面向第三方支付的校园消费大数据系统及其数据采集与预处理设计
2020-12-01杨凡孙力群
杨凡 孙力群
摘要:大部分住宿型学校各种校园消费支付的第三方电子业务系统已经部署实施,校园消费活动每天产生大量交易数据,这些数据蕴含隐藏着在学生生活管理、后勤服务和保障、关联活动预警、商户类型布局预测、商户活动评估和过程考核中的管理价值。但大多数院校对这些原始数据没能开展充分有效的数据分析和利用。该项目就是为解决这一管理痛点,由我校大数据竞赛团队设计开发的校园消费行为大数据分析系统,对接我校智慧校园建设项目,现已进入模块测试阶段。通过hadoop,hive,scikit-learn、flask、echarts等大数据分析、开发和可视化技术开发大数据分析系统。通过对住宿型学校学生消费行为和业务的数据结构梳理和形式化定义,发现并显式化这些业务的各种数据分析需求。设计模块化、参数化的应用架构,为校园智慧化建设赋能。该文阐述了项目起源、技术平台和设计架构。并重点介绍了数据采集、清洗和预处理的设计思路和理念。
关键词:校园消费;大数据;数据采集;数据清洗;数据可视化;hadoop
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)29-0044-03
1 背景
大部分住宿型学校(高校、职业院校)实施了各类业务系统,学生在校园的各类学习和生活消费行为,只要是经过业务系统的,都完整记录了消费明细数据。当前的高校信息化建设已经进入了一个以“智慧校园”建设为主题的新时期[1]。这些数据价值的挖掘与分析,往往只做了简单的统计报告。数据内在的、隐性的价值、各类数据之间的关系分析没有揭示出来,每天生成的海量数据没有进行高度价值化的挖掘分析,数据反映的问题只能靠管理人员的经验和直觉才能发现,并且已有较大的滞后性。我们开发目标就是针对这些痛点和难点,采用通用化的产品级平台+配置式定制开发+增值式数据服务的开发模式。
通用化的产品级平台:成熟的开源技术架构、基于行业共性业务特征的组件化设计。
配置式定制开发:基于产品级通用平台,柔性化开发以满足机构客户个性化数据分析场景,追求通用平台与个性定制间成本与效益平衡。采用高度通用化平台:通过hadoop、hive、scikit-learn、flask、echarts等大数据分析、开发和可视化技术,开发通用性的校园消费行为大数据分析系统。
增值式数据服务:通过客户学校部署的大数据分析系统,基于数据分析结果,为客户提供更加详尽的业务数据报告,或接受全权委托代理的大数据应用分析系统的管理服务。基于客户自身业务数据特征,通过不断累积的本行业大数据开发应用经验,提供数据诊断方案,为智慧校园管理赋能。
2 系统框架设计
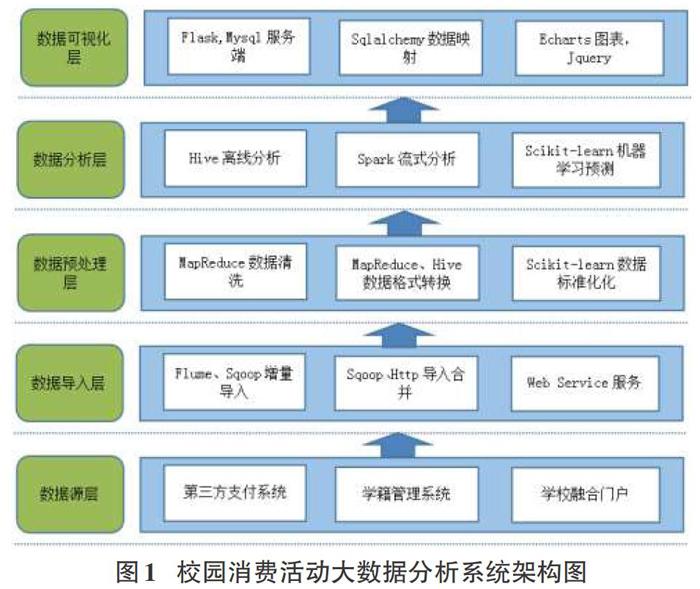
校园消费行为大数据分析系统产品技术架构采用分层模块化的大数据生态圈组件。基础计算平台采用高可用性Apache Hadoop。结构层次如图1所示。
校园大数据分析平台采用多层架构,将大数据处理、数据交换与共享、基于关系型和统计型大数据存储、权限管理、大数据分析挖掘进行有效整合,贯通校园大数据管理和应用的各个环节,从而适应于多维异构环境下校园大数据处理要求,实现海量数据的高效管理[2]。
1)项目的分析数据源来在校园消费的第三方支付平台,通过模拟访问终端的访问模式,将每天交易记录先存储成本地文件,再追加到hadoop平台HDFS的待处理文件中。而关联的消费者学生信息则来源于学校业务系统,两类数据在分析阶段实现按需合并。
2)数据导人层主要通过flume组件将交易记录导人到ha-doop HDFS文件,并将业务系统的学生数据定期更新到HDFS中,并做必要的数据清洗。需要注意的是,系统首次导人的时候需要将业务数据一次性全量导人,以后则是定期增量导人。
3)数据预处理层包括数据清洗和格式转换,清洗是将交易记录中的损坏、缺失数据进行无害化处理,格式转换是将字段的物理内容转换成分析时所需要的形式。这里采用mapReud-ce技术,逐记录按既定规则进行基础的清洗和转换,生成待分析的hdfs文件。
4)数据分析层使用hadoop生态系统中的hive组件,hive组件使用SQL风格的语言开发分析程序,上手容易,又能利用ma-pReduce引擎的云计算能力。整个系统的数据仓库的数据由Hive来管理,也就是说,无论是结构化数据还是半结构化数据,获取数据都是以Hive表的形式输出到数据分析层。
5)数据可视化层是终端用户直接接触的内容,以Web方式表现是最友好的使用模式。数据分析层Hive分析后的结果用sqoop组件导人到后台的MYSQL数据库中。项目使用flask、sqlachemy构建网站后台,从MYsoL读取分析后数据,在浏览器端使用echarts图表组件以曲线图,柱状图等形式显示大数据分析结果[3]。
3 数据采集与预处理设计
3.1数据采集功能设计
数据采集程序通过PVthon代码编写任务脚本,定时任务实现每天零点准时获取上一日数据。通过抓取禧云第三方支付商户平台API文档获取每天交易记录的数据[4],实现自动化获取流水记录并保存至本地文件。抓取的记录为全校所有餐饮商户的日记录,是增量式数据采集模式。
设计思路:准备好接口所需要的参数(token和流水开始结束日期)→模拟登录禧云商家平台获取账户的token→利用代碼获取当日日期和昨日日期→向服务器发送请求并保存数据至本地目录,核心代码如下:
class Timing_collect(object):
def' _init_(self):
while 1:
print(time.strftime(”%H:%M:%S”, time.localtime0》
if (time.strftime(”%H:%M:%S”, time.localtime0)==OO:OO:OO'):
self.dateStart= str(self.getYesterday0)
self.dateEnd= str(datetime.date.today0)
loop=1
while loop:
tw:
self.run0
loop=0
except:
pass
time.sleep(l)
def run(self):
self.s= requests.Session0
self.login0
self.save_excel0
def login(self):
login_url=7https://xr.xiyunerp.com/api/vl/user/login 7
self.data=f
'username':some,
'password' : 'some',
'verif'icationr : r r
}
self.headers = {
'User-Agent' : ' Mozilla/5.0 (Windows NT 10.0; Win64;x64; rv:74.0) Gecko/20100101 Firefox/74.Or
}
response = self. s. post(login_url, data = self. data, head-ers = self.headers).text
response = json.loads(response)
self.token = response[ 'bizContent ' ][ 'token ']
print(登錄成功! ')
def getYesterday(self):
today = datetime.date.today0
oneday = datetime.timedelta(days=l)
yesterday = today - oneday
retum yesterday
def save_excel(self):
print(r %s流水在保存 …… '%self.dateStart)
url =
3.2 预处理功能设计
通过各管理平台采集后的数据需要进行清洗过滤,以去除重复数据、异常值和缺失值,为数据挖掘提供良好的数据基础[5】。以行为单位的物理清洗和格式转换在MapReduce中完成,MapReduce整个处理过程可以概括为以下阶段:输入一>map->shuffle->reduce->输出,以下示例说明。
1)实现Mapper重写map0方法。
map类继承了库类中的Mapper,即Mapper。通常map类中会重写map方法,map每次只接受一个key-value,然后对其进行预处理,再分发出处理后的数据
public class MyMapper extends Mapperf
Text text= new Text0;
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)()
2)数据预处理去除干扰字符,清洗特殊字符。
String retValue= value;
retValue= value.toStringO.replace(‘|,'一')-//将l替换为一
retValue= retValue. toString0. replaceAIl(”\\r\\t”,””);//将换行符删除
3)在map阶段通过split(”,”)得到每行数据字段数据的数组。
StringD split= reValue.toString().split(”,”);
4)用trim()方法去除字符串两端空格并用isEmpty0判断是否有字段的数据为空,不为空开始进一步处理。
private boolean CheckData(Stringo paramArr){
for(int i=0;i
if(paramArr[i].trimO.isEmpty()){
return false;
))return true;)
5)日期格式转换。
String now= split[7];
Date date=new SimpleDateFormat(”yyyy/MM/dd hh:mm”).parse(now);
now=new SimpleDateFoⅡnat(”yyvv—MM—dd hh:mm”).format(date);
6)选出需要的数据,按指定格式输出。
StringRevalue=String.format(”%s,%s,%s,%s,%s”,now,split[2],split[4],split[5],split[6])
7)输出数据。
text.setfRevalue1:
context.write(text,NullWritableget0)
4 系统研发小结
作为一个参加“互联网+”创新创业大赛的项目,我们通过技术开发和初始运作,有了一些心得体会。
客户痛点:校园消费的第三方支付平台存在数据展示信息价值低、数据单一、信息不直观等问题;没有专门的平台用来展示这些分析和挖掘过后的数据,客户交互性弱,扩展性弱;海量业务数据无法直观反映内在的问题,只能靠管理人员的经验和直觉才能发现,并且已有较大的滞后性;客户对大数据分析应用于校务管理与决策的认识程度不够,守着数据不知如何充分利用。
市场现状与机遇:移动互联、物联网、云计算、社交网络、Web的快速发展让学生校园行为数据前所未有的增长,海量数据中必然蕴含着巨大的价值[6];大部分企业或高校对大数据认知程度不高,不懂得如何将积累的海量业务数据充分利用,市场客户需要培育;客户对实现的技术方式不甚了解,对数据安全有疑虑,市场和客户对产品接受有一定障碍;大公司定做大数据平台价格高、面向客户的门槛较高。
市场发展前景:住宿型学校基数很大,在中心城市密集分布,具有业务复制的基础;每所学校学生数从几千至几万,每天校园消费活动频度很高,数据持续生成,海量业务数据有待充分利用;而绝大部分学校的校园消费场景已对接支付宝等第三方支付平台,而且平台数据所有权归属学校,完全具有进一步实施大数据分析的技术和法律可行性;从宏观市场上看,随着国家大数据战略推进实施以及配套政策的贯彻落实,大数据产业发展环境将进一步优化,社会经济各领域对大数据服务需求将进一步增强,大数据的新技术、新业态、新模式将不断涌现,产业规模将继续保持高速增长态势。
参考文献:
[1]王亚楠.大数据背景下数据挖掘技术在高校中的应用——以校园卡系统为例[J].华中师范大学学报(自然科学版),2017.51(S1):9-12.
[2]李有增,曾浩.基于学生行为分析模型的高校智慧校园教育大数据应用研究[J],中国电化教育,2018(7):33-38.
[3]宋文文,孙力群.大数据可视化数据加载模式比较分析[J]‘电脑知识与技术,2019,36:11-12.
[4]李辉.Flask Web开发实战:入门、进阶与原理解析[M].北京:機械工业出版社。2018.
[5]禧云开放平台.APl文档交易流水推送服务[EB/OL].[2020-02-20].http://www.caj cd.edu.c n/pub/wml.txt/9 808 10-2.html.
[6]李铁波.基于校园大数据的学生行为特征分析与预测方法[J].重庆理工大学学报(自然科学),2019,33(7):201-206.
[7]邓逢光,张子石,基于大数据的学生校园行为分析预警管理平台建构研究[J].中国电化教育,2017(11):60-64.
【通联编辑:谢媛媛】
作者简介:杨凡(2000-),男,江苏镇江人,本科在读,研究方向为大数据技术与应用;孙力群(1972-),男,江苏苏州人,讲师,硕士,研究方向为软件工程、大数据分析与开发。
