“数据驱动+”模式在人员调度中的应用研究
2020-11-28李锋,许伟
李 锋,许 伟
(华南理工大学 工商管理学院, 广东 广州 510640)
一、引 言
随着人口红利的逐渐消失,中国经济增长逐渐面临着劳动力紧缺的问题。对于劳动力密集型的传统制造行业而言,招工难成为企业普遍面临的困境,甚至成为企业生存与发展的瓶颈。以广州市海珠区大塘村的纺织产业为例,即便是开出月薪1万元的条件也难以招到熟练的制衣工人,2019年此处的产业集群面临着迅速萎缩的尴尬局面。因此,如何通过合理调度企业的现有员工,在人员数量不增加的前提下满足企业的用工需求,成为企业迫切需要解决的现实问题。同时,多品种、小批量的产品生产特点,以及资源调度问题混合整数规划的计算复杂性(NP-Hard)天性,造成了当前企业所面临的人员调度问题非常复杂,难以求解。而市场需求的不确定性,特别是其随机性难以采用传统数学建模的方式建立其随机分布函数,使得资源调度问题难以建立其数学模型,模型求解更是无从下手。
然而,大数据技术的不断发展,“数据驱动+模型驱动”逐渐成为此类复杂应用问题的分析和求解范式。“数据驱动+”能够解决调度前端产品需求不确定性引发的需求建模困难问题,即并不强求于建立随机因素的分布密度函数或累计分布函数(数学表达式);而“模型驱动”能够实现应用问题的原始数据,而不是简化后的数学模型,与现有求解算法和算法引擎的无缝衔接。因此,大数据推动下的“数据驱动+”研究范式逐渐替代传统数学建模方法。本文也正是在此市场牵引、技术推动下,以具体制造企业的维修人员调度问题为研究对象,探索“数据驱动+”研究范式下的理论、方法和工具。
二、国内外研究现状
资源调度问题是运营管理领域中的经典优化问题。由于此类问题中资源(如员工、机器、设备等)通常要求取整数值,构建出的模型通常是NP-Hard问题,即问题求解的时间随着问题规模的增加呈现指数型增长。因此,各种启发式算法、智能优化算法被提出用于求解各种具体资源调度问题。其中,代表性研究工作包括:刘振元等[1]将启发式算法引入到分支定界法中,用于求解多技能资源时间窗约束下的人员调度问题;张扬等[2]设计了多条规则,采用启发式算法求解订单随机调度问题;袁彪等[3-4]在分支定界算法基础上采用分支定价算法求解家庭护理问题中的人员调度问题。然而,更多的求解算法是基于智能优化算法。例如,遗传算法[5-6]、启发式算法与遗传算法相结合的混合算法[7-8]、候鸟优化算法[9]、模拟退火算法[10]、粒子群算法[11-12]、离散烟花算法[13]与萤火虫膜算法[14]等。
将资源调度问题建模为一个混合整数规划问题,采用以上智能优化算法进行求解,能够实现问题求解。但是,随着研究的深入,现实问题中的不确定性和随机性因素导致问题的数学建模成为研究工作的瓶颈:问题中的随机性因素通常难以用一些常见的随机模型进行拟合。如果刻意为了数学建模而对研究问题进行简化,必然导致模型脱离了实际,模型的解释力度下降。例如,张扬等[2]将订单的生产时间和服务时间都分别简化为一个正态分布随机量,袁彪等[4]将服务时间简化为正态分布随机量,陈蓉等[5]将员工状态刻画为一个简单的马尔可夫链。而李磊等[12]则指出常见的理论模型难以刻画应用问题中的非线性和随机性,必须采用更加“复杂”的刻画模型。
随着大数据技术的不断发展和成熟,“数据驱动+模型驱动”的研究范式逐渐兴起[15]。在此研究范式下,应用问题中难以采用数学建模的部分直接用原始数据进行分析。因此,“数据驱动+”是对传统“模型驱动”研究范式的一个重要且有益的补充。但是,由于“数据驱动+”的研究范式对该领域专家提出了新的要求,目前对于此研究范式的应用主要集中在背景相对简单的场景。例如,许鹏程等[16]对网上用户的用户画像建模;宋小康等[17]对网络上信息(情报)的文本进行分析,对信息进行存储;尹忠博等[18]对科技类电子文献的文本进行分析等。这些应用领域即便在“数据驱动+”研究范式尚未提出之前就采取了类似的数据分析范式[19-20]。对于一些更加复杂的应用领域,“数据驱动+”研究范式的应用相对较少。其中,代表性工作包括:陈彬等[21]对社会问题的数据驱动和仿真模型驱动进行了论述何康乐[22]对网络安全领域的网络节点采取了数据驱动的在线筛选李胜会等[23]对基本医疗保险领域中的问题进行了分析等。本文鉴于研究问题的复杂性,探索“数据驱动+”研究范式在运营管理领域中的经典问题应用。
三、某制造企业的维修部门工作现状
(一)维修记录的基本信息及数据预处理
本文以一个代工制造企业的维修部门为例,研究该维修部门的维修工人的调度问题。从企业信息系统中获取维修部门的工作记录。整理后数据字段如表1所示。

表1 数据字段及含义对照表
表中,故障类型(C1)分为机械故障和电气故障两类;是否停机(C2)表明了故障对设备运行的影响;故障设备铭牌(C4)是发生故障设备的唯一标识,其分属不同的故障设备类型(C3);故障维修时间(C5)和故障解除时间(C7)记录了故障的实际维修时间。
原始记录数合计5 969条,时间跨度一年(2017年9月27日至2018年9月26日)。从数据中剔除重复的设备故障维修记录,并剔除维修工人工号(C6)为空的记录数,最终得到一年统计数据如表2所示。

表2 预处理后维修记录的汇总统计
对企业的维修员工进行工作量统计,发现30名员工中,部分维修员工全年的维修时间不超过100小时。过滤这些工作时间较短的员工后,对维修时间超过100小时的维修员工(人数为16人)进行每月和全年的工作时间统计。统计的结果如图1所示。
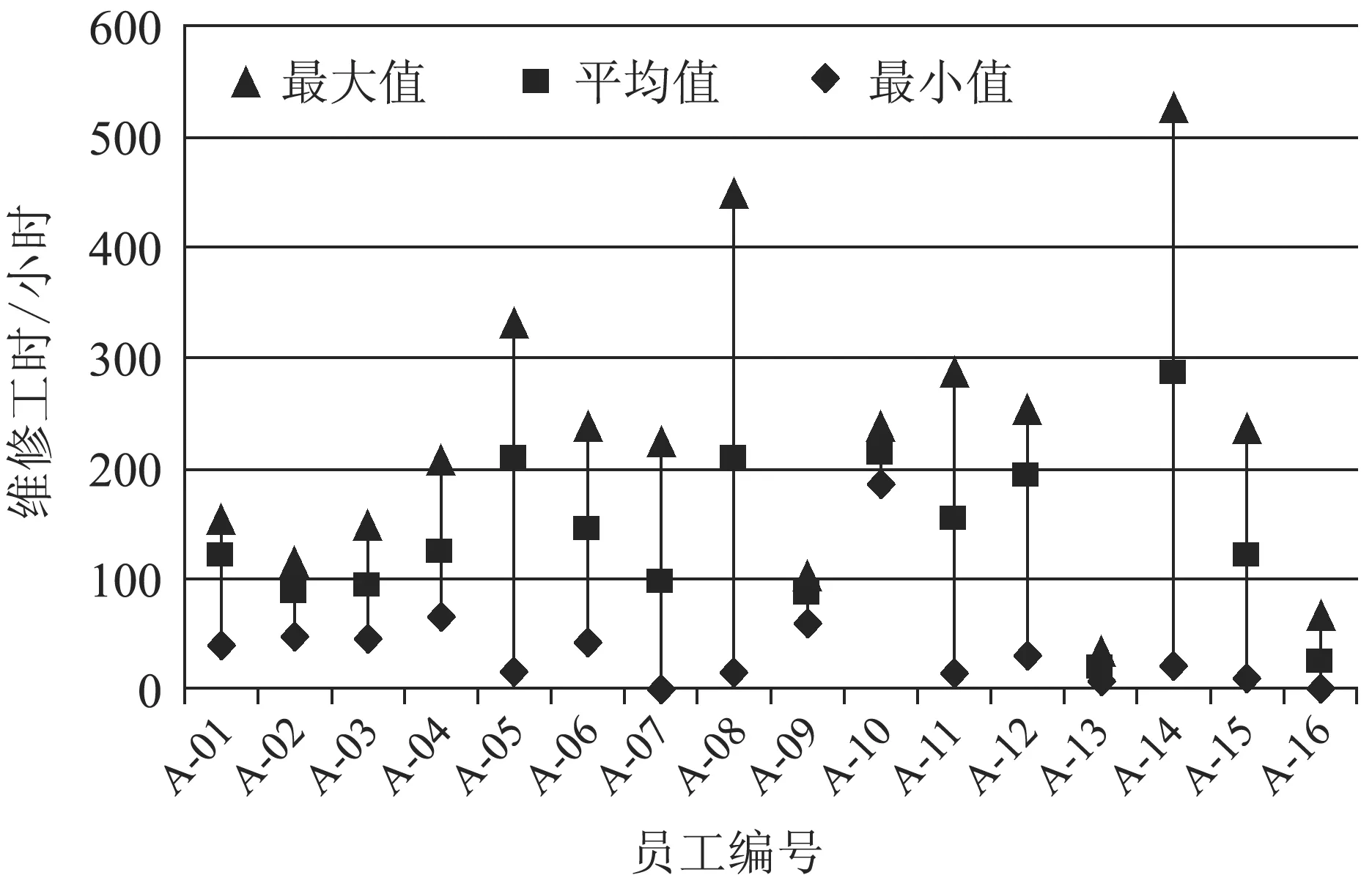
(a)部分员工每月工作时间统计

(b)部分员工全年工作时间统计
从图1可以看出,企业维修部门的16名员工实际工作时间差异较大,工作没有实现平均分配。因此,需要对维修部门的员工调度方案实施优化。
(二)设备维修的统计分析
为了实现对员工调度管理,需要对设备维修的“需求”进行分析和建模,即对设备维修任务进行分析。对设备维修任务的数量和工时需求进行统计分析,如图2所示。

(a)每日需要维修的设备数量

(b)每日维修需要的工时
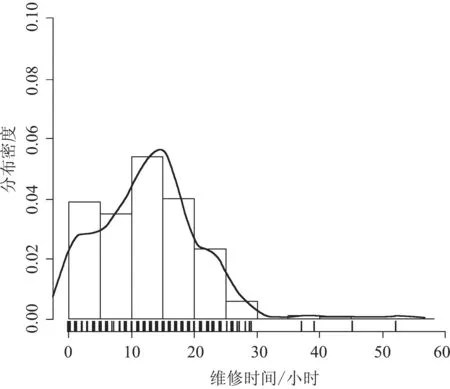
对这两组数据采用常见的随机分布模型进行拟合。结果表明,每天设备维修的所需工时不服从常见的分布形式,成为数学建模分析的瓶颈。
继续根据维修记录中的故障类型对每天维修所需工时进行分类统计,具体如表3所示。

表3 每日维修任务的分类统计
表3中无论是机械故障还是电气故障维修所需工时差异性较大,并且两类故障的日统计也无法采用常见的随机分布函数拟合,每日维修任务的分类统计直方图如图3所示。

(a)每日机械故障维修需要的工时

(b)每日电气故障维修需要的工时
如果按照自然月进行维修工时统计,得到的时间序列如图4所示。

(a)每月机械故障维修需要的工时

(b)每月电气故障维修需要的工时
从以上对机器故障的分类和分时统计可以发现,维修部门每个月的工时需求基本稳定。但是也存在少数几个月工时需求低于平均值50%,或高于平均值50%的现象。这个结果说明工厂设备维修员工的人数可以较好地被预测。但是,这些员工可能需要通过加班的方式应对部分工时需求较多的情况。
进而,对维修记录中维修总工时最长的设备进行维修时间统计,得到排名前4的设备单次维修时间的分布情况,如图5所示。

(a)排名第1位的设备54#

(b)排名第2位的设备19#

(c)排名第3位的设备24#
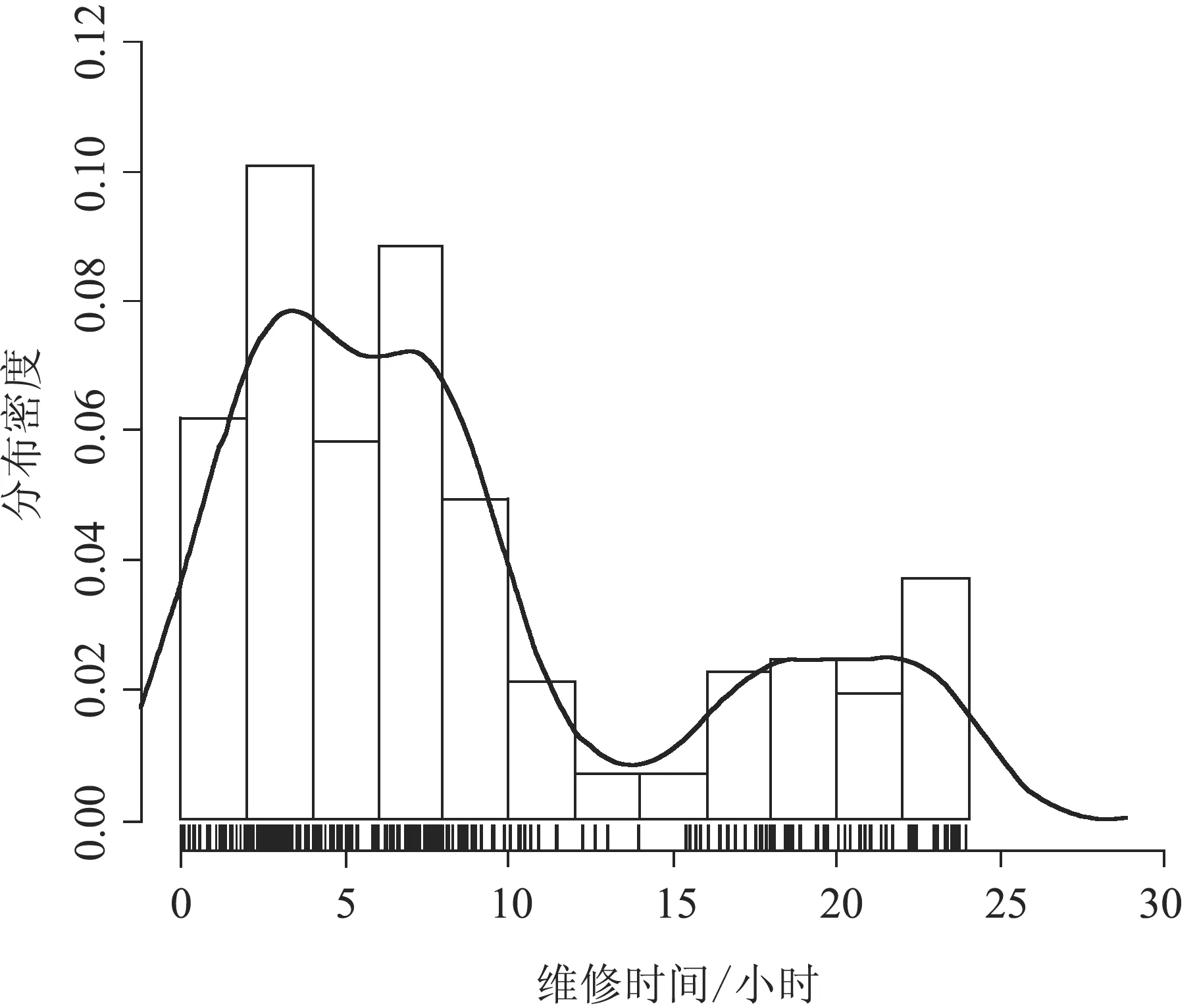
(d)排名第4位的设备10#
从图5可以看出,即使是同一类设备,单次维修的时间差异也较大。为了检验维修时间的长短是否与故障类型相关,我们以排名第1位的设备54#为例,进行分类统计。设备54#维修时间的分类统计如图6所示。
图6中,设备维修时间与故障类型无关,维修时间都呈现比较复杂的分布形式。
根据以上数据统计和分析,可以得到以下结论:企业维修部门的每日维修需求数量和工时呈现较强的随机性,差异性较大;每日维修需求无论是维修数量(故障数量),还是维修工时都难以用常规的数学模型进行拟合;即使是同一类设备,无论是机械故障还是电气故障,其维修时间同样难以用常规的数学模型进行拟合。
鉴于维修需求数学建模遇到的实际困难,下面将以“数据驱动+”的研究范式,即根据维修需求原始数据进行人员调度问题求解。

(a)机械、停机故障
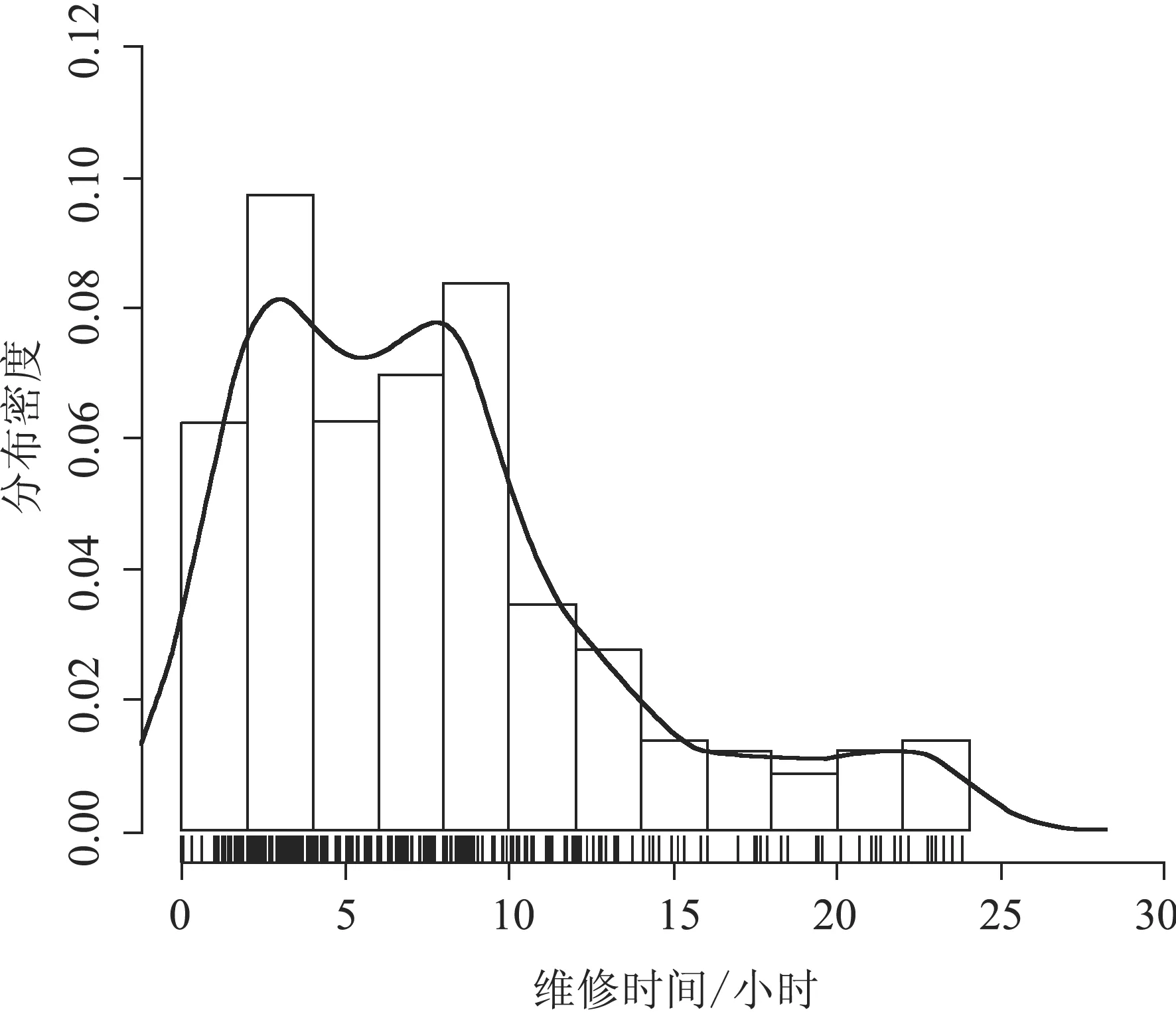
(b)机械、非停机故障
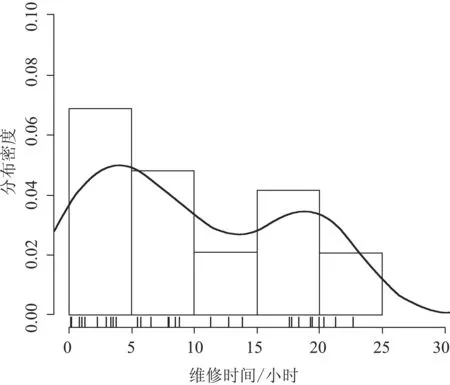
(c)电气、停机故障
(d)电气、非停机故障
四、维修部门员工调度问题求解
(一)维修部门员工的人员定额
根据当前企业一线员工的工作安排,可以知道部门每位员工:每周工作6天,每天正常工作8小时;每位每月总加班工时不超过20小时。据此,以月为基本单位,构建求解最优维修员工数量和调度的数学模型。以2017年11月为例,定义周一至周日每天休息的员工数量分别为xi(i=1,2,…,7),每天员工的总加班工时为yj(j=1,2,…,30),每天的实际维修工时需求为dj(j=1,2,…,30),目标为总员工人数Z最小:
(1)
用AMPL软件并调用混合整数规划C-PLEX求解引擎,求解问题[24]363-369。得到最优解为:
(2)

在这个月的30天中,有23天员工的实际工作时间要低于8个小时,7天员工需要加班。2017年11月最优的维修员工的实际工作情况如图7所示。

(a)28名员工正常工作时间和维修任务工时需求

(b)28名员工加班情况
作为对比,如果不加班,仅以员工的正常工作时间满足维修工时需求(yj=0.00,j=1,2,…,30),在式(1)基础上构建的问题模型如下,
(3)
求解得到的最优解为:
X*=[0, 5, 0, 0, 15, 26, 0],Z*=46
(4)
此计算结果远远高于最佳的人员配置,即企业按照维修工时峰值配置的员工数量,必然导致人力资源的浪费。
由于员工加班总时长为530.30小时,考虑到加班工资是正常工作时间工资的1.50倍,如果多招1名员工(1名员工能够工作25天,即工作200个正常工时),尝试以29名员工满足工作需求。此时,以员工的总加班时间最短为优化目标,得到调整后的问题模型如下:
(5)
求解得到的最优解为:
(6)
对比(6)与(2)的计算结果,可以知道增加1名员工只能降低加班时间52.53小时(530.30-477.77)。如果考虑加班成本,可以知道雇佣第29名员工,维修部门的成本实际增加了253.82%[200÷(52.53×1.5)]。
(7)
式(7)中,为了完成2017—2018年的维修任务,最为合理的员工数量为29个人(max{Z*(k)})。因此,设定员工数量为29人,以式(5)为模板重新计算每月的加班时间,最终得到加班时间为:
(8)
(二)专业技能/专业分工对员工调度的影响
假定维修部门的员工分为两类,一类员工仅能够完成机械故障的修理工作,另一类员工也仅能够完成电气故障的修理工作(在此设定下,原模型中维修员工为“全能型”员工,既可以维修机械故障,又可以维修电气故障)。因此,将每天的维修任务按照机械故障和电气故障进行分类,然后重新计算所需的员工数量。
计算得到机械故障维修员工的人数和加班情况如下:
(9)
同样,计算得到电气故障维修员工的人数和加班情况为:
(10)
将机械故障维修人员和电气故障维修人员的数量加在一起,可以发现当员工的专业技能有限时,企业的用工和加班工时都在增加。为满足全年的机械故障维修需求,需要24名机械故障维修人员。同样,为满足全年的电气故障维修需求,需要12名电气故障维修人员。
以24名机械故障维修人员和12名电气故障维修人员,重新计算每月的加班工时,得到结果如下:
(11)
(12)
将式(11)和(12)的结果与式(8)的结果对比,可以知道,专业分工及人数增加后,加班工时略有减少(2 559.65=2 014.10+545.55),但是加班状况并未实质解决。
(三)员工工资水平对调度的影响
从前文对2017年11月的员工调度分析中,可以知道通过增加员工数量来减少加班工时,其成本更高。因此,设定维修部门的维修员工具有不同的专业技能,但是工资水平有所差异。在此差异下,研究工资水平对人员调度的影响。
为了简化计算,本文设定每位员工的每月工资以200工时计算。并且,假定机械故障维修人员的工资水平为1.00,电气故障维修人员的工资水平为k1(0.70≤k1≤100),而原模型中“全能型”维修人员的工资水平为k2(0.70≤k2≤100)。
根据式(8)(11)(12)的结果,计算原模型全年的员工成本和专业分工后全年的员工成本的差值。该差值大于0,表明原模型成本更低,反之则专业分工的成本更低。具体结果如图8所示。

(a)电气故障维修人员工资系数k1对调度方案的影响

(b)“全能型”维修人员工资系数k2对调度方案的影响
如图8所示,当“全能型”维修人员的工资水平k2显著高于电气故障维修人员的工资水平时,根据故障类型调度不同维修人员,运营总成本会更低(图8(b)中,成本差值小于0);如果电气故障维修人员的工资水平显著低于机械故障维修人员的工资水平时,根据故障类型调度不同维修人员,运营总成本会更低(图8(a)中,成本差值小于0)。
(四)“数据驱动”对调度的影响
为了进一步检验“数据驱动”对人员调度问题的影响,继续以2017年11月的数据为例,对比“模型驱动”与“数据驱动”的差异性。
假定以星期为单位,统计得到一个星期中每天的设备维修工时需求的平均值。接着,以此平均值作为“模型驱动”下人员调度问题中需求数据,并以此构建问题模型(模型中假定一个月只有4个星期,因此员工的最多加班工时为5小时)。
对此问题进行求解,得到问题的解如下:
(14)
将此结果与式(2)所示的实际结果对比会发现:如果忽略实际问题中的波动性因素,工厂在人员配置上一定会出现短缺的情况。
如果将此人员配置应用到2017年11月,得到实际情况如下:
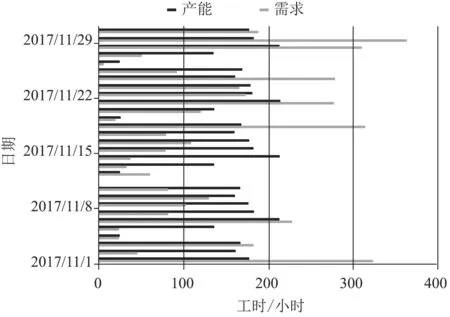
(a)供需情况对比
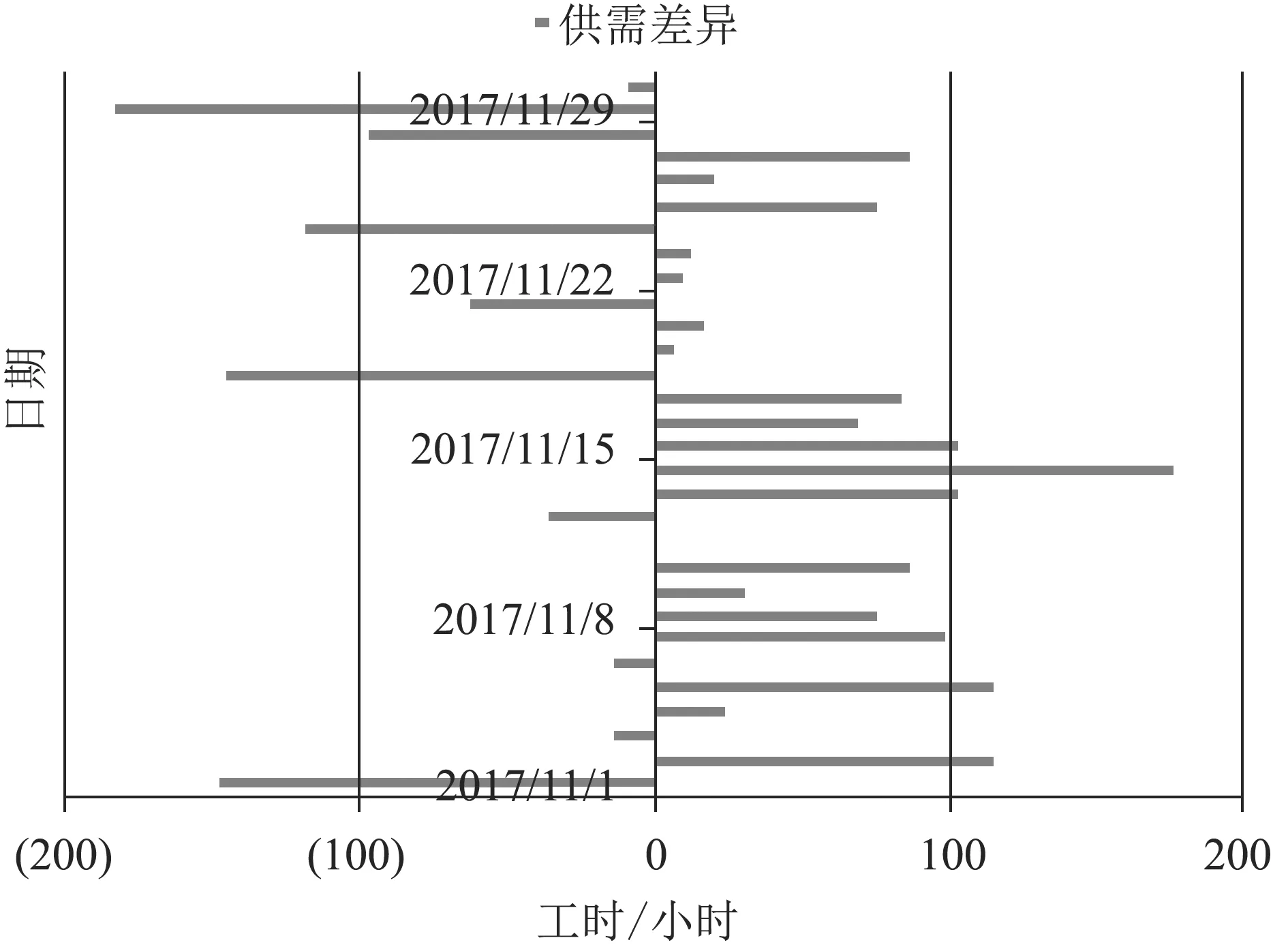
(b)供需差异对比
从图9中可以看出,在11月的30个工作日中,总共有10天维修能力不足,并且有3天维修能力的缺口接近或超过150小时。
(五)小结
通过对以上应用问题的分析过程,明确了“数据驱动+”研究范式下问题的研究思路:对研究问题的模型参数进行数据分析和挖掘,尝试发现数据的模式或数学模型;如果数据的数学模型能够被建立,那么可采用数学模型刻画该参数;如果数据的数学模型难以建立,那么可采用原始数据刻画该参数;以模型和数据共同构建应用问题模型(数学),并对模型进行求解。
以前文所示的对具体应用问题的分析和求解,得出“数据驱动+”研究范式的优势:能够突破数学建模方法在面对复杂企业实际情况的应用瓶颈(数学建模的困境),并实现问题的优化求解;如果单独以数学模型驱动问题求解,必然导致实际问题中的不确定性/随机性因素被忽视,最终导致研究问题的解并非最优解;不仅能够解决具体应用问题,还可以从多个角度对问题进行扩展研究;通过大数据分析,能够将应用问题分解或整合,并进行对比。
五、结 语
本文以一个企业维修部门的实际维修需求为例,通过数据分析确认了传统数学建模方法应用上的困境。进而采取“数据驱动+”的研究范式,以数据驱动克服数学建模无法解决的瓶颈,最终以模型驱动实现问题求解。在此研究范式和理论框架下,不仅能够实现问题求解,还能够用数据驱动的研究方法,对问题深入挖掘,从而给出更加细致的管理启示。
