基于强化学习的应急通信研究
2020-12-07朱连伟
朱连伟
(安徽工业大学管理科学与工程学院,马鞍山243032)
0 引言
随着通讯技术的发展和科技的进步,互联网已经深入到了人们生活的各个角落,而且随着拥有高宽带、低时延、多点连接特点的5G 网络的出现和应用,人们在现在的生活在越来难以离开通信网络。所以当遇到自然灾害导致通讯设施毁坏时,这对受灾区域人们的生活和营救人员的通讯都会造成很大的影响,虽然现在有通讯卫星、通讯车和通讯气球可以用于灾害区域的紧急联络,但是都会有着通讯范围、传输数据量和使用时等问题之中的一个或者多个问题。所以怎么解决灾害区域的通信问题是在移动网络研究中一个比较重要的问题。
而在应急通信中,国际上通常使用的手段时使用空中平台中继通信,而且空中平台中继通信可以很好地解决在地形复杂区域的信号覆盖问题[1]。无人机拥有机动性好、生存能力强、部署迅速的特点,将无人机当成空中平台中继通信应用在灾害区域用于应急通信和救灾指挥具有着重要的实际意义和应用前景[2]。
强化学习就是学习“做什么才能使得数值化的收益信号最大”,学习者不会被告知应该采取什么动作,而是必须自己通过尝试去发现那些动作会产生最丰厚的收益。强化学习最大的特点就是考虑的是长期收益最大化,即目标是最优解,所以使用强化学习的理论和模型对以无人机为中继通信节点的问题进行建模,从而找到研究问题中的最优解。
1 强化学习
1.1 强化学习要素
在强化学习中,除了采取学习行为的智能体和智能体所处的环境之外,强化学习系统还有以下几个子要素:策略、回报信号、价值函数以及可选的环境模型(Model-Free or Model Based)。
(1)策略(Policy):定义了一个特定时刻智能体的行为方式,一般用π 表示。简单来说,策略是一个从当前感知到的环境状态到该状态下采取的动作的一个映射。它对应于心理学中被称为“刺激-反应”的规则或关联关系。在某些情况下,策略可能是一个简单的函数或者是一个查找表,然而在其他情况下,也可能涉及大量的计算,例如搜索过程。策略本身是可以决定行为的,因此策略是强化学习智能体的核心。一般来说,策略可能是环境所在状态和智能体所采取的动作的随机函数。
(2)回报信号(Reward):定义了强化学习问题中的目标,一般用R 表示。在每一步中,环境向强化学习智能体发送一个称为收益的标量数值。智能体的唯一目标就是最大化长期总收益。因此,收益信号是改变策略的主要基础,如果策略选择的某个动作导致了一个低的回报,那么这个策略可能会改变自己以便于在将来相同的情景下获得更多的回报。
(3)价值函数(Value Function):表示从长远的角度看什么是好的,简单地说,一个状态的价值是一个智能体从这个状态开始,对将来累积的总收益的期望,一般用vπ(s)表示。尽管收益决定了环境状态直接、即时、内在的吸引力,但是价值表示了接下来所有可能状态的长期期望。
(4)环境模型:这是一种对环境的反应模式的模拟,或者更一般的说,它允许对外部环境的行为进行推断。例如,给定一个状态和动作,模型就可以预测外部环境的下一个状态和下一个收益。环境模型会被用于做规划。使用环境模型和规划来解决强化学习问题的方法被称为有模型方法。而简单的无模型方法就是直接的试错,这与有目标地进行规划恰好相反。
1.2 强化学习的基本学习过程
图1 解释了强化学习的基本过程。进行操作的主体来做决策,即选择一个合适的动作(Action)At。而系统(环境)有自己的状态模型,我们选择了动作At后,环境的状态(State)会变,我们会发现环境状态已经变为St+1,同时我们得到了我们采取动作At的延时奖励(Re⁃ward)Rt+1。

图1 强化学习过程
在上面介绍强化学习的基本原理中涉及以下到几个强化学习的要素。
首先是比较简单地三个:环境状态S,t 时刻环境的状态St是它的环境状态集中某一个状态;个体的动作A,t 时刻个体采取的动作At是它的动作集中某一个动作;环境的奖励R,t 时刻个体在状态St采取的动作At对应的奖励Rt+1会在t+1 时刻得到。当有给定策略的时候,一般会计算累积回报,计算公式如下:

其中γ是奖励衰减因子,在[0,1]之间。如果为0,则是贪婪法,即价值只由当前延时奖励决定,如果是1,则所有的后续状态奖励和当前奖励重要性一样。大多数时候,我们会取一个0 到1 之间的数字,即当前延时奖励的权重比后续奖励的权重大。
其次是个体的策略π,最常见的策略表达方式是一个条件概率分布π(a|s),即在状态s 时采取动作a 的概率。即π(a|s)=P(At=a|St=s)此时概率大的动作被个体选择的概率较高。
最后是个体在策略π和状态s 时,采取行动后得到的价值(value),一般用vπ(s)表示。这个价值一般是一个期望函数。虽然当前动作会给一个延时奖励Rt+1,但是光看这个延时奖励是不行的,因为当前的延时奖励高,不代表到了t+1,t+2,...时刻的后续奖励也高。因此我们的价值要综合考虑当前的延时奖励和后续的延时奖励。价值函数vπ(s)一般可以表示为下式:
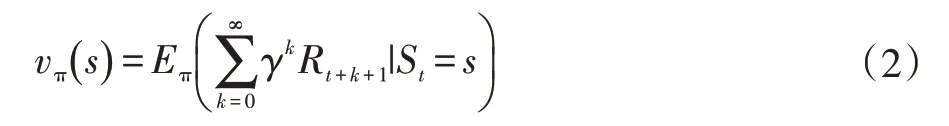
强化学习的基本方法就是通过智能体与环境的多次交互进行多次学习,然后根据学习到的收益来更新相关的价值函数,理想情况是通过多次学习来获取一个真实的价值函数,也就是最终获得最优的结果。
2 强化学习在无人机应急通信中的应用
2.1 应急通信的发展状况
目前世界上的应急通信方式基本有三种,分别是应急通信车、通信卫星和通信气球,而应急通信车可以将突发事件产生地点的声音图像传给指挥中心,同时还可以通过应急通信保障指挥系统保障通信[3]。通信卫星可以在灾害发生第一时间获取灾区信息,同时也可以将信息送至相关部门,同时还可以对灾区的即时情况进行跟踪,保障灾区和外界之间的通讯和联络[4]。卫星通信虽然在应急通信中有很大的优势,但是卫星通信往往需要专用的通信设备(例如卫星电话),所以很难大规模应用[5]。所以,许多国家也十分重视应急信息无线电发布系统的研发工作[6],国际上许多标准化组织也在从事相关标准的研究。而且无线电发布系统需要一定的通信设施。这也就导致在通讯设施损坏的灾区很难使用。
虽然国内外对与应急通信都有很多研究,但是这些研究在无基础通信设施的情况下效果并没有达到十分好的结果,所以很多研究人员提出了基于无人机的应急通信网络研究[7]。其中有结合智能手机的蓝牙功能和Wi-Fi 功能来构建临时的mesh 网络,并通过mesh 网络来将灾区的受灾信息已分布式的方法储存在网络节点,最后通过无人机将这些存储的信息传送给相关的部门以支援灾区救援[8]。
由于无线自组网应用在应急通信的时候可以为救灾工作提供方便、稳定和灵活的通信服务[9],所以将无人机应用于应急网络的同时使用自组网来代替毁坏的通信设施,这两者结合应该会有较好的结果。因此可以使用无线自组网来代替损坏的通讯设施来接收灾区的数据,然后通过无人机来将自组网络中的数据转发给附近的基站从而实现与外界网络的联系。
2.2 强化学习在无线通信的应用
强化学习是机器学习的一种,也是通过反复训练来得到一个好的结果,强化学习的特点就是在智能体与环境交互后获得的收益来更新策略,目标是最大化最终收益,所以对于无线通信网络,强化学习可以应用到路由协议上面,例如通强化学习方法来学习得到当前网络状况下最好的数据传输路径[10],这里作者将无线传感器网络当做环境,然后将节点当成智能体,节点根据数据的优先级、与邻居节点之间的链路质量等信息选择路由,然后或得一个收益,最后通过强化学习得到一个较优的路由路径。也有不少研究者将强化学习用于无线电动态频谱分配,例如将强化学习用于学习引擎,通过采取动作获取的收益值来认识动作策略对于环境的影响,其中有用来学习信道状况,收益是吞吐量和分组成功传输功率,所以最大化收益能够增强网络的性能。同时文献中提到了强化学习在动态信道的选择上有以下优势:强化学习帮助用户适应于不确定的动态的环境,还有就是可以让操作环境和信道的异构性的复杂度可以最小化[11]。本文关注的是使用路由器搭建自组网络,然后将无人机当成移动基站来收集和转发来自网络中的数据达到和外界联通的效果。这种模式拥有布置速度快和灵活性高的优点,而引入强化学习后,可以通过强化学习去寻找使得当前条件下效果最好的一条无人机的移动路径。
2.3 无线网络生存时间最大化
如图2 所示的网络模型,其中地面部分是由N 个路由器组成的无线自组网络,主要功能是为用户提供数据传输服务。而天空中的无人机则是充当一个移动基站,负责将无线自组网中的数据传输给远程的基站,从而实现用户和外界的通信。这种网络模型的特点是无线自组网布置便捷快速,在受灾区域能够快速搭建起临时网络,而且无人机是一个空中的移动基站,受地面环境影响较小。同时由于路由器在灾区布置时会存在能量的限制,所以研究的方向是利用无人机的移动性来延长路由器网络的生存时间。在强化学习中,无人机就是强化学习中的智能体,而无线自组网络就是强化学习中的环境,而智能体在每一步中选择动作也就是无人机决定下一步飞的方向,这个方向可以是连续的,也就是在无人机所处的平面随意选择方向移动,这是一个连续的动作空间,但是也可以将空间简单地离散化,例如只有四个方向东、南、西、北,或者更加的细化,无人机选择移动方向和环境交互产生的收益就是网络的生存时间,无人机移动的最终目标就是使得无线自组网络的生存时间最大化,即通过强化学习的方法来学习得到一条无人机的移动路径,使得地面的无线自组网络生存时间最大。

图2 网络模型
3 结语
本文介绍路由器组成的无线自组网在应急通讯中的优势,并且可以用无人机作为移动基站来优化无线自组网的生存时间。对如何选择无人机的路径方面提出了使用强化学习方法,无人机也就是强化学习中的智能体通过学习得到一条移动路径从而使得网络的生存时间最大。
