基于聚类蚁群算法的物流最优路径
2020-12-16马宁
马 宁
(华北水利水电大学公共管理学院, 郑州 450046)
物流是商品从生产者转移到消费者的过程中最重要的一环,尤其是现今网购的日渐发达,物流也随之变得越来越重要。其中物流配送的最优路径问题,对于提升整个物流运输水平尤为关键[1]。一个科学的物流配送路径,不仅能够使运输的效率得到大大的提高,还要能够降低对物流运输资源的消耗。
关于物流最优路径的求解问题,目前,众多学者对其进行了研究。蚁群算法[2-6]作为一种仿生类算法,已经广泛应用在许多寻找最优解的问题上。随后研究人员Dorigo基于蚁群算法研究了旅行商分配[7]和车间调度[8]问题的最优解。Stutzle[9]提出的MMAS(max-min ant system)以及Gambardella等[10]提出的HAS(hybrid ant system),都在一定程度上提高了蚁群算法的检索效率。Juliandri等[11]通过整数规划来求解最优路线集。Masutti等[12]使用蜜蜂启发方式来求解最优路径。Akhand等[13]通过旅行商分配问题,寻找路径的最优解。Sarwonno等[14]对蚁群算法的全过程进行了分析。以上这些研究虽然对算法的性能有一定的提升,但它们都是一种“尽力而为”的算法,并没有结合物流运输的实际情况,比如用户对于送达时间的要求以及物流运输资源的有限性。
本文在聚类蚁群算法的基础上加入了用户收货时间和运输车空置率的影响因素,对原始算法进行优化。
1 蚁群算法的基本原理
蚁群算法是一种仿生学算法,其已经被广泛应用在组合最优解的问题中。其主要分为基于路径最优解的方式和基于聚类的方式。
1.1 基于路径最优解的蚁群算法
最优路径问题的最典型案例就是,地点i到地点j的最短路径寻找。假设蚂蚁数量为m,那么信息要素更新和转移概率计算的方法为
τij(t+1)=ρτij(t)+Δτij
(1)
(2)
最优寻路就是每一只蚂蚁在经过每一条路径时都留下信息要素,而后面经过的蚂蚁根据信息要素的大小选择路径。经过数次的迭代以后,就可以得到最优的路径。
1.2 基于聚类的蚁群算法
该算法一个最典型的示例就是:一个系统中有多个节点,每个节点都放置多种不同类的物品,一个蚂蚁在随机运动中遇到某个节点时,会拿起数量最对的种类的物品,而放下数量最少的种类的物品。简单来说就是在某点放下物品的概率与该点该物品种类的数量多少成反比。拿起和放下物品的概率为
(3)
(4)
式中:Pp为拿起的概率;Pd为放下的概率。这种方式能够在保证总体物品种类和数量不变的情况下,完成物品的聚类。
1.3 最优路径问题的算法选择
一个典型的物流最优路径问题如图1所示。
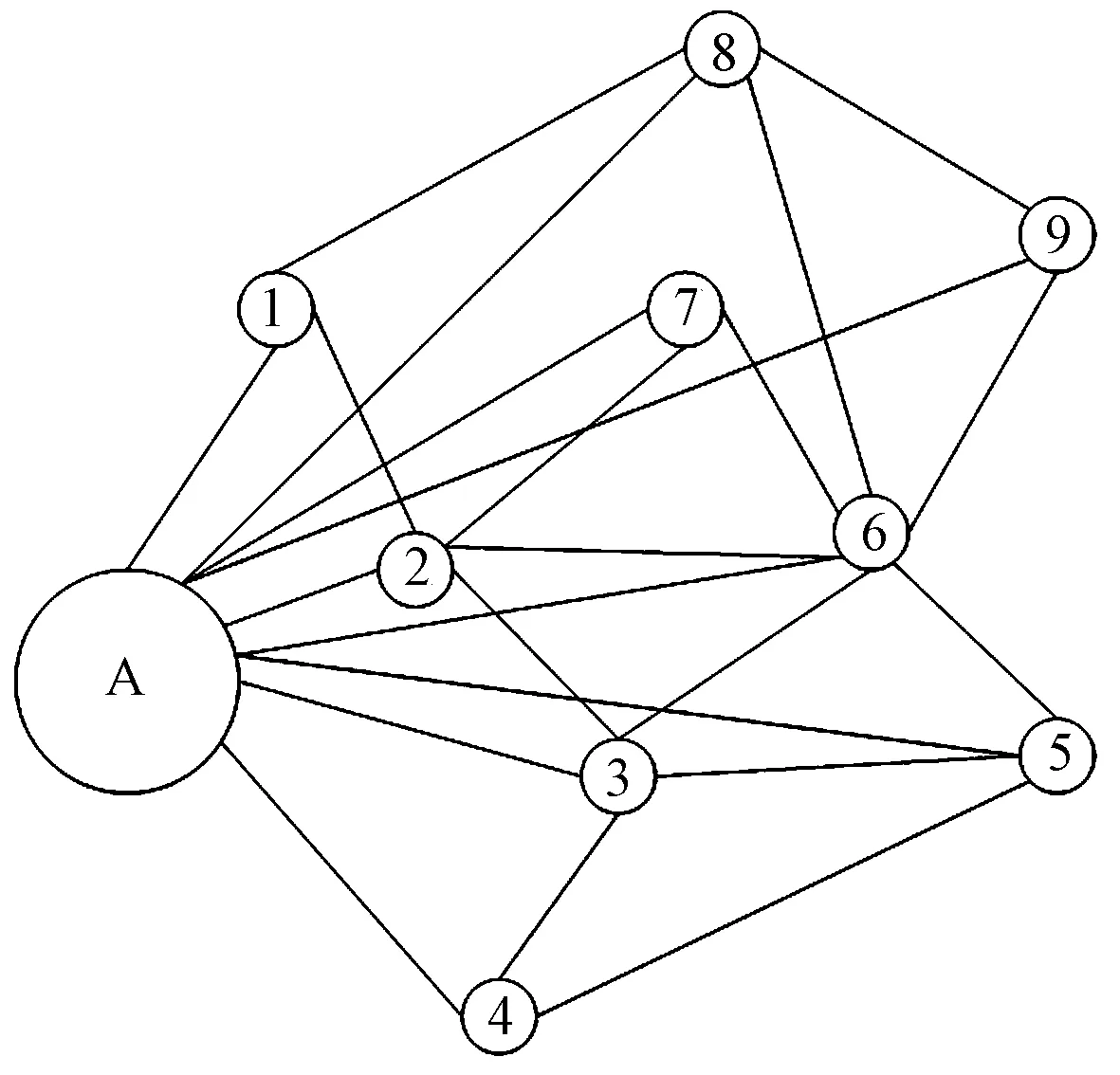
A为货物配送中心;1~9为客户地址图1 物流配送示意图Fig.1 Logistics distribution schematic map
物流配送车需要从A点出发,并将货物送给1~9的客户;不同客户还存在时间要求;对于配送公司而言,还有配送车空置率和成本等要求。那么,在满足上述约束的前提下,如何安排最优运输次序,如何选择最优运送路径,这是一个典型的物流最优路径问题,本文采用基于聚类的蚁群算法,对这一问题进行了探索。
2 物流配送的模型建立
2.1 参数与路径模型
假设客户的地理方位和送货需求都是已知确定的。货物集散中心的运输车辆为m,客户数量为n,客户集合为N,货物集散中心可以被赋值为1,网络中顶点的集合设为D(包括货物集散中心和客户集合),运输车集合为K。N、D、K分别为
N={2,3,…,n}
(5)
D={1}∪N
(6)
K={1,2,…,m}
(7)
货物集散中心的运输车出发时间为T0,客户i收到货物的时间为Ti,客户i的收货时间窗口为(ETi,LTi),客户要求货物的运送量为Q,运输车k所服务的客户集合为Sk,运输车在客户i处的停留时间为Wi,运输车在客户i处进行服务的时间为Si,客户i和客户j之间的距离为dij。
由此,可以建立运输车的路径模型。
变量的决策为
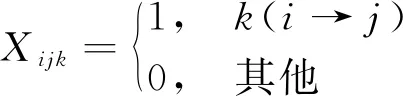
(8)
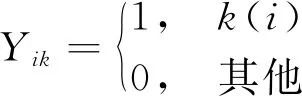
(9)
模型的数学表示为

(10)
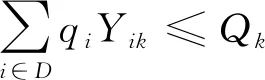
(11)
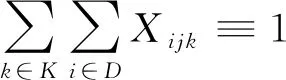
(12)
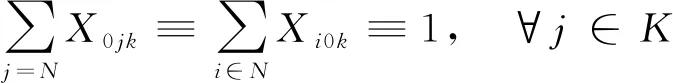
(13)
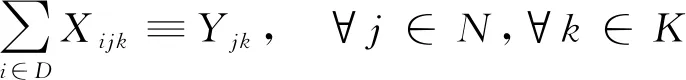
(14)
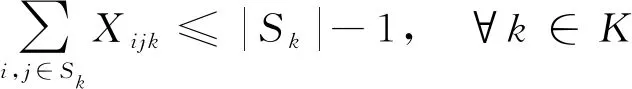
(15)
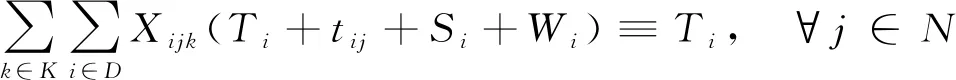
(16)
ETi≤Ti+Wi≤LTi, ∀i∈N
(17)
X=Xik∈D
(18)
式(10)为路径的约束(尽量最短);式(11)为运输车承载量的约束(不超过规定承载量);式(12)为客户的配送和服务次数的约束(为1次);式(13)、式(15)为运输车路径的约束(不能形成回路且必须返回货物集散中心);式(14)为运送顺序的约束(从客户i到客户j);式(16)为货物送达时间;公式(17)为货物送达时间的约束(必须在客户要求的时间窗口内);式(18)为路径约束(所有道路必须是连通的)。
2.2 算法模型
当运输车辆在地点i为某位客户完成服务以后,那么可以按照如下规则来选择下一个服务的客户j。
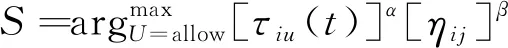
(19)
式(19)中:S为可以选择的下一个客户,U=allow为还需要被服务的客户的集合,在客户集合中选择距离最短的客户。这样运输车辆在每次送货时,都在未被服务的客户中选择下一个服务对象,这样一直迭代循环到最短路径。下一个服务客户的选择概率Pijk可以表示为
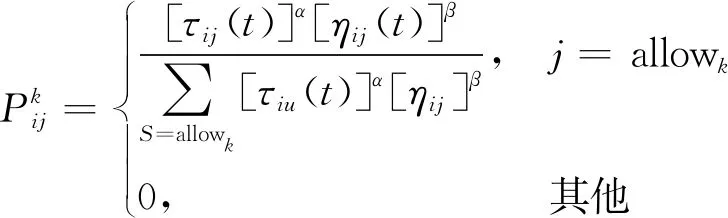
(20)
式(20)中:allowk为车辆k在t时刻完成一个客户的服务后,可选择的下一个服务客户的集合;τij(t)为t时刻,客户i到客户j的信息要素(初始值为常量);ηij(t)为t时刻,客户i到客户j的可见度;α和β为信息素和启发因子对路径选择的影响程度。
当下一个服务客户的集合为空时,就表示完成了一次迭代循环。下一轮迭代循环的起始时刻为t+1,根据上一轮循环残留的信息要素,对信息要素进行更新。其更新方式为
τij(t+1)=ρτij(t)+Δτij(t,t+1)
(21)
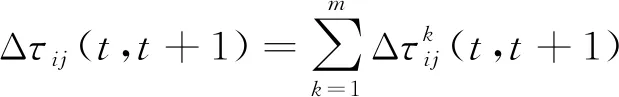
(22)
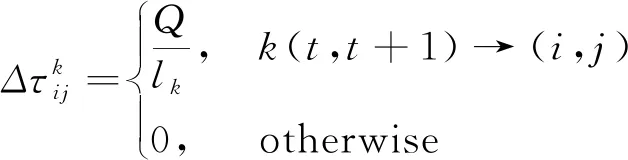
(23)
式中:ρ为信息要素的持久程度,其值为0~1;m为运输车辆;式(22)为t时刻到t+1时刻,路径i到j的信息要素增量;Q为一次迭代循环所释放的信息要素总量;lk为一次迭代循环运输车k所走过的路径长度。
算法的具体步骤如下。
(1)初始化每一个参数,确定货物集散中心到每一个客户之间路径的距离,和客户到客户之间路径的距离。
(2)运输车从货物中心出发开始配送,即i=1;在满足式(17)的前提下,完成对客户j的服务;按照规则寻找下一个需要服务的客户,重复服务过程;经过多次的寻找,完成对系统内所有客户的服务;最后返回货物集散中心。
(3)通过式(20),从上一步中路径集合寻找最短路径的下一位客户,并根据该客户的需求重新分配运输车。
(4)根据式(12)更新信息要素,并回到步骤(2)重新开始;直到达到规定的最大迭代循环次数。
3 案例应用
通过一个理想化案例来证实上述模型的可行性。某物流货物集散中心总共有4辆运输车;车辆的平均时速均为50 km/h;每辆车最大运输量为2 500 kg;每辆车百公里耗油均为11 L;货物集散中心编号为1,客户编号为2~15;运输车的最早出发时间为早晨7:30;每个客户的服务时间均相同。每个客户对于送货时间要求、货物数量要求、以及地理位置坐标如表1所示。
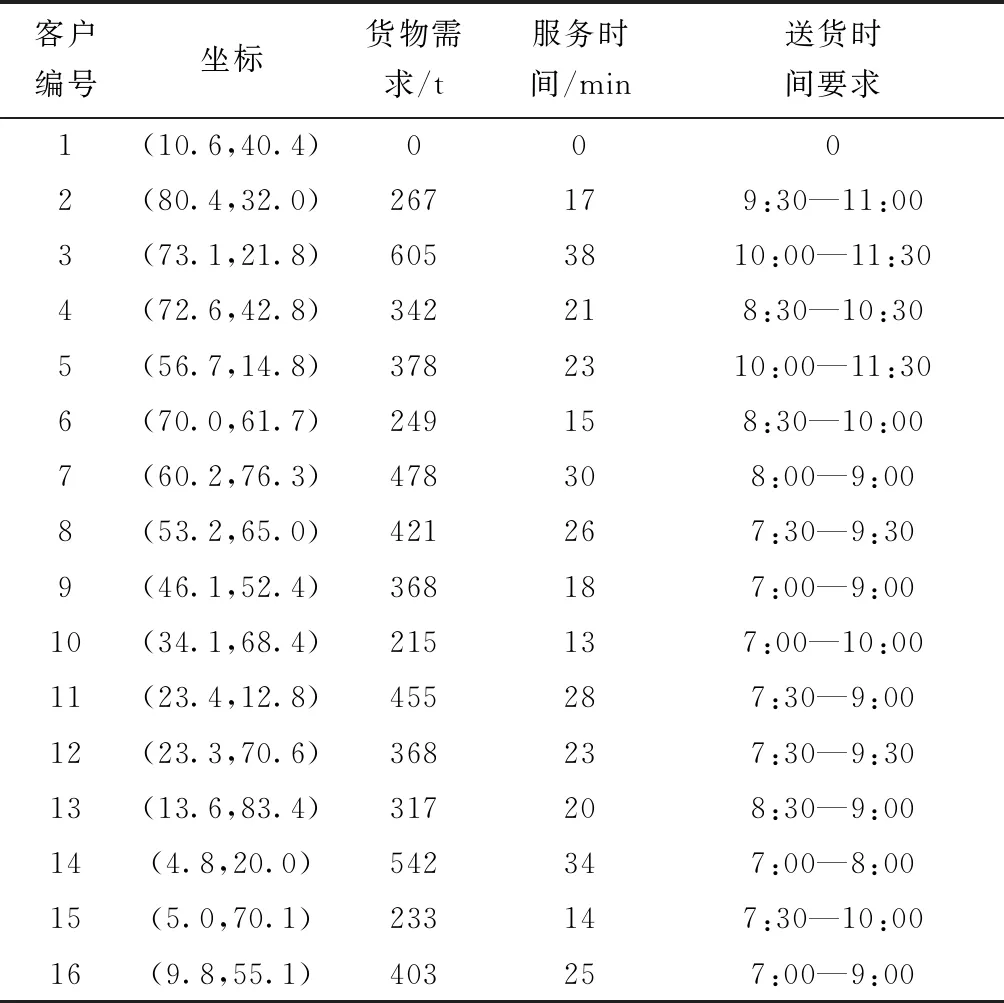
表1 客户信息
假设运输车在货物运输过程中,处于不会出现意外情况、道路距离即为两点间的直线距离、并且交通状况畅通无阻的理想条件下。为了更方便地看出1~16的各个节点之间的距离,将其计算出来,并用表2来统计。
在使用传统的蚁群算法进行最优路径的求解时,都会是一种“尽力快速到达”的方式;即不考虑资源的浪费,以求在最短的时间内完成货物的运输任务。采用传统的蚁群算法得到的运输车路线、空载率、运输量、车辆行驶里程等数据如表3所示。
由表3的数据可知,货物集散中心的四辆运输车全部使用,分为四条线路,在客户要求的时间内,完成所有客户的货物运送任务。这种路径安排方式的成本(运输车行驶里程482.4 km),和运输车浪费情况(空载率)都可以从表3中得出。
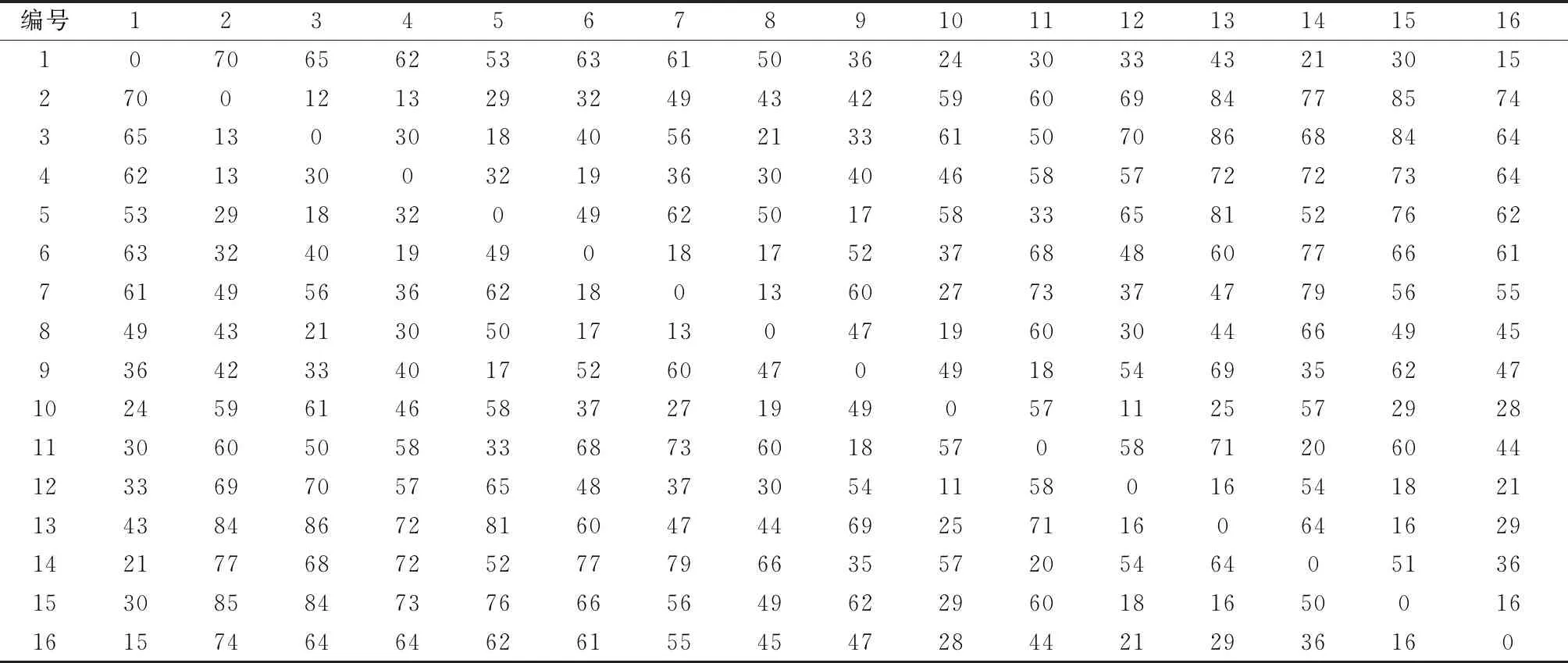
表2 距离信息

表3 原始算法货运数据
考虑客户时间窗口之后,得到的运输车路线、空载率、运输量、车辆行驶里程等数据如表4所示。
由表4的数据可知,货物集散中心的四辆运输车只使用了三辆,分为三条线路,在客户要求的时间内,完成所有客户的货物运送任务。这种路径安排方式的成本(运输车行驶里程416.2 km),和运输车浪费情况(空载率)都可以从表4中得出。
两种算法对比之下可以发现,虽然传统算法在最短的时间内将货物送达,但这在实际中并不是一个硬性的要求,且改进后的算法依然可以满足客户对于送货时间的要求。在成本节约方面,改进算法减少了车辆总行驶里程66.4 km;在车辆分配方面,改进算法节约了一辆运输车的使用;在空置率方面,改进算法极大地减低了运输车的空置率。

表4 改进算法货运数据
4 结论
综上所述,研究了物流配送的最优路径问题,并且建立了配送的模型;以蚁群算法为基础,加入客户收货时间要求和运输车辆空置率这两大要素,对原始算法进行了优化和提高,使其可以更加契合实际应用情况。最终通过对模型案例的分析可以说明,改进后的算法有效地降低了物流运输的成本、节约了物流运输的资源、降低了运输车的空置率。使物流过程向着低成本和高效率的方向又前进了一步。
