结合核相关滤波器和深度学习的运动相机中无人机目标检测
2020-12-02梁栋高赛孙涵刘宁钟
梁栋,高赛,孙涵,刘宁钟
1.南京航空航天大学 计算机科学与技术学院,南京 211106 2.模式分析与机器智能工业和信息化部重点实验室,南京 211106 3.软件新技术与产业化协同创新中心,南京 211106
对于快速运动的小型无人机,在检测时有两个挑战:① 无人机与相机的相对快速运动,容易产生成像运动模糊,导致无人机外观特征改变或丢失;② 小型无人机或者距离较远的无人机,其外观特征不明显,容易与飞鸟等类别产生混淆。
在视觉检测问题中,以Faster RCNN(Regions with CNN feature)[1]为代表的两阶段检测方法准确率高于以YOLO(You Only Look Once)[2]和SSD(Single Shot MultiBox Detector)[3]为代表的单阶段检测方法。两阶段检测方法首先提取出候选区域,然后对候选框进行分类和回归。因此,通常两阶段检测方法比单阶段检测方法运算速度慢。RetinaNet[4]作为单阶段检测方法,采用Focal loss损失函数,有效解决了类不平衡带来的准确度低的问题,同时也保持了较高的检测速度。
在视觉跟踪问题中,跟踪主要有判别类和生成类两种跟踪方式。核相关滤波器(Kernelized Correlation Filters,KCF)[5]是一种典型的判别类跟踪方法。初始化KCF时,由目标区域生成循环矩阵,利用循环矩阵在傅里叶域可对角化的性质,将空域上的卷积运算转化为频域上的相关运算,以此持续修正跟踪框位置。该方法巧妙利用了循环矩阵对角化特性,大幅降低了计算量,提高了跟踪速度。
然而,对于小型无人机的检测任务,由于目标微小、观测距离远、背景复杂且运动速度快,常出现外观信息缺失和运动模糊的问题,现有目标检测方法往往难以确保无人机目标的逐帧检测[6-9]。而对于上述情况,目标轨迹的持续跟踪可以弥补目标检测的不足。然而,现有目标跟踪算法的不足在于,对下一帧目标的位置点估计通常局限于指定邻域范围内。一旦无人机和相机的相对快速运动导致了下一帧目标所在位置偏移过大时,将产生错误的跟踪结果。因此,需要对场景进行运动补偿或者对无人机进行重定位,以避免跟踪错误。
文献[6-7]首次针对运动相机下的无人机检测问题开展了专门研究。利用在视频帧序列中的运动信息提取出时空立方体[10],进一步筛选时空立方体中的候选区域,再对目标候选框进行类别分类和轨迹回归。在候选框轨迹回归时,引入了运动补偿机制,增强了回归器的精度和鲁棒性。上述工作的实验结果表明,帧间运动信息的有效引入对无人机检测算法的性能提升至关重要。
本文提出了RetinaNet与KCF结合的无人机检测算法[11-12]。KCF跟踪轨迹提供帧间目标运动信息,利用跟踪轨迹抑制RetinaNet检测器的虚警率,跟踪结果同时弥补RetinaNet漏警而造成的目标丢失。另一方面,RetinaNet检测结果间歇性提供可以持续修正跟踪结果。针对观测场景中小型无人机或者距离较远的无人机其外观特征不明显的问题,在RetinaNet模型中引入低层特征信息,弥补高层特征层所忽略的图像细节,使RetinaNet对小目标具有更强的检测能力。针对KCF在特定场景下不适用的问题,引入对观测场景纹理自适应的相机运动补偿策略选择对相机进行运动补偿或对无人机重定位,增强了跟踪器在极端场景下的鲁棒性。
1 相关工作
1.1 RetinaNet目标检测器
RetinaNet采用单阶段检测器[3,13-14]的思想,考虑到检测精度和速度的均衡,主干网络选用深度残差卷积神经网络ResNet[15]中的ResNet-50网络结构。由于卷积运算过程中特征层的尺寸随着网络层的增加而减小,高层特征更注意全局信息而低层特征更注意细节信息。此方法采用高低层特征融合的特征金字塔结构,并在多层特征图后接目标类别分类和检测框位置回归2个子网络,使该检测模型具有多尺度检测的能力。
传统的两阶段目标检测算法在分类和检测框回归之前需要完成候选区域提取,单阶段检测算法无需候选区域提取过程,往往运行速度较快。然而,目标检测问题是典型的类不平衡问题,由于开放场景下视频背景的多样性,训练所需的负样本(即视频背景)的样本数量往往远大于正样本数量(无人机目标)。然而,在以最小化损失函数为目的的模型训练过程中,大量负类样本的引入往往造成训练过程中负类权重过大(即分类器更倾向于将样本预测为负类),导致检测精度下降。为了解决类不平衡造成的检测器性能下降问题,RetinaNet采用了如式(1)和式(2)的Focal loss作为损失函数:
(1)
loss=-α(1-Pt)γlgPt
(2)
式中:p为网络预测是否为正类的概率值,p∈(0,1)。正类样本标签y=1,p的优化目标为趋近于1。负类样本标签y=-1,p的优化目标为趋近于0。通过Pt来描述p,等同于将所有样本的Pt优化为1。
在式(2)中,α是正负样本参数,在本系统中,因为目标检测算法中负类样本数量远大于正类样本,对于正类样本,取α=1,对于负类样本,取α=0.25,从而使得正样本对于模型损失函数的影响大于负类样本,解决正负样本失衡的问题。γ是调节难易样本对于损失函数贡献的参数,对于困难样本,Pt越小,那么(1-Pt)γ越大,从而产生相对大的损失。同理,对于简单样本,Pt越大,则(1-Pt)γ越小,从而产生小的损失,将模型训练的重点放在困难的样本上。
RetinaNet结构如图1,C1~C5是ResNet网络下采样生成的特征图,P3~P7是特征金字塔网络。P5层由C5层得到,P4层由C5层上采样结果与C4层相加得到,P3层由C4层上采样结果与C3层相加得到,P6层则由P5层下采样得到,P7层则由P6层下采样得到。P3层和P4层通过2层特征相加的方式得到,既保留了高层特征,又融合了低层特征。P3~P7层都连接着检测框分类子网和回归框位置回归子网,其中分类子网和回归子网是2个全卷积层网络[16],输入的特征图有256个通道,与256个滤波器做4次卷积。在分类子网中,卷积4次后的特征图与K×A个滤波器做卷积,得到K×A个通道特征图;在回归子网中,卷积4次后的特征图与4×A个滤波器做卷积,得到4×A个通道特征图。其中A表示每个点映射到原图的候选框(称之为anchor)数量,K表示目标种类。

图1 RetinaNet网络结构Fig.1 RetinaNet structure
1.2 KCF目标跟踪器
KCF是一种判别式跟踪方法,这类方法在跟踪过程中训练一个目标检测器,使用目标检测器去检测下一帧预测位置是否是目标,然后再使用新检测结果去更新训练集进而更新目标检测器。KCF使用目标周围区域的循环矩阵采集正负样本,利用脊回归[17]训练目标检测器,并利用循环矩阵在傅里叶空间可对角化的性质将矩阵的运算转化为向量的基本积,大大降低了运算量,提高了运算速度,使算法满足实时性要求。
脊回归模型:
f(x)=WTx
(3)
式中:x为输入数据;W为回归模型的参数矩阵。脊回归的损失函数就是在最小二乘回归的基础上加上W的F范数作为惩罚项,即
(4)
式(4)对W求导,令导数等于0,得到脊回归器:
W=(XHX+λI)-1XHy
(5)
式中:X为输入数据,由循环矩阵得到;λ为惩罚项系数,不小于0;y为真值。
由基向量x生成循环矩阵X的过程为
循环矩阵基向量x:
x=[x1,x2,…,xn]
(6)
位移量q:

(7)
生成循环矩阵X:
m=0,1,…,n-1
(8)

(9)
通过核相关将线性回归拓展到非线性回归的回归模型:
(10)
式中:β为在傅里叶域下的回归系数,基于式(3)的最终回归模型为
(11)
KCF利用循环矩阵在傅里叶域可对角化的性质,将空域上的卷积运算转化为频域上的相关运算,以此持续修正跟踪框位置。该方法利用循环矩阵对角化特性,大幅降低了计算量,提高了跟踪速度。
1.3 相机运动补偿
相机运动补偿的基本思路是设法求出相机在当前帧与历史帧之间的运动偏移量。目前常用的相机运动补偿方法包括随机抽样一致(Random Sample Consensus)算法[18]与相位相关[19-20]等。
图2(a)中绿色框表示第n帧目标区域,黑色框表示目标区域2.5倍Padding的候选区域。候选区域中心点坐标为(x1,y1)。图2(b)中黑色框由图2(a)中候选区域得到,如果不进行运动补偿,在第n+1帧处提取出与第n帧相同的候选区域时,无人机只有一部分在候选区域中。
图3展示了修正图2中候选区域位置的过程:第n帧图片与第n+1帧图片计算出偏移矩阵,偏移矩阵中包括水平方向和竖直方向平移量以及旋转量等信息。利用偏移矩阵计算出第n帧候选区域中心点坐标(x1,y1)经过补偿后对应于第n+1帧的坐标(x2,y2),以(x2,y2)为中心点提取候选区域,无人机将全部位于候选区域内。
图4展示了Ransac和相位相关方法计算偏移量的过程。如图4(b)所示,提取出相邻2帧图片的特征点,完成2帧图片的匹配并计算出偏移量。如图4(c)所示,相位相关首先利用傅里叶变换,将相邻2帧从图像灰度域变换到频域,利用相关定理,计算出频域最大响应点,该点便是前后2帧位置差的响应,据此得到相机帧间运动偏移量。其中X和Y表示图片坐标点,对应的Z表示该点处的狄拉克函数值。
但是,上述2种方法在空天背景下可能存在以下问题:Ransac进行特征点拟合时,对特征点数量有要求。然而当空天背景纹理较少时,提取的特征点数量往往不足,Ransac计算出的偏移量将存在较大误差。相位相关算法通过全局图像信息获得帧间偏移量,避免了特征点提取,但也因此计算复杂度较高。

图2 无人机只有一部分在取样框内Fig.2 Only part of UAV in Padding_bbox

图3 利用偏移矩阵修正候选区域位置Fig.3 Correction of candidate regions with offset matrix

图4 Ransac与相位相关计算2帧偏移量Fig.4 Offset calculation of two frames by Ransac and phase correlation
2 RetinaNet与KCF结合的无人机检测
RetinaNet有着较快的检测速度和较高的精确率,但是针对小目标的检测,如果不进行改进,则存在较高漏警率的问题。KCF是相对快速鲁棒的跟踪算法,对背景杂乱和旋转等视频都有较好的跟踪结果。但是KCF跟踪局限于上一帧目标邻域内,如果相机或无人机快速运动,导致下一帧目标不在上一帧目标邻域内,则无法跟踪到目标,因此需要对相机进行运动补偿或对无人机重定位。RetinaNet与KCF结合,可以发挥两者的优点同时又能互相弥补不足。面对小目标或者特征丢失严重的目标,RetinaNet无法正确检测时,可利用KCF实现持续轨迹跟踪,避免目标漏警;当目标被遮挡,KCF将失去跟踪目标,RetinaNet检测到目标后可为KCF重新初始化,恢复跟踪轨迹。
2.1 引入低层特征的RetinaNet
在检测小目标无人机时,细节信息起到了关键作用。传统RetinaNet对P3~P7层做分类和回归。由于每个特征层的感受野不同,在设计anchor时,P3~P7层对应最佳原始尺寸为{32,64,128,256,512}, 每个尺寸的anchor对应3种不同的长宽比{1∶1,1∶2,2∶1},同时又有3种不同的面积比例{20,21/3,22/3},因此每层共有9种anchor。P3层anchor尺寸为32像素×32像素,因此难以检测成像远小于32像素×32像素的小目标无人机。每个特征层的anchor尺寸主要由感受野决定,如果强制将P3层anchor尺寸设置为16像素×16像素,则会出现在原图中整个无人机提取得到的特征,经过P3层anchor回归后只能得到整个无人机1/4区域的情况。P2层网络有着比P3层更丰富的细节特征信息,如果对P2层也做分类和回归,能弥补高层网络丢失的细节特征信息。P2层anchor尺寸为16像素×16像素,加入P2层训练的网络,对小于32像素×32像素的无人机也有较高的识别率。在第4节中,将详细探讨使用不同特征层对小目标检测的性能影响。实验中验证了加入P2特征层后能明显提升对小目标无人机的检测率。
2.2 RetinaNet与KCF具体交互方式
KCF与RetinaNet结合工作时,将RetinaNet设置一个较高的阈值,因此认为RetinaNet检测到的结果是可靠的,利用检测的结果去初始化KCF跟踪器,检测结果持续修正跟踪器,跟踪结果填补漏警的检测结果,检测与跟踪结合流程如图5所示,图中:n表示图片的序列号,总共有N帧;IOU(Rn+1,Kn+1)表示检测结果与跟踪结果的目标区域交并比;Luav表示无人机的位置区域;Area(Rn-1)表示检测结果的目标区域面积;Area(Kn-1)表示跟踪结果的目标区域面积。
初始化当RetinaNet检测器过于敏感,可能出现虚警检测结果,即背景中的其他目标被检测为无人机,采用虚警的结果对KCF跟踪器进行初始化,KCF后续的跟踪都是不可信的。因此,RetinaNet采用较高的检测阈值(在本文实验中,采用置信度高于0.90的检测结果),以降低虚警的可能。同时,在对KCF初始化后,将KCF跟踪结果与RetinaNet检测结果作比较:
1) RetinaNet没有检测结果,则取KCF跟踪结果作为最终无人机目标。
2) RetinaNet有检测结果,则计算KCF跟踪结果与检测结果的交并比,判断两者的结果是否一致。如果检测和跟踪的结果高度一致,最终无人机目标取面积最大的结果;如果检测结果与跟踪结果不一致,最终无人机目标采用检测结果,并用检测结果对KCF跟踪器进行初始化。

图5 检测与跟踪结合工作流程图Fig.5 Flow chart of detection and tracking combination
2.3 KCF不适用的情况
如图2所示,初始化KCF时,对第n帧目标框进行了2.5倍的Padding操作,跟踪时,在第n+1帧相同位置提取出和上一帧Padding框一样大小的区域,并将图像灰度域变换到频域,利用相关定理找出最大响应点,从而确定目标位置。但是如果由于无人机快速运动或者相机快速运动,导致了无人机不在Padding框内或者只有一部分在Padding框内,则最大响应点处将不是无人机或者只包含一部分无人机。上述情况将导致跟踪失败,因此需要以合理方式实现相机运动补偿和无人机重定位。
3 相机运动补偿和无人机重定位
对相机进行运动补偿或者对无人机重新定位,可以有效解决因无人机或相机快速运动使下一帧目标不在上一帧目标邻域内,从而导致跟踪失败的问题。
3.1 光流法对无人机重定位
针对无人机快速运动造成的跟踪丢失情况,可以采用光流法[21]对无人机重新定位。
如图6所示,通过输入相邻2帧图片,计算出光流场,根据光流场计算出每个像素点处运动速度的大小,该像素点的值表示速度的大小,将由速度大小组成的图片二值化,利用最小外接矩形将运动区域切割出来。
在所有矩形区域中,找到无人机所在运动区域的步骤为首先找出在上一帧目标区域7.5倍Padding后的区域内的所有矩形(KCF在对上一帧目标区域进行2.5倍Padding,重定位时在此基础上进行3倍Padding),如图7所示。其次,对满足上述条件的矩形区域计算出每个矩形区域的运动角度Drect、每个矩形区域的运动速度大小Srect和原始目标的bbox 7.5倍Padding区域的运动角度Dframe;假设7.5倍Padding区域内共有m个矩形,用D[i]~D[m]存储m个矩形的运动信息。
先找出m个矩形中运动角度与整个Padding区域运动角度不一致的矩形存储在B[]中;接着在B[]中找出运动速度最大的矩形判定为无人机所在矩阵;如果所有矩形运动角度与整个Padding区域运动角度一致,则直接在D中找出运动角度最大矩形判定为无人机所在矩形。伪代码为

图6 光流法找出无人机所在区域Fig.6 Detection of UAV area with optical flow

无人机重定位伪代码程序输入:连续2帧 输出:第2帧目标所在矩形区域1. 计算光流场,图像二值化后求最小外接矩形。2. 计算出Drect、 Srect和Dframe。3. int i=0, j=04. for i in range(m)5. if(|Dframe-D[i]. Drect|>15)6. B[j]=D[i]7. j+=18. if (B[] 不为空)9. let B[k].Srect=max(B.Srect)10. uav=B[k]11. if (B[] 为空)12. let D[k].Srect=max(D.Srect)13. uav=D[k]
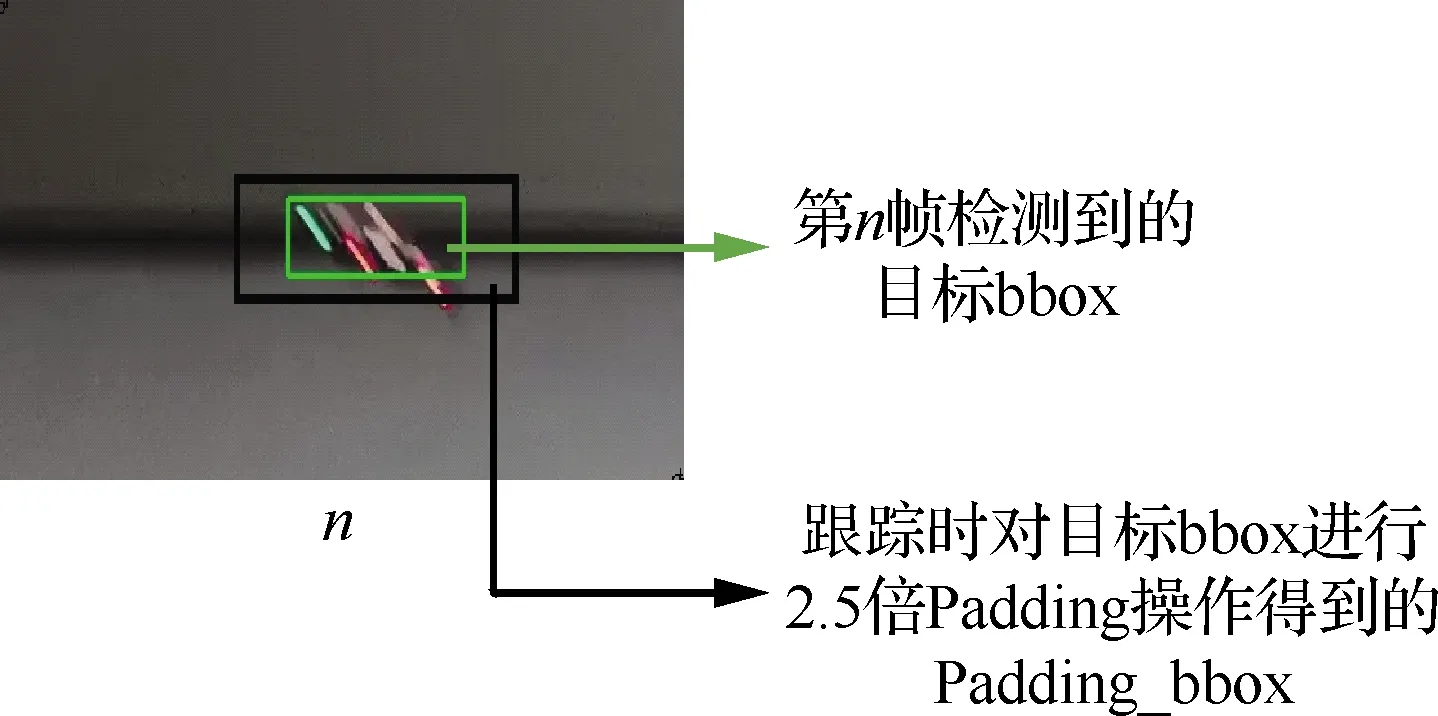
图7 7.5倍Padding找出候选区域示意图Fig.7 Detection of candidate area by 7.5 Padding
3.2 不同运动补偿算法的优缺点
Ransac算法需要对图片特征点进行匹配,如果图片背景纹理少,则提取的特征点不满足最低拟合条件,不能计算出偏移矩阵,无法进行运动补偿。对于背景纹理多的场景,Ransac算法可以计算出偏移量从而对相机进行运动补偿。
相位相关不需要提取图片特征点,即使是纹理较少的场景,也能在频域中找到最大相关峰值,计算出偏移矩阵,完成运动补偿。但相位相关存在计算量较大的问题。
在背景纹理较多的场景中,采用光流法对目标重定位时,由于背景运动的干扰,最终得到的矩形区域中,无人机很可能与运动的背景混淆。当采用最小外接矩形进行运动区域分割时,无人机与背景存在被一个矩形区域包围的可能性,从而导致错误的无人机重定位结果。
因此,上述基于光流法实现无人机重定位算法更适用于背景纹理少的场景,而在背景纹理丰富的场景中Ransac算法和相位相关法更为适用。
在第4节实验中将进一步探讨3种算法的性能。
3.3 场景纹理自适应的运动补偿
针对上述运动补偿算法的不足,本节提出了通过对纹理丰富度的观测,自适应的选取运动补偿或目标重定位的策略,具体的,在纹理较少的场景使用光流法对无人机重定位,在纹理较多的场景使用相位相关进行相机运动补偿,在提高整体精确率的同时确保算法的稳定性。
为解决纹理丰富度的观测问题,引入差分盒子计数法[22-23]统计出图片纹理特征。对于一幅M×M的图像,可以看成三维空间的一个曲面。长为M、宽为M、高为L,其中L为图像的像素级数,一取L=256。将其所在平面(M×M)分为R×R大小的网格,在高度上也进行相同的划分,不过划分的单位为R×L/M。这样,图像所在三维空间就被划分为很多盒子。这样划分的目的是使长宽方向和高度方向的划分次数相同。在被划分成的每个R×R个网格内,找出最大像素值u和最小像素值b,u处于高度方向上第m个盒子,b处于高度方向上第n个盒子,则该R×R区域需要(m-n+1)个盒子覆盖所有灰度值。统计出所有盒子N,分形维数B=lgN/lgR。由于B是N和R对应直线的斜率,所以需要多次改变R,即网格大小,获得多个样本点,最后通过直线拟合求得最终的B。最终的补偿方案便是通过差分盒子计数法统计图片纹理复杂度:图片纹理较少的使用光流法对无人机重定位;图片纹理较多的使用相位相关对相机进行运动补偿。
4 实 验
4.1 实验设置
在进行实验时,标注了15个视频3 500帧VOC格式的无人机训练集,在测试时,选取了5种 不同场景的无人机飞行视频用来做测试。这5种场景分别是:① 相机和无人机运动方向相反; ② 相机快速运动,无人机运动较慢; ③ 无人机快速运动,相机静止; ④ 背景纹理较多; ⑤ 背景纹理较少。
文献[6-7]是专门研究检测小目标无人机的工作,YOLOv3[14]是单阶段检测方法。因此本文也与上述3种检测方法做了对比实验。
SiamRPN[24]、ECO(Efficient Convolution Operators for tracking)[25]、DiMP(Discriminative Model Prediction for tracking)[26]是基于深度学习的跟踪方法,本文也与之做了对比实验。
RetinaNet、文献[6]方法、文献[7]方法、YOLOv3、SiamRPN、ECO和DiMP算法都采用15个视频的3 500帧数据集进行训练。其中RetinaNet、SiamRPN、ECO和DiMP都采用ResNet50作为骨干网络,其余参数为原文献中推荐值。
设置的消融实验如下:
方法1只用RetinaNet检测。
方法2只用KCF跟踪。
方法3RetinaNet与KCF结合的工作方式。
方法4RetinaNet与KCF结合并且采用相位相关做运动补偿的工作方式。
方法5RetinaNet与KCF结合并且采用Ransac做运动补偿的工作方式。
方法6RetinaNet与KCF结合并且采用光流法对目标重定位的工作方式。
方法7YOLOv3检测方法。
方法8文献[6]检测方法。
方法9文献[7]检测方法。
方法10SiamRPN跟踪方法。
方法11ECO跟踪方法。
方法12DiMP跟踪方法。
方法13本文方法。
4.2 分场景消融实验
为了测试算法在不同场景下的表现,设计了分场景实验如下:
场景1相机和无人机运动方向相反。
场景2相机快速运动,无人机运动较慢。
场景3无人机快速运动,相机静止。
场景4背景纹理较多。
场景5背景纹理较少。
5种场景下的各方法的精确率如表1所示,召回率如表2所示。
精确率和召回率计算方式为
精确率(precision) = TP/(TP+FP)
召回率(recall) = TP/(TP+FN)
式中:TP为将正类预测为正类的数;FP为将负类预测为正类的数;TN为将负类预测为负类的数;FN为将正类预测为负类的数;
由表1可知,在上述5个场景中,其中的4个场景方法13(本文方法)有着最高的检测精确率。由于Ransac算法做补偿的特性,对于背景纹理较少的场景5,方法5不能正常工作,没有结果。
对比方法3~方法6实验结果,由表1和表2可知,在场景1和场景3中方法6精确率和召回率最高,在场景4中方法4精确率和召回率最高。场景4中方法3召回率只有0.341,说明存在检测与跟踪都失效的情况,而对比方法4~方法6结果,精确率和召回率都有很大提升。综上表明在相机快速运动(场景1)或无人机快速运动的场景中(场景3、场景4),运动补偿算法或对目标重定位的引入有助于增强检测算法的稳定性。注意到在场景1、场景2、场景3和场景5中场景纹理相对较少,使用光流法对无人机进行重定位时,相较2种背景补偿方法(方法4和方法5)有着更高的精确率与召回率。在场景纹理最多的场景4中,由于背景运动的干扰,方法6结果最差,方法4结果最好。在3种方法中,方法5场景适应性相对较差,当场景纹理较少时,方法5失效(参见方法5场景5结果)。因此,考虑到检测结果的精确率与召回率,以及对场景的适应性,本文提出的通过观测场景纹理自适应选择相位相关和光流法的工作方式结果最优。
在场景2和场景3中,由于相机或无人机快速运动,导致了无人机成像模糊,表1中检测方法在这2个场景中有着较高的精确率,但在表2中检测方法有着最低的召回率。实验表明针对成像模糊的场景,结合帧间运动信息辅助检测有助于提高检测率。
在场景1中,无人机和相机反向快速运动,引入相机运动补偿后抵消了相机运动带来的影响,但无人机快速运动仍影响了少部分跟踪结果,因此本文方法比结果最好的方法11低5%的精确率和召回率。在场景2中,引入相机运动补偿抵消了相机运动带来的影响,但由于成像模糊,少部分无人机已经完全失去无人机特征,出现了部分跟踪失败的情况,本文方法比结果最好的方法11低3.33%的精确率和召回率。场景3、场景4和场景5中,无人机快速运动,本文方法使用光流法重定位时有着最高的精确率和召回率。

表1 不同场景下精确率Table 1 Precision in different scenarios

表2 不同场景下召回率Table 2 Recall rates in different scenarios
图8为不同场景下本文方法与RetinaNet和KCF及其不同结合方法的轨迹图比较。其中X和Y表示图片中的坐标位置,T表示时间信息,对于连续的帧序列,帧的序号表示其处于的时间点。轨迹图包含了无人机运动的时间信息和空间信息。通过对比检测结果的轨迹与无人机真实运动的轨迹,可以直观地判断不同方法的检测性能。
4.3 对RetinaNet改进的消融实验
对RetinaNet进行改进时,对比了使用不同网络层对小于32像素×32像素的小目标无人机的检测精确率和召回率,如表3所示。

表3 不同网络层组合的精确率和召回率
实验表明,随着不断地加入低层网络,小目标无人机的检测率逐渐提高。P4层anchor为64像素×64像素,检测小于32像素×32像素的无人机目标时有很高的漏警率。这一情况在加入P3层后得到了有效改善,P3层anchor为32像素×32像素,能检测到32像素×32像素的小目标。但是如果无人机目标小于16像素×16像素则会出现漏警的情况,并且如果训练集中的小目标数据较少,即使采用Focal loss损失函数也不能有效解决小目标类不平衡的问题。加入P2层网络后,对小目标的检测率进一步提高。
5 结 论
本文提出了一种检测与跟踪结合的无人机检测算法,探究了不同网络层组合对小目标的检测率,证明了低层网络信息的加入的确能提高对小目标的召回率。同时也提供了针对特定场景,采用特定网络层组合的思路。改进的RetinaNet与KCF结合,RetinaNet检测结果持续修正KCF跟踪结果。针对RetinaNet产生的虚警结果,借助跟踪结果的轨迹加以抑制。KCF跟踪的结果弥补RetinaNet漏警的可能。
针对KCF跟踪时可能遇到的极端情况,提出通过观测场景纹理自适应的选择对相机进行运动补偿或对无人机进行重定位的策略,增强了KCF在极端情况下的鲁棒性。即使在无人机或者相机快速运动的场景中,补偿后的KCF算法依然能进行可靠的跟踪。未来的工作将是采用更为鲁棒有效的跟踪方式,提高快速运动小目标的检测精度。
