采用自注意力机制和CNN融合的实体关系抽取 *
2020-11-30段跃兴张泽华
闫 雄,段跃兴,张泽华
(太原理工大学信息与计算机学院,山西 晋中030600)
1 引言
互联网中的信息大多都是无结构的,实体关系抽取旨在从这些非结构化的信息中快速、准确地抽取出用户所需要的信息。实体关系抽取在信息抽取[1]、智能问答系统[2]和知识图谱[3]等应用中发挥着重要的作用。实体关系抽取可以表述为:从一段存在2个实体(Entity)的文本S中,确定其中目标实体对〈e1,e2〉之间的语义关系r,例如在句子〈e1〉People〈/e1〉 have been moving back into 〈e2〉downtown〈/e2〉中,people和downtown 2个实体之间存在Entity-Destination的关系。根据对数据集的标注程度,实体关系抽取可以分为有监督、半监督和无监督3类。本文旨在研究有监督实体关系抽取,它将实体关系抽取问题转化为一个分类问题。有监督实体关系抽取方法主要包括传统方法和深度学习方法,前者主要采用特征向量和核函数的方法进行实体关系抽取,其依赖于自然语言处理NLP(Natural Language Processing)[4]工具预先提取文本特征,但是这些工具本身就存在不足,使用这些工具会造成错误传递问题,影响最终的分类效果。相比传统方法,深度学习方法可以自动获取更多有效特征,并且不需要借助自然语言处理工具就可以明显提高分类效果,因此国内外的研究者在深度学习的基础上进行了很多实体关系抽取的研究。
深度学习方法通过学习每个词的分布式表示,不仅能够自动提取文本特征,而且还能够很好地利用文本结构特征,是当前实体关系抽取方法的研究热点。Socher等[5]通过循环神经网络(RNN)学习句子的句法结构信息进行实体关系抽取。Zhang等[6]使用双向的RNN进行关系抽取,但是RNN存在长距离依赖问题,不能充分考虑上下文语义关系。Zeng等[7]引入了词的位置向量特征(Position Feature)并利用卷积神经网络提取句子级别和词汇级别的特征,连接这2个特征作为关系分类的最后特征向量。dos Santos等[8]在卷积神经网络的基础上,提出了一种新的排序损失来进行关系抽取。王林玉等[9]提出了基于卷积神经网络和关键词策略的实体关系抽取方法,通过关键词抽取算法TP-ISP(Term Proportion-Inverse Sentence Proportion)获得关键词特征,以弥补卷积神经网络在特征提取方面的不足,从而提高每个类别的区分度。肜博辉等[10]提出了一种基于多通道卷积神经网络关系抽取的方法,使用不同的词向量作为神经网络不同通道的输入,以表征更多的语义信息。实体关系抽取是一个序列到标签的分类问题,分类结果取决于句子序列的整体语义信息。循环神经网络能够学习高质量的文本信息,但是它的计算能力依赖于序列的长度,当句子序列较长的时候,提取句子特征时会受到影响,并且每一个词的编码都需要借助上一个词的表示,因此不能并行计算。卷积神经网络可以在句子序列中进行并行计算,CNN也考虑了多个n-gram特征,在一定程度上也可以缓解长距离依赖问题。
注意力机制[11]是由Treisman等通过模拟人类视觉注意力机制提出的模型。通过输入序列与标签之间的相关性,从而为输入序列中对分类结果影响大的词分配较大的权重。自注意力机制[11]是对注意力机制的改进,主要用于序列建模的任务中。在自注意力机制中,权重是通过输入序列中词之间的相似度函数动态得到的,为联系紧密的2个词分配较大的权重,输入序列中的词的语义信息取决于整个输入序列,因而能够更充分地获取句子中词的上下文语义信息,而不是由它们的相对位置预先确定。因此,本文采用自注意力机制和卷积神经网络融合的方法来进行关系抽取,解决了传统神经网络对序列中词的语义信息学习不足的问题。
综上所述,由于卷积核是固定的,单一地利用CNN进行实体关系抽取,易导致句子中词的上下文语义提取得不够充分。因此,本文利用自注意力机制和CNN融合的方法进行实体关系抽取,首先通过自注意力机制处理数据集以增强句子中词的上下文语义,然后通过CNN自动提取特征。
2 自注意力和卷积神经网络融合模型
本节将介绍一种新的自注意力机制和卷积神经网络融合的模型Self-ATT-CNN。该模型的结构图如图1所示。

Figure 1 Structure of Self-ATT-CNN model图1 Self-ATT-CNN模型结构图
相比传统的卷积神经网络,本文模型在输入层和卷积层之间加入了自注意力层。本文模型主要由4部分组成:(1)输入映射层,通过查询预先训练好的词向量表,将文本中的词映射成低维的实数向量,组成句子矩阵。(2)自注意力层,通过自注意力对输入的原始词向量特征WF(Word vector Feature)进行计算得到具有更加丰富的上下文语义的词的表示。之后将词的位置向量特征PF(Position vector Feature)进行融合得到卷积层的输入。(3)卷积神经网络层,通过卷积神经网络的卷积、池化运算提取句子的特征,组合为最后的特征向量。(4)输出层,将通过卷积神经网络提取的特征向量输入分类器中进行分类,输出最终的分类结果。
2.1 输入映射层
输入映射层将句子序列中的每个词转换为向量表达,一个句子序列可以表示为一个矩阵。本文使用连续词袋模型CBOW(Continuous Bag Of Words)模型对1 000亿字的谷歌新闻语料进行训练[12],得到300维的词向量,它带有潜在的句法和语义信息。对于输入句子序列S:
S={w1,w2,…,wn}
(1)
其中,n表示句子S中词的个数。通过查找词向量矩阵将每个词转换为向量的计算方式,如式(2)所示:
rw=Wword×Vw
(2)
其中,rw表示词的向量表示。Wword∈Rdw×|v|是所有词的词向量矩阵,dw表示词的向量维度,|v|是数据集中所有词的个数。Vw是词的one-hot编码表示。对于在词向量矩阵中不存在的词,本文将对其采用随机初始化的方式进行表示。
2.2 自注意力层
传统的神经网络主要是采用递归神经网络(RNN)或卷积神经网络(CNN)对句子序列进行编码。这两种神经网络可以隐含地学习句子中词的上下文信息,但是由于长距离依赖性问题,它们都无法很好地学习词上下文信息,因而对句子整体特征提取的效果不是很好。为了能够充分捕获词的上下文语义信息,本文引入自注意力机制。自注意力机制已经成功应用于各种自然语言处理任务,如机器翻译[13]和语义角色标注[14]。
2.2.1 自注意力机制
自注意力机制通过计算2个词之间的相似性将句子中任意2个词联系起来,就可以直接捕获句子序列中任意2个词之间的关系,无论这2个词之间距离如何。因此,2个相距较远的词之间语义关系也能被很好地获取,缓解了句子中的长距离依赖问题。通过自注意力机制对输入的词向量进行计算能够得到新的词向量,使得模型的输入可以表示出更加丰富的上下文语义信息。本文模型采用多头自注意力[14]计算方法,其模型结构如图2所示。其中,h表示多头自注意力机制中头的个数。

Figure 2 Multi-head self-attention model图2 多头自注意力模型
首先在多头自注意力机制中采用放缩点积(Scaled Dot-Product Attention)来进行相似度得分的计算。给定Query、Key和Value,相似度得分计算公式如式(3)所示。
(3)
其中,Score∈Rn×n为得分矩阵;dw取为词向量的维度,起到调节的作用。之后通过Softmax将得分进行归一化,将原来的得分转换为权重之和为1的概率分布,这样能更加突出2个元素之间的相关性。计算如下:
α=Softmax(Score)
(4)
最后经过分配权重即可得到Attention计算结果:
Attention(Query,Key,Value)=α·Value
多头自注意力机制就是将Query、Key和Value通过不同的参数矩阵映射在多个平行头上进行重复多次Attention计算,每个头可以处理不同的信息,这样就可以处理句子序列的不同部分,提取更丰富的句子特征。最后将多个Attention运算的结果进行向量拼接,多头注意力每一个平行头的计算公式如下所示:
headi=
(5)
MultiHead(Query,Key,Value)=
WM[head1,head2,…,headh]
(6)
其中,h为多头注意力机制中平行头的个数。WM∈Rdw×dw用于连接多个平行头的Attention运算的结果。因为该模型采用的是自注意力机制,所以输入多头自注意力的矩阵Query、Key和Value都为输入序列S。通过计算最终将得到:
S′={w′1,w′2,…,w′n}=MultiHead(S,S,S)
(7)
其中,S′是多头自注意力的输出,w′i是句子序列中第i个词通过多头自注意力机制计算后得到的新输出,它相比原始词向量带有更加丰富的语义信息。最后得到的S′∈Rn×dw是句子的新表示,也是下一层的输入。
2.2.2 位置向量特征
在实体关系提取的任务中使用词的位置向量特征,其依据是假设离实体近的单词比更远的单词具有更大的影响。使用自注意力机制计算句子中的任意2个词之间的相关性,计算过程中任何2个词之间的路径长度都记为1,因此没有考虑2个词之间的相对距离。所以,本文将参考Zeng等[7]的方法将词的位置向量特征加入进去。对于句子中的每一个词,通过计算该词与句子中实体的相对位置得到词与实体之间的距离。例如在图1中moving距离people和downtown 2个实体的相对距离分别为3和-3,通过查询随机初始化得到的位置向量矩阵生成词的位置向量信息,对于给定的一个句子序列S:
S={w1,w2,…,wn}
(8)

(9)
2.3 卷积神经网络层
2.3.1 卷积层
卷积过程相当于对输入矩阵的一个滑动窗口进行乘积求和的过程,用来提取特征。在文本处理中,卷积核通常覆盖上下几行的词,因为句子矩阵的每一行代表一个词的词向量,因此卷积核的宽度和模型的输入宽度一样,句子矩阵维度为n×(dw+2×dp),在卷积过程过采用Nguyen等[15]的多尺寸卷积核方法来提取更多的n-gram特征,在实验中取卷积核的高度分别取Hi∈{2,3,4,5},卷积运算过程如下所示:
(10)
其中,W1∈RHi×(dw+2×dp),Hi表示卷积核的高度,b表示偏置,f为非线性激活函数,这里使用ReLU函数:
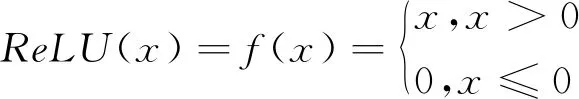
(11)
通过不同尺寸的卷积核计算,最后的结果为:
C=[c1,c2,…,cn-Hi+1]
(12)
2.3.2 池化
池化层(Pooling)也称为下采样层,主要用来对卷积层提取的特征进行降维,得到最终表示句子整体信息的高级特征。池化层能够缓解过拟合且提高模型的容错性。常用的池化操作有2种:最大池化(Max Pooling)和平均池化(Average Pooling),本文模型采用最大池化策略进行特征选取。在卷积层中的每个卷积核得到一个向量,选取向量中的最大的值作为池化层提取的特征。
pi=max(C)=max(c1,c2,…,cn-Hi+1)
(13)
此方法输出的特征pi是一个固定维度的向量,和输入句子的长度无关,此向量维度取决于和卷积层中卷积核的个数,之后每个句子得到一个相同维度的特征向量:
Z={p1,p2,…,pm}
(14)
其中m是卷积核的个数。这样就很好地解决了输入句子长度不一致的问题。
2.4 输出层
2.4.1 分类
在此层将池化层得到的特征值组合为特征向量,并将其作为全连接层的输入进行分类,本文使用Softmax分类器进行分类,为了防止模型产生过拟合现象,采用dropout[16]的方法。dropout以一定概率随机丢弃某些神经元,从而减少冗余,增加特征之间的正交性。其表述如式(15)所示:
x(i)=r·Z
(15)
其中,r是伯努利随机变量的向量,Z为句子经过池化后得到的特征表示,x(i)为第i个输入经过模型提取后的有效特征向量。输入样本属于每一类别的概率为:
(16)
其中,x(i)为第i个输入经过模型后的有效的特征。y(i)为预测的输入实例x(i)的类别,k为数据集中总的类别数。θj为整个模型中可学习的超参数。由式(16)可以得到当前输入样本属于每个类别的概率。
2.4.2 模型训练
在模型训练中采用交叉熵(Cross Entropy)作为损失函数。交叉熵用于度量2个概率分布间的差异性,值越小表明两者之间的差距越小,反之越大。在损失函数中加入L2正则化来防止过拟合,本文模型损失函数如下所示:

(17)
其中,λ为L2正则化的系数。在模型的优化过程中,采用小批量梯度下降法(Mini-batch Gradient Descent)更新迭代权值,其运算速度快,并且也解决了结果的随机性,所以本文选择小批量梯度下降法来更新参数,使用反向传播方法进行参数调整。即:
(18)
其中,μ为学习率。
3 实验与分析
3.1 数据集和评价体系
3.1.1 数据集
本文采用SemEval-2010 Task 8数据集和SemEval-2007 Task 4数据集进行实验,它们是专门用来做实体关系抽取任务的数据集。
SemEval-2010 Task 8数据集中总共有10 717条数据,其中包括8 000条训练数据和2 717条测试数据。该数据集包含9类带有方向的关系和1类不带方向的other关系。句子中2个实体的方向不同将被视为2种不同的关系,这种关系叫带有方向的关系。
SemEval-2007 Task 4数据集中包含7种不带方向的关系类别,共包含1 529个关系实例,其中980条训练数据和549条测试数据。
3.1.2 评价标准
为了评价本文模型是否有效,采用数据集中官方文档中的评价指标macro-averagedF1[17]值进行评价。要计算macro-averagedF1的值,必须先计算出每个类别的准确率(precision)、召回率(recall)和F1值,最后求整个数据集的平均F1值。
(19)
其中,TPi为第i类关系中分类正确的实例个数,FPi是将其他类别的实例错误分为第i类的实例个数,FNi为将第i类的实例错误分为其他类的实例数。最终通过计算可以得到macro-averagedF1值。
(20)
其中,k为数据集中总的类别数。
3.2 实验参数的设置
实验中的词向量使用Mikolov等[12]预先训练好的300维的词向量,位置向量的维度取50维。使用小批量梯度下降法来学习网络中的参数,最小样本值为20。为了提高训练速度,本文模型使用指数衰减法来设置学习率,学习率初始值为1.0,衰减系数为0.9。使用dropout方法和L2正则化来抑制过拟合现象,取dropout rate的值为0.5。L2正则化的系数λ取值为10-5。模型中的其他参数矩阵采用高斯分布进行随机初始化。通过比较不同参数下的结果,本文模型最优结果参数设置值如表1所示。

Table 1 Hyperparameter setting values
在卷积过程中,卷积核的大小表示在卷积中提取特征的范围,卷积核过大或过小都会影响特征的提取。为了提取到更多的有效信息,本文采用了Nguyen等[15]的多尺寸卷积核进行实验,因此分别取卷积核的高度为2-gram,3-gram,4-gram,5-gram在2个数据集上实验分别得到相对应的F1值。使用多尺寸过滤器能够获得更多的卷积特征。同时使用2-gram,3-gram,4-gram,5-gram时,在2个数据集上得到的F1值分别达到最大值84.46%和83.23%。具体情况如表2所示。

Table 2 Effect of filter size on F1 value
在模型训练的时候采用了dropout的方法来防止模型过拟合。当dropout rate的值分别取0.5和0.6时,在SemEval-2010 Task 8和SemEval-2007 Task 4数据集上取得了最好的F1值,如图3所示。

Figure 3 Effect of dropout rate on F1 value图3 dropout rate对F1值的影响
3.3 实验验证
为了验证本文模型对于实体关系抽取的稳定性和有效性,采用对比实验方法,分别在2个数据集上与多种模型进行对比。本文分别用CNN、BRNN(Bi-directional Recurrent Neural Network)、BLSTM(Bi-directional Long Short-Term Memory)和本文模型进行对比,都采用统一的词向量和位置向量作为模型的输入,表3和表4所示为不同的4种模型在2个数据集上的precision值、recall值和F1值结果。

Table 3 Experimental results comparison on SemEval-2010 Task 8

Table 4 Experimental resutls comparison on SemEval-2007 Task 4
由表3和表4中的实验结果可以发现,在使用同样输入的前提下,BLSTM的效果比CNN和BRNN的效果要好,BLSTM是双向长短期记忆网络,可以缓解长距离特征获取的问题,能够提取到长句子中距离较远的有效特征,但是效果还不是很好。
本文模型比CNN和BLSTM模型的效果更好,在使用同样输入的情况下,在注意力机制中计算词的上下文依赖信息的时候,本文模型对句子序列中的所有词直接两两进行相似性计算,忽略了2个词之间的距离,能更加有效地捕获到词在整个句子中的上下文依赖信息,使得通过自注意力层得到的词向量表达出更加丰富的语义信息。因此,卷积神经网络能够捕获到有效的句子的高级特征,弥补了用卷积神经网络提取句子特征的局限性。

Figure 4 Comparison of models on SemEval-2010 Task 8图4 SemEval-2010 Task 8上模型的对比图

Figure 5 Comparison of models on SemEval-2007 Task 4图5 SemEval-2007 Task 4上模型的对比图
如图4和图5所示,本文模型在训练样本迭代训练次数到50时已经趋于稳定,其他的模型需要等到80次迭代时才能逐渐趋于稳定。由此可知,采用自注意力机制能够更好地考虑句子序列中词的上下文依赖信息,从而更好地捕获句子的全局信息,所以本文模型稳定性更好。采用同样的输入,在2个数据集上只采用卷积神经网络模型的F1值分别为80.72%和79.72%,利用自注意力机制和卷积神经网络融合的模型的F1值分别达到了84.46%和83.23%。由此可以说明,本文模型可以很好地解决在卷积神经网络中利用固定大小的卷积核来提取句子序列中词的上下文的限制问题。
4 结束语
本文在卷积神经网络进行实体关系抽取的基础上引入了多头自注意力机制,和其它使用深度学习进行实体关系抽取的方法相比,本文模型采用自注意力机制能够在句子内部学习到更加丰富的词的上下文语义信息,在通过自注意力层之后将词的位置向量特征加入句子序列,从而保证了序列的顺序信息,使得卷积神经网络能够提取到更加有效的句子全局特征。实验表明,本文模型在实体关系抽取上取得了良好的效果,但是此模型只能用在已标注数据的有监督的关系抽取中。在接下来的工作中将考虑以下2个方面:(1)尝试引入更多的有效特征作为输入来提高模型的性能。(2)有监督的关系抽取在标注数据的时候还是比较困难的,在远程监督的实体关系抽取方面的工作还比较少,因此,在后续的学习中,我们应该考虑将模型扩展到远程监督[19]实体关系抽取中。
