基于线程融合特征的Windows恶意代码检测与分析
2020-12-07芦天亮杜彦辉暴雨轩
周 杨,芦天亮,杜彦辉,郭 蕊,暴雨轩,李 默
中国人民公安大学 警务信息工程与网络安全学院,北京 100038
1 引言
恶意代码的种类繁多,主要分为几个大类:勒索病毒、挖矿程序、木马、蠕虫病毒、感染型病毒、后门程序、木马程序等。根据国家计算机病毒应急处理中心的每月计算机病毒疫情分析[1],2019年3月发现新增病毒700余万个,到5 月升至1 967 余万个,到8 月更是发现新增病毒4 791万个。花指令、计算机程序模块化、代码混淆等技术的发展更是大大降低了恶意代码的制作和传播成本。但有专家估计,这些检测到的恶意代码仅不到网络上所有恶意代码的1/2[2],有超过近50%的恶意代码,甚至在出现后的三个月内仍然无法被检测出来[3-4]。面对日益强大的恶意代码生态链,急需更多的研究去分析恶意代码的本质规律,用最具代表性的特点区分恶意代码和正常样本。
按照分析原理对恶意代码分析方法进行分类,通常分为动态分析、静态分析及混合式分析。静态分析无须运行恶意代码,在静态环境下借助工具将二进制文件进行反汇编并对其提取行为数据,常包括函数调用名、文件结构信息、导入表、字符串、控制流等。例如,2014年Shi H B 等人[5]通过提取静态链接库信息,以构建恶意代码样本特征。静态分析方法简明、耗时少,但仅仅只能检测已经识别到的恶意代码,并且对于恶意代码混淆、加壳、干扰、变形等方式束手无策,因此静态分析存在误报率高、检测率低的缺陷。
动态分析恰恰能避免这些缺点,动态分析以一个虚拟环境真实运行恶意代码样本并收集程序执行中的所有信息,沙箱是用于此目的典型系统。在动态方法中生成的常见行为数据类型包括系统调用名称,上下文中的参数、环境变量等。当前许多安全平台及安全专家都使用动态特征来进行恶意代码的分析与检测,龚琪等人用APIs序列[6]、API调用类别特征频繁度[7]等方法在区分勒索病毒和正常样本时都取得了良好的效果。但此类检测方法耗费大量的计算量及计算时间,并且在描述恶意行为的方面仅针对一类病毒,不具有普适性。
动静态结合是将动态特征及静态特征结合作为区分特征,Damodaran A 等人[8]在 2017 年对比了动态、静态及混合分析三种分析方式的效果发现,基于动静态结合的方法不一定优于纯动态分析,因为动静态分析产生特征的天然差别难以进行交叉检验,混淆技术虽然容易破坏操作码序列,但如果不加入其他的针对API序列的混淆,很难对API序列产生影响。
线上恶意代码共享库的泛滥,代码混淆、变形、多态等技术的出现,使恶意代码数量以前所未有的速度暴增,静态分析手段已无法应对。但即使改变了恶意代码的句法结构,绝大多数恶意代码的执行都需要基于Microsoft Windows 提供的多种API 接口,方便调用API以使用来自操作系统的服务[9],实现其恶意任务,动态分析手段可以将恶意代码在虚拟环境中运行,抓取所有API 调用信息及参数。因此应对当前暴增的多种技术混淆、变形的恶意代码环境,动态分析技术显得更有优势。
尽管恶意代码会调用的API类别与正常程序相同,可是这些API 的调用顺序及它们各自的函数返回值不同却表示完全不同的意图、达到完全不同的结果。因此,仅仅关注全局API 调用序列是完全不够的,还要考虑不同API的参数、顺序等因素导致不同的线程完成的功能。由此可见,动态行为特征的界定取决于所选取的行为特征及对行为特征进行的处理。Galal H S等人[9]在2016年提出基于语义的方法使用语义规则或行为判断来深入了解恶意代码行为,给本文提供了思路。本文先在沙箱系统内运行可执行文件,用Python脚本从.json格式的动态分析报告中抽取API调用信息,再以线程为单位将各个函数APIs以时间序列排序,抽取API在函数中的调用时序、返回值等参数,利用统计和计算两种方法构建两种恶意代码特征模型。一类统计特征在API宏观数量上概括恶意代码行为与正常样本的差异;另一类计算特征计算每个API 在线程内的调用情况及各个API 在所属类别中的TF-IDF 值。将两类特征向量化后用改进的Vec-LR 算法进行检验,发现此类特征模型及本文算法在区别正常样本及恶意代码的效果良好,能达到94.37%,而后又采用不同的样本集将本文算法与常见杀毒软件进行比较,发现该模型在检测未知恶意样本时仍然表现良好,检测率在90%以上。
2 行为特征构建
2.1 行为特征收集
本文选用的Cuckoo沙箱[10]是一款用Python语言编写的开源自动化恶意代码分析系统。它可以将未知、不可信的软件隔离执行。Cuckoo 沙箱通过虚拟网络将Host 机 器 与 Guest 机 器 连 接 ,Guest 机 通 过 Cuckoo Agent程序来完成对Cuckoo运行的监控,Host机负责运行Cuckoo 主程序、收集分析报告。Cuckoo 可自动将所有未知软件放在隔离环境中动态执行,并提取其运行过程中的动态行为,例如:文件行为、进程行为、网络行为等,并且Cuckoo 沙箱能够跟踪记录恶意软件所有的调用状况;恶意样本文件行为:例如读取文件、下载文件、创建新文件、修改文件或删除文件等行为;获取恶意软件的内存镜像;以PCAP 格式记录恶意软件的网络流量;在恶意代码运行过程中还能截取系统的屏幕截图;获取执行恶意代码的Guest机的完整内存镜像等。所有截取到的信息,都会以.json 文件的形式生成报告提取在Host机器中。恶意代码样本大小及功能不一,因此在Cuckoo 沙箱中的运行时间也不尽一致,本文选取的样本大小在1 KB~10 MB之间,平均运行时间约为210 s。
2.2 API调用序列构建
传统的恶意代码研究常计算恶意代码API 种类的调用频率,或以全局模式构建API 调用序列,这两种构建方式仅针对一种特征,难以描述恶意代码的行为,并且以全局模式构建API序列,或因数据量限制而无法收集足够多的信息,或因收集信息过多占用过大的空间及时间代价。
进程中的实际运作单位是线程,一个进程内包含一个或多个线程,且线程是CPU 调度的最小单位。进程中的线程并行执行,每条线程都是一条单一顺序控制流,一个进程可并发多条线程以执行不同的任务。API调用顺序以全局模式来看仅仅只能记录API 的调用情况,而不能刻画API 调用序列所完成的任务。API 调用均属于一个函数线程,以线程为单位提取API 调用信息,可以提高信息提取数量级且有一定的分类性。Cuckoo沙箱生成的.json报告中单个API的调用信息包含该函数所属的类别、函数名称、函数操作返回值、函数运行的系统时间及其所属线程等关键参数。
根据API所属线程及时间两个参数,可以时序地提取每个线程的所有API操作,对于API调用超过5 000的线程,按顺序保留前5 000 次调用信息,将每个线程的API以系统时间进行排列。最终保留的信息如表1所示。

表1 文件调用参数
2.3 行为特征提取
若直接使用API 序列[6]作为特征,冗长的序列及序列比对会产生极大的计算量。特征频繁度[7]计算可以解决数据过于庞大导致的计算问题,可样本中大量打开、关闭文件等操作的调用频繁度很高,而此类API不能代表恶意代码的恶意行为,将会影响样本特征区分度。因此本文将构建两类特征:一类统计特征,以解决大量的序列造成的数据量过大的问题,并以统计方式在API调用总数上将恶意代码与正常样本进行区分;另一类计算特征,将计算API 调用的参数作为特征值,并计算每一类API 的TF-IDF 值,以数值的形式直观地提高特征区分性能,借用ONE-HOT一位有效编码的思想将TF-IDF值计算特征向量化,最后以样本编号为主键合并为Data Frame形成本文的行为特征集。
2.3.1 构建统计特征
API统计特征能在API总数上粗略呈现恶意代码及正常样本的行为数量级差异,例如恶意代码在调用API频率、调用线程数量、消耗系统空间及调用参数等方面与正常样本均有区别,统计特征能概括大部分恶意代码及正常样本系统操作频度的不同。统计特征包括API调用数量、类别、线程数量、API返回值等12维统计特征如表2所示。
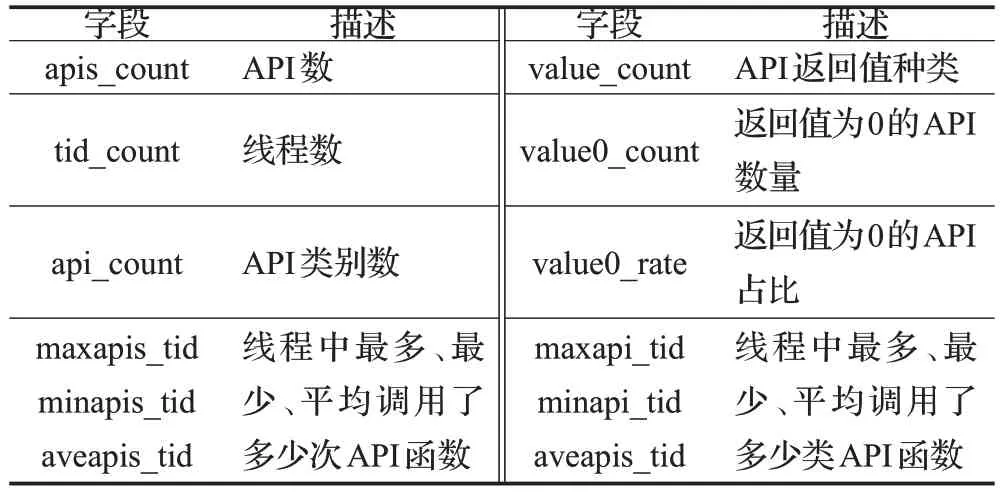
表2 统计特征
2.3.2 构建计算特征
(1)单个API计算特征
CPU中的最小调度单位为线程,线程中某类API的调用频率、调用顺序及返回值,能概括该线程完成的任务并反应该线程在恶意代码操作中的重要性,例如某线程50%以上的API 都在进行读取文件目录及读取文件的操作,该线程完成的任务很有可能是遍历系统文件判断是否处于虚拟机环境并决定下一步的任务进行。API的调用类别也能作为区分正常样本与恶意代码的依据之一,例如Wannacry 病毒在生成随机加密会话密钥或公钥/私钥对时调用的CryptGenKey函数,就是正常样本里很少出现的API 种类。本文中所有正常样本包含的API种类为310种,恶意代码为351种。API统计特征函数返回值为0代表该函数操作正常完成,因此统计线程中该API 返回值为0 的次数及返回值为0 的次数占该API 调用次数的比率有助于分析线程内操作的执行情况及该API在线程内的重要程度。根据2.2节中构建的文件调用参数,计算得出以线程为单位的单个API计算特征如表3所示。

表3 API计算特征
(2)TF-IDF计算特征
API 对于单个线程或单个样本的重要程度不足以作为所属类别样本的分类依据。而TF-IDF值可以评估单个API对于一类样本的重要程度,表示该API的区分力。TF-IDF的主要思想是:若某一类别API在一类样本中的调用频率高,且在其他类别中调用频率低,则判断此类API具有强区分能力,适合用于样本分类。TF-IDF值不论大小均有评判价值,TF-IDF值大则表示此类API在类别区分中具有强区分力,反之TF-IDF 值越小则表示区分力越弱。而TF-IDF 值为0 则表示此类API 未在该样本中出现。
TF-IDF:TF*IDF,TF 表示APIi在样本j中出现的频率,它可表示为:

ni,j是该APIi在样本j中的调用次数,是样本j中API的总调用次数和。但打开文件、关闭文件这一类的API,在某些正常样本中出现的频数也很高,就无法将此类API 作为区分的标准,IDF 值正好能筛减这一类API,IDF表示逆向文件词频,即如果这一类API在正常及恶意样本中出现频率都极高,则该API 的IDF 值极低,反之。它可表示为:

|D|表示样本的总数,j表示包含该API的样本数目。某类API在一类样本中高频调用,且该类API在整个样本集合中低频调用,可以产生出高权重的TF-IDF 值。因此,TF-IDF 值的大小可以表示此类API 的重要程度,TF-IDF越大,则表示该API在类别区分中具有越好的区分度。
2.3.3 特征向量编码
统计特征将形成12 维向量,计算特征将形成6×m维向量,其中6为表3中的5类计算特征及TF-IDF值,共6类计算特征;m表示所有样本调用的API种类数。将统计特征及计算特征以样本编号为唯一主键进行合并,将生成6m+12 维向量作为样本特征向量。
3 Vec-LR算法
LR算法采用sigmoid函数做分类,由于该函数值域为(0,1)。因此最基本的LR分类器适合于对二分类(类0,类1)目标进行分类。函数形式为:

由式(3)可见决定函数值域的关键变量为Z,将Z权值化代入Logistic函数中构造出预测函数,为:

判别新样本需要计算出一个Z值,经典的LR算法使用梯度下降函数,计算出的θ更新过程为:

式中,i表示样本序号,j表示属性序号,α表示步长,该公式将一直被迭代执行,直到函数值收敛。
LR 算法使用梯度下降函数进行迭代来计算θ更新,需要一个for 语句循环m次,没有完全地实现向量化。改进的Vec-LR 算法中的Vectorization 向量化使用矩阵计算来代替for 循环。X矩阵的每一行为一个训练样本,而每一列为单个样本不同的特称取值。下面为向量化过程:

θ的更新过程可以改为:

至此α的取值变成了梯度下降的关键点,要确保梯度下降算法正确运行,需要保证θ在每一步迭代中都减小。α的取值判断准则是:如果θ变小了表明取值正确,否则减小α的值。
4 实验及结果
4.1 实验数据及实验环境
本文选取Windows 恶意代码及正常样本作为实验对象,恶意代码来自全球www.malware-traffic-analysis.net公开网站[11]。共收集4 000多个恶意代码样本,其中7类已知及1 类未知样本;正常样本数据集来自360 官方下载安装包,根据样本大小及使用比例共收集了10类软件(例如:办公软件、驱动工具、图形图像、音频视频等,共计1 400 个)在投入沙箱运行之后,经过筛选留下1 100个恶意代码样本及1 079 个正常样本的.json 文件,为了保证正常样本数量和恶意代码样本数量平均,本文最终保留恶意代码及正常样本各1 000个.json文件作为实验数据。正常样本及恶意样本的类别及数量如表4所示。

表4 实验中所使用的样本
为保证数据处理环境及沙箱运行环境互不干扰,本文将数据分析系统与沙箱环境系统分别搭在两台电脑上,系统环境参数如表5。

表5 实验环境
4.2 实验结果
4.2.1 与常见算法比较
通过上述特征提取方式,生成特征向量,转化为Data Frame的格式,数据为:其中m为特征的维度,N=2 000 为恶意代码样本与正常样本总和,yi为样本类别,共有0(正常)、1(恶意)两种。使用本文算法进行处理分类,并与SVM、Random Forest、Decision Tree进行比较,检测模型的性能。评估参考值包括检测的准确率、召回率、F1 值[12-13]、模型运行时间、分类器ROC曲线及AUC面积。
从表6中可见,以上四种分类器的准确率最低值为89.74%,通过计算得平均检测率为91.9%。可见本文的特征选择方法在恶意代码与正常样本的检测中有良好的效果。其中Vec-LR 算法准确率最高,达到94.37%,在召回率、F1 值上,Vec-LR算法均优于其他算法,分别达到92.61%和93.57%。使用向量化代替for 循环的Vec-LR 算法在时间消耗方面也取得较好成绩,为8.82 s。可见本文的模型选择在同类分类方法中也具有良好效果。ROC曲线是比较分类器综合性能优劣的直观表现形式[14]。ROC 曲线越靠近坐标左上角则表示分类器的准确性越高。本文实验中分类器的ROC曲线如图1、图2所示。

表6 实验结果数据
由图1、2可见通过检测本文构建特征,各算法的综合效率都较高,而所有算法中Vec-LR 算法效果最佳。ROC曲线的横坐标表示假阳性率(False positive rate),纵坐标表示真阳性率(True positive rate),分类器ROC曲线与X轴围成面积值为AUC,AUC面积值大小表示分类器性能的好坏,AUC 面积是常见的衡量二分类模型优劣的指标之一,可展示分类器整体性能[15]。表7 是本文实验中的AUC面积比较。

图1 分类器ROC曲线图

图2 分类器ROC曲线局部图

表7 实验结果ROC曲线AUC值
AUC面积充分展示了分类器的整体性能,从表7得知 Vec-LR 算法性能最佳,AUC 面积值为 0.985 6,其次为Random Forest。
4.2.2 与常见杀毒软件比较
实验2另取一组不与实验1重复的Windows恶意代码样本。计算所有样本在Virus Total 上的平均检测率Rˉ ,Rˉ=M/A,其中,A为Virus Total 上所有杀毒软件的总数,M为杀毒软件检测为恶意样本的计数。从中取一组M为1 000 的未知类别恶意代码样本。其中Rˉ为0.2。将该组样本使用Vec-LR进行检测,并与杀毒软件 McAfee、F-Port、ClamAV、Trend、Symantec 进行比较。本文算法及市面上各厂商的检测率结果如表8 所示。通过对比发现,当Rˉ值为0.2即大多数检测软件无法判断该病毒时,本文算法仍然具有较好的检测率为92.6%,说明本文算法在应对新生或未知恶意代码的识别上仍优于其他软件。

表8 与常见杀毒软件对比实验结果
5 结束语
本文在恶意代码分析方法中选择了动态分析方法,使用Cuckoo 沙箱进行了细致的恶意代码行为捕捉,在特征提取阶段,本文以线程为单位,每线程抽取前5 000个API函数,保证每个样本的特征都在万级以上。特征处理阶段,本文采用统计特征及计算特征两类特征以最小代价捕捉恶意代码特征。在计算特征里,本文还引用在自然语言处理性能较优的TF-IDF 值帮助概括每个API的区分能力。在分类器的构建和选择上,本文选择适用于二分类的LR算法,并用Vectorization向量化进行了改进,实验的最后本文实验获得了较好的效果。比起之前的模型,本文在检测恶意代码及未知样本中的检测率均有提升。不足之处在于前期的沙箱运行及恶意代码特征抽取阶段耗费大量的时间。
基于本文的实验结果,将继续细化强化改进本文的抽取提取方式。后期将尝试在本文基础上对样本进行多分类的训练,进行深度学习算法的引入,降低实验的时间复杂度,进一步提高实验准确率。
