异构无线传感器网络中继节点部署算法
2020-12-16马千里申朝晖
马千里,袁 易,申朝晖
(1.山西大学 计算机与信息技术学院,太原 030006; 2.太原欧亚科技发展有限公司,太原 030006)
0 概述
无线传感器网络(Wireless Sensor Networks,WSNs)由近千个传感器节点组成,每个传感器节点由电池提供能量,传感器节点通常部署于环境恶劣的地方,这导致节点可能发生失效,从而影响整个网络的连通质量[1]。针对该问题,在传感器节点网络中引入中继节点,传感器节点不再直接将信息发送给彼此,而是先发送给中继节点,然后中继节点再将信息发送给其他传感器节点,进而实现网络信息的传递。这与引入actor节点使网络连通的无线传感器和执行器网络(Wireless Sensor and Actor Networks,WSANs)工作原理类似[2]。actor节点可移动且较sensor节点通信性能更好,若传感器节点因意外或者电量耗尽而失效,actor节点可代替失效节点工作,并能较好地适应网络的随机变化。根据相关部署策略引入中继节点的部署方案,实质上与在异构网络中增加具有较高通信性能的actor节点类似。
LIN等人[3]最早在WSNs中添加中继节点,将同构网络中加入最少中继节点的问题命名为最少数目斯坦纳点和有界边长的斯坦纳树问题(Steiner Tree Problem with Minimum Number of Steiner Points and Bounded Edge Length,STP-MSPBEL)并证明其为NP难问题,在此基础上,提出基于图增量的中继节点部署GA-RD算法。文献[4]对GA-RD算法进行改进,提出基于权重图的IWGA-RD算法,并证明该算法具有更好的近似比。算法的近似比和近似解反映了算法优化程度,在改进算法部署时其可作为衡量算法能否减少节点数量和提高网络性能的参考指标。
目前,WSNs中继节点数据传输包括自主收集、接收信息、携带信息后再发送等环节,使全网数据吞吐量与传输量大幅提升。为满足传感器网络数据吞吐量和传输量的要求,网络部署规模庞大且节点众多而密集,在节点收发信息的瞬时易造成网络拥塞,甚至导致网络瘫痪。因此,减少传感器网络中继节点数量至关重要。本文在IWGA-RD算法的基础上进行改进,提出一种基于节点权重与边长的LWGA算法,通过对节点权重和边长的排序改进中继节点加入网络的优先级次序,以选择传感器网络中节点数量更少的中继节点部署方式。
1 研究现状
无线传感器网络作为一种重要的网络技术,将信息世界与人们日常生活紧密联系在一起,实现了两者之间的交互。WSNs以数据为中心,其中传感器节点由感知、数据处理及存储、通信、供能单元构成[5-6]。WSNs技术与其应用场景关联密切,不同场景的应用技术有较大差别。WSNs因其大规模、自组织、高可靠性等特点被广泛应用于军事、医疗、环境等领域,但是由于其存在节点能量易耗尽造成网络中断、存储空间有限等缺点,因此研究人员将精力集中在WSNs有利特性的研究[7-9]上。目前关于WSNs的研究方向为传感器的网络连通、网络节能[10-11]以及网络覆盖[12-14]等方面,本文主要研究传感器网络环境下中继节点部署的网络连通问题。
研究人员从上世纪末就开始对在网络中添加中继节点进行研究。文献[3]所提STP-MSPBEL方案中最小Steiner树[15]和最小生成树问题类似,都是最短网络的一种解决方案,但两者区别在于,最小生成树网络是在给定的点集和边中寻求最短网络使网络连通,而最小Steiner树网络允许在给定的点之外增加额外点使网络连通[16]。
本文主要研究基于Steiner树的网络。在文献[3]的基础上,研究人员对这类问题进行改进和优化。文献[17]基于文献[3]重新推导算法的近似比,证明该算法的近似比为4。文献[18]提出一种使网络达到k-连通的中继节点部署算法。文献[19]证明使网络达到连通加入最少异构中继节点的问题仍为NP难问题,并对文献[3]所提中继节点部署算法的近似比重新推导得到近似比为7。文献[20]基于文献[19]提出结合约束部署区域的思想新算法,将近似比降低到2。上述算法均基于网络中节点为同构这一假设,即要求加入的中继节点与已有节点具有相同的通信性能。而实际上无线传感器网络存在多种异构情况,例如XBeeS2与XBeeS2Pro射频模块均为ZigBee路由器的主要组成部分,其采用相同的协议栈,彼此之间可通信并组建网络。然而XBeeS2射频功率仅为2 mW,室外通信距离为120 m,XBeeS2Pro射频功率为63 mW,室外通信距离长达3 200 m,其价格是XBeeS2的3倍以上。文献[4]将网络节点的通信性能进行区分,在网络中加入中继节点使网络连通,并通过减少后加入的中继节点数量降低网络能耗以节省网络成本。文献[21-22]研究由中继节点和传感器节点组成的异构网络,在该网络中加入新中继节点,从而由负载平衡和能量有效等方面优化网络性能。无线传感器网络中异构与同构的最大区别在于传感器节点之间的通信性能[23],因此同种算法在这2种网络中有明显差异,且相关算法都需运用到图增量。考虑到同构场景的局限性,本文针对异构场景下的节点部署问题展开研究。
2 网络模型与问题描述
文献[4]将sensor节点按照通信性能进行区分:普通sensor节点为低性能节点,命名为S1;将高通信性能的sensor节点命名为S2,且S2的通信半径大于S1,即RS2>RS1。2个节点之间通信半径由其中通信半径小的节点决定,如图1所示(dist(S1,S2)代表S1和S2之间的欧式距离,三角形和圆形代表通信半径不同的传感器节点)。
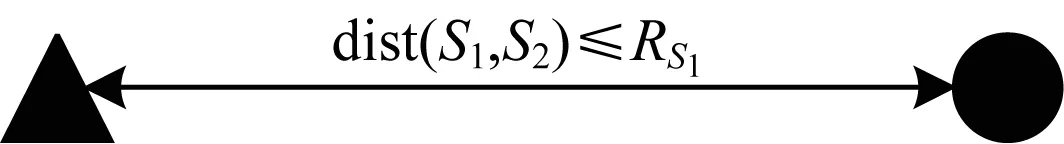
图1 2个节点之间的通信半径示意图
Fig.1 Schematic diagram of communication radius between
two nodes
根据上述对不同节点通信半径的分析,本文在WSNs中部署中继节点(WSN-RELAY)以实现网络连通性,并对其进行形式化定义。
定义1在二维平面里,给定无向图G=
E={e(i,j) | dist(i,j)≤RS2,i∈SS1& &j∈SS2}∪
{e(i,j) | dist(i,j)≤RS1,i∈SS1‖j∈SS2}
(1)
新添加的边和节点构成G=
1)GA-RD算法
GA-RD算法的主要思想是通过向森林T加入n-1个边使T变成1棵树,从而实现整个网络的连通[4]。输入G=
2)IWGA-RD算法
IWGA-RD算法是先计算出各边的权重,并将其按升序排列形成队列Q。与GA-RD算法类似,IWGA-RD算法采用最小生成树算法求解图增量问题,再将Q中的元素利用迭代法依次加入森林T中,在e(i,j)为0的边加入中继节点使网络连通,最后去掉多余的中继节点。
以下介绍本文所提LWGA算法中边的权重计算方法。由于S1与S2的通信性能不同,在2个sensor节点之间加入中继节点时,会考虑到该因素。假设S2的通信性能与中继节点近似,则权重的计算存在以下3种情况:
1)当2个sensor节点(设为i,j)均为S1时,所需中继节点数量与2个节点之间的距离dist(i,j)和S1的通信半径RS1有关。当dist(i,j)≤RS1时,i与j均在对方的通信范围内,无需加入中继节点,网络本身为连通状态;当dist(i,j)在RS1和2RS1之间时(见图2),需加入1个中继节点,该中继节点同时在2个节点的通信范围内,使得网络连通;当dist(i,j)>2RS1时(见图3),在2个sensor节点各自通信范围的最远处(2个节点通信范围以外)分别加入1个中继节点,计算该距离为dist(i,j)-2RS1,在此距离范围内需部署中继节点使得网络连通,2个节点之间的权重计算公式如式(2)所示。

图2 dist(i,j)∈(RS1,2RS1)示意图Fig.2 Schematic diagram of dist(i,j)∈(RS1,2RS1)

图3 dist(i,j)∈(2RS1,+∞)示意图 Fig.3 Schematic diagram of dist(i,j)∈(2RS1,+∞)
(2)
2)当2个sensor节点分别为S1和S2时,在S1通信范围最远处部署1个中继节点,将该中继节点视为S2,其余节点的部署与2个S2节点之间的距离有关(见图4),2个节点之间的权重计算公式如式(3)所示。

图4 2节点分别为S1和S2时权重分布示意图Fig.4 Schematic diagram of weight distribution whenthe two nodes are S1 and S2 respectively

(3)
3)当2个sensor节点均为S2时,其通信性能与加入的中继节点接近,其约束半径均为RS2,2个节点之间需部署的中继节点数量仅与其间隔的距离有关,2个节点之间的权重计算公式如式(4)所示。
(4)
2个节点之间的权重w(e(i,j))与这2个节点之间连通所需的中继节点数量有关,根据以上3种情况,可得出定义2。
定义2假设i、j均为sensor节点,SS1为S1节点的集合,SS2为S2节点的集合。当i,j∈SS1时,2个节点之间的权重如式(2)所示;当i∈SS1、j∈SS2时,2个节点之间的权重如式(3)所示;当i,j∈SS2时,2个节点之间的权重如式(4)所示。
3 算法描述
根据上述权重计算方法,本文对传统IWGA-RD算法进行改进,提出一种基于权重及边长的LWGA算法。
算法1LWGA算法
输入图G=
输出Srelay(中继节点集合)
1.设n=|V|且E’=V×V-E
2.定义1个空的森林T
3.计算各边权重和边长,并初始化1个权重和边长升序(按权重排序,若权重相同,则按边长排序)的队列Q,其包含E’中所有元素
4.WHILE T中包含少于n-1个边,DO
5.IF边集E不等于空集
6.取E中任意元素e(i,j),并将其从E中清除
7.IF T中加元素e(i,j)后未出现回路
8.在T中加入元素e(i,j)
9.ELSE
10.取Q(Q中元素为升序排列)中第1个元素e(i,j),将其从Q中清除
11.IF T中加入元素e(i,j)后未出现回路且w(e(i,j))和dist(i,j)均不为零
12.将e(i,j)加入T,并在i、j之间部署中继节点
13.END DO
LWGA算法先通过式(1)~式(3)计算出G中各边的权重,再按权重升序排序,并将权重相同的边按边长升序排序,得到最终排序。LWGA算法的第11行中采用最小生成树算法求解权重图增量问题,然后找出Q中最小权重和边长的边加入森林T,若待加入边的权重或边长大于零,则表示该边需加入中继节点使其连通。
定理1LWGA算法在[0,w(Ek+1)]区间收敛。
证明LWGA算法在[0,w(Ek+1)]区间收敛证明如下:
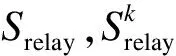

w(e(i,j))+w(e(r,j))
(5)
当部署第k+1个节点时,对应的最小权重及边长生成树为LWT(Ik+1,Ek+1)。连通Ik+1的1棵树为Ek+e(i,r)+e(r,j)-e(i,j),则有:
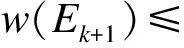
w(e(r,j))
(6)
由上述可知,每部署1个中继节点,LWT上的权重之和就减1,当部署k个中继节点时,LWT(Ik,Ek)的权重必然为定值,因此,LWGA算法在[0,w(Ek+1)]区间收敛,证毕。
设klwga=|Srelay|、kiwga=|Slwga|,在未部署节点前存在∑w(I0)=kiwga,其中,kiwga为采用IWGA-RD算法得到的中继节点数量。与IWGA-RD算法相比,由于LWGA算法在权重相同的情况下按边长依次升序排列,在增加节点时多了1个更优的筛选条件,因此其每部署1个新中继节点,在生成树边长相同的情况下权重之和就比IWGA-RD算法减少1,最终所得权重之和∑w(In)必然小于kiwga,由此可知LWGA算法部署的中继节点数量不超过IWGA-RD算法,从而得出结论:LWGA算法的近似解小于IWGA-RD算法,即klwga≤kiwga,说明采用LWGA算法部署的中继节点更少。
4 实验结果与分析
为验证采用LWGA算法部署传感器网络时所需中继节点数量的情况,本文使用MATLAB软件进行仿真实验。将低通信性能节点S1的半径RS1固定为30 m,可变参数为低通信性能节点S1的数量(NS1)、高通信性能节点S2的数量(NS2)及半径。图5为某次部署节点前后的节点随机拓扑情况,区域中已有方形节点为随机部署。图5(a)为部署节点前的节点随机拓扑情况(有10个高性能节点、100个低性能节点),其中节点位置、节点之间是否连通均为随机;图5(b)为部署节点后的节点随机拓扑情况,圆形节点为后加入的中继节点。

图5 部署节点前后的节点随机拓扑情况Fig.5 Random topology of nodes before andafter node deployment
4.1 小规模仿真实验
以300 m×300 m正方形区域作为实验区域,通过调整可变参数大小,观测所需中继节点的数量,取100次随机观测结果的平均值作为实验结果,并将LWGA算法得到的结果与GA-RD、IWGA-RD算法进行对比,实验参数设置如表1所示,其中“—”代表自变量。

表1 小规模仿真实验参数设置Table 1 Parameter setting of small scale simulationexperiment
在实验区域随机部署100个低通信性能节点S1及10个高通信性能节点S2,在改变S2通信半径RS2的情况下,对比GA-RD、IWGA-RD及LWGA算法所需中继节点的数量,结果如图6所示(1号实验)。可以看出:当RS2为30 m时,GA-RD算法与IWGA-RD算法所需中继节点数量相同,LWGA算法所需中继节点数量最少;当RS2为30 m~50 m时,GA-RD算法所需中继节点数量略有下降,LWGA算法和IWGA-RD算法所需中继节点数量降幅明显;当RS2大于50 m时,GA-RD算法所需中继节点数量几乎不变,LWGA算法和IWGA-RD算法所需中继节点数量保持下降;当RS2为50 m~130 m时,IWGA-RD算法所需中继节点数量较GA-RD算法减少约25%,而LWGA算法所需中继节点数量较IWGA-RD算法减少约30%,故LWGA算法的性能优于另外2种算法;当RS2大于90 m时,IWGA-RD、LWGA与GA-RD算法所需中继节点数量保持上述趋势且差距更明显。

图6 S2通信半径与中继节点数量关系曲线1Fig.6 Relationship curve 1 between the communicationradius of S2 and the number of relay nodes
在实验区域部署150个低通信性能节点S1,将高通信性能节点S2半径设置为60 m,在改变S2数量的情况下,对比GA-RD、IWGA-RD及LWGA算法在解决WSN-RELAY问题时所需中继节点的数量,结果如图7所示(2号实验)。可以看出:当S2数量小于5时,GA-RD、IWGA-RD算法所需中继节点数量接近,LWGA算法较这2种算法所需中继节点数量减少约25%;当S2数量大于5时,GA-RD算法所需中继节点数量先不变再下降,IWGA-RD、LWGA算法所需中继节点数量均逐渐减少,且LWGA算法所需中继节点数量较IWGA-RD算法减少约30%;当S2数量为20~25时,LWGA算法所需中继节点数量仍低于IWGA-RD算法且趋于恒定。因此,当S2数量为0~25时,LWGA算法所需中继节点数量较GA-RD、IWGA-RD算法更少,LWGA算法性能更优。

图7 S2数量与中继节点数量关系曲线1Fig.7 Relationship curve 1 between the number ofS2 and relay nodes
在实验区域部署10个高通信性能节点S2,将中继节点和S2的通信半径RS2设置为60 m,通过改变低性能节点S1的数量,观测GA-RD、IWGA-RD及LWGA算法在解决WSN-RELAY问题时所需中继节点的数量,结果如图8所示(3号实验)。可以看出:当S1数量为80时,3种算法所需中继节点数量大致相同;随着S1数量的增加,3种算法所需中继节点数量均出现下降,IWGA-RD算法所需中继节点数量较GA-RD算法减少约10%,LWGA算法所需中继节点数量较IWGA-RD算法减少约20%;当S1数量为180时,3种算法所需中继节点数量几乎相同。因此,当S1数量为80~180时,LWGA算法较GA-RD、IWGA-RD算法性能更优。

图8 S1数量与中继节点数量关系曲线1Fig.8 Relationship curve 1 between the number ofS1 and relay nodes
4.2 大规模仿真实验
以1 000 m×1 000 m正方形区域作为实验区域,通过调整可变参数大小,观测所需中继节点的数量,取100次随机观测结果的平均值作为实验结果,并将LWGA算法得到的结果与GA-RD、IWGA-RD算法进行对比,实验参数设置如表2所示,其中“—”代表自变量。

表2 大规模仿真实验参数设置Table 2 Parameter setting of big scale simulationexperiment
在实验区域随机部署200个低通信性能节点S1及20个高通信性能节点S2,由于中继节点半径仅为实验区域边长的6%,因此大规模实验环境下需部署更多中继节点。在改变S2通信半径RS2的情况下,对比GA-RD、IWGA-RD及LWGA算法所需中继节点的数量,结果如图9所示(4号实验)。可以看出:当RS2不断增加时,3种算法所需中继节点数量均出现下降;当RS2为60 m~120 m时,3种算法所需中继节点数量降幅较大;当RS2大于120 m时,3种算法所需中继节点数量降幅趋于平缓;当RS2相同时,IWGA-RD算法所需中继节点数量较GA-RD算法减少约10%,LWGA算法所需中继节点数量较IWGA-RD算法减少约10%。因此,LWGA算法性能要优于IWGA-RD、GA-RD算法。
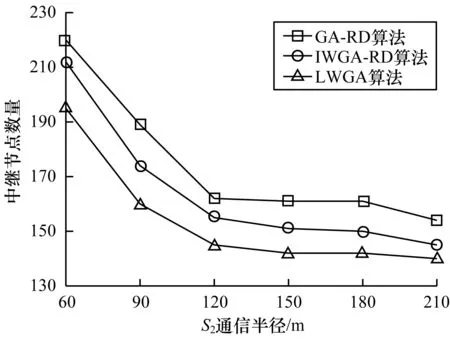
图9 S2通信半径与中继节点数量关系曲线2Fig.9 Relationship curve 2 between the communicationradius of S2 and the number of relay nodes
在实验区域部署200个低通信性能节点S1,将高通信性能节点S2半径设置为60 m,在改变S2数量的情况下,对比GA-RD、IWGA-RD及LWGA算法在解决WSN-RELAY问题时所需中继节点的数量,结果如图10所示(5号实验)。可以看出:随着S2数量的增加,3种算法所需中继节点数量都出现下降且降幅较小;当S2数量达到60时,IWGA-RD、LWGA算法所需中继节点数量接近;当S2数量为20~60时,IWGA-RD算法所需中继节点数量较GA-RD算法减少约15%,LWGA算法所需中继节点数量较IWGA-RD算法减少约10%。

图10 S2数量与中继节点数量关系曲线2Fig.10 Relationship curve 2 between the number ofS2 and relay nodes
在实验区域部署20个高通信性能节点S2,将中继节点和S2的通信半径RS2设置为60 m,通过改变低性能节点S1的数量,观测GA-RD、IWGA-RD及LWGA算法在解决WSN-RELAY问题时所需中继节点的数量,结果如图11所示(6号实验)。可以看出:随着S1数量增加,3种算法所需中继节点数量出现递增,IWGA-RD算法所需中继节点数量较GA-RD算法减少5%~10%,LWGA算法所需节点数量较IWGA-RD算法减少5%~10%,LWGA算法性能最优。由于节点半径与实验区域边长相差较大,因此造成上述实验结果与小规模环境下的变化规律有差异。
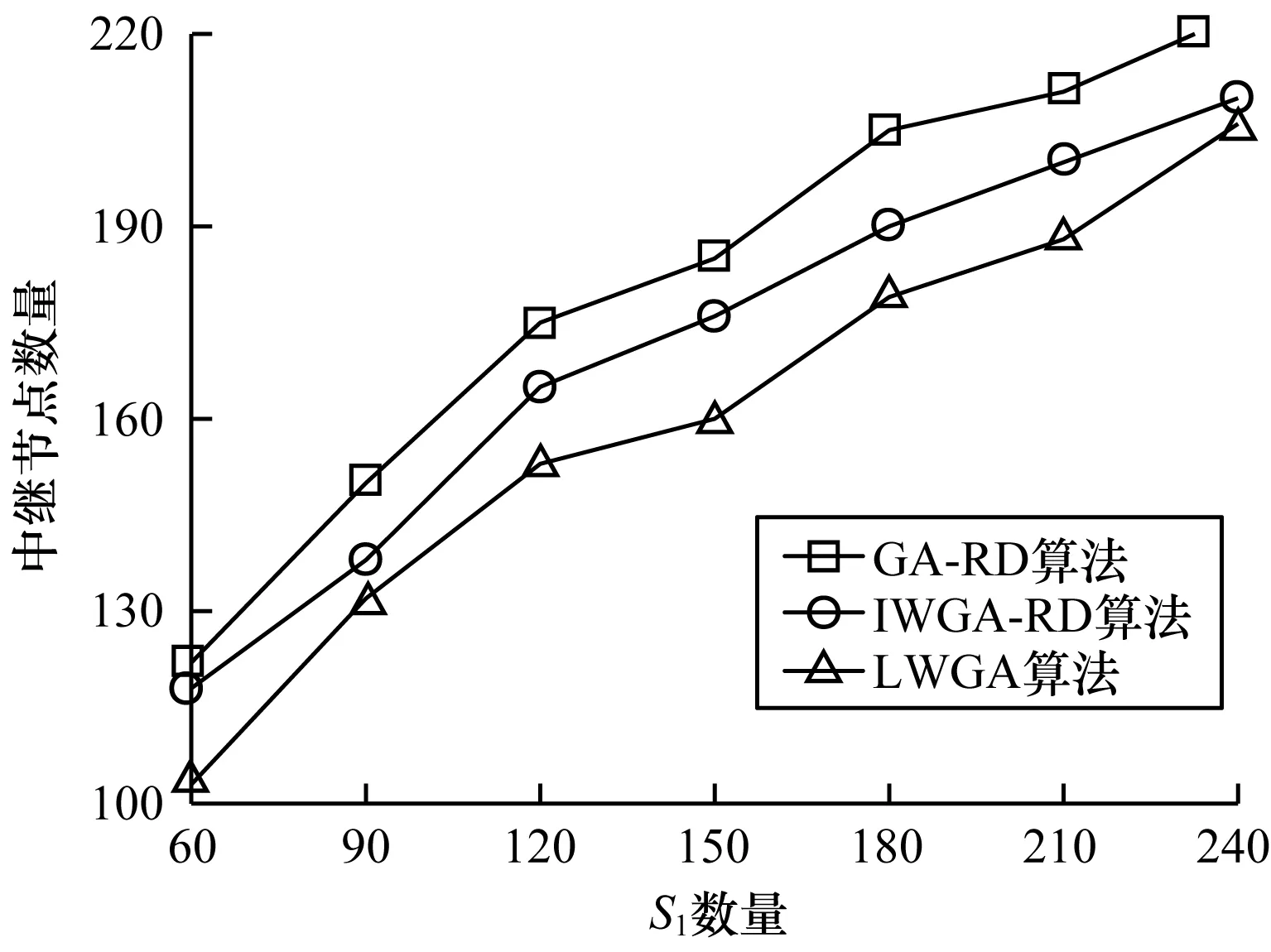
图11 S1数量与中继节点数量关系曲线2Fig.11 Relationship curve 2 between the number ofS1 and relay nodes
4.3 假设检验与实验结论
4.3.1 假设检验
由于IWGA-RD算法基于GA-RD算法改进得到,因此只需验证LWGA算法优于IWGA-RD算法,即可得证其优于GA-RD算法。为从统计学角度更好地说明LWGA算法的优异性能,以下通过假设检验[24]来验证LWGA算法与IWGA-RD算法之间的显著差异,从而证明本文实验结果的可靠性。
设H0表示LWGA算法与IWGA-RD算法在不同条件下所需中继节点数量无显著差异,H1表示LWGA算法与IWGA-RD算法在不同条件下所需中继节点数量有显著差异(H0:原假设,H1:备择假设)。将统计量设置为不同条件下IWGA-RD、LWGA算法再次分别进行100次随机实验所需中继节点数量,显著水平α设置为0.05,实验样本出现的概率记为p。假设检验的原理是根据实验样本统计量的大小及其分布确定检验假设成立可能性概率p的大小并进行判断:若p>α,说明α所取水准不显著,在H0条件下出现的数据样本不是小概率事件,H0假设正确,则拒绝H1假设,接受H0假设,即认为差别很可能是由抽样误差造成的,在统计上不成立;若p≤α,说明所取α水准显著,在H0条件下出现的数据样本是小概率事件,H0假设错误,则拒绝H0假设,接受H1假设,即认为此差别很可能是实验因素不同造成的,故在统计上成立。表3~表5为表1、表2中6组实验经假设检验所得p值。由表3可知,6组实验的p值均满足p<α,因此设立的备择假设H1成立,即:LWGA算法与IWGA-RD算法所需中继节点数量有显著差异,因此本文实验样本结果具有可靠性,在统计上成立。

表3 不同S2通信半径下实验1和实验4的p值Table 3 p values of Experiment 1 and Experiment 4under different communication radius of S2
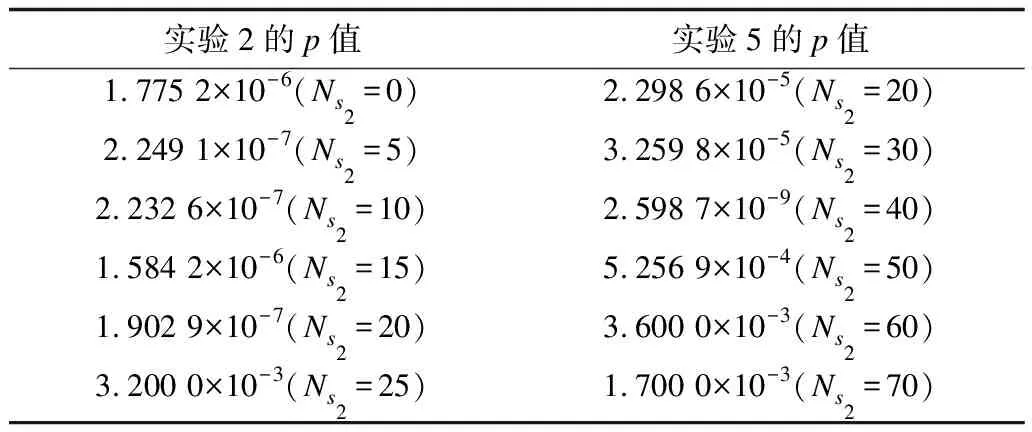
表4 不同S2数量下实验2和实验5的p值Table 4 p values of Experiment 2 and Experiment 5under different numbers of S2
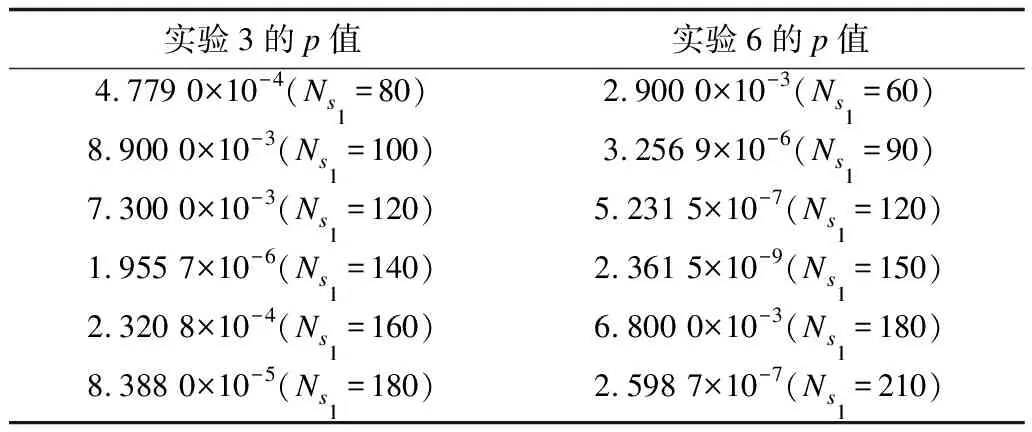
表5 不同S1数量下实验3和实验6的p值Table 5 p values of Experiment 3 and Experiment 6under different numbers of S1
4.3.2 实验结论
由上述实验结果可知,在相同的实验场景下,与GA-RD、IWGA-RD算法相比,LWGA算法可减少所需中继节点的数量,能有效降低网络负载与部署成本,具有更好的网络性能。由实验结果分析可知,在某些条件固定的情况下,LWGA算法在自变量改变的部分区间内呈现出一定优势,但超过临界值后,3种算法的性能接近。根据文献[25]对节点负载数据的相关分析,当自变量为节点数量时,在实验区域内部署节点数量越大,各节点承担的数据包越多,当低性能节点数量增加时,整个网络负载随之升高,因此3种算法性能在某些条件下近似。当改变性能节点通信半径和高性能节点数量后,3种算法的实验结果差异趋于明显,这是因为高通信性能节点的通信半径与中继节点接近,是低性能节点通信半径的2倍甚至更多,改变其相关参数对整个网络影响较大,因此LWGA算法在节省中继节点数量上的效果也更显著。综上所述,LWGA算法优于GA-RD、IWGA-RD算法,可得到更好的网络性能。
5 结束语
为了用尽量少的中继节点解决WSNs网络拥塞问题,本文提出一种基于权重及边长的中继节点部署LWGA算法,在IWGA-RD算法的基础上按节点权重和边长对边进行排序,设定节点优先级依次迭代加入中继节点,以减少相同环境下部署中继节点的数量。仿真实验与假设检验结果表明,该算法较GA-RD、IWGA-RD算法所需中继节点更少,具有更好的网络性能。后续将用尽量少的中继节点实现网络负载平衡,以解决无线传感器网络耗能不均匀的问题。
