基于天气数据对空气质量预测的改进KNN算法
2020-12-02郑茂波孟佳俊鲁越
郑茂波 孟佳俊 鲁越


摘 要:基于天气数据进行空气质量预测,首先收集成都市A区2018年4月1日到2018年6月3日64天24个天气属性,然后对天气属性进行筛选、数据处理;接着,建立KNN分类模型,利用k折交叉验证和多数表决原则对64个样本进行分类;最后在传统KNN分类模型的基础上,使用反距离加权建模,结果表明模型有较好的泛化能力和预测效果。
关键词:天气数据;空气质量;k折交叉验证;反距离加权;KNN算法
中图分类号:X823 文献标志码:A 文章编号:2095-2945(2020)34-0037-03
Abstract: This paper forecasts air quality based on weather data. 24 weather attributes from April 1, 2018 to June 3, 2018 are collected from April 1, 2018 to June 3, 2018. Then, the KNN classification model is established, and 64 samples are classified by k fold cross verification and majority voting principle. Finally, on the basis of the traditional KNN classification model, the model is established by inverse distance weighting, and the results show that the model has good generalization ability and prediction effect.
Keywords: weather data; air quality; k fold cross verification; inverse distance weighting; KNN algorithm
引言
近年來,由于能源消耗的不断增加,空气污染日益加剧,空气质量问题已经严重影响到人们的正常生活,各种呼吸道疾病频发。空气污染不仅对人类的身体健康造成了极大的损害,还对生态环境造成了严重的负面影响。2018年7月,国务院颁布了《打赢蓝天保卫战三年行动计划》,明确四个“明显”主要任务:明显降低细颗粒物(PM2.5)浓度、明显减少重污染天数、明显改善空气质量和明显增强人民的蓝天幸福感。因此,进行空气质量预测,为当地政府及时提供信息,避免严重空气污染事故的发生是很有必要的[1]。
针对大气质量的计量分析和预测,刘杰等[2]提出应用支持向量机和模糊粒化时间序列相结合的方法,对PM2.5质量浓度未来变化趋势和范围进行预测;杨锦伟等[3]基于马尔科夫模型建立了空气污染物浓度预测模型;陆志涛等[4]基于RAM扩展模型构建了评估空气质量状况的空气质量指数以及评估空气质量提升空间的空气质量发展指数,并将其应用于我国城市空气质量的评价研究;贺金龙等[5]运用灰色系统理论建立污染物GM(1,1)预测模型,实现了对北京市环境污染情况的预测;姜孪娟等[6]以江苏省为例,提出一种基于BP神经网络的空气污染预测模型。
综合上述文献可以看出,学者们从不同的角度,采用不同的方法,对大气环境进行评价。本文将传统KNN分类算法进行改进,对成都市A区2018年64个样本进行反距离加权、采用循环寻找最佳的K,并利用14个天气属性数据值进行空气质量的预测。
1 数据来源及处理
1.1 天气数据
从中国气象数据网(http://data.cma.cn/site/index.html)获得成都市A区2018年4月1日到2018年6月3日每天的天气数据,共64组样本数据,每组样本数据包含24个属性。
1.2 空气质量数据
从成都市环境空气质量发布系统(http://182.150.31.86:9875/Default.aspx)公开获取对应时间的空气质量指数(AQI),根据环境空气质量指数(AQI)技术规定(试行)的标准[7],对应不同的空气质量类别,如表1所示。
表1 空气质量指数
1.3 数据处理
1.3.1 数据筛选
去掉天气数据的24个属性中跟空气质量关系不大和主观的定性的属性数据,即去掉现在天气、风力、体感温度、水平能见度、总云量、云量、低云量、2分钟平均风向(角度)、最大风速的风向、极大风速的风向共10个属性。
1.3.2 数据整理
获取的天气数据都是以小时为单位,而空气质量数据(AQI)是以天为单位,所以先要对天气数据进行处理,对余下的14个不同属性数据采用了以下方法:
(1)取累加和:降水量
(2)取最大值:最高气温、最高气压、最大风速、极大风速
(3)取最小值:最低气温、最低气压、最小相对湿度
(4)取平均值:气压、海平面气压、温度、2分钟平均风速、相对湿度、水汽压
2 KNN模型
2.1 KNN模型原理
KNN算法的基本原理是通过选取K个离测试点最近的训练样本点,并输出这K个样本点中数量最多的样本标签即多数表决原则,从而得到测试点的类别。
假设每一个训练样本有n个特征值,那么每一个样本都可以用一个n维行向量表示:X(x1,x2...xn),样本点的每一个样本所属的类别均已知,同样,每一个测试点样本也可以表示为:Y=(y1,y2...yn),要实现KNN算法,需要计算出每一个样本点到测试点的距离,然后选取距离最近的K个样本,获取K个样本中每一个样本的类别标签,再找出K个样本中数量最多的标签即多数表决原则,最后返回该标签并获得最后测试样本类别结果。
2.2 数据标準化
本文采用最大值最小值标准化,使所有数据均处于[0,1]区间内,新的数据值?自′等于原始值?自与最小值?自min的差除以最大值?自max与最小值?自min的差,即:
?自′=(1)
2.3 距离公式
针对天气数据的特点,采用欧氏距离来测定样本相似度,则距离d为:
d=?自′?自′2(2)
2.4 k-折交叉验证
(1)首先将前50组样本数据作为训练集,剩下的14组样本数据作为测试集。
(2)增强模型的泛化能力,对50组样本数据采用k-折交叉验证(注:与KNN算法的K不一样),即将训练集平均分成k等分,每次将其中的k-1组样本数据作为训练,剩下的1组样本数据作为验证集,一共进行k次,取k次的平均正确率来验证模型。考虑到每组的样本数据的数量,本文取k=5,即将训练集分成5组,每组为10个样本数据。
2.5 多数表决原则
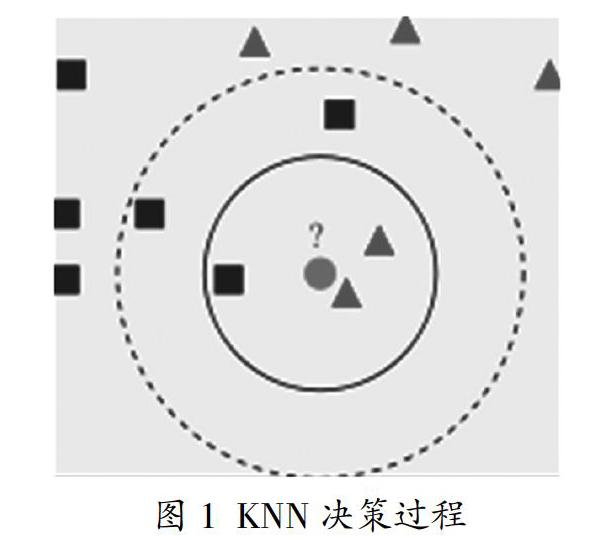
图1中,圆圈要被决定赋予哪个类,是三角形还是四方形?如果K=3,由于三角形所占比例为2/3,圆圈将被赋予三角形那个类,如果K=5,由于四方形比例为3/5,因此圆圈被赋予四方形类。
以2.1-2.5建立的KNN模型称为模型一。
3 模型的改进和结果
3.1 反距离加权
如图1所示,内环的两个三角形对圆圈的影响是不是一样的?从相似的角度出发,两个样本距离越近,说明属性越相似,也就是类别更接近。所以,在多数表决原则的基础上,需要对不同距离的样本给出权重,距离越近,所占权重越大。选取反距离加权,记权重系数为w,则
w= (3)
其中?姿表示待定常数,是为防止d过小导致的w趋于无穷大,以此建立模型称为模型二。
3.2 K值的选择
在模型训练中,以2.4中的k-折交叉验证的分类平均正确率为目标,采用循环搜索,寻找最佳的K和?姿。
3.3 模型结果
模型得到的训练参数和分类结果见表2。从表2可以看到,在训练集,模型二比模型一的分类正确率只有少许提高;但是在测试集却有大幅度提高,这说明模型二较模型一有效。同时模型二的测试集的正确率高于训练集,说明模型二有不错的泛化能力。
3.4 模型结果的分析
上述模型的正确率都在70%左右,分析结果主要有以下两个原因:
(1)样本数据集较少:总共只有50组训练样本,造成训练不足以致影响正确率。
(2)样本不均衡:分析50组训练样本发现大多数标签(即AQI分类)集中在第Ⅱ,III类,其它类别较少。
4 模型评价
采用传统的KNN算法,效果不佳,并且泛化能力弱,采用反距离加权的KNN算法,明显提高了模型的分类正确率。同时,使用k-折交叉验证可以有效提高模型的泛化能力。
下一步研究考虑的方向:
(1)搜集的样本数据集的数量足够且保持均衡。
(2)样本属性数据的处理:当样本属性数量较多时,不同属性的重要程度也不是一样的,可以考虑属性加权或者是采用主成分分析进行降维处理。
参考文献:
[1]CHEN Y,SHI R,SHU S,et al.Ensemble and enhanced PM10 concentration forecast model based on stepwise regression and wavelet analysis[J]. Atmospheric Environment, 2013,74:346-359.
[2]刘杰,杨鹏,吕文生,等.模糊时序与支持向量机建模相结合的PM(2.5)质量浓度预测[J].北京科技大学学报,2014,36(12):1694-1702.
[3]杨锦伟,孙宝磊.基于灰色马尔科夫模型的平顶山市空气污染物浓度预测[J].数学的实践与认识,2014,44(2):64-70.
[4]陆志涛,周鹏,吴菲.基于RAM拓展模型的我国城市空气质量评价[J].环境经济研究,2017,2(2):93-107.
[5]贺金龙,吴晟,周海河,等.基于GM(1,1)-PCA的环境预测与分析研究[J].信息技术,2018(1):105-109.
[6]姜孪娟.BP神经网络算法在空气质量预测中的应用——以江苏为例[J].信息与电脑:理论版,2018(24):69-70,73.
[7]生态环境部.环境空气质量指数(AQI)技术规定(试行)[EB/OL].中华人民共和国生态环境部,2012-03-02[2019-8-24].http://www.gov.cn/zwgk/2012-03/02/content_2081374.htm
