基于CNN 的双边融合网络在高光谱图像分类中的应用
2020-12-10
(河海大学计算机与信息学院,江苏 南京 211100)
1 引言
近年来,高光谱图像(HSI,hyperspectral image)引起了人们的广泛关注,在各种遥感领域,如农业监测、环境监测、海洋遥感等[1-4]中都有应用。由于数百条光谱波段为地物信息的识别与分类提供了极为丰富的光谱信息,在早期的研究中,利用光谱信息进行分类成为一个热门方向[5-7],其中,特征选择和降维[8-13]的方法常被用于缓和光谱维的高维性。随着研究的深入,高光谱图像复杂的空间、光谱特征分布成为困扰高光谱图像分类的主要问题,许多研究者选择加入空间局部联系性来提升模型的分类性能[14-17],并取得了一定的效果。但这些方法大多基于手工特征和浅层模型,不仅高度依赖专家知识,而且泛化力差,难以提取具有代表性的判别特征。
深度学习[18]是目前最热门的算法之一,它的出现使计算机技术在图像分类[19]、目标探测[20]等方面取得了巨大的进展。与传统的机器学习算法相比,它可以自动从原始输入数据中由浅到深地提取特征,其学习过程完全自动化,且适应力强。Chen等[21]将深度学习引入高光谱图像分类算法中,构建了一种基于堆叠自编码器的深度模型来提取高级特征。Liu 等[22]提出一种利用深度置信网络提取特征,再结合主动学习对这些特征进行迭代的分类框架。虽然这些光谱分类器已经取得了较好的分类结果,但研究证明,将空间特征合并到分类器中会进一步提升分类精度[23]。因此,许多研究者将目光转向了在图像识别领域具有核心地位的深度卷积神经网络[24]。Zhong 等[25]设计了一种以原始的三维立方体作为输入数据的端到端光谱空间残差网络。Feng 等[26]设计了一个3D-2D 深度卷积神经网络(CNN,convolutional neural network)模型,利用残差学习和深度可分离卷积来学习深层次光谱空间特征。残差学习[27]等方法虽然可以解决模型向深度进发时所引发的过拟合等问题,但在解决CNN 向深层进发时所引起特征图分辨率下降、细节特征丢失,进而导致最终分类精度下降的问题上仍有进一步提升空间。针对这一问题,Li 等[28]结合反卷积与全卷积来增强空间分辨率,Mou 等[29]提出一种由全卷积和反卷积搭建的无监督光谱空间特征学习网络结构。这类方法往往需要在反卷积前设置最大池化层来去除冗余,减少计算负担,但最大池化层同样会带来特征丢失的问题,以往的方法往往无法有效克服这种信息丢失,从而导致最终分类结果下降。另一方面,Ma 等[30]提出一种带有跳跃结构的端到端反卷积网络来学习频谱空间特征,该方法通过超链接来融合深浅层判别特征,从而弥补损失的特征信息并进一步提升性能。但其面临的一大问题是无法精准地找出最优深浅融合层,同时,过多的跳跃结构也会增加模型过拟合的风险。另一种提取有效判别特征的传统策略是基于特征融合的宽网络,如Lee 等[31]提出的利用多尺度滤波器的空间光谱特征融合的分类方法和Gao 等[32]提出的多分支融合分类方法。但这些宽网络往往只是对某一特征图进行优化,而对其他特征图优化不足。
为了解决这些问题,本文提出了一种双边融合块网络(DFBN,bilateral fusion block network)对高光谱图像进行分类,与以往的高光谱图像分类算法模型通过增加深度或广度来获取更为丰富的特征相比,它更加注重挖掘已被提取的特征信息,即将同一特征图内更具有代表性的判别特征与其他特征相分离,并采取不同方法进行处理,从而完成对特征图的优化。在结构方面,它由上下2 个结构组成,常规卷积、转置卷积、上采样和最大池化层为下结构,1×1 卷积层和超链接为上结构。下结构负责对更具代表性判别特征进行强化处理,上结构负责传递被丢失的局部空间联系性信息。所有结构共同作用,以达成更高效的分类精度。
2 提出方法
2.1 双边融合块网络
图1 展示了双边融合块网络高光谱分类框架的总体流程。从图1 可以看出,为缓和高维性、节约计算成本,首先应用主成分分析法(PCA,principal component analysis)抽象出高光谱图像中最具有信息量的波段子集;然后建立以标记像素为中心的图像块,并传送给双边融合块网络进行训练;最后对待测像素的标签进行预测。其中,双边融合块网络主体由双边融合块、全连接以及sigmoid 分类函数构成,双边融合块的个数与高光谱图像的复杂程度相关。
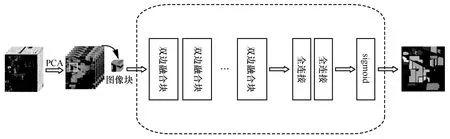
图1 双边融合块网络高光谱分类框架的总体流程
2.2 双边融合块
图2 展示了双边融合块的整体结构,它由上下2 个结构组成。上结构负责传递原始局部空间联系性,由一个带有1×1 卷积的超链接构成;下结构负责提取更具代表性的判别特征并强化,由2 个卷积层、一个最大池化层,以及带有上采样层和转置卷积层的双层结构共同组成。下面以基准数据集IP(Indian Pines)的参数设置为例,展示双边融合块的具体设置。
首先,将输入图像块的大小设置为15,21×21(表示空间尺寸为21 像素×21 像素,图层共计15 层),并将第一卷积层中的滤波器尺寸设置为16,5×5,步长设置为(1,1),输入图像块与滤波器卷积后得到尺寸为16,21×21 的新特征图。然后,利用缩小比例因数为(3,3)的池化层对该特征图进行最大特征提取,以此得到一个尺寸为16,7×7 的特征图。包含转置卷积和上采样的双层结构将会对该特征图进行强化处理,将前者的滤波器尺寸设置为16,3×3,步长设置为(3,3),后者则沿着特征图的行和列分别将这些最大特征重复3 次,二者所得特征图结合为一个32,21×21 的融合特征图。该融合特征图被传递给滤波器尺寸为64,5×5 的第二卷积层,并在Relu 处理前,与上结构中经64,1×1的滤波器处理后得到的尺寸为64,21×21 的特征图相融合,进而得到最终输出特征图谱。本文还为每层卷积添加了批量归一化(BN,batch normalization)和Relu 函数加快训练过程,提高泛化能力。
池化层在提取优质特征,去除噪声冗余和抑制过拟合等方面有着出色的表现。在本设计中,池化操作将提取特征图内最优特征,双层结构负责对最优特征进行强化,即利用转置卷积重构最优特征的特征图谱,扩展其空间分辨率;利用上采样将最优特征复制到一定空间范围内。最后将二者的输出拼接,得到更具代表性的判别特征强化图。
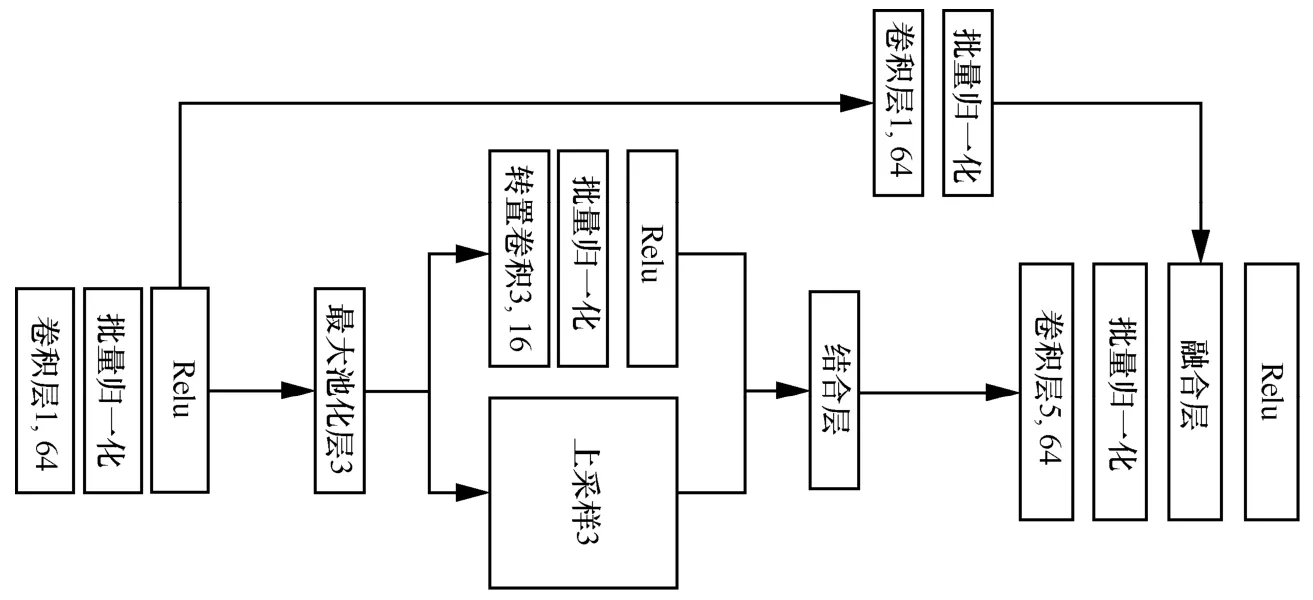
图2 双边融合块结构
图3 展示了转置卷积和上采样的原理。转置卷积层可以将单个输入特征与多个输出特征相关联。上采样将池化层提取出的最大特征值直接复制到附近位置上,从而扩充特征图谱。

图3 转置卷积与上采样原理
3 实验结果与分析
3.1 高光谱图像设置
本文将在IP、PU(University of Pavia)、SA(Salina)这3 个基准数据集上对所提双边融合块网络进行测试,以验证其有效性。
IP 数据集是由AVIRIS 传感器在印第安纳州西北部上空拍摄的。它在空间域上由145 像素×145 像素组成;在光谱域上则由224 个光谱反射率波段组成,其波长范围为0.4~2.45 μm。其中,可用的地面真相为16 个类,本文的实验中去掉20 个吸水带,最终选用数据集光谱波段总数为200 条。
PU 数据集是由ROSIS 传感器在意大利北部上空拍摄的,它在空间域上由610 像素×340 像素组成;去掉吸水带后,光谱域上由103 个光谱波段构成,光谱覆盖范围为430~860 nm。其中,地面真相为9 个类,本文实验中使用的数据集光谱波段总数为103 条。
SA数据集是由AVIRIS传感器在加利福尼亚州上空拍摄的,它在光谱域上具有224 个波段,空间域上则是由512 像素×217 像素组成,它还具有高空间分辨率(3.7 米/像素)的特点。去掉20 个吸水带后,实验数据集波段总数为204 条,其可用的地面真相为16 个类。
图4 展示了上述数据集相应参考数据的色彩合成以及每个分类的样本集的数量。
3.2 实验设置
本文所提双边融合块网络基于Python 语言与keras 深度学习框架。实验环境为64 位 Windows10操作系统,RAM 16 GB 和 NVIDIA GeForce GTX 1660 Ti 6 GB GPU。为了防止不同的训练样本所带来的偏差,本文实验取相同条件下20 个以上的实验结果的平均值进行分析。本模型采用随机梯度下降法更新权重,学习率为0.01,全连接中的Dropout层断开的神经元比例设置为0.3,激活函数为Relu。本文还对双边融合块网络进行了小批量梯度下降的训练,训练样本设置为16 个,epoch 设置为200。
对于IP 数据集,随机选取10%作为训练样本,并将剩余90%作为测试样本。对于PU 数据集,随机选取2%作为训练样本,并将剩余98%作为测试样本。对于SA 数据集,随机选取0.5%作为训练样本,并将剩余99.5%作为测试样本。
为了更好地衡量分类准确度,采用总体精度OA 表示被正确分类的类别像元数与总的类别个数的比值,Kappa 系数KA 表示分类与完全随机的分类产生错误减少的比例,平均精度AA 表示各类别的平均准确率。
3.3 模型合理性测试
双边融合块网络的最优参数如表1 所示。

图4 IP、PU 和SA 数据集的样本设置
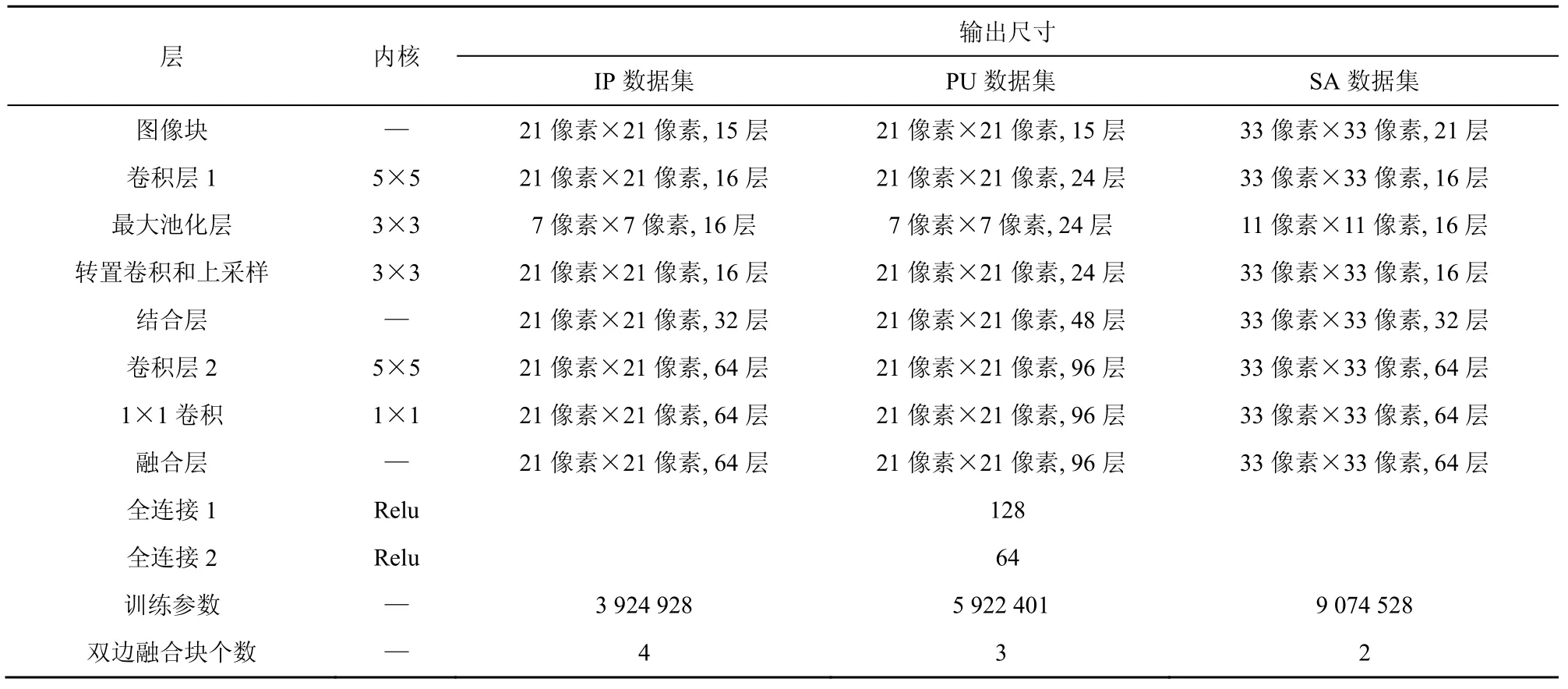
表1 双边融合块网络最优参数
为了印证双边融合块中各个层的有效性,本文以IP 数据集为代表,对设置不同层的合理性进行分析,结果如表2 所示。从表2 中可以看出,当不采用转置卷积、上采样和超链接时,OA 仅为97.78%,分别加入上述3 种优化手段后,OA 均有不同程度的提升。当同时使用上采样和转置卷积时,OA 达到98.37%,明显优于单一采用转置卷积或上采样的98.15%和98.29%。超链接结构的加入也使OA 提升,这是因为引入了原始局部空间相关性。同时采用上述3 种优化手段,OA 达到98.45%。
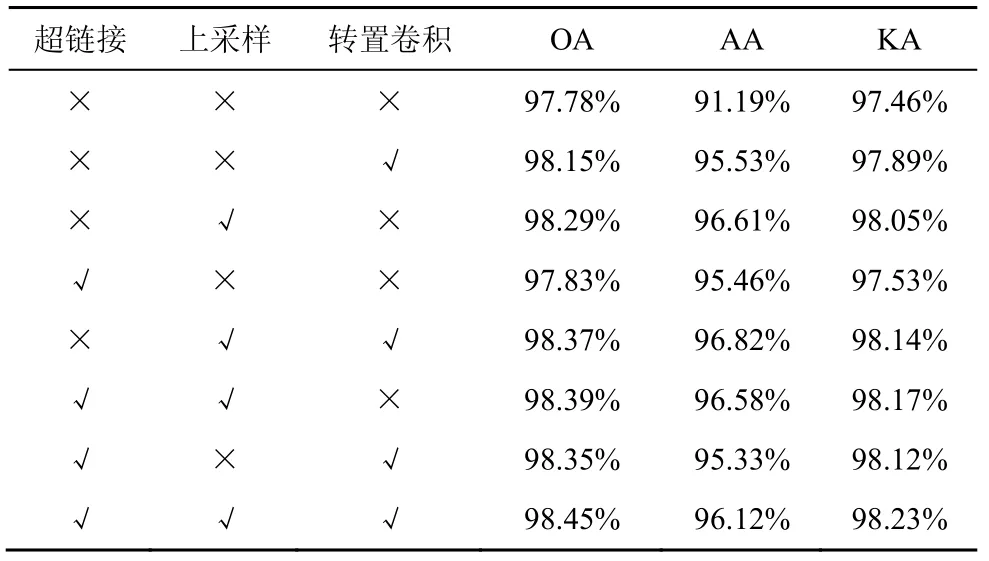
表2 利用IP 数据集对双边融合块网络进行层设置分析
3.4 小样本测试
小样本问题是现有HSI 分类方法中普遍存在的问题。为了评估双边融合块网络在小训练集下的分类性能,本文从各类中随机抽取一定比例的样本作为训练集,剩下的样本作为测试集。对于IP 数据集,本文随机选取了1%、3%、5%、7%、10%的训练样本进行测试;对于PU 数据集,随机选取0.5%、1%、2%、3%、5%的训练样本进行测试;对于SA 数据集,随机选取0.1%、0.5%、1%、2%、3%的训练样本进行测试。测试结果如表3~表5 所示。可以看出,双边融合块网络具有非常好的小样本分类性能,对SA 数据集分类表现最佳,0.5%的训练样本OA 即可达到98.71%;其次是PU 数据集,2%的训练样本的OA 为98.74%;在IP 数据集的表现上,10%的训练样本OA 可达98.45%。
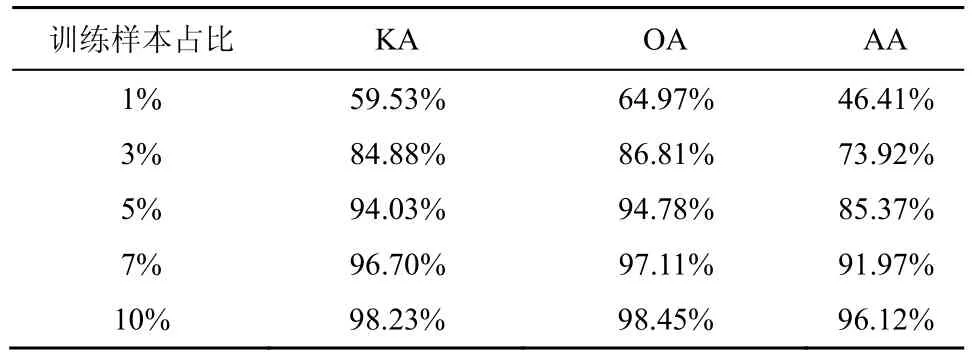
表3 IP 数据集在小样本情况下的分类结果
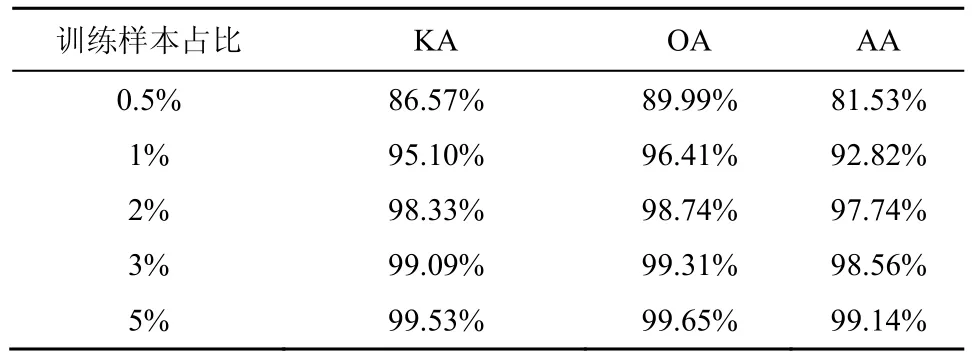
表4 PU 数据集在小样本情况下的分类结果
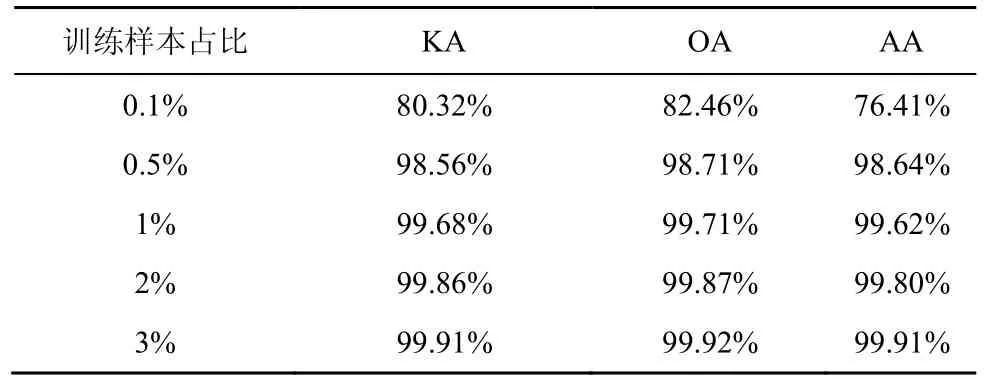
表5 SA 数据集在小样本情况下的分类结果
3.5 与其他模型的比较
为了评价所提双边融合块网络的性能,本文将与5 种经典的基于卷积神经网络的高光谱图像分类模型进行对比,包括RPCA-CNN(randomized principal component analysis convolutional neural network)模型[13]、带有多尺度滤波器的深度网络 DCNN(contextual deep convolutional neural network)模型[31]、反卷积增强网络FCNN(full convolutional neural network)模型[28]、利用空谱特征进行分类的3D 网络SSRN(spectral-spatial-residual network)模型[25]和具有16 层卷积的2D 经典残差网络DRN(deep residual network)模型[27]。为了使所有的性能评估基于相同的条件,DCNN 模型、FCNN 模型、SSRN 模型与DRN 模型均采用了批量归一化层优化训练过程,批尺寸为16个。RPCA-CNN 批尺寸为32 个。为了更好地与传统残差网络进行对比,DRN 模型的训练集与双边融合块网络相同。其余参数参考相关文献设置。
本文测试了训练样本大小固定的情况下,各种模型的性能。在IP 数据集中随机选取10%的样本进行训练,其余90%的样本进行测试。图5 展示了不同模型的分类效果。从图5 中可以看出,RPCA-CNN模型的分类效果最差,其分类图中具有相当大的噪声,这是因为其模型深度不够,不能提取到具有代表性的判别特征,同时对训练过程中出现的过拟合、分辨率下降等现象没有做出相应优化调整。而在另外4 种经典分类模型中,注重增加网络深度的算法模型(SSRN 模型、DRN 模型、DFBN 模型)所取得分类结果要明显优于其他对比模型。此外,与SSRN 模型和DRN 模型相比,所提DFBN 模型能够更准确地对近边缘区域的像素进行分类,并提供与参考图(图4)更加相似的结果。表6 和表7给出了针对IP 数据集的定量分析结果。RPCA-CNN模型所取得的定量分析结果最差,所提DFBN 模型在OA、KA 上均取得了最优的结果,而在AA 上略低于SSRN 模型,这是由于在IP 数据集中存在类别样本极度不均衡的现象,而基于3D 卷积神经网络的SSRN 模型在加入了原始高光谱图像的光谱上下文联系后,克服了这一缺点,但其忽略了卷积神经网络在向深处进发所引发的空间分辨率下降,以及对已提取到特征的利用,所以在精度方面的综合评价上,本文所提DFBN 模型取得了最优结果。
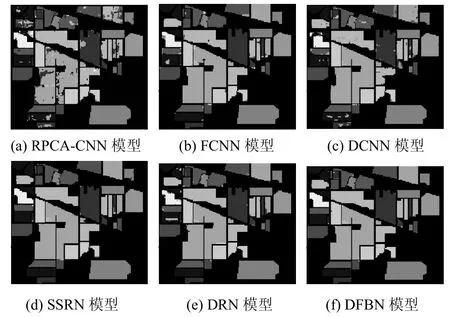
图5 不同方法对IP 在标记像素上的分类结果
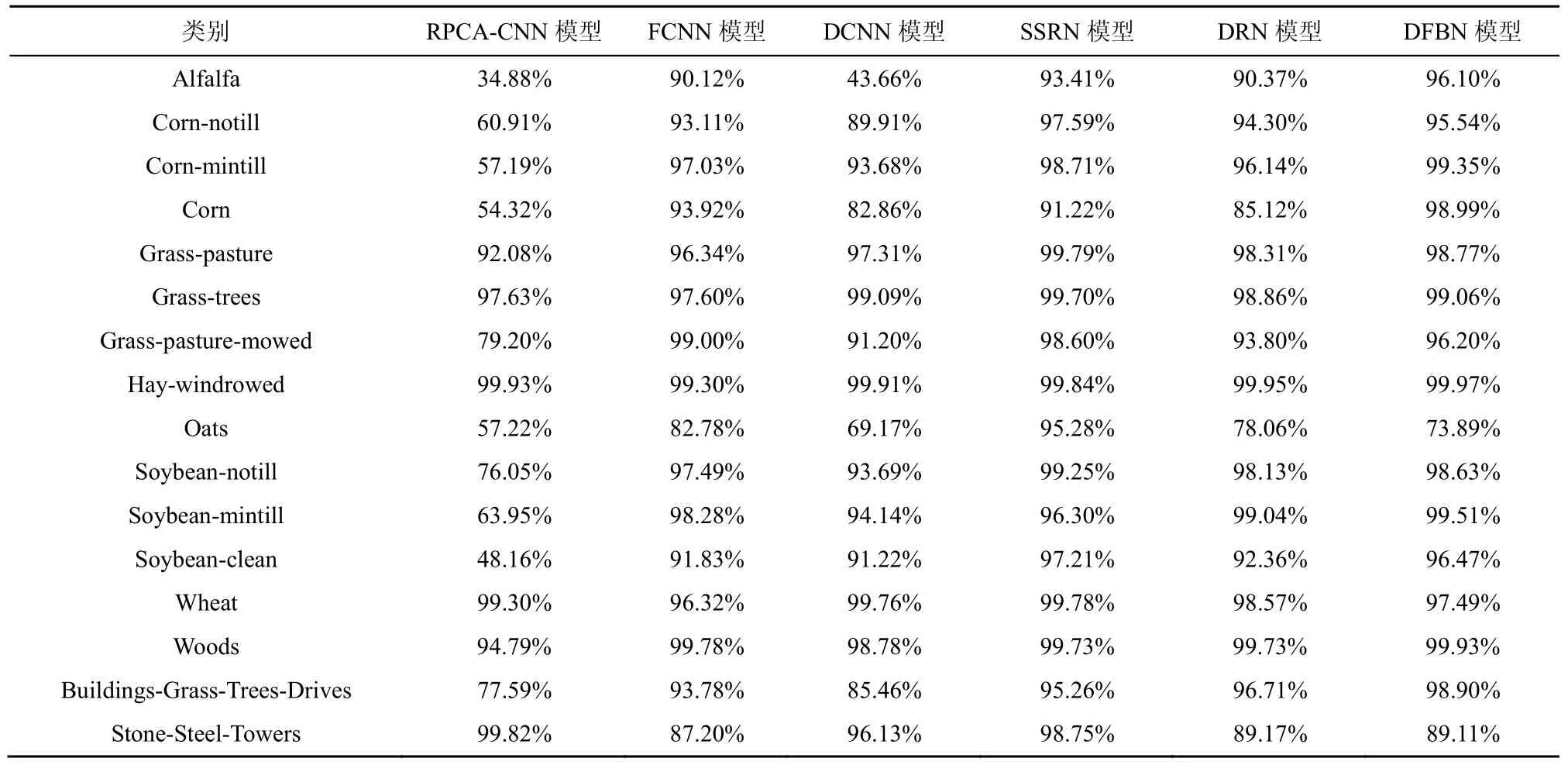
表6 在IP 数据集下与其他分类模型的比较
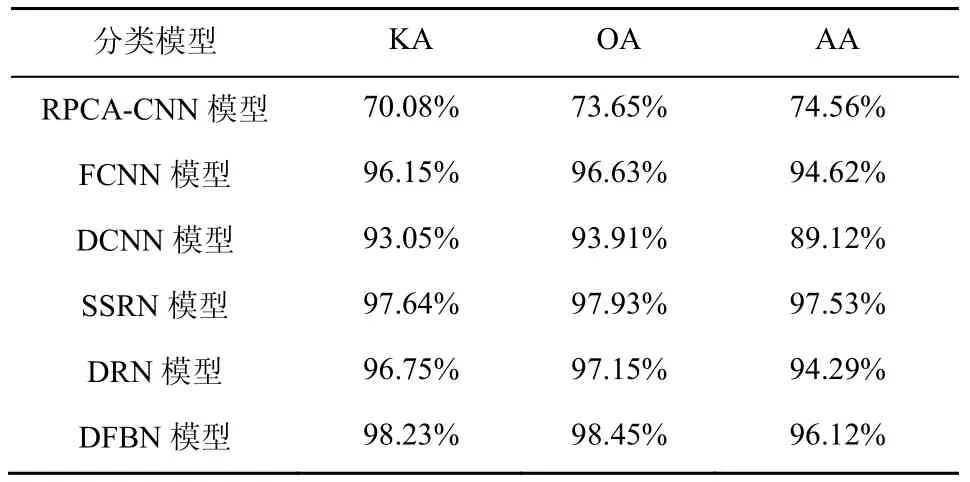
表7 针对IP 数据集的分类结果
第二和第三个实验分别在PU 数据集和SA 数据集上进行。对PU 数据集,随机选取2%作为训练样本,剩余的样本作为测试样本。对于SA 数据集,选取0.5%作为训练样本,剩余样本作为测试样本。图6 和图7 给出了由不同分类方法得到的分类图,表8~表11 为相应的定量分析结果。同样地,在视觉效果上,本文所提方法在2 个数据集上所展示的地物分类图拥有最少的噪声且与图4 所展示的地物分类参考图最为相近;在定量分析中,DFBN 模型在PU 数据集和SA 数据集上的OA 分别达到了98.45%和98.74%,OA、KA及AA 均高于其他对比方法。所提DFBN 模型在IP 数据集、PU 数据集和SA 数据集上均有较好的性能。

图6 不同方法对PU 在标记像素上的分类结果

图7 不同方法对SA 数据集在标记像素上的分类结果
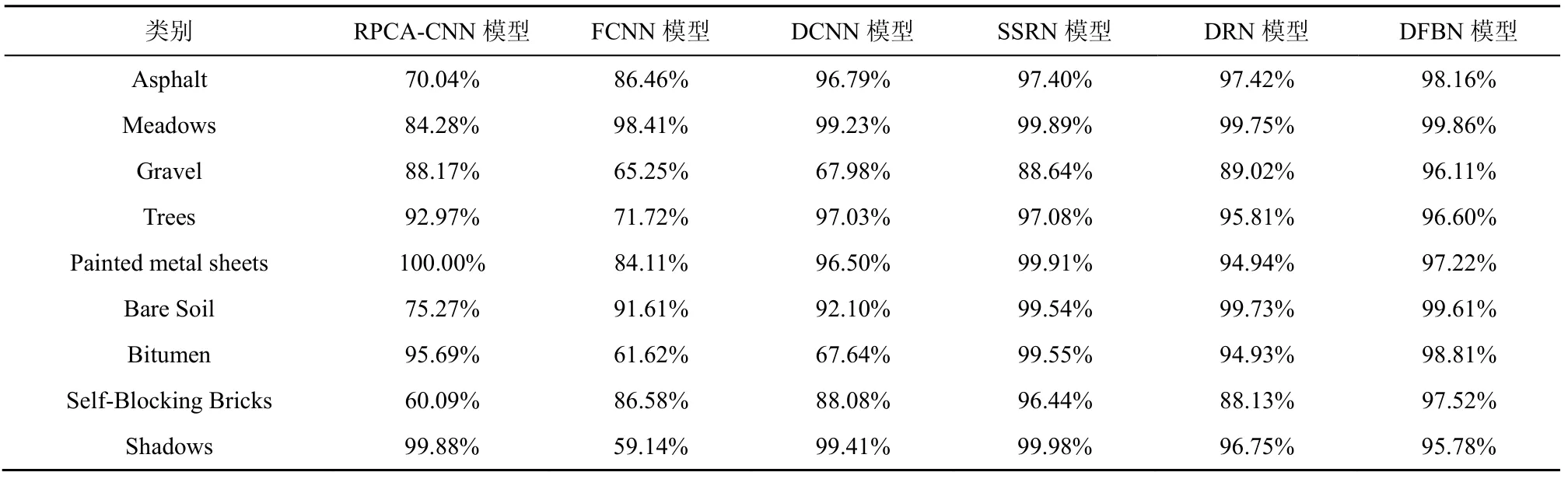
表8 在PU 数据集下与其他分类模型的比较
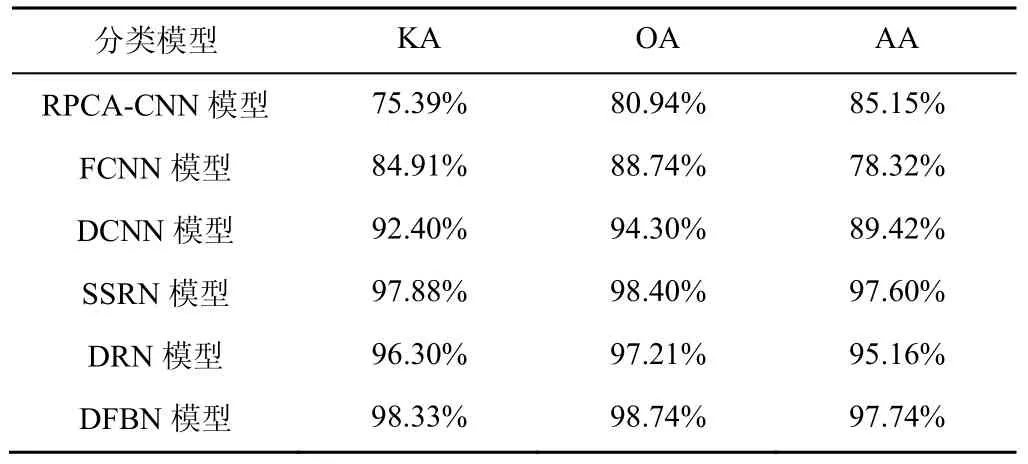
表9 针对PU 数据集的分类结果
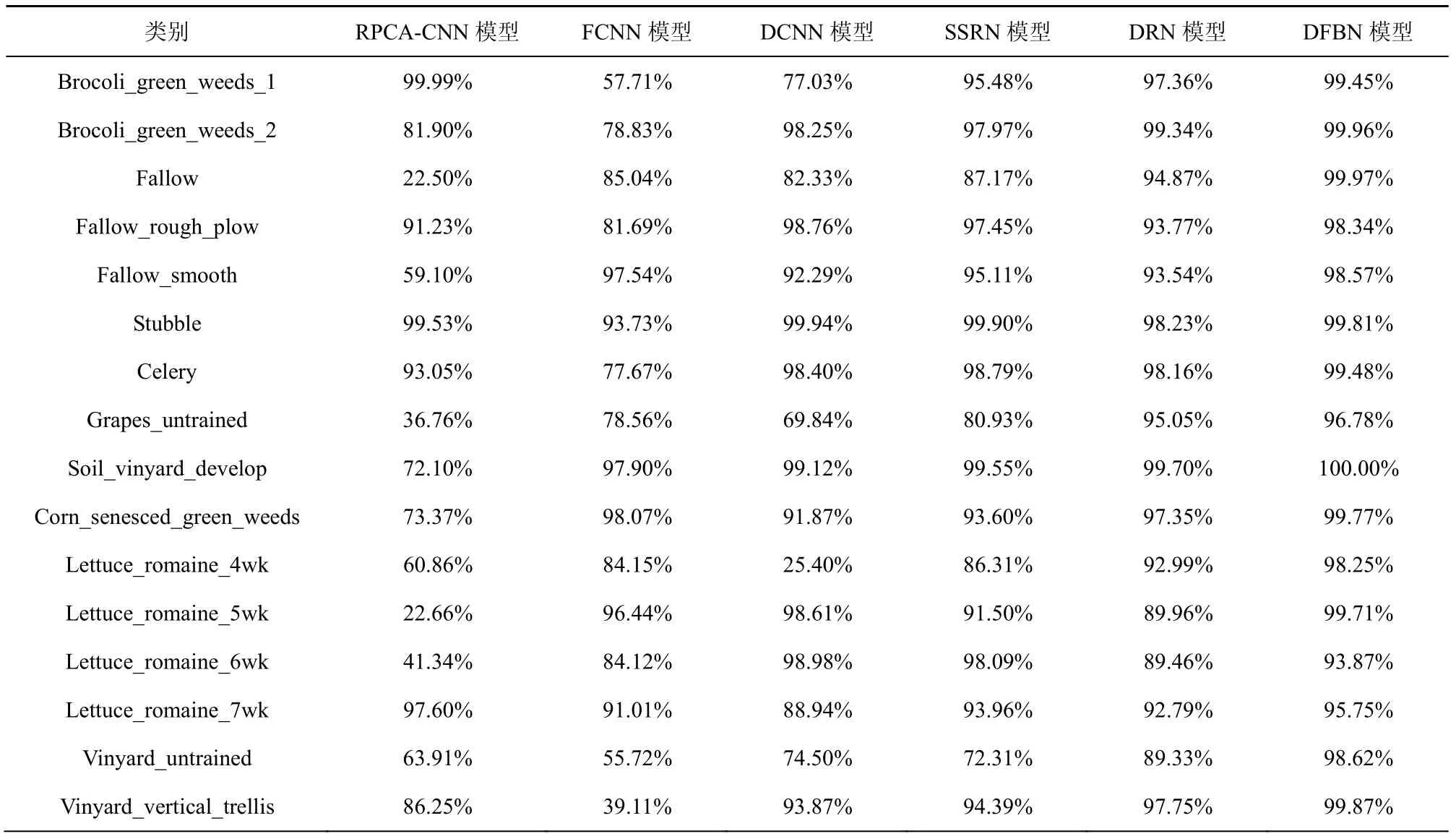
表10 在SA 数据集下与其他分类模型的比较
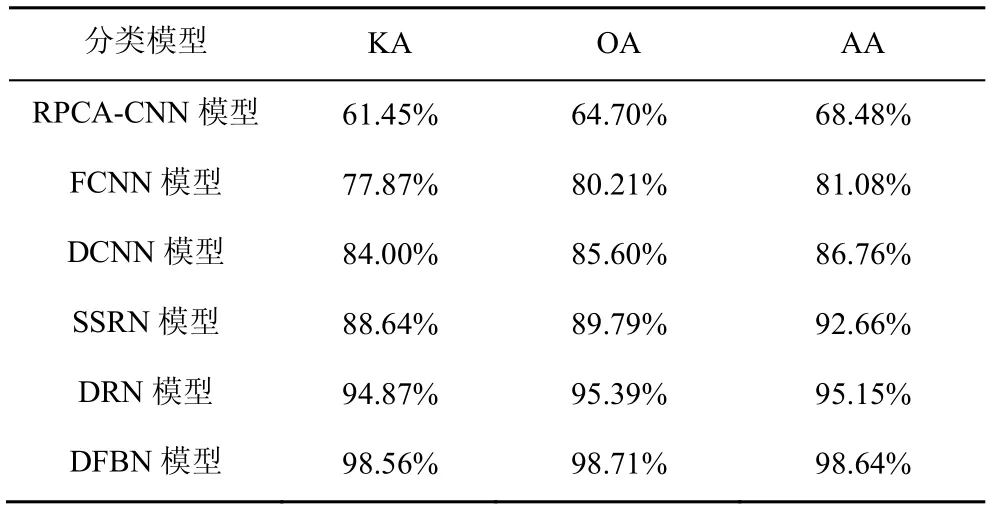
表11 针对SA 数据集的分类结果
4 结束语
本文提出了一种基于卷积神经网络的高光谱图像分类模型DFBN。作为一种新的提取判别特征的模型,它有效克服了空间分辨率下降和特征信息丢失所带来的精度下降问题,此外,它提供了一种新的提取更具代表性判别特征的思路。在3 个真实的HSI 上的实验结果表明,所提模型在分类图的视觉质量和定量指标上均有出色的表现。
虽然双边融合块网络在性能方面非常优异,但仍缺乏对上、下结构所获得的特征图进行权重分配的研究。在未来的工作中,将引入注意力机制,系统地分配2 个特征图占比,进一步提高分类精度。
