云环境下基于字形相似度的密文模糊检索方案
2020-12-10黄保华袁鸿黄丕荣程琪
黄保华 袁鸿 黄丕荣 程琪


摘 要:中文关键词的模糊检索可以基于字形、字音、字义等不同方面,针对目前相关研究主要基于拼音相似度进行的局限性,文章提出了云环境下基于汉字字形相似度的密文模糊检索方案。方案基于汉字字形相似性,通过欧几里得距离来计算汉字的相似度,基于布隆过滤器和p-稳定分布的局部敏感哈希函数构建索引,通过安全陷门和安全索引内积的方式,实现了汉字多关键字的密文模糊检索。实验证明,方案在保证密文模糊检索安全性的同时,具有较低的时间代价和空间代价。
关键词:字形相似度;云环境;局部敏感哈希;可搜索加密;模糊检索
中图分类号: TP391 文献标识码:A
1 引言
随着云计算的普及,为节约数据存储成本和增加访问便捷性,大量数据被存储于云服务器,其中不乏涉密的非结构化文档,而这些文档存储之前需先进行加密。随时间流逝,数据规模膨胀,对于大量加密数据的检索成为问题,可搜索加密(Searchable Encryption,SE)应运而生[1]。
经典SE通过关键字精确检索密文数据,但检索易出现格式错误或检索结果与查询目标不一致,针对这些问题,Jin Li提出了模糊检索,基于编辑距离构建模糊词集合,实现模糊检索[2]。Wang B提出适用于多个关键词的密文模糊检索,使用局部敏感哈希(Locality Sensitive Hashing,LSH)函数和布隆过滤器构造索引,大幅地提高了检索效率[3]。
汉字构词为多个单字组成,与英文有明显界限的构词方式不同。根据汉字构词特性,Ding W利用TF-IDF实现汉字关键词的自动提炼,并基于拼音构建模糊词集进行匹配[4]。陈何峰根据英文关键词构建模糊词集,设计了新的编辑距离衡量方法用于构建模糊集合[5]。方忠进根据汉字读音的特点建立音近模糊词集合,并用英文和中文实现了关键词的同义词构建,实现中文模糊音和同义关键词的检索[6]。
汉字除了读音外还有含义、字形等差异,不能用同样的方式进行度量。Cao J采用三种不同的编辑距离衡量方式,通过多个精准匹配进行模糊匹配[7]。罗文俊提出以同义词集合建立扩展索引实现对同义词的检索[8]。
上述这些方案对中文关键词的密文模糊检索,主要是基于汉字拼音相似进行,但在中文汉字的构成中,字形和字音都是汉字的构成基础。人们在日常生活中遇见生字时,习惯使用字形相近的汉字进行代替,如江新所述,在汉字学习中,相近字形引起的错误多于相近字音引起的错误[9]。所以,在检索中基于字形相似度的模糊检索十分必要,王逍翔[10]提出了一种在明文状态下通过点阵对字形进行编码的关键字校检方案,该方案实现的是明文下的关键字校检,存在编码方式过于复杂,依赖于图形图像处理等缺陷。本文提出了一种云环境下中文多关键词密文模糊检索方案。方案基于字形相似度进行搜索,字形编码简便,支持多个中文关键词同时进行检索,且不需要预先构建模糊词集。
2 相关工作
2.1 布隆过滤器
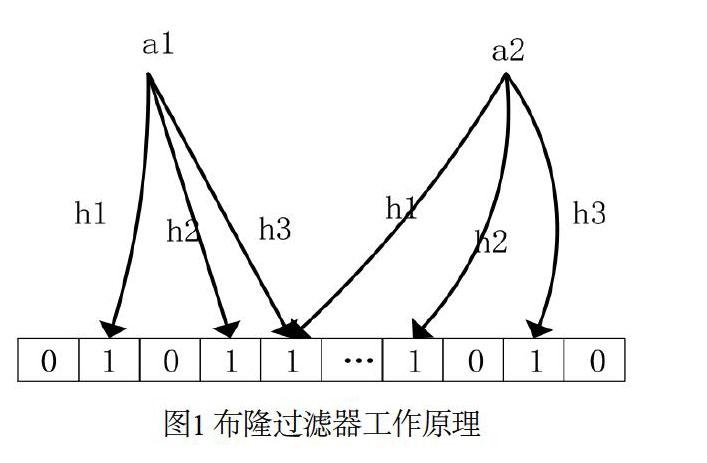
1970年Howard Bloom提出一种二进制向量数据结构—布隆过滤器(Bloom Filter),它拥有优秀的时间和空间效率,可用来判定一个元素是否在集合中[11]。
Bloomfilter判定元素是否在集合的思路是采取哈希函数的方法,先构建一个初始值为0、长度为m的阵列,再将元素映射到布隆过滤器进行判定。该元素在集合内,则该点为1,否则为0。布隆过滤器工作原理如图1所示,有集合S={a1,a2,a3,…,ak},布隆过滤器使用l个独立分布的哈希函数{h1(·),h2(·),h3(·),……hl(·)},将ai映射到对应的比特位,即把数组h(ai)位置的值为1。如果对应位置已有映射,即对应位置值为1,则不影响前面映射的效果[11]。
2.2 欧氏距离
欧几里得度量(Euclidean Metric,也称欧氏距离)常用来定义距离,指两个点在n维空间中的真实距离,或向量的自然长度(即该点到原点距离),在二维和三维空间中就表示两点之间的直观空间距离[12]。
n维空间中,每个点都有n个坐标,表示为x[1],x[2],x[3],……,x[n],n维空间中任两个点x1、x2之间的欧式距离计算方法如公式(1)所示。
(1)
2.3 p-稳定分布的欧氏局部敏感哈希
LSH是一类满足条件的函数,条件为:在原始数据具有很高相似度的情况下,使用此哈希函数哈希后仍保持高相似度;若它们本来不具相似度,对它们哈希后仍不相似[13]。
欧氏局部敏感哈希(Exact Euclidean Locality Sensitive Hashing,E2LSH)是LSH在欧氏空间的一种随机化实现方法[13]。E2LSH基本原理:利用基于P-稳定的性质使用LSH将高维数据降维,并保证降维后的高维数据依然满足LSH的特性。
p-稳定分布的哈希函数族可用来对高维特征向量进行处理,在其将高维数据降维的同时,能保持数据间距离稳定[14]。具体方法:随机構建一个d维向量a,如果a中每个元素的生成都满足p-稳定分布,那么对于d维特征向量v,依据稳定分布特性,随机变量a·v和(|vi|p)1/p·X分布相同(其中X为随机变量且满足p-稳定分布),所以可以用a·v来降维向量v,还能用来计算||v||p,易看出这是一个可以线性组合的过程,可以认为,a(v1 -v2) = a.v1–a.v2[14],于是构造计算公式为:
(2)
其中,是向下取整操作,v为需要降维的数据点,向量 a满足p-稳定分布,r为大于0的常数,b是均匀分布在[0,r]上的实数。
2.4 五笔字型输入法
五笔字型输入法是一种可以将每个汉字表示为不超过四字符的编码串的中文形码输入法。其特点是在输入时基本不用选字,省了找字的时间。与拼音输入法类比,其不会受到方言、发音不规范等问题的干扰,即使不认识该字也可以打出想要的字。五笔字型输入法使用A-Y的25个英文字母(Z为“万能学习键”可用于代替未知字根,作为通配符使用)对汉字实行编码,其字形编码拆解方式称为字根,字根表如图2所示。
3 预备知识
3.1 系统模型
图3是本方案的系统模型,系统由云服务器,数据拥有者和授权用户三个部分组成。数据拥有者使用明文文档生成安全索引并对明文文档执行加密,再将安全索引与密文文档一同上传到云服务器,同时可以下发密钥给其他云服务器用户。获得数据拥有者下发的密钥的云服务器用户称为授权用户。授权用户可在本地构建安全陷门发送到云服务器。云服务器接收到安全陷门之后对加密索引执行检索,并把检索到的密文文档返回给授权用户。授权用户使用拥有者下发的密钥解密密文文档,获得明文文档。
3.2 符号定义
F:明文文档集合;
D:加密后的密文文档集合;
W:从F分词出的关键词集合;
EIndex:生成的安全索引;
K:密钥,用于加密、解密、构建安全索引和构建安全陷门;
Q:查询请求;
T:安全陷門,用于检索;
R:搜索结果,为文档集合。
4 云环境下密文多关键字模糊检索方案
4.1基于字形相似度
汉字分为四类:象形字、形声字、会意字、指事字。汉字中的85%为形声字,所以中国人在认识汉字的过程中,遇到生字时会将字的一部分的读音作为整个字的读音。然而汉字中又有形近字,部分形近字字形相似,读音却有巨大差距,如荀(xun)与苟(gou)、治(zhi)与冶(ye)等。
每个汉字都有其独特字形,用五笔字型输入法的思维可将每个汉字拆解成不超过四个英文字符的字形编码。将汉字转换为字形编码后可通过字形相似度衡量汉字之间的距离。这具备两个优点:一是细化编辑距离,提高模糊检索的精确度;二是编码串可以转换为高维向量,从而通过E2LSH将编辑距离转化为欧式距离用于生成安全索引和安全陷门。
4.2 算法实现
4.2.1 密钥生成
首先根据安全参数m生成密钥sk,数据拥有者进行初始化操作,获得密钥K,其过程如算法1所示。
算法1:密钥生成算法
输入:安全参数m;
输出:密钥K;
1)生成对称加密所需的密钥sk;
2)随机生成L个E2LSH所需要的密钥对hk = { ( a1,b1 ) ,( a2,b2 ) ,…,(an,bn) };
3)随机构建一个m * m的可逆矩阵M1和M2;
4)Return K =(sk,hk,M1,M2)。
4.2.2 安全索引生成
为保证信息安全,提取中文关键词和构建安全索引过程在本地进行。安全索引构建具体步骤:(1)对文件实行分词处理,提炼中文关键词,并将中文关键词转换为字形编码串,构建二维向量vi;(2)构建与文件数相等的布隆过滤器,使每个文件对应一个Bloomfilter,使用E2LSH将vi映射到对应Bloomfilter,获得索引向量;(3)使用可逆矩阵M1、M2对索引向量进行加密,获得安全索引。
算法描述如算法2所示。
算法2:
输入:明文文档集合F;
输出:安全索引EIndex;
1)for ?fi∈F do;
2)Bi = 0 //构造m位的布隆过滤器;
3)get W ={w1,w2,…,wn} for fi //分词;
4)forWi W do;
5) wi = “c1c2……ck”//将关键词wi转换成五笔字形编码(大写);
6) wi = {c1c2,c2c3,……,ck-1ck}//以wi中相邻的两编码字符为一组;
7) vi = 0 //构造一个大小为26x26的向量;
8) for j = 0 to k-1 do;
9) a =( the ASCII of cj)-65;
10) b =( the ASCII of cj+1)-65;
11) vi [a] [b] = 1;
12) end;
13) x1 =ha1,b1(v1),x2=ha2,b2(v2)…xl=hal,hbl(vl);
14) Bi[x1] = 1 ,Bi[X2]=1,……,Bi[xl]=1; //x映射至相应布隆过滤器;
15) Bi= the first half of B,B=the second half of B//Bi分为前后相等两部分;
16) Ii = M1Bi,Ii = M2Bi,Ii= {Ii,Ii};
17)end;
18)return EIndex= {I1,I2,……,In}。
构建安全陷门与构建安全索引过程相同,所以安全陷门的安全性与安全索引安全性能相同,在陷门的生成过程中保证了信息安全。
5.2 性能测试
本文方案性能测试的实验环境:操作系统Windows8.1(64位),CPU为Intel(R)Core(TM)i5-3230M(2.60GHz),内存大小8GB,编程语言为Java。使用500篇中文期刊文献作为数据文件,大小约1GB,从文献标题提取关键词共6,437个关键词。
5.2.1 检索效率
本文方案与文献[6]提出的基于关键词的加密云数据模糊搜索时间做对比,结果如图7所示。
从图7可看出,在进行关键词的模糊检索时,本文方案由于不需要与模糊词集进行对比,相对于文献[6]的方案在检索效率上有较大提高。随着关键词数量的增加,本文方案检索时间也呈递增趋势,但其趋势平缓,适用于云存储中大量关键词的模糊检索。
5.2.2 空间效率
设密文文档数为N,关键词数量为M,本文方案所需存储空间仅为密文文档所需空间以及安全索引所需空间,且安全索引由固定大小的布隆过滤器所构建,可设其所需存储大小为常数k,所以本文方案所需存储空间大小为O(kN),仅与文件数量呈线性相关。文献[6]方案中,需要额外构建模糊词集,模糊词集大小与编辑距离相关,设编辑距离为d,其模糊词集的大小与编辑距离以及关键词数量均相关,所以文献[6]方案的空间代价为O(dMN),而且其关键词数量与文档数成正比关系,其空间代价可表示为O(N2)。所以在空间效率方面,本文方案优于文献[6]方案。
6 结束语
本文针对云环境下密文模糊检索问题,提出了一种基于字形相似度的密文模糊检索方案,实验表明该方案具有较理想的效果。本文方案与基于拼音相似度的方案相比,提出了一种新的模糊检索思路,将汉字转换成字形编码串,用字形编码串相似度来衡量字形相似度。同时,使用欧氏局部敏感哈希来实现编辑距离的量化,再利用布隆过滤器构建安全索引和安全陷门,减少空间使用的同时大幅地提高检索效率,且能很好地保证信息安全。未来将考虑采用分层次的布隆过滤树对方案进行改进,进一步提高方案的检索效率。
基金项目:
1.国家自然科学基金项目(项目编号:61962005);
2.国家重点研发计划课题(项目编号:2018YFB1404404)。
参考文献
[1] Song D. Practical Techniques for Searches on Encrypted Data[C]// IEEE Security and Privacy Symposium, May. IEEE, 2000.
[2] Jin Li, Qian Wang, Cong Wang, et al. Fuzzy Keyword Search over Encrypted Data in Cloud Computing[C]// IEEE Conference on Computer Communications, IEEE, 2010.
[3] Wang B , Yu S , Lou W , et al. Privacy-Preserving Multi-Keyword Fuzzy Search over Encrypted Data in the Cloud[C]// IEEE Conference on Computer Communications. IEEE, 2014.
[4] Ding W , Liu Y , Zhang J . Chinese-keyword Fuzzy Search and Extraction over Encrypted Patent Documents[C]// International Joint Conference on Knowledge Discovery. IEEE, 2016.
[5] 陳何峰,林柏钢,杨旸,等.基于密文的中文关键词模糊搜索方案[J].信息网络安全,2014(07):75-80.
[6] 方忠进,周舒,夏志华.基于关键词的加密云数据模糊搜索策略研究[J].计算机科学,2015, 042(003):136-139,173.
[7] Cao J , Wu X , Xia Y , et al. Pinyin-indexed method for approximate matching in Chinese[J]. Qinghua Daxue Xuebao/journal of Tsinghua University, 2009, 49:1328-1332.
[8] 罗文俊,孙志蔚.基于simhash的密文同义词检索方法[J].武汉大学学报:理学版,2014,60(5).
[9] 江新,柳燕梅.拼音文字背景的外国学生汉字书写错误研究[J].世界汉语教学,2004(01):6+62-72.
[10] 王逍翔,邵玉斌,龙华.基于形近字识别的互联网搜索关键字校验[C].第六届云南省科协学术年会暨红河流域发展论坛论, 2016:194-200.
[11] Burton H Bloom. Space/time trade-offs in hash coding with allowable errors[J]. Communications of the ACM, 1970, 12(7):422-426.
[12] 贾楠,付晓东,黄袁,等.基于树编辑距离的工作流距离度量方法[J].计算机应用,2012,32(012):3529-3533.
[13] M Datar, N Immorlica, P Indyk, et al. Locality sensitive hashing scheme based on p-stable distributions[C]. // The twentieth annual symposium on computational geometry, 2004, 34(2):253--262.
[14] 史世泽.局部敏感哈希算法的研究[D].西安:西安电子科技大学.2013.
作者简介:
黄保华(1973-),男,汉族,贵州盘县人,华中科技大学,博士,广西大学,副教授;主要研究方向和关注领域:数据库安全、车联网安全、密文信息处理。
袁鸿(1995-),男,汉族,湖南邵阳人,广西大学,硕士;主要研究方向和关注领域:密文信息处理。
黄丕荣(1993-),男,壮族,广西崇左人,广西大学,硕士;主要研究方向和关注领域:密文信息处理。
程琪(1994-),男,汉族,广西岑溪人,广西大学,硕士;主要研究方向和关注领域:密文信息处理。