基于信息传播特性的新词发现方法研究
2020-11-30曹春萍杨青林
曹春萍 杨青林


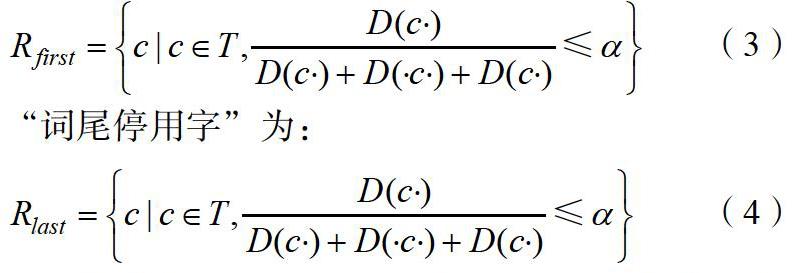
摘 要: 针对现有方法无法有效、快速地识别出网络中文新词,且其生命周期比较短的问题,提出了一种基于信息传播特性的新词发现方法研究。利用N-gram算法得出候选词串列表,基于词频和词语灵活度对垃圾词串进行过滤,实现基于信息传播特性的微博新词统计方法。实验结果表明:提出的基于信息传播特性的新词发现方法在查准率、召回率都要比使用中文ICTCLAP9115分词方法分词更好,更具有优势。
关键词: 信息传播;新词;发现方法;N-gram算法
中图分类号: TP301 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.09.053
本文著录格式:曹春萍,杨青林. 基于信息传播特性的新词发现方法研究[J]. 软件,2020,41(09):201203
【Abstract】: In view of problem that existing methods can not identify Chinese new words on the Internet effectively and quickly, and their life cycle is relatively short, the paper proposes a new word discovery method based on characteristics of information dissemination. It obtains list of candidate word strings with N-gram algorithm, filters waste word strings based on word frequency and flexibility, realizes statistical method of new words in microblog based on characteristics of information dissemination. Experimental results show new word detection method based on characteristics of information dissemination has better precision and recall rate than the Chinese ICTCLAP9115segmentation method with advantages.
【Key words】: Information dissemination; New words; Discovery method; N-gram algorithm
0 引言
自微博出現以后,其以实时性和方便性受到广大网民的欢迎和热爱,已经发展为网络应用的爱宠。同时微博上汇聚的庞大用户以及比较自由的言论环境,又使微博发展为切实掌握社会热点的重要工具。伴随计算机信息技术和网络技术的发展创新和应用,计算机网络越发成为大众信息发布与文化传播交流的社会平台,因此产生一大批全新的网络用语和热词。一些普及度比较高的网络新词开始为众人所认可,并被逐渐扩展到中文词语库之中[1]。因为在网络世界中存在海量文本,而要想在文本中寻找到散落的网络新词单独凭借人工查找、查阅和统计比较困难,因而怎样在短时间内快速有效地对网络数据进行查阅并发现新词,这就成为一项迫切需要解决的现实问题。但网络文本数据庞大,因为其相关性比较差、组词并无规律,这些就导致部分规律原理方法很难直接套用;而单条网络文本因为其文本长度比较短,噪声比较大[2],这就造成传统的基于统计学的发现方法很难提高其最终准确率。因此,本文研究基于信息传播特性的新词发现方法。
1 基于信息传播特性的微博新词发现方法
相比于常规的语料训练,微博语料库中包含的文本内容由于身处网络世界,要更为庞大复杂。除正常的文本信息以外,还会伴随诸多无意义的干扰选项,比如说表情符号中的[doge]、[泪]、[微笑]等等;微博用户或平台发布的网页链接,比如http://t.cn/8syl8qn等;符号“//@”用户名用代表转发用户,符号“@”+表示语句中提到的特定用户;由于绝大多数微博用户名不是正式网名,因此所有微博用户名称都不具有实际意义;以及微博语料库中的标点符号,由于文本的失真和非正式性,导致大量微博用户滥用标点[3]。这几种字符串并没有产生新词,因而能够将其从待处理语料库中过滤,直接以“空格”来取代,如此可进一步提升语料库的文本含量并有效降低后续操作的难度。
1.1 利用N-gram算法得出候选词串列表
N-gram模型主要是根据如下一种假设:第个词语的出现只和前面个词语有关系,而和其他词语之间均无关联。我们以来表示这个词语,如此出现的概率就能够以来表示,这里使用代表词串。在保证大量训练语料的基础上,按照最大相似规则[4],就能够获取以下公式:
和分别代表词串和在训练语料中出现的具体次数。假设这个词语可以有机组成一个句子,即,那么这句话的先验概率就可以用公式代表,如下所示:
之所以将其称之为N-gram算法下的模型,就因为其单独反映出连续个词语间的关联。比较常见的分式模型就是时的Bigram模型和时的Trigram模型。
1.2 基于词频和词语灵活度过滤垃圾词串
任何一个新词的出现,势必会伴随着绝大多数群众的大规模使用,而使用次数越少的词语并不具有发展为一个新词的可能性;同时因为互联网用户在建立文档的时候必然会出现输入法错误的操作,错别字等各式状况的发生,在新词候选集合中会出现诸多偶然性匹配,这种匹配在性质上并不纳入新词考虑范围内,绝大多数这种噪声元组是没有办法通过阈值的筛选,可是依然会有一小部分的噪声因为彼此之间信息阈值在计算方式上的不同,其统计记录也会影响到词语整体最终呈现的准确率[5]。本文利用词频和词语灵活度的方法对上文形成词串中的垃圾词串进行过滤,以便有效提高之后新词统计方法的工作效率。一个具备成为词语的字符串,势必会在社会得到广泛推广和使用,因而在训练语料库中也会频繁出现。出现频率较低的词串在性质上会被归属为不具备一定意义的有效词串。通过统计分析得知,92.01%的候选词串其出现次数基本上小于等于2,所以本文在词频过滤方法的阈值大小设置为2。
另外一方面,按照中文的形成和组词规律,会存在一部分字符并不时常出现在词首或词尾,这些字符即为“停用字”,主要分为“词首停用字”和“词尾停用字”[6]。本文通过词串的灵活度(代表每一个字符组成词语的可能性和可行性)和设置阈值的比对,去有效发现“停用字”。本文以来代表待判字符,以·代表随意一个字符,有可能会出现在词首/词尾,甚至是词的任何一个位置,由此定义“词首停用字”为:
上述公式中:代表词串在训练语料库中出现的实际次数;代表字符出现在词首或词尾的可能性阈值。实验中设定阈值为2,共选取出大概200个停用字,如“是”“的”“了”“们”“你”等。对候选词串完成垃圾过滤以后,本文以统计学方法获取最终出现的新词结果。
1.3 基于信息传播特性的微博新词统计方法
微博新词与普通词语在组成结构上有很大不同,如词语构成上相较来说较为自由不受限,并没有遵循传统的语法构造[7]。由于单纯的汉语组成规则方法,其规则的制定比较耗时,且可移植性较低;另外虽然单一的N-Gram模型其可移植性较为优秀,可其在大规模数据的运作中涉及的计算量比较庞大,所以本文提出了基于信息传播特性的新词发现方法,利用N-Gram方法对新词进行识别、统计。主要步骤如下所示:
步骤1:首先对文本信息语料库中的分词碎片进行预先处理,以便获取到候选新词集。在将其加入垃圾词串库的MC过程中需要把每一个文本连续编号以组建一个碎片子集FS,按照上述规则,FS主要是作为大于2个词的词子集而存在。比如:“第一次/大概/还/一知半解/不明觉厉”。按照刚刚的规则能够获得2个FS子集,即“第一次可能”和“不明觉厉”。在N-Gram模型词串库MC提取FS的候选语料算法的操作过程具体如下所示:
算法:N-gram中候选新词提取算法。
输入:MC//词串语料库集合;FS//碎片语料序列;
输出:CS//候选新词子集。
过程:
1)在词串语料库MC中,按照关键词的提示,候选词串按照运算规则提取到FS,将其作为三元的Bi-Gram和四元的Tri-Gram模型内的计算对象;
2)对每一个FS中蕴含的词语频数进行统计,之后统一做归一化处理,最后通过Bi-Gram模型公式(1)分别对FS的三元组、四元组和五元组字符出现的概率进行精准计算。之后将字符串连同其出现的概率值存储至语料库内;
3)按照公式(2)对每一组词句的分词结果出现概率进行比较,选择最优结果[8],换句话说就是通过公式(3)获得概率的最大值,若是小概率则利用公式(4)对概率进行计算。得到结果后,将所有字符串出现的概率按大小关系进行排序,选择较大的一组字符串作为候选字符串;
4)借助TriGram模型,重复上述过程2)和过程3),获得候选字符串,最后抽取同时存在于与内的相同字符串作为候选语料的新词序列。
步骤2:通过相邻熵对候选新词子集进行成词概率的过滤。候选新词一般是三元组或五元组,计算左右相邻熵均超过阈值,如此便加入新词子集内。候选新词通常为四元组,首先对左边邻近熵进行计算,判断其是否超过阈值[9-10];一旦超过阈值,继续对右边相邻熵进行计算,将左右邻近熵超过阈值的候选新词纳入新词子集内。如果候选新词判断为新词,那么其在语料库中势必具备较高的出现频率,必然“高富帅”肯定会比和它有关的垃圾词串“富帅不”出现频率要高。假设候选新词用表示,那么我们使用词频代表在语料库内出现的频率,一般越大,作为新词的可能性就越大,二者成正比例关系。根据有关资料显示,用来表示两个事物之间的相关性或亲密度。在新词筛选的过程中,可以用来衡量多个字/词组合成语句的可能性大小。对于候选新词而言,其亲密度可用以下公式表示:
其中,与分别代表和所指代的词频。为了综合衡量候选新词库内的词频与内部的亲密度,我们一般采取线性加权对候选新词的可信度进行计算。用表示新词的可信度,计算公式如下所示:
上述公式中,和分别代表词频与值的标准值。对于词频而言,我们一般以公式(7)进行推算:
上列公式中,与分别代表语料库内的新生词频最大值与最小值。值的标准推算和词频相似。代表权重,用以调整词频与的比值。当时,候选新词的可信度由且仅有所决定,反之,则由词频单独决定。在对每个候选新词的可信度进行计算后,我们就可以根据其可信度对候选新词进行统计发现,实现新词发现。
2 实验论证与分析
为保证本文设计的基于信息传播特性的新词发现方法的有效性,进行实验论证分析。
2.1 實验准备
硬件环境:需要两台计算机,(1)配置:Intel Xeon E9-1331v5,4.50 GHz主频,64 GB内存,32位操作系统;(2)配置:Intel Xeon E6-2929 v5,3.30 GHz主频,256 GB内存,64位操作系统;软件环境:(1)操作系统Windows10,(2)操作系统是Cent OS。算法采取JAVA与python双结合,编辑工具以Eclipse和IDLE为主。
本次实验选取9000条微博文本,分成三组作为输入,分别利用本文方法和中文ICTCLAP9115分词方法对其做相关处理,按照一系列的计算获取最终结果。
2.2 实验结果分析
通过新浪微博APP,随机抽选取新浪微博中粉丝数量比较多的微博账号作为信息采集的起点,利用“滚雪球”的方式,采集到2019年4月1日至2020年4月1日这些微博账号在微博上公开发布的每一条微博的网络IP、信息发布者、信息发布时间、信息发布内容等,在对垃圾微博进行过滤等处理后,建立了包括9000条微博的原始数据集合。
本文方法和中文ICTCLAP9115分词方法的实验对比结果如下表所示。
分析表1可知,本文提出的基于信息传播特性的新词发现方法在查准率、召回率都要比使用中文ICTCLAP9115分词方法分词更好,更具有优势。
3 结束语
本文对基于信息传播特性的新词发现方法进行分析与设计,依托信息传播的特性,收集并提取微博词语数据的普遍特征,结合新词出现规则,对新词的出现进行统计分析,实现新词发现法的创新。实验论证结果表明,本文设计的基于信息传播特性的新词发现方法具备极高的有效性,在对微博新词进行统计查找的过程中,可以有效节省计算时间,提高查找率和召回率。希望本文的研究能够为我国新词发现方法提供理论依据和参考。
参考文献
[1]赵志滨, 石玉鑫, 李斌阳. 基于句法分析与词向量的领域新词发现方法[J]. 计算机科学, 2019, 46(6): 29-34.
[2]陈芬, 高小欢, 彭玥, 等. 融合文本倾向性分析的微博意见领袖识别[J]. 数据分析与知识发现, 2019, 3(11): 120-128.
[3]宾晟, 孙更新. 基于多关系社交网络的协同过滤推荐算法[J]. 计算机科学, 2019, 46(12): 56-62.
[4]李嘉兴, 王晰巍, 常颖, 等. 社交网络用户行为国内外研究动态及发展趋势[J]. 现代情报, 2020, 40(4): 167-177.
[5]刘伟童, 刘培玉, 刘文锋, 等. 基于互信息和邻接熵的新词发现算法[J]. 计算机应用研究, 2019, 36(5): 1293-1296.
[6]黄伟, 曹春萍.基于行为分析与传播个体的微博传播模型研究[J].软件, 2019, 40(01): 127-131.
[7]汪文妃, 徐豪杰, 杨文珍, 等. 中文分词算法研究综述[J]. 成组技术与生产现代化, 2018, 35(3): 1-8.
[8]刘申凯, 周霁婷, 朱永华, 等. 融合知识图谱和ESA方法的网络新词识别[J]. 计算机技术与发展, 2019, 29(3): 12-17.
[9]曾浩, 詹恩奇, 鄭建彬, 等. 基于扩展规则与统计特征的未登录词识别[J]. 计算机应用研究, 2019, 36(9): 2704- 2707+2711.
[10]李娟, 虞金中. 基于新词的新闻命名实体识别研究[J]. 电脑知识与技术, 2018, 14(22): 153-154.
[11]陈海宇.“大数据”时代背景下计算机信息处理技术的探讨[J].计算机产品与流通, 2020(05): 6.
