基于关联数据本地化的多密码作业流调度算法 *
2020-11-30关川江李建鹏史国振
关川江,李建鹏,史国振,毛 明
(1.西安电子科技大学通信工程学院,陕西 西安 710071; 2.北京电子科技学院电子与通信工程系,北京 100070)
1 引言
密码服务是一种由安全协议、密码算法、密码基础设施、密码芯片等密码相关设备和系统提供的服务,包括加密、解密、数字签名、认证等安全服务和密码资源管理服务等[1]。云环境中密码服务的应用不仅可以促进安全可靠云计算体系的建设,也可以有效简化密码模块的设计与实施,使得密码技术的使用更集中、规范和易于管理[2]。采用集中式部署方法将密码机集群资源池化,实现对“密码资源集中管理、虚拟化共享、内网调度、外网专用”,是当前密码服务云的主流实现方法[3]。
工作流调度是在云资源上执行高度相互依赖任务的过程,其主要目的是实现用户任务与云中计算资源的最优匹配,以最大化资源吞吐量[4],是一个著名的NP-Complete类问题[5]。云计算中的资源调度工作主要包括发现资源和过滤资源、选择目标资源、将资源分配给目标任务等步骤[6]。异构系统基于列表的任务启发式调度算法中,RR(Round-Robin)[7]通过建立处理资源循环列表,将就绪任务轮流分配给各处理节点,直至所有有效任务都被成功分配到对应节点中等待执行。异构最早完成时间HEFT(Heterogeneous Earliest Finish Time)[8]、预测最早完成时间PEFT(Predict Earliest Finish Time)[9]、约束最早完成时间CEFT(Constrained Earliest Finish Time)[10]、最小化调度长度MSL(Minimizing Schedule Length)[11]和异构选择值HSV(Heterogeneous Selection Value)[12]等算法,都是通过平均处理时间和平均通信时间决定任务调度的优先级,具有调度效率高、算法复杂度低等优势。其中,HEFT首先预计算所有任务在各个处理节点上的完成时间,然后将任务依次调度至其对应的具有最小完成时间的处理节点上运行,为了适应在复杂异构集群环境中的作业流调度系统性能需要,不少研究学者在该算法基础上进行了深入探讨并提出了各自有效的解决方案[13,14]。针对有限资源环境中多作业流的调度问题,Zhao等人[15]描述了一种有向无环图DAG(Directed Acyclic Graph)相对于当前时刻滞后程度的量化方法,根据每个任务的滞后程度确定任务调度的优先级,从而解决了多作业流执行中的公平性问题。Bittencourt等人[16]分析了在网格中调度多个作业流时,4种不同策略对调度长度和公平性的影响。Wu等人[17]采用包括遗传算法、蚁群优化和粒子群优化等基于包的元启发式随机调度算法,提出了一种面向市场的云工作流分层调度策略(Market-Oriented Hierarchical Scheduling Strategy),有效提高了任务调度效率,同时在完成时间、执行成本等方面取得了良好的优化效果。
上述各方案在传统应用作业流的调度系统中都表现出了良好的性能,但都存在关联数据本地化差的问题,即无法保证将数据依赖性作业流的各个子任务分配至同一处理节点上执行。对于密码作业流而言,当数据依赖性作业流的不同子任务被部署于不同处理节点上运行时,节点之间运算信息的交互过程不仅加大了系统通信性能的开销和任务处理过程中密钥匹配的难度,同时也为整个密码服务系统的处理数据安全性带来了严峻威胁。
2 模型描述
2.1 任务模型描述
本文利用有向无环图DAG来对作业流JOB=(T,E)进行建模,其中T={T1,T2,…,Tn}是任务节点集合,E是节点之间的边集合,边的属性用于标识相邻2个任务之间是否存在关联数据,取决于任务所在作业流的数据依赖性标识。有序边起点处对应的任务节点称为终点处任务节点的直接前序任务,终点处对应的任务节点称为起点处任务节点的直接后继任务。没有直接前序任务的任务节点称为入口任务,没有直接后继任务的任务节点称为出口任务。对于∀ei,j∈E,若ei,j=1,则表示T上2个任务节点Ti,Tj∈T之间存在关联数据和执行依赖顺序,这意味着在完成任务Ti之前不能调度任务Tj;若ei,j=0,则表示2个任务节点Ti,Tj∈T不属于数据依赖性任务,其调度过程没有先后之分。
如图1所示的作业流,共有4个作业流集合,分别为:JOB1={T1,T7},JOB2={T2,T5,T8},JOB3={T3,T6,T10,T12},J4={T4,T9,T11}。其中,作业流JOB1、JOB3和JOB4中各任务之间的边权不等于0,为数据依赖性作业流;作业流JOB2中各任务之间的边权等于0,不存在关联数据,为非数据依赖性作业流。就JOB3而言,任务T3是整个作业流的入口任务,也是任务T6的直接前序任务;任务T12是整个作业流的出口任务,也是任务T10的直接后继任务。对于任务集合T中的任一任务Ti,可以用一个多元组表示:
Ti={j_id,num,cmd,cyp,long,flag,data}
(1)
其中,j_id为任务所属作业流标识,也是密码服务系统中请求作业流的唯一标识,属于同一作业流的各任务具有相同的j_id属性;num为任务在其所属作业流中的唯一标识,属于同一作业流的各任务具有不同的num属性,属于不同作业流的任务的num属性可能相同,该属性与j_id结合使用以保证任务处理中密钥信息的快速匹配和处理结果的正确返回;cmd为任务的处理命令,常见的密码服务处理命令有加密、解密、签名、验签和Hash运算等;cyp为请求任务所使用的密码算法标识,包括该服务系统所支持的所有序列密码算法、分组密码算法、公钥密码算法和Hash算法等,该属性结合cmd决定作业流任务所请求的密码运算功能;long为该任务中待处理数据的大小;flag是任务所在作业流的数据依赖性标识;data是任务中待处理数据集。

Figure 1 Job stream DAG图1 作业流DAG
在密码服务中,存在着许多数据依赖性作业流,如Hash函数的运算过程以及分组密码加解密采用的CBC(Cipher Block Chaining)、OFB(Output FeedBack)、CFB(Cipher FeedBack)等工作模式中,直接前序任务的运算结果会作为输入条件之一参与其下一任务的数据运算。假设JOB4是工作于CFB模式下的AES加密服务请求作业流,则入口任务T4在经加密运算后的输出密文会作为输入,生成加密其直接后继任务T9的会话密钥;同样地,任务T9的加密运算结果又会作为任务T11会话密钥的生成输入条件,直至完成对出口任务T11中数据的加密运算,即可结束整个工作流的服务运行。完整加密过程如图2所示。

Figure 2 Complete procedure of AES encryption in CFB mode图2 AES密码算法的CFB加密模式
可见,对于密码服务请求,其中任一作业流的入口任务与其它任务之间不存在关联数据,在该类任务的调度过程中可与非数据依赖性作业流中的任务采取同一处理策略;而数据依赖性作业流中非入口任务与其直接前序任务之间存在着不可忽略的关联数据,用于该类任务运算处理的处理节点之间也需要进行大量的数据交互。如何保护该类任务之间关联数据交互过程中的安全性,同时避免整体服务系统因该过程而导致的通信性能开销和作业流密钥匹配难度,是本文算法的主要研究目标。
特别说明的是,本文只考虑单一处理命令请求的密码作业流。对于复杂处理命令请求作业流,如需要对某一明文数据进行Hash运算后,再对Hash运算结果利用公钥密码算法进行签名时,则可以将Hash运算和签名运算分别作为2个独立的具有单一处理命令的密码作业流进行处理。
2.2 处理节点模型
云密码服务系统是一个典型的分布式异构系统,云中各密码处理节点的密码实现功能、数据处理速率、数据传输速率等特性都存在着巨大差异。为了实现密码计算资源的按需配置,简化管理与调度的流程,对处理节点的状态信息进行统一定义和描述:
Nj={func,comput,commun}
(2)
其中,func表示对应处理节点可实现的请求密码功能,与任务的cmd属性和cyp属性相对应;comput表示处理节点的数据处理速率;commun表示处理节点的数据传输速率。
对于密码服务系统中的任一数据依赖性作业流,当其入口任务按照相关调度策略被分配至某处理节点时,则该作业流中其余所有后继任务与各节点之间的关联数据量就已经被确定,为本文关联数据本地化的实现提供了理论依据,可以表示为处理节点-任务关联数据矩阵(N-T)。以图1中JOB3作业流为例,假设已经完成对其入口任务T3的调度并将其分配至标识为N3的节点,则此时处理节点-任务关联数据矩阵为:
N1N2N3N4…Nn
(3)
容易发现,数据依赖性作业流中的每个后继任务只与其直接前序任务的处理节点之间存在关联数据,与其余节点之间的关联数据均为0。
3 关联数据本地化密码调度算法
3.1 相关参数定义
为了方便描述本文调度算法的设计思路与工作过程,对该算法的相关参数及性能属性进行如下形式化定义:
定义1(任务执行代价W(Tk)) 任务执行代价是指在目标运算节点的数据处理速率下运算完成当前任务所需的时间。对于标识为Nj的处理节点,则任务Tk所需的执行代价为:
(4)
定义2(作业流的MakespanM(a)) 作业流的Makespan是指JOBa中最后一个任务执行完成所用的时间:
(5)
其中,a表示作业流,NTar表示调度系统为任务Tk分配的运行节点,Ti→NTar表示在任务Tk之前所有已分配至节点NTar上等待执行的任务。
定义3(任务完成时间O(s)) 任务完成时间是指在调度算法s驱动下,系统运行完成指定任务集所需要的时间,因此,定义任务完成时间为作业流集中作业流的最大Makespan值。
定义4(运行节点负载L(Nj)) 运行节点负载即各目标运行节点的实时负载情况,可以用所有分配至该运行节点的任务执行代价之和来表示:
(6)
其中,∀Ti→Nj表示所有调度至Nj的任务。
定义5(资源利用率U(Nj)) 资源利用率可以有效标识系统资源单位时间的使用效益,平均资源利用率也是系统资源间负载状况的衡量指标。系统中运算节点Nj的资源利用率定义为调度至Nj的所有任务的运行时间之和与任务完成时间的比值:
(7)
设调度系统中共有|N|个运算节点,则调度算法s的平均资源利用率为:
“坚持创新发展,就是要把创新摆在国家发展全局的核心位置,让创新贯穿国家一切工作,让创新在全社会蔚然成风”。以理论创新为引领,大港油田抓住油藏渗流场这个关键,开展精细油藏描述地质模型升级研究,建立基于油藏地球物理的地质模型研究方法,提高地质模型研究精度;攻关渗流地球物理基础理论,建立基于时移的多维的油藏渗流地球物理地质模型,提升模型的时效性;开展渗流场重构基础理论研究,建立多参数渗流描述模型、多维度流场评价模型和多方案的驱替模型。
(8)
定义6(不公平因子F(s)) 不公平因子是衡量多作业流调度算法s公平性的重要指标。由于多作业流共享有限运算资源,所以JOBa的调度长度很可能比单独运行JOBa时要长,假设Mown(a)为单独运行JOBa时的调度长度,则JOBa的Sslowdown为:
Sslowdown(a)=M(a)/Mown(a)
(9)
那么,调度算法s的不公平因子为:
(10)

(11)
3.2 算法设计
在密码作业流服务系统中,数据依赖性作业流与非数据依赖性作业流随机交叉并发,其中数据依赖性作业流的入口任务和非数据依赖性作业流的各任务之间不存在关联数据,因此该类任务的处理过程没有数据本地化要求,节点资源的选择调度更加灵活,可以按照任意先后顺序为其匹配最优处理节点;而数据依赖性作业流中非入口任务与其直接前序任务之间存在着严格的执行顺序约束,如果直接前序任务未能得到及时处理,则会严重阻塞该作业流中所有后续任务的执行,同时应保障关联数据交互过程的安全性,避免数据迁移带来的传输时延和通信代价。本文调度算法结合系统中各计算节点的实时负载状态,采取数据依赖性作业流和非数据依赖性作业流分类调度的思想,一方面针对存在关联数据的任务实现关联数据本地化处理,另一方面针对不存在关联数据的任务,尽可能实现系统在作业流处理中数据吞吐率、资源利用率和调度公平性最大化。调度结果在保障系统中所有任务请求密码功能正确实现的基础上,有效提高密码服务系统的安全性与系统性能。
针对多作业流共享有限运算资源的应用问题,为了促进各作业流调度过程的公平性,在参考HEFT算法的同时,由于本文算法对数据依赖性作业流的非入口任务进行了关联数据本地化处理,因此避免了用于处理该类任务不同处理节点之间关联数据的通信代价,从而在确定不同作业流以及同一作业流中各任务优先级时,只考虑任务的执行代价:
(12)
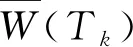
(13)
其中,Texit是出口任务。
策略1对于数据依赖性作业流的非入口任务,作业流调度单元统一维护作业流分配表,用于记录分配至各处理节点的作业流历史信息,通过在该表中查询与当前作业流标识j_id所在记录的处理节点标识,将当前任务分配至该处理节点,从而将后继任务与其直接前序任务分配至同一处理节点上运行,实现了前后任务关联数据的本地化,避免了数据交互过程产生的传输开销和安全性威胁。
策略2对于数据依赖性作业流的入口任务和非数据依赖性作业流的各任务,由于该类任务之间不存在关联数据,其处理节点资源调度方法比较灵活,因此,通过设计良好的调度策略,可以有效弥补因其他任务运算过程关联数据本地化需求而导致的系统性能下降问题。为了提高任务处理的实时性和系统负载均衡性能,减少任务的等待时间,从而将该类任务分配至当前系统时刻具有最小负载的运行节点上等待执行。
此外,为了减小数据依赖性作业流运行节点的任务负载,预留较为充足的资源用于该类作业流中后续任务的处理。
在利用策略2完成任务Tk调度后,目标运行节点NTar的负载更新规则为:
(14)
4 算法仿真与性能分析
在Windows环境下,通过C语言编程对算法进行仿真与性能测试,并在不同的CCR(CCR是通信代价与执行代价的比值。对于单位任务,处理节点的通信代价=W(·)×CCR)值设置下,对本文算法、HEFT和RR 3种算法的任务完成时间、平均资源利用率和不公平因子随数据依赖性作业流占比的变化情况进行了对比与分析。由于不同请求密码功能任务间的调度过程相似,故设置具有相同请求密码功能的任务队列进行算法的仿真与性能测试。
首先生成300个单位任务,并将所有任务随机分配给30个独立作业流,然后根据数据依赖性作业流占比从中随机选择作业流修改各自对应的数据依赖性标识;设置处理节点群中处理节点数目为4,对于单位任务各节点的执行代价W(·)∈{30,40,50,60};作业流任务集各属性设置方法如表1所示。

Table 1 Job stream task property settings
4.1 任务完成时间
按照上述方法设置处理节点群中各节点及任务属性,并当CCR值为0.1,0.2,0.3时,分别测试3种算法的任务完成时间(单位时间个数)随数据依赖性作业流占比的变化情况,如图3所示。与其他2种调度算法相比,本文算法对数据依赖性任务进行了关联数据本地化处理,在任务的运算过程中产生的通信代价为0,有效避免了CCR值对服务系统性能的影响。此外,与RR算法相比,本文算法更加精确地考虑了处理节点群中各节点的性能异构,从执行代价角度衡量了各节点的实时负载情况,显著减少了服务系统的任务完成时间;与HEFT算法相比,本文算法在完成数据依赖性作业流入口任务的调度后,采用提前预算完整作业流执行代价的方式,预留较为充足的资源用于该类作业流中后续任务的处理,在减少任务完成时间的同时,避免了数据依赖性作业流占比对服务系统性能的影响,提高了系统的稳定性。

Figure 3 Task completion time changes with the proportion of data-dependent job streams图3 任务完成时间随数据依赖性作业流占比的变化
4.2 平均资源利用率
保持运行节点及任务属性不变,当CCR值为0.1,0.2,0.3时,分别测试3种算法的平均资源利用率随数据依赖性作业流占比的变化情况,如图4所示。同样地,由于关联数据本地化的引入,CCR值不影响本文算法的平均资源利用率。通过执行代价标量节点负载和提前预算数据依赖性作业流执行代价的方式,本文算法有效改善了异构系统中各处理节点间的负载均衡,提高了系统整体资源利用率。

Figure 4 Average resource utilization rate changes with the proportion of data-dependent job streams图4 平均资源利用率随数据依赖性作业流占比的变化
4.3 不公平因子
保持运行节点及任务属性不变,当CCR值为0.1,0.2,0.3时,分别测试3种算法的不公平因子随数据依赖性作业流占比的变化情况,如图5所示。在多作业流共享有限运算资源的环境中,相比于RR算法,本文算法的不公平因子显著降低,并且受数据依赖性作业流占比的影响较小,具有较好的稳定性,但略高于HEFT算法,这是因为2种算法在处理单一作业流时的工作过程和调度结果完全一致,而在多作业流场景中,本文算法具有更小的Makespan,这是由于HEFT算法在该场景下是以增加任务完成时间为代价导致的。

Figure 5 Unfair factor changes with the proportion of data-dependent job streams图5 不公平因子随数据依赖性作业流占比的变化
5 结束语
针对云密码服务系统中多作业流、多算法、多命令、多工作模式随机交叉情况下的密码应用需求,本文提出了一种基于关联数据本地化的密码作业流调度算法,避免了因数据依赖性任务间关联数据的交互而导致的系统通信性能开销,进一步提高了处理数据的安全性,为系统设计者简化了密钥匹配和中间状态管理的难度。此外,仿真实验表明,该算法在提高系统任务执行效率、资源利用率和公平性等方面具有显著优势,并且在不同CCR值和数据依赖性作业流占比情况下表现出了良好的稳定性。
