基于Corr-LDA-ITD模型同时做图像分类和标注
2020-12-04罗菊香
罗菊香
(江西服装学院 物联网工程教研室,江西 南昌 330000)
0 引言
随着图像数据的海量增长,图像分类和标注也伴随着相应的挑战[1]。近年来,科研人员提出了各种各样的方法[2-3],图像分类与标注的研究也越来越受到学术界关注。
Corr-LDA模型是图像标注的经典模型,大量的研究工作都是基于此模型进行改进[4],有学者提出了标注性能更好的Corr-LDA-ITD模型,本文在Corr-LDA-ITD模型的基础上提出了一个同时做图像分类和标注的概率主题模型(Corr-LDA-ITD-P模型)。同时基于变分EM算法推导了模型参数以及给出了该模型分类和标注图像的方法,并在真实数据集上对模型的分类和标注性能进行了验证。
1 Corr-LDA-ITD-P模型同时做图像分类和标注
1.1 Corr-LDA-ITD-P模型概率图
Corr-LDA-ITD-P模型的概率如图1所示。
1.2 Corr-LDA-ITD-P模型参数求解注
利用变分EM算法求解参数[5],在E步骤中算得后验Dirichlet参数γ,参数φ,参数ρ分别为:
(1)
(2)
(3)
经过E步骤之后然后在M步骤中计算模型参数π,β,α,μ分别为:
(4)
(5)
本文没有对α进行优化,多次实验发现,将α设置成全为1的向量,模型性能较好。
(6)
由于这个解不是封闭的,本文用共辄梯度法来优化μ[6]。重复执行E,M步骤,直到收敛。
1.3 Corr-LDA-ITD-P模型对图像分类与标注
(7)
提出模型经过训练集数据学习之后,确定模型的参数,使用该模型对新图像预测标注词。选取概率较大的前几个标注词作为图像的标注,具体标注公式如下:
(8)
2 实验结果与分析
为评估Corr-LDA-ITD-P模型的分类和标注性能,本文在LabelMe真实数据集上进行相关实验。
LabelMe数据集含8类图像,包括“海岸”“森林”“高速公路”“城市”“高山”“乡村”“街道”“高楼”。每类包含200幅图像,共1 600幅图像。图像特征提取过程采用网格抽样技术,从每一个网格中心抽取一个大小为16×16的区块,然后用128维的sift描述子进行描述,利用k-means算法对所有的sift描述子进行聚类,构成240个图像码书。同时移除出现次数少于3次的标注词,构成294文本码书。
3 数据集分类性能
为评价Corr-LDA-ITD-P模型分类性能,本文将Corr-LDA-ITD-P模型与Mc-sLDA[6],Mca-sLDA模型进行比较。实验过程中选择主题数为20~120,6组主题进行比较。随机抽取每类图像的一半作为训练集,剩下的作为测试集,随机抽取5次,进行5次实验,计算5次实验分类和标注的正确率平均值。实验根据公式(7)对图像进行分类,选取概率最大的标签作为类标签。实验结果如图2所示。
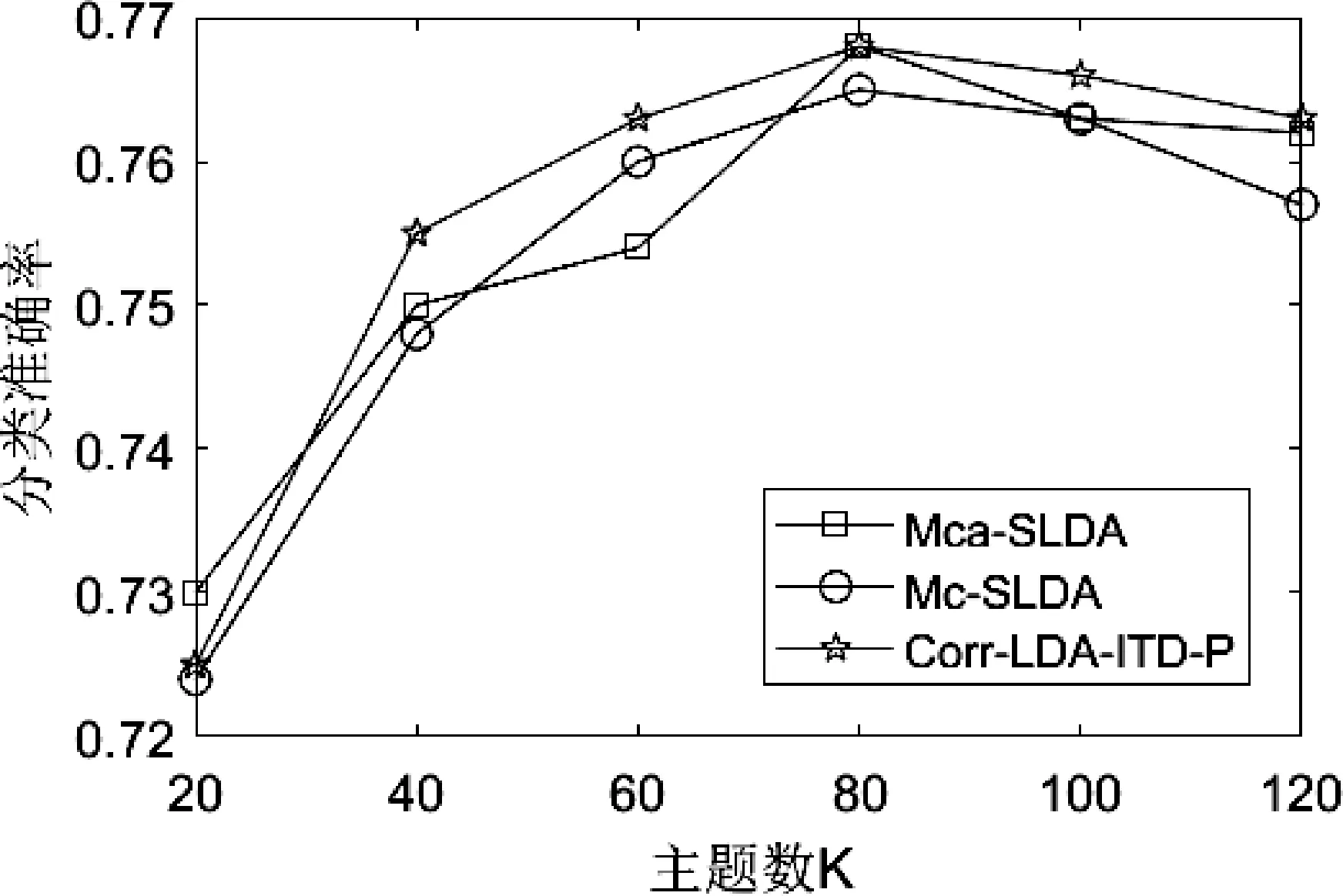
图2 LabelMe数据集上分类性能比较
图2是数据集上分类性能比较。从LabelMe数据集上实验结果可知,提出模型在K=80的时候表现了76.9%的最好性能,在K=40,60,80,100,120的时候,表现了分类性能要优于相比较模型。
4 数据集标注性能
为了评价P-Mca-sLDA模型的标注性能,本文将P-Mca-sLDA模型与Corr-LDA 模型、Mca-sLDA模型进行比较。实验过程中选择主题数为10~110,11组主题进行比较。随机抽取每类图像的一半作为训练集,剩下的作为测试数据,随机抽取5次,模型进行5次实验,计算了5次实验F-measure的平均值。实验根据公式(8)对图像进行标注,选取概率大的前5个词作为标注词。实验结果如图3所示。

图3 LabelMe数据集上标注性能比较
图3是数据集上值的比较。从LabelMe数据集上实验结果可知,模型在K=50的时候表现出了40.5%的最好标注性能。在K=10,20,30,40,60,70,80,90时,表现出了模型的标注性能要优于相比较模型。
