本文网络预测深度图的δ1为0.864,与文献[27]网络相比,本文网络的δ1提高了6.6%,RMSE降低了4.3%;与文献[28]网络相比,本文网络的δ1提高了5.6%,这说明本文所提网络在KITTI数据集上也具有优势。
2.5 网络测试时间对比
图7表示本文网络与其他4种先进网络的测试时间与均方根误差(RMSE)结果对比。实验选用NYUv2数据集,文献[11]采用编解码结构的网络,文献[25,29]提出基于条件随机场的神经网络。从图7可以看出,本文网络在取得最低误差的同时,单张图像处理时间也最短;本文网络的计算时间远低于文献[25,29]网络,且相比文献[28]提出的结构注意力引导网络,其测试时间降低了41.6%。因此,与其他先进网络相比,本文提出的多层级特征融合结构的单目图像深度估计网络具有更高的准确率和计算效率。

图7 本文网络与先进网络的测试时间与RMSE对比Fig.7 Comparison of test time and RMSE between theproposed network and advanced network
2.6 深度图的主观对比
实验将真实深度、文献[11]预测图与本文预测图进行比较,如图8所示。从图8可以看出,在第一行走廊图像中,文献[11]预测图中黑色虚线标记框处并未显示房梁部分,然而本文预测图在相同位置有与真实深度相同的房梁部分;在第二行书架图像中,柜子的左边有白色的门,本文预测图黑色虚线标记框处表明了门的深度信息,然而文献[11]预测图丢失了部分深度信息,同时,本文预测图中的柜子边缘清晰可见;在第三行客厅图像中,本文和文献[11]预测图均可以预测出客厅中桌子的深度,但是文献[11]没有得到图像左下角沙发的深度信息,而本文预测图在左下角的相对应位置上估计出沙发的深度信息。通过对比可以看出,本文预测图的深度信息更加完整、准确,同时还保持了图像的细节信息。

图8 文献[11]与本文预测深度图对比Fig.8 Comparison of the predicted depth maps byreference[11] and this paper
3 网络结构测试
本节通过对比网络结构中模块的不同形式来说明本文网络结构性能最佳。其中,实验过程中的数据集均采用NYUv2数据集,且数据划分、数据预处理及网络参数配置与上文相同。
3.1 多层级融合结构测试
为了验证本文提出的多层级融合结构对网络性能的提升,实验对以下4种结构进行对比:第1种是基本编-解码结构,没有跨层级的融合;第2种仅在编码器中增加多层级融合;第3种是仅在解码器中增加多层级融合结构;第4种是编-解码器两者都加入多层级融合,结果如表3所示。其中,最优结果加粗表示。从表3可以看出:当同时采用2种融合结构时,有5个评价指标结果达到最优,这说明了本文提出的多层级融合结构对深度预测任务有效;此外,仅对编码器添加多层级融合结构时,网络性能也得到了提升;仅当在解码器添加多层级融合结构时,网络性能反而下降,这可能是由于编码器与解码器的能力不匹配而导致的结果。

表3 多层级融合结构性能对比Table 3 Performance comparison of multiple level fusion structures
3.2 编码器多层级融合结构测试
多层级融合的结构形式有很多种,本文对多种结构和调整模块进行对比分析,表4列举了编码器中具有代表性的3种结构,分别为图2中的双层级结构、图3中的单层级结构和图4中的三层级结构。其中,最优结果加粗表示。在实验过程中,编码器的多层级融合结构会发生变化,而网络结构的其他部分仍保持不变。从表4可以看出,双层级结构的性能最优,这说明融合的层级并不是越多越好,过多的层级会干扰高维特征图的输出,而过低的层级不能保证有效信息的导入。因此,双层级结构可以在低维干扰和信息导入之间达到平衡状态。

表4 编码器跨层级结构性能对比Table 4 Performance comparison of encodersacross hierarchies
3.3 解码器上投影模块测试
上投影模块的结构有很多种,本文列举了4种典型结构进行对比,如图9所示。其中,图9(a)是本文采用的上投影结构,图9(b)中2个5×5卷积核均采用空洞卷积的方法来增加感受野,其膨胀率为1,图9(c)增添了一条跳跃连接,期望获取更多的局部特征和细节信息,图9(d)用Inception-v1替代双路卷积部分,用以简化计算量。
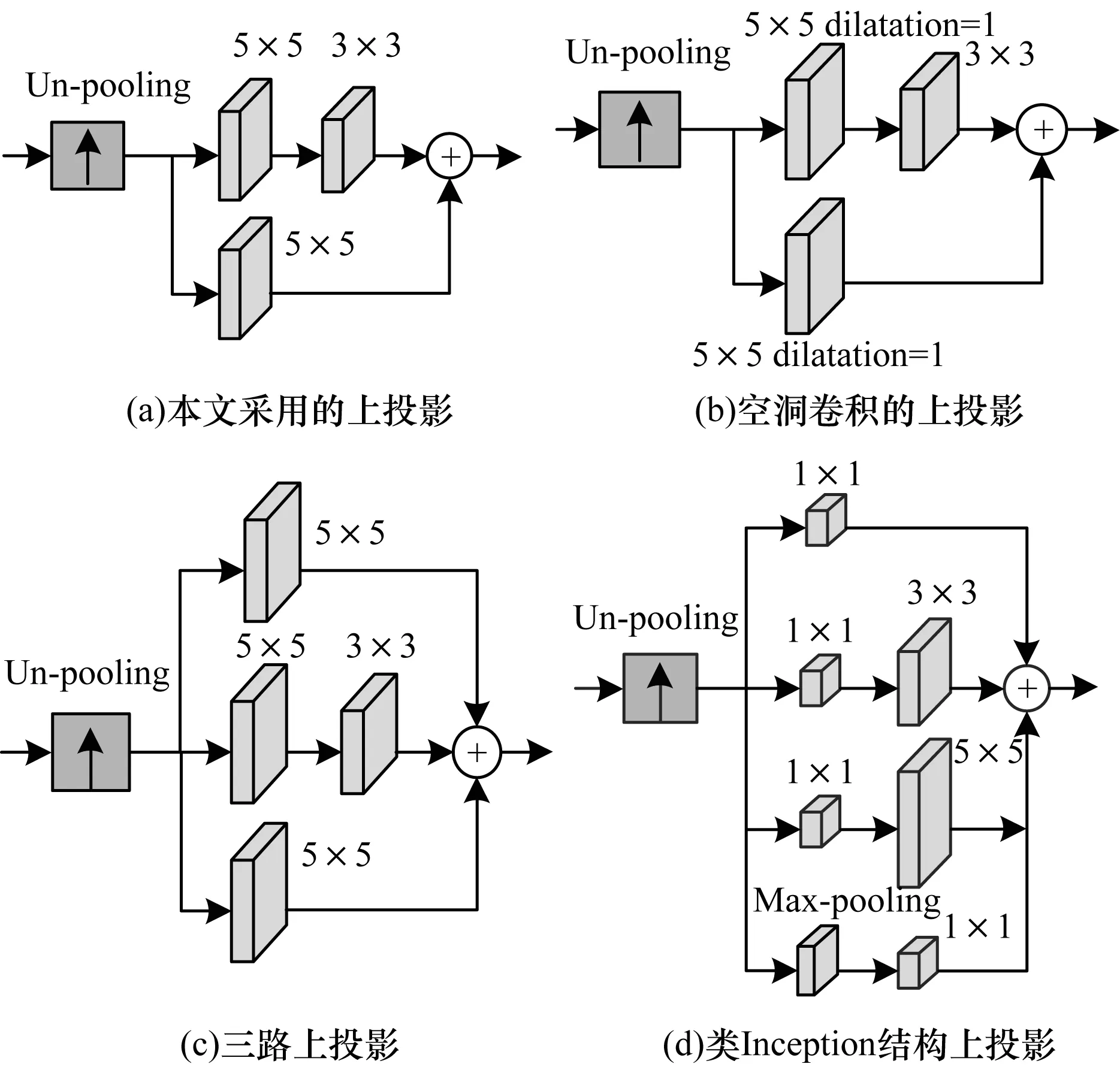
图9 不同结构的上投影模块Fig.9 Up-projection modules of different structures
在实验过程中,只有解码器中上投影模块结构发生了变化,网络结构的其他部分仍保持不变。解码器上不同结构的上投影模块对比如表5所示。其中,最优结果加粗表示。从表5可以看出:图9(a)模块结构性能最佳;图9(b)模块结构虽然增加了感受野,但是忽略了周围紧邻的信息影响;图9(c)模块结构中增加了5×5通道数期望获取更多的图像特征,反而造成数据冗余;图9(d)模块结构中采用Inception-v1结构降低参数量,但是参数量的减少造成了恢复性能降低。
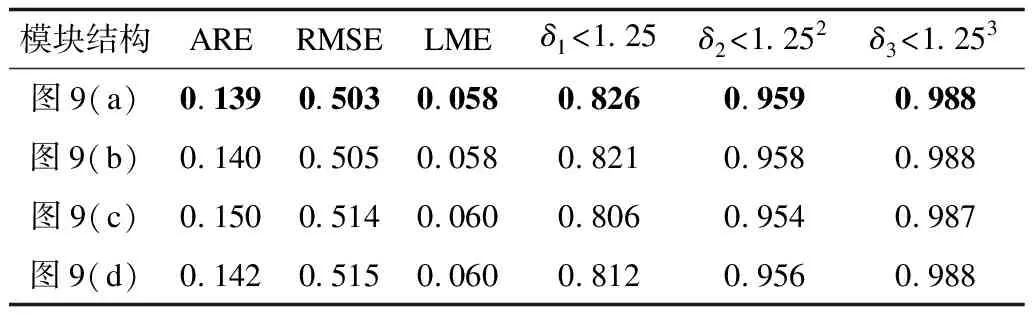
表5 解码器中上投影模块结构对比Table 5 Comparison of up-projection model structuresin decoder
本文通过实验验证上投影模块中的上采样算法,结果表明,亚像素卷积[30]的效果优于反池化、双线性插值及反卷积等算法,因此本文采用亚像素卷积。
3.4 解码器多层级融合结构测试
如图10所示:单层融合结构仅将S3输入到融合模块中,中间经过上采样与3×3卷积操作,之后再经过超参数加权操作;双层结构将S2、S3同时输入到融合模块中,S3与单层融合模块操作相同,S2仅经过上采样和超参数加权操作;三层结构将S1、S2、S3同时输入到融合模块,S2、S3输入与双层融合模块操作相同,S1仅经过上采样和超参数加权操作。在实验过程中,只有解码器的多层级融合模块结构发生改变,而网络结构的其他部分保持不变。

图10 解码器的不同层级融合Fig.10 Different levels fusion of decoder
与编码器结构分析类似,实验分别对单层、双层和三层融合结构进行对比,结果如表6所示,其中,最优结果加粗表示。从表6可以看出:S1、S2与S3同时存在时,δ1指标反而下降,高维信息中的空间信息未经过充分解码,还处于一个抽象状态,如果将高维信息与低维信息在融合模块中融合,反而干扰了预测的精准度,因此最终网络结构中不包含S1;当S3单独存在时,其δ1指标明显提高,可见调整后有利于优化预测图像,但是其缺少相对应的空间关系,因此其结果不能达到与S2、S3同时存在时的效果。
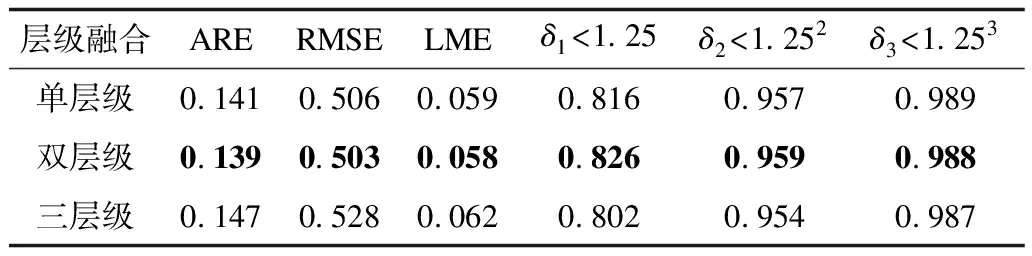
表6 解码器中融合模块对比 Table 6 Comparison of fusion module in decoder
4 结束语
针对单目图像预测深度图任务中存在的信息不精确、细节缺失等问题,本文提出多层级特征融合结构的单目图像深度估计网络。通过对编码器ResNet101与解码器进行多层级特征融合,提高其特征整合能力,并在NYUv2数据集和KITTI数据集上进行对比实验。实验结果表明,在相同的测试环境和评价指标下,该网络在单目深度估计任务中性能最佳,不仅能够提高预测深度图的精度,而且还保留了细节信息。虽然本文网络结构在现有评价指标上得到了提升,但是预测图像边缘仍呈模糊状态,不符合人类的直观感受。因此,下一步将结构相似度参数与图像梯度相结合作为深度图像评价指标,利用该指标评判预测深度图像的优劣,以改善预测深度图像边缘较为模糊的现状。
