大数据在地质矿产中的应用探究
2020-11-28汪涛
汪 涛
(甘肃省地质矿产勘查开发局水文地质工程地质勘察院,甘肃 张掖 734000)
大数据是在二十世纪八十年代由全球知名咨询公司麦肯锡在研究报告中首次提出,在该研究报告中定义大数据为通过网络技术对数据进行获取、处理、分析,从中提取到海量的有价值的交易数据或传感数据[1]。
麦肯锡在研究报告中指出,大数据已经渗透到各行各业中,逐渐成为重要的生产因素,预示大数据时代即将到来。随着网络技术的快速发展,大数据技术正在逐渐成熟,国内外相关研究中又对大数据有了新的定义,是从大量的网络数据中提取出有用的数据进行处理,并且提取到的数据具有一定的关联关系和分析价值。
大数据因具有处理效率快、存储安全性高、分析精度高等优点,已经被广泛应用到各个领域中,其中就包括地质矿产。大数据在地质矿产中的应用,有效提高了地质矿产勘查数字化水平,使地质矿产行业迈向了一个新的阶段,为此提出大数据在地质矿产中的应用探究。
1 大数据在地质矿产中的应用
地质矿产勘查从数据化到信息化转变的过程,离不开数据处理、存储、分析,本文主要对大数据在地质矿产数据处理、存储及分析三方面的应用进行详细研究。
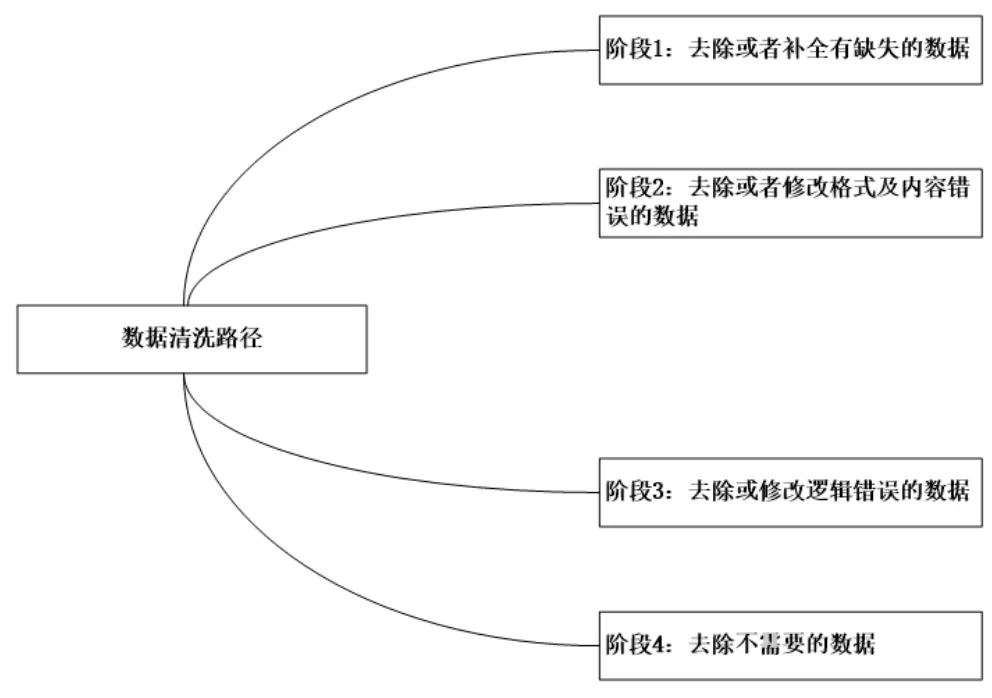
图1 基于大数据的地质矿产数据清洗路径图
1.1 地质矿产数据处理
大数据对矿产地质数据处理主要分为数据清洗、数据降维两部分,其中大数据技术对地质矿产数据清洗主要体现在以下两个方面:一是利用大数据技术检查并消除异常数据;二是利用大数据技术检查并消除比较相似的数据。大数据对于地质矿产数据清洗处理过程如下:首先将地质矿产数据导入到大数据处理工具中,如果地质矿产数量达到千万级以上,可以使用大数据处理软件中的Python操作处理。在Python操作界面中可以观察到元数据属性,查看到格式、内容、逻辑错误的数据。对于该类数据清洗处理的方式有两种,一种是直接将其删除,另一种是对其进行修改。两种处理方法应当根据数据的重要性进行选择,如果出现错误的地质矿产数据对后续地质矿产分析不造成影响,可以选择第一种;如果出现错误的地质矿产数据对后续地质矿产分析结果造成直接影响,选择第二种处理方式,采用插补的方式对残缺和错误的数据进行补全完整,选取与残缺数据相同属性的一组数据,计算出该组数据的均值、众数以及中间数,然后使用该属性的计算值对残缺数据进行插补,图1为基于大数据的地质矿产数据清洗路径图。
对于清洗过后的地质矿产数据还需要利用大数据技术对其进行降维处理,降维处理的目的是为了简化地质矿产数据属性,为后续地质矿产数据存储提供方便。大数据技术对地质矿产数据降维处理具体操作为:首先将一个大型地质矿产数据集划分为多个不同的小数据集,然后建立一个目标数据特征子集模型,假设地质矿产数据中包含了F个特征信息,通过特征选择选出H个最具有代表性的特征构成新的特征矢量D,在进行特征选择的过程中,不会丢失掉单个重要信息的特征,但若需要较小一部分的特征子集,且在原始的地质矿产数据特征又不相同的情况下,应当选择不会造成信息丢失的特征[2]。为了避免地质矿产数据在降维处理过程中丢失,当原始的地质矿产数据特征不相同时,需要利用大数据特征提取技术进行降维处理,大数据特征提取是利用映射函数将特征从原始的数据空间映射到新的特征子空间当中。提取的特征矢量可表示为K,K经过变换函数变换降维后得到新的特征矢量。特征提取能够在不丢失原始数据特征空间信息的情况下,减小原始大数据特征空间的规模,从而达到降低特征维度的目的。当利用大数据技术对复杂属性地质矿产数据进行降维处理时,要根据地质矿产数据的特征选用适当的方法,若地质矿产数据中的特征是相互独立的个体,则选用大数据特征选择技术更加方便快捷;若地质矿产数据中的特征之间具有关联性、不独立,则应选用大数据特征提取技术对矿山地质数据进行降维处理,通过执行特征的函数变换,消除特征之间的相关性。在进行数据降维时也可将两者综合利用,首先进行特征选择,将选出的一部分具有代表性的特征施加数学映射变换,其次,再将原始数据空间映射到新的子空间中,达到双重降维处理的效果,完成大数据技术对地质矿产数据处理。
1.2 地质矿产数据存储
大数据对矿产地质数据主要采取分类存储的方式,将处理过后的矿产地质数据进行分类。首先将处理后的地质矿产数据进行排序,对于排序的准则函数设定一个阈值,方便后续的分类筛查工作。在排列好的地质矿产数据中,将对应的属性特征集合定义如下:

公式(1)中,D1、D2表示降维处理数据的特征矢量值。通过改变设定的数据准则阈值,筛选出与其相符合的数据。然后根据设定的判断阈值对数据样本的特征进行合理的排序,并以此作为分类依据,将处理后的地质矿产数据进行分类,将统一属性的数据整合到一个文件中。地质矿产数据主要分为地质矿石数据、地质化学数据、地质三维数据、地质影像数据以及地质图像数据五种,将地质矿山数据文件设定为CFH类型;将地质化学数据设定为CFHL类型;将地质三维数据文件类型设定为DID类型;将地质影像数据文化类型设定为SDIR;将地质图像数据文件类型设定为DIDI类型,将分类的数据以表格的形式存储到大数据分布式数据库中,下表为基于大数据的地质矿产数据分类存储表。
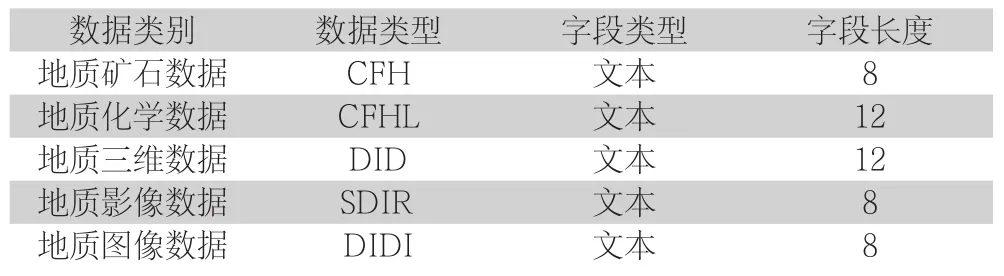
表1 基于大数据的地质矿产数据分类存储表
1.3 地质矿产数据分析
大数据在地质矿产数据分析中的应用,主要利用大数据中的三维建模及可视化技术,利用该两种大数据技术建立地质矿产三维可视化模型,并对模型进行分析,其过程如下:首先调取大数据分布式数据库中的矿产地质三维数据,运用HIGGV6.4软件对三维地质数据进行网格化,生成网格化数据集,网格化具体过程为:采用自然邻点法进行网格化,步长设定为250m;当网络小格数据大于或等于2时,用平均值对该小格进行赋值;将每个网络小格各元素的含量值归网至该小格中心点处,由此可以得到地质矿产三维模型。然后再将地质矿石数据、地质化学数据输入到建立好的三维模型中,对矿产地质数据进行曲线反演。通常做法是先做已知剖面或剖面已知地段的反演,总结出反演的原则和方法,再对未知区域进行反演,以此可以清楚的观看到矿产分布情况、矿床实际情况,推断出矿产具有分布位置,为后续矿产开采、确定靶区提供准确依据,实现基于大数据地质矿产数据分析,完成大数据在地质矿产中的应用探究。
2 结语
本文根据大数据在地质矿产中应用现状,着重对大数据技术在地质矿产数据处理、存储及分析中的应用进行了详细研究,有利于推广大数据技术在地质矿产中的应用,提高地质矿产勘查数字化、信息化、智能化水平,为地质矿产勘查技术及方法创新和开采提供理论依据,并且最重要的是可以促进地质矿产行业发展突破。大数据在地质矿产领域中的应用非常广泛,不仅仅只包含此次研究的内容,在地质矿产数据采集方面也具有良好的应用,今后会对大数据在地质矿产数据采集中的应用进行探究。
