图像OCR识别在机顶盒信息检测中的应用分析
2020-11-30靳国荣


摘 要 随着生活水平的提高,机顶盒已成为每个家庭必备的设备,因此,机顶盒的质量就显得尤为重要。但如果机顶盒写入的信息有误,将导致机顶盒无法正常运行,会极大地影响用户的观看体验。现有技术对机顶盒等视频盒子的信息检测还停留在传统的人工测试判定,即通过人工的方式对视频图像上的信息进行比对来检验正误,但是人工检测的方式带有很多个人主观观点,无法快速准确地发现机顶盒中信息有误的问题。
关键词 OCR;图像预处理;文字识别
引言
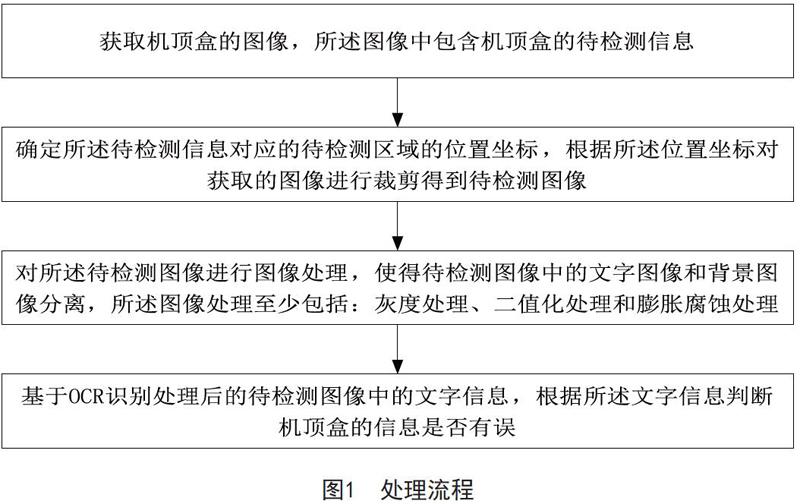
本文提出的图像OCR识别的机顶盒信息检测方法及系统,技术方案概括为:获取机顶盒的图像,所述图像中包含机顶盒的待检测信息;确定所述待检测信息对应的待检测区域的位置坐标,根据所述位置坐标对获取的图像进行裁剪得到待检测图像;对所述待检测图像进行图像处理,使得待检测图像中的文字图像和背景图像分离,所述图像处理至少包括:灰度处理、二值化处理和膨胀腐蚀处理;基于OCR识别处理后的待检测图像中的文字信息,根据所述文字信息判断机顶盒的信息是否有误。
图像OCR识别的机顶盒信息检测方法的处理流程如图1所示。
1图像采集处理
1.1 图像采集
机顶盒的图像可以通过HDMI设备获取,机顶盒的待检测信息可以是机顶盒生产序列号、机顶盒加密序列号、锁定模式序列号、机顶盒加密卡序列号等。采集出来的图像如图2所示。
1.2 定位检测区域
根据所述位置坐标对获取的图像进行裁剪得到待检测图像;具体而言,可以根据待检测信息在图像中的位置确定出裁剪区域的位置坐标,然后根据裁剪区域的位置坐标对获取的图像进行裁剪得到待检测图像,待检测图像中包含了机顶盒的待检测信息。如图3所示。
1.3 图像预处理
待检测图像进行图像处理,使得待检测图像中的文字图像和背景图像分离,所述图像处理至少包括:灰度处理、二值化处理和膨胀腐蚀处理;
可以理解,灰度处理、二值化处理和膨胀腐蚀处理是依次进行的,其中,灰度处理包括:
对待检测图像进行灰化处理,得到只包含一种灰度值的灰度图像,灰化公式如下:
式中,表示灰度图像中像素的灰度值,R表示红色分量值,G表示绿分量值,B表示蓝色分量值。
二值化处理包括:确定灰度阈值,根据所述灰度阈值对灰度图像进行二值化处理得到二值图像,二值图像就是只有黑白两种颜色表示的图像,在数字上用0 表示黑色(0),1表示白色(255) 。图像中属于同一物体的像素在灰度值上存在极大相似性,相反,不同物体在灰度值上通常表现为较大差异。因而,本实施例通过自动阈值化技术,选取能够充分体现前景和背景差异的分割灰度值,使待识别的文字大致分离出来。
根据自动阈值化技术确定灰度阈值的方法包括:设定初始灰度阈值,对于灰度图像的每个像素,计算其Kirsh算子,根据初始灰度阈值与Kirsh算子的大小对初始灰度阈值进行动态调整得到灰度阈值。
膨胀处理包括:遍历所述二值图像的每一个像素,用结构元素的中心点对准当前正在遍历的像素,获取当前结构元素所覆盖下的二值图像对应区域内的所有像素的最大值,用该最大值替换当前像素值[1];由于二值图像最大值就是1,所以就是用1替换,即变成了白色前景物体。如果当前结构元素覆盖下,全部都是背景,那么就不会对原图做出改动,因为都是0;如果全部都是前景像素,也不会对原图做出改动,因为都是1;只有结构元素位于前景物体边缘的时候,它覆盖的区域内才会出现0和1两种不同的像素值,这个时候把当前像素替换成1就有变化了。膨胀后的图像的整体亮度会有提高,图形中较亮物体的尺寸变大,而较暗物体的尺寸会减小甚至消失。
腐蚀处理包括:遍历所述二值图像的每一个像素,用结构元素的中心点对准当前正在遍历的像素,获取当前结构元素所覆盖下的二值图像对应区域内的所有像素的最小值,用该最小值替换当前像素值;由于二值图像最小值就是0,所以就是用0替换,即变成了黑色背景。如果当前结构元素覆盖下,全部都是背景,那么就不会对原图做出改动,因为都是0;如果全部都是前景像素,也不会对原图做出改动,因为都是1,只有结构元素位于前景物体边缘的时候,它覆盖的区域内才会出现0和1两种不同的像素值,这个时候把当前像素替换成0就有变化了。腐蚀后的图像整体会变暗,图像中比较亮的区域的面积会变小甚至消失,而比较暗的区域会增大一些。
2OCR识别
通过对待检测图像进行处理后,能够得到更加易于文字识别的图像,本实施例中,将处理后的待检测图像输入至Tesseract-OCR引擎中,Tesseract-OCR引擎对待检测图像进行文字识别得到待检测图像的文字信息。
Tesseract-OCR引擎使用到的静态字符分类器,包含一种特别的设计思想,即分类器训练与分类识别过程的分离。大多数分类器,其训练样本和识别字符具有同样的处理方式,因而,只有当待识别字符与训练样本接近时,识别成功率才能够到保证。Tesseract-OCR引擎使用了一种突破性的解决方式,在训练样本集时,系统选取字符的近似多边形段作为特征;而在识别过程中,系统选取属于字符边界的固定长度的短线段作为特征,并使用多对一方式对应于系统的标准特征。
其文字识别的具体步骤如下[2]:
精选出可能与待检测特征匹配的类别,未知字符每一个待识别特征通过查表可以得到一组可能与其匹配类别的向量,系统将这些匹配向量相加,选取出得分最高的几个类别作为最有可能未知字符匹配的名单;
通过计算相似度确定最终类别,每一個标准字符都由一个逻辑合式代表,由此待识别特征与标准字符的“距离”可以被计算出来。最后,综合得到的具有最短距离的类别,就是与未知字符相似度最高的类别。
Tesseract-OCR引擎的分类设计能够识别受损字符,具有较强的鲁棒性,所以在选取分类器的训练样本时就不需要引入损伤字符,并且其识别的速度和准确率较高。
识别出文字信息后,比较所述文字信息与预设文字信息是否一致,若一致,则表示机顶盒的信息正确,否则,表示机顶盒的信息有误。
3结束语
经过实际实验及实用,该方法在机顶盒自动检测上具有非常好的效果。达到了预期设计目标。
参考文献
[1] 章专,仲林国,朱志刚.基于图像采集与处理的自动抄表系统[J].电测与仪表,2004,(1):19.
[2] 昝元宝,靳国荣.机械式水表读数识别图像预处理研究[J].信息化技术应用,2019(7):26-27.
