基于深度学习图像数据集评估的车牌检测方法
2020-12-10聂敏


摘 要:针对复杂道路背景中车牌检测精度低的问题,提出一种基于深度学习的车牌检测方法。该方法首先采用快速的基于区域卷积网络方法(Faster R-CNN)在图像中检测出车辆区域,然后对每个车辆区域采用分层抽样方法获取该车辆区域中的车牌候选区域,最后采用训练的深度卷积神经网络过滤非平板候选项,定位车牌区域位置。这种基于车辆区域检测的方法为车牌检测提供尺度信息,限制搜索范围,使车牌检测更加可靠。文章利用Caltech和AOLP图像数据集进行评估算法的性能,实验表明,这种方法在准确率、召回率、F-score性能方法都高于其他算法,可以应用于不同场合下的车牌检测问题。
关键词:车牌检测;深度学习;卷积神经网络;条件约束
中图分类号: TP391 文献标识码:A
1 引言
随着现代城市对智能交通方面的需求,车牌检测在车流监控、交通管理等许多实际领域中的应用越来越广泛,研究人员几十年来提出了多种车牌检测方法[1,2]。现有的许多算法在简单的场景中性能表现良好,但是在开放、复杂的工作环境中,因为道路场景图像受到拍摄条件(扭曲、模糊、光照、遮挡等)的影响和图像中背景杂波(如植物、建筑、行人、道路指示牌等)的干扰,加上车牌区域面积在整个图像中占比相对较小,使得车牌检测仍是一个难题。
传统的车牌检测方法大致可分为边缘检测、颜色检测、区域检测和字符检测四大类。首先,基于边缘的方法[3,4]是利用车牌字符的重复垂直边缘模式。这种方法可以有效地检测到车牌位置,但对背景杂波和图像模糊敏感,容易受到干扰导致精确度降低。其次,基于颜色的方法是将给定的图像分割成颜色均匀的区域,利用车牌的几何特性选取其中的车牌区域。该方法对视角畸变具有较强的鲁棒性,但对光照变化特别敏感。第三,基于区域的方法通过提取纹理特征,对候选区域进行分类。该方法可以处理许多道路场景的车牌检测问题。最后,基于字符的方法是利用字符检测器检测车牌区域。由于近年来机器学习(例如CNNs)的发展,该方法表现出良好的性能,但由于道路场景图像中人员、字符较多,仍存在误报问题。
2 车牌检测方法
车牌检测就是在一张图像中利用合适的矩形框定位出图像内所有的车牌位置。因此,本文提出的车牌检测方法可以分解成三步:首先对输入图像进行车辆检测,其次利用分层抽样方法获取车牌候选区,最后过滤非平板候选项,定位车牌位置。本文提出的车牌检测方法流程图如图1所示。图1a表示输入图像,1b和1c是检测车辆区域,排除背景杂波信息干扰,1d是在车辆区域内进行车牌搜索、检测和定位。
2.1 车牌区域检测
为了生成候选区域,本文采用了分层抽样的方法,通过采用贪婪匹配融合程序,获取一个全局区域。分层抽样是一个对总体进行抽样的方法,首先将总体按照某种特征划分为若干次级总体(层),然后再从每一层内对次级总体进行单纯地随机抽样,组成新的样本。分层抽样可以将一个内部变异很大的层分成一些内部变异较小的层,从而提高总体指标估计值的精确度。
车牌区域检测首先使用基于图形的分割方法生成初始区域,采用贪心算法对区域进行迭代分组:利用基于颜色、纹理、大小和填充(合并区域形状的特征)等特征计算所有相邻区域之间的相似度,将两个最相似的区域组合在一起;然后计算得到的区域与其他相邻区域之间的新相似度;最后将相似区域分组合并的过程重复进行,直到整个图像变成一个单独的区域。具体算法如下所示。
1)输入图像;
2)利用图像分割算法生成初始区域,初始化相似度S=0;
3)選择相邻区域对,计算两者的相似度,;
4)若,令,合并相邻区域对,去除关于和的相似度:和;
5)迭代第三步和第四步,直到S=0;
6)从R中的所有区域中提取车牌位置框L。
由于综合考虑了区域之间的差异性和区域内部的相似度问题,并且采用聚类方式对图形中的顶点进行分割,因此可以获取边界保持良好的车牌候选区域:
其中,表示第i个区域的边界框,N为候选区域的个数。在合并过程后出现的区域均可认为是候选区域,如图2所示。
2.2 车牌分类
给定一个车辆区域和R(该区域中的一组候选区域),利用该车辆区域的尺度信息可以有效地去除误报现象。假定车辆区域的宽度和高度分别为和,考虑到车牌的相对大小和宽高比尺寸,本文施加两个约束,对不满足约束条件的车牌候选区域进行过滤:
经过预过滤后,获取了可能被认为是车牌的各种边界框。为了从多个边界框中判断车牌位置,本文应用一个基于CNN的分类器来过滤剩余的非板块候选。本文采用的CNN模型为TensorFlow框架,TensorFlow框架包含用于特征提取的两个卷积层和两个全连接层,模型配置如表1所示。
由于每个车辆区域中至多存在一个车牌,因此本文选取该区域内响应最大的一个候选区域作为车牌,当存在车辆误检或车牌遮挡情况时,通过设置阈值M降低错误率。如果响应值满足M>0.8,分类器将给出检测过程最终结果,定位出车牌位置。
3 实验结果与分析
采用Caltech数据集(1999)和AOLP数据集两个数据集对本文提出的方法进行性能评估,并与其他方法进行比较。Caltech数据集(1999)包括126个图像集,分辨率为896×592,数据集部分图像如图1和图2所示,由于背景杂乱、车牌颜色不同、车辆遮挡、各种拍摄环境(如光照变化、失焦模糊等)等原因,该数据集中的许多图像对车牌检测算法都具有很大的挑战性。
从精确度(Precision)、召回率(Recall)和F-score三项指标对本文提出的车牌检测方法进行评估,其中F-score定义:
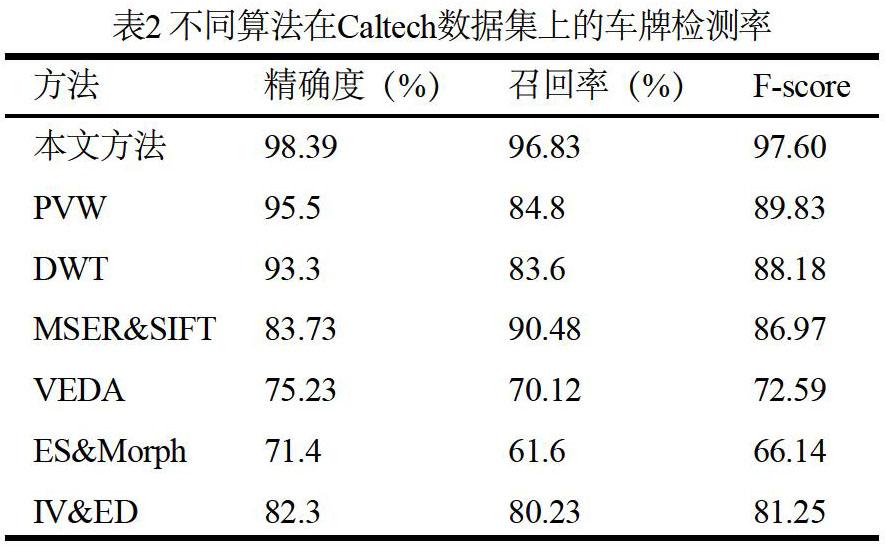
表2给出了本文方法与其他方法在Caltech cars数据集的实验检测结果。对比的车牌检测方法有:基于主视觉单词的字符识别算法(Principal Visual Word,PVW),MSER和SIFT分类器相结合的识别算法(Maximally Stable Extremal Regions& SIFT,MSER&SIFT)、垂直边缘检测算法(Vertical Edge Detection Algorithm,VEDA)、边缘统计和形态学结合的算法(Edge Statistics & Morphology,ES&Morph)、离散小波变换(Discrete Wavelet Transform,DWT)、强度方差和边缘密度(Intensity Variance & Edge Density,IV&ED)检测算法。
从表中可以看出,本文所提方法的精确度为98.39%,召回率为96.83%,优于其他算法。
4 结束语
由于道路场景图像中背景杂乱、车牌颜色不同、车辆遮挡、拍摄模糊等原因,有效的车牌检测仍然是一个十分具有挑战的问题。本文提出了一种基于深度学习的车牌检测方法,该方法根据深度学习和分层抽样方法缩小车牌检测区域信息,根据多尺度的约束条件,有效处理误报问题,提高检测精度。采用不同情况下的真实数据集Caltech和AOLP对本文提出的方法进行实验评估,从实验结果来看,本文提出的方法在性能指标方面都优于其他检测方法,说明本文方法的有效性。
参考文献
[1] 郑楷,郑翠环,郭山红,等.基于色差的车牌快速定位算法研究[J].计算机应用与软件,2017,34(5):195-199.
[2] 陈庄,杨峰,冯欣,等.多尺度积角点检测和视觉颜色特征的鲁棒车牌定位算法[J].重庆大学学报,2016,39(2):89-98.
[3] Liu W B,Wang T. Anti-Noise Car License Plate Location Algorithm Based on Mathematical Morphology Edge Detection[J].Applied Mechanics and Materials,2014,513-517:1052-1055.
[4] 钟伟钊,杜志发,徐小红,等.基于字符边缘点提取的车牌定位方法[J].计算机工程与设计,2017,38(3):795-800.
作者简介:
聂敏(1970-),女,土家族,湖南花垣人,贵州大学,本科,铜仁学院大数据学院,副教授;主要研究方向和关注领域:多媒體技术与应用、大数据安全。