一种混合语种文本的多维度多情感分析方法
2020-12-16李妍慧郑超美王炜立
李妍慧,郑超美,王炜立,杨 昕
(南昌大学 信息工程学院,南昌 330031)
0 概述
在自然语言处理领域,文本情感分析的研究受到了国内外研究者的重视和关注。微博作为目前最大的社交平台之一,具有言论自由、表达随性等特点。基于微博所拥有的庞大数据量和包含的丰富情感,微博成为文本情感分析研究的重要数据集来源。随着研究工作的深入,文本情感分析的研究领域从用户评论逐渐扩展到微博文本上,研究文本的语言也从单语逐渐转变成双语文本。随着互联网的迅速发展与微博在国际市场知名度的提高,微博上涌现出大量“好high”“hold不住”等网络热词,出现了越来越多的混合语种,诸多因素均加大了语言分析和情感预测的难度。国外针对Twitter的英文微博情感分类已有不少研究成果,研究技术已经相对成熟,国内中文的微博情感分析起步稍晚,针对混合语种文本的研究尚处于起步阶段。同时,法国哲学家笛卡尔将人的原始情绪分为surprise、happy、hate、desire、joy和sorrow 6类,在此基础上分支和组合出的其他情绪,构成了人类丰富的情感世界。相比二分类的情感分析,细粒度的情感分析更全面地涵盖了用户的心理状态,更细致地表达出情绪变化。因而,微博研究任务从正负情感扩展到多情感分类乃至更加复杂的问题。多情感的预测分析能够精准地判别用户的观点和态度,对于快速掌握大众的情绪趋向、预测热点事件、实施舆情监控、满足民众需求等具有重要意义。因此,本文运用迁移学习的思想,对微博的中英混合双语文本进行多情感倾向分析,以改善分类效果。
1 相关研究
早期研究混合语种文本主要停留在粗粒度的情感极性分析上,混合语种情感分析的问题在于将资源丰富的语言情感资源应用到资源贫乏的语言中,而不同语言的情感表达之间又无直接关联。因此,根据研究方式的不同,可以分为以下4种:
1)基于机器翻译的方法。文献[1]利用机器翻译转换语言,通过与英文情感词典匹配分析来判定情感极性。文献[2]使用机器翻译方法发现源语言英文文本与日文翻译出的英文之间的词汇重叠率很低。文献[3]指出机器翻译生成的目标语言文本可能与原始数据的情感极性相反,如英文“It is too beautiful to be true.”含有消极情感,翻译成中文“实在太漂亮了是真实的”则传递了积极的情感。文献[4]提出运用两个机器翻译系统对同一文本进行双向翻译,减少翻译过程中的误差,由于情感信息在不同语言下的差异,机器翻译的效果时好时坏。因此,目前的机器翻译工具性能有待提高。
2)基于特征概率分布的方法。文献[5]将文献[6]提出的结构对应学习(SCL)推广到多语言文本中,提出混合语种的结构对应学习方法。针对机器翻译所存在的问题,文献[7]提出M-CLSCL算法,通过改进结构学习算法,并利用拉普拉斯映射影响两种语言之间的词对,借助选出的轴心词对目标语言的情感分类。但是该方法的词对关系是一对一映射,要求过于严格,对翻译结果有一定影响。文献[8]提出基于单词分布式表示的SCL方法,形成一对多的次对映射关系,通过将特征词翻译成目标语言词,使用余弦相似度选择符合条件的多个词,最终统一对关键特征建模得到特征空间,在此空间进行情感分析研究。
3)基于平行语料库的方法。平行语料库通过成对的句子学习混合语言的词向量,消除了对机器翻译的依赖[9]。文献[10]提出把双语词向量运用于英文-中文语言情感分析中,使用双语词向量将训练数据和测试数据映射到统一的空间;双语词向量依赖大型的平行语料库,同时在获取混合语种的语义信息时往往忽视了文本的情感信息。
4)基于深度学习的方法。文献[11]提出一种多语言的词向量模型,并将其应用到跨语言的文本情感分析中。在多语言词向量的基础上,文献[12]提出一种多语言的文档向量模型,并将其应用到跨领域和跨语言的情感分析中。文献[13]通过实验验证,将Twitter消息作为情绪分析对象,把情绪符号作为独特的指标与词向量结合,能够显著提高情感分类的效果。文献[14]分析印度语言对(hi-en,ben-hi-en)在混合语料中句子级层面的情感极性,提出线性支持向量机和由线性支持向量机、逻辑回归、随机森林组成的集合投票分类器两种模型,但模型均使用了n-grams和TD-IDF提取特征向量。文献[15]提出利用CNN结构生成句子的词语级表示,并作为Bi-LSTM网络的输入,用集体编码器捕捉整个句子的情感,在特定编码器中使用Attention机制分析基于字词级别的情感。
上述文献研究了情感倾向性分析问题,但存在以下不足:1)针对混合语言文本的分析大都基于词语级别,由于数据的稀疏性,未能充分考虑到整个句子的关联性;2)混合语言文本的情感分类不够细致,大部分研究仅从正负极性的角度判别,无法准确地传达出情感信息。为此,本文根据中英混合微博文本的特性,提出一种混合语种文本的多维度多情感分析方法,基于句子级进行特征提取并使用迁移学习[16]的思想,同时将情感细分为5类,以提高双语微博多情感倾向预测的全面性与准确性。机器翻译将原始文本翻译成单一语言文本,构造出汉语、英语和双语3种文本,针对3种形式的语义特征,将其中重要信息合并成一个语义向量,再使用Attention机制进行关键信息提取,最终得到对应情感的概率。这种方法不仅从不同语言角度提取句子信息,解决了词语级别的模型所存在的弊端,而且还结合BERT[17]强大的语义提取能力和迁移学习思想的应用,综合考虑了原始文本的情感信息,提炼出的情感倾向更为全面和准确。
2 Transformer模型与BERT模型
2.1 Transformer模型
Transformer[18]作为一种seq2seq模型,沿用了经典的encoder-decoder框架。该模型先对输入序列进行编码,生成相应的语义编码向量,再将其输出到解码器。不同的是使用Self-Attention取代了RNN作为特征提取器,为编码单元的最主要部分,如式(1)所示:
(1)
其中,Q、K、V是输入字向量矩阵,即输入向量维度,Self-Attention中得到的输出序列与输入序列完全相同。式(1)通过计算一句话中每个词与其他词之间的相互关系,得到词的新的表征。
图1所示为Transformer编码单元。

图1 Transformer编码单元
新的表征中包含有词本身信息和该词与句中其他词之间的关系,具有更全面的词向量信息。Transformer中引入“multi-head”机制,增强了词在不同子空间中的交互能力。假如词向量是256维,经过6层的Encoder时,分成8份,则每份以32维进行计算。每部分均与句子中其他词进行交互,如式(2)、式(3)所示:
MultiHead(Q,K,V)=
Contact(head1,head2,…,headh)WQ
(2)
(3)
2.2 BERT模型
BERT(Bidirectional Encoder Representations from Transformers)是一个通用的预训练模型,不但在11项NLP任务中取得最先进的结果,而且简化了NLP领域的预训练模块。BERT采用掩码语言模型(Masked Language Model,MLM)预训练方法表征文本双向特征,增加Next Sentence Prediction预训练方法更精准地捕捉句子间的关联,使用高性能的Transformer结构替代LSTM,并且采用fine-tunning方法构建语言处理模型。
BERT模型的强大之处在于Transformer结构和fine-tunning方法。BERT作为通用的预训练模型,使用双向Transformer[19]作为编码结构,没有固定的decoder,输出为文本表示,可以接受多种下游任务。
fine-tunning[20]指的是迁移学习,深度学习对数据集和计算资源要求严格,fine-tunning是一种半监督学习,通过修改预训练模型结构,选择性载入权重参数,用训练集重新训练模型进行微调。使用相对较小的数据量快速训练好模型,大幅减少了计算量和计算时间。
3 混合语种的多维度分析模型
3.1 模型架构
英文微博句法表达较为严谨,文本情感分析大都基于情感词典进行,但是词典中的资源有限,更新时间周期长;中文微博表达不拘形式,网络热词层出不穷,更没有开源的中文情感词典,难以对句子级进行细致的语法分析。针对中英混合语种的微博文本情感分析问题,随意性地表达更是增加了句法结构的分析难度,使得提取语义特征成为一大难题。为此,本文放弃传统的情感词典、word2vec和skip-gram等方法,对句子在不同语种下的情感倾向进行整合。考虑到词语的稀疏性,将整条微博作为一个整体,探讨内在的逻辑和蕴含的情感倾向,并将此微博翻译成相应的中文和英文,划分成同一文本在3种语种下的细粒度情感分析,然后综合上述3种语义特征,进行深层次情感信息挖掘并作出最终的预测。以一条微博为例,其情感分析的结构如图2所示。

图2 中英混合文本情感分析模型
由于自然语言处理领域模型训练的计算量大,对计算资源要求高,成本偏高,因此使用预训练的BERT模型作为语义提取器,分析在3种语种下的语义信息,通过迁移学习的方法,保留其中的重要信息并进行综合分析,最终通过Sigmoid函数得到情感概率。
3.2 单一语言维度的语义提取模块
基于词语级别的情感词典和word2vec等方法具有稀疏性,无法更好地提取上下文关联性信息。
word2vec仅针对下一个词语进行预测,属于静态预测,而BERT模型通过自注意力模型对整个句子进行整体建模,能够直接获取句子的整体信息。
RNN、CNN等建模方法存在难以捕获相隔较远词语之间的联系的问题,即长程依赖问题,虽然有不少解决方案,如LSTM、调节CNN感受野等,但该问题依旧存在。BERT模型是基于自注意力模型对句子进行建模,会均匀地提取每个词语与其他词语之间的联系,因此无论句子多长,均不会出现长程依赖问题。此外,BERT模型的训练语料相当庞大,且从句子级提取语义信息,对文本的分析能力更强大。针对多种语言的混合语料,Google提供了基于104种语言的混合语料的预训练BERT模型,直接使用此模型将很大程度上减轻工作量。
对于微博数据而言,许多看似相反的情感也存在于同一个微博数据中,如高兴与悲伤、生气与惊喜。原因可能是微博的文本篇幅有不少还是偏长,情感信息比较复杂。在这种情况下如果考虑不同情感之间的关联可能导致引入错误的信息,造成模型识别效果较差。
本文在对BERT所提取的文本信息进行情感分类时,为每个情感都新建一个由全连接层和Sigmoid激活函数组成的Logistic 回归模型,得到每种情感的概率。
针对中英混合双语的微博文本,输入为Im,经过相应的语义训练器BERTm,生成语义向量Vm,得到的语义特征再投入到BERT模型中,可以预测出其情感倾向1。
通过机器翻译将源文本分别翻译成中文和英文两种形式。按照中英混合双语文本同样的训练方式,分别通过语义提取器BERTc和BERTe,根据生成的语义向量Vc和Ve可以得到预测的情感倾向2和情感倾向3。
Vm=BERTm(Im)
(4)
Ve=BERTe(Ie)
(5)
Vc=BERTc(Ic)
(6)
作为整个模型的语义提取部分,在单一语言维度的训练中,仔细观察测试指标在测试集上的变化,当其达到最大值时,保留语义提取模型(BERT)部分的参数。
3.3 多维度语言情感分类模型
使用Attention算法对语义向量进行关键信息提取,能提取深层次词语向量之间的相互联系,并且能消除上一步提取的语义向量的序列信息,方便后续处理。因此,对同一语言维度的语义向量Vm、Vc和Ve,使用Attention算法进行处理,其公式如下:
ut=vTtanh(W·ht)
(7)
αt=Softmax(ut)
(8)

(9)
其中,ht表示在时间t下的输入序列向量,W、v是可训练的参数矩阵,c为输出,αt取值范围是[0,1]。
针对单一语言维度所提取的语义向量ht,通过tanh非线性变换提取在每一个时间序t下的权重向量与同一时间序下的v点乘得到一个0维权重值ut。生成的权重值差值较大,不便于分析,使用Softmax函数将ut映射到实数范围[0,1]之间生成αt,在时间序t下的输入向量ht与αt的成绩进行加权平均得到输出c。
由于实验中3种不同语种的文本、词嵌入维度和时间序列长度不同,因此对上述单一语言维度所提取的语义向量,采用独立的Attention模型,其中,可训练的参数不进行共享。
综合上述3种语言维度下的语义信息,对中英混合文本信息的提炼更为精确和全面。因此,将获取的语义信息向量Cm、Ce、Cc进行拼接融合,得到新的语义向量Cf。新的语义向量综合了3种单一模型下的所有文本特征,通过全连接层和Sigmoid激活函数,便可得到5种情感倾向的概率。同时,模型的损失函数采用平均交叉熵损失。
Cf=Concat(Cm,Ce,Cc)
(10)
p=Sigmoid(w·Cf+b)
(11)
(12)
其中,w、b均为可学习参数矩阵。
相比于简单的处理方法,本文方法使用了迁移学习思想,主要体现在两个方面:一是在单一语言维度的语义提取部分,BERT模型作为自然语言处理领域中的一个通用模型,通过迁移学习方式获取文本的语义向量;二是在综合考虑3种语义向量时,使用迁移学习的思想学习其中的重要信息,生成一个新的语义向量。
4 实验与结果分析
4.1 数据集
本文实验所使用数据集是采用NLPCC2018在“Emotion Detection in Code-Switching Text”情感评测任务中的公开数据集。该数据集包含训练集(Train)6 000条,验证集(Dev)728条,测试集(Test)1 200条。微博内容来自新浪微博,其中标注数据集中包含5种情感,即happiness、sadness、anger、fear和surprise,每篇微博包含0种、1种或者2种情感。本文针对微博级的多标签情感倾向进行分类,NLPCC2018数据集的统计结果如表1所示。

表1 NLPCC2018 数据集的统计结果Table 1 Statistical results of NLPCC2018 datasets
4.2 预处理
本文使用的NLPCC2018数据集整体格式较为整齐,但由于微博文本表达偏口语化,首先对文本进行清洗,去除与情感无关的噪声;其次将其中的繁体中文字转换为简体中文;对于文本中的数字(如2013156,321)、特殊符号(□、(○^4.3 词嵌入
对于使用预训练BERT的实验部分,本文选取了3种不同语言版本的BERT预训练模型,分别是中文版本、英文版本(区分大小写)以及中英混合语言版本。每种版本的模型均需要首先进行编码:对输入文本进行one-hot编码,将语言文字转换为数字表示,得到相应的文本表征;将每个词语映射到一个可变的参数向量中,在模型的训练中调节相关参数。本文采用BERT预训练模型的参数向量作为初始参数向量。
4.4 训练模型
Google提供的预训练BERT有BERT-lager和BERT-base两种版本。由于计算能力受限,本文选择参数量较少的BERT-base版本。BERT-base共有12层,隐层为768维,采用12头模式,共110 M个参数。最大序列长度为512。由表1可以看出,源数据集中5种情感的数据分布不均衡。为保证训练时数据均衡,本文采用随机重复采样的方法,即对于每个训练批次通过随机重复采样保证5种情感数据有相同的数量。表2为实验模型中的参数设置,其中,本文经实验发现在本任务中,Dropout率设为0.5能取得更好的效果。

表2 模型的参数设置Table 2 Parameter settings of model
笔者在实验中发现,简单地将整个模型直接投入训练时,所得到的结果甚至要弱于单一语言维度下的结果,而借鉴了迁移学习思想的模型,先针对单一语言维度进行训练,然后保留其语义提取部分即BERT部分的参数,再迁移到整体模型中进行训练,可取得高于单一语言维度训练下的实验结果。可能的原因是不同语言维度在语义提取部分的参数训练时收敛速度不同,实验流程如图3所示。

图3 训练模型实验流程
本文首先对中文、英文、混合文本分别进行训练,保留其语义提取部分的参数,然后将三者语义向量进行综合分析,并随机初始化模型中的部分分类参数,将单一语言维度中的语义提取部分进行再次训练,得出最终预测结果。使用迁移学习方法与未使用迁移学习方法的实验结果如表3所示。

表3 未使用迁移学习与使用迁移学习的实验结果对比Table 3 Comparison of experimental results without using transfer learning and using transfer learning
4.5 结果分析
为证明本文方法的实用性,本文在NLPCC2018数据集上进行实验,并与文献[21-23]的算法模型进行对比分析。实验将微博情感分为5类,即Happiness、Sadness、Anger、Fear和Surprise。为保证分析的客观性,主要对比的评估标准是查准率和查全率。查准率指的是该类测试样本中的正确判别与该类测试样本总判别的比例,查全率则是指该类测试样本中的判别与该类总测试样本的比例[24]。由于查全率与查准率的相互干扰,因此本文以5种类别的宏平均的F1分数(Macro-F1)为算法模型的评估标准,其定义如下:
(13)
(14)
(15)
(16)
其中,P为查准率,R为查全率,TP为真正例,FP为假正例,FN为假反例。
针对机器翻译后的中文、英文和源数据集的中英混合文本,本文分别采用相应的BERT预训练模型在训练集上进行调参,得到其训练模型,再将验证集和测试集分别投入到相应的训练模型中,实验结果分别如表4~表6所示。
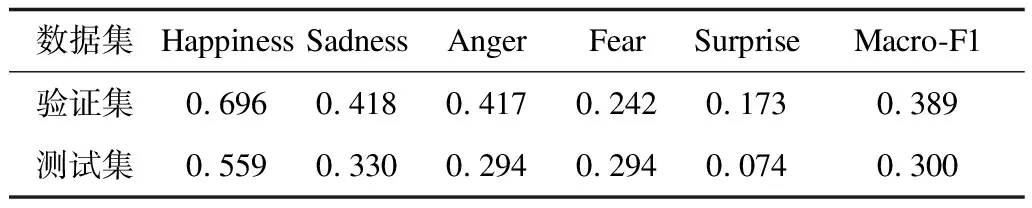
表4 英文文本的多情感分类结果Table 4 Multi-emotion classification results of English text

表5 中文文本的多情感分类结果Table 5 Multi-emotion classification results of Chinese text

表6 中英混合文本的多情感分类结果Table 6 Multi-emotion classification results of Chinese-English mixed text
在3种单一语言维度的情感分析模型下的实验结果可以发现:1)无论是在单一类别还是在所有类别的综合上,验证集的分类性能均优于测试集;2)在5种情感的分类中,Happiness的表现效果最佳,其次是Sadness、Anger,且三者的分类效果均高于对应模型下的Marco-F1;3)对比3种模型的综合性能可以看出,翻译成英文文本下的模型分类效果较差,对情感的倾向预测会出现误差,表现较好的是中文和中英混合文本的分类模型,而且不管是在验证集还是测试集上,中英混合文本的表现均略优于中文分类模型。虽然机器翻译技术已经成熟,能表达源数据集的总体意思,但由于微博文本表达的口语化与网络热词的不断更新,在某种程度上对于语言本身意义的转换仍然存在一定的偏差,损失了部分原始信息。
由表7可知,不管是在验证集还是在测试集上,混合语种文本的多维度多情感分析模型的综合性能均超过了50%。

表7 混合语种文本的多维度多情感分类结果Table 7 Multi-dimensional and multi-emotion classification results of mixed language texts
对比每一类别下的情感分类性能发现,其结果基本均优于以上3种单一语言维度模型在每类情感中的分类效果。一方面是得益于迁移学习的思想,主要应用于单一语言维度文本的语义特征提取和3种语义向量的综合分析中,不仅能够学习到BERT模型中的语义特征、从3种语义向量中获取关键性的情感信息,还优化了整个训练过程,简化了计算过程。另一方面是从3种语言维度的角度能够更为精准地判别情感倾向,对于同一文本,可能在中英混合语言维度中的情感表现不明显,但是翻译成中文或者英文文本,其中蕴含的情绪则非常清晰,3种语言维度的综合考虑降低了情感预测的误判率。
通过图4可以很直观地看出,混合语种文本的多维度多情感分析模型的综合评估性能(Macro-F1)得到了明显提升。分别与基于单一语言维度英文、中文和中英混合的多情感分析相比较,Macro-F1分别提高了0.688、0.133、0.617。
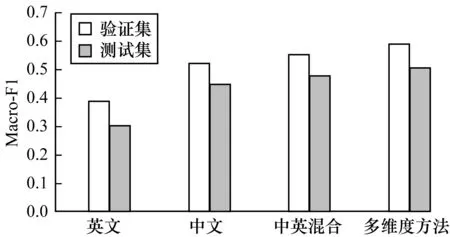
图4 不同方法在验证集和测试集上的Macro-F1
同时,将本文所提方法与在NLPCC2018情感评测任务中的前5名实验结果进行比较,其数据如表8所示。

表8 不同方法在同一数据集下的实验结果Table 8 Experimental results of different methods under the same dataset
上述实验对比结果表明,本文所提的方法取得了较好的效果。从实验结果角度来看,与比赛中使用的单一算法模型相比,实现了不同程度上的超越;与前两名所使用的集成多种算法的集成学习模型比较,超越了第二名,取得与第一名较为接近的实验结果。从建模角度来看,仅使用一种模型建模较为容易,计算更为简单,在实际应用场景中的部署也更易实现。因此,基于不同语言维度,使用BERT模型,借鉴迁移学习思想,本文提出一种多维度多情感的分析方法,为处理混合语种文本的情感分析问题提供了一种行之有效的解决方案。
5 结束语
本文针对中英混合文本的多情感倾向性分析问题,提出一种混合语种文本的多维度多情感分析方法。通过确定5类情感标签,使用BERT模型作为语义提取算法,对同一文本在3种不同语言维度进行情感分析,然后利用迁移学习的思想将各自语义提取模型的参数迁移到整体模型,进行更全面的分析,优化了计算过程,提高了模型性能,同时在针对中英混合文本的多情感分析中取得较好的效果。但是本文方法仍然存在不足,如使用机器翻译将混合文本翻译成中文、英文的数据集,翻译结果不完全准确,同时由于微博表达的口语化和网络热词的不断涌现,翻译过程中会出现偏差,因此使用多种语义提取算法,多角度地挖掘词语、句子之间的深层信息,更全面客观地提取文本的语义信息,精准地分析判断出文本的情感倾向,将是下一步的研究方向。
