基于GCC-NMF的语音分离研究
2020-11-26吴君钦王迎福
吴君钦,王迎福
(江西理工大学信息工程学院,江西 赣州 341000)
0 引 言
鸡尾酒会问题[1-2]是经典的盲源分离问题,涉及在现实环境中分离并发语音信号的混合。改进的分离算法将导致更大程度的干扰抑制和更少的伪影,这将提升包括助听器和人工耳蜗在内的助听设备的质量和鲁棒性,以及近年来日益普及的语音识别系统的性能。盲语音分离问题的主要困难在于混音系统的欠定性、混响环境、噪声的存在以及语音的非平稳性。但是,随着包括非负矩阵分解[3-7](Non-Negative Matrix Factorization,NMF)等机器学习算法的出现,不仅提高了算法的计算能力,而且在该问题上也取得了重大进展。
NMF是一种无监督的字典学习算法,它是引导盲源信号的各种声源分离技术的核心[8]。NMF非常适合于混合声信号的成分性质,可产生基于混合声谱图成分的无损表示[9-10]。但是,当将其应用于复杂混合语音信号[11]时,信号源会跨多个词典原子进行编码,随后需要对原子进行分组才能实现分离。尽管许多解决此问题的方法都涉及某种形式的监督和无监督方法,包括本文介绍的方法。然而利用先验的知识或信息来解决有监督的分割问题。对于简单的声音,可以手动对字典原子进行分组,但是随着声源复杂性或声源数量的增加,此方法很快变得非常麻烦。一种常见的监督方法是使用隔离的源记录来适应特定于源的词典,然后将这些词典连接起来以对混合信号进行编码。由于每个源均由其相应的字典进行编码,因此编码过程实现了分离。另一种常见的方法涉及使用混合信号中存在的源的种类的先验知识来约束NMF词典的各个部分,以使它们对应于“感兴趣”的源。无监督解方法通常使用空间分布的麦克风,将NMF与空间信息结合起来以实现分离[12-15]。一类基于模型的方法是学习一组特定源信号的词典,同时并行调整其对应的混合模型。混合模型可以采取空间协方差矩阵的形式,而字典可以通过多层结构变得更复杂。但是,空间协方差矩阵方法对初始化值敏感,并且在实践中需要使用受约束的字典才能获得良好的结果。另一类方法是将NMF与传统的波束形成算法结合起来,但是这些方法是针对大型麦克风阵列开发的,与本文考虑的双通道[16-17]情况有很大差异。
目前对于非负矩阵的研究主要是对于特定源信号的字典以及受约束的字典,对噪声的字典以及其他源信号的字典研究较少。本文利用非负矩阵和广义互相关方法相结合对混合信号的噪声字典和源信号字典进行深入研究。
1 非负矩阵分解和广义互相关
1.1 非负矩阵分解
非负矩阵分解算法的输入由混合信号的幅度时频表示组成,从数学的角度可表示为非负矩阵Vft,其中f和t分别指频率和时间。非负矩阵分解算法是将该输入混合信号的频谱图分解为2个非负矩阵:字典矩阵 Wfd(见图 1(a))和系数矩阵 Hdt,以使它们的乘积Λ=WH近似于V。W的d列称为字典原子(见图1(b)),它是频率的非负函数,可以在每个时间点与相应的系数线性组合,从而重构输入频谱图的相应列。
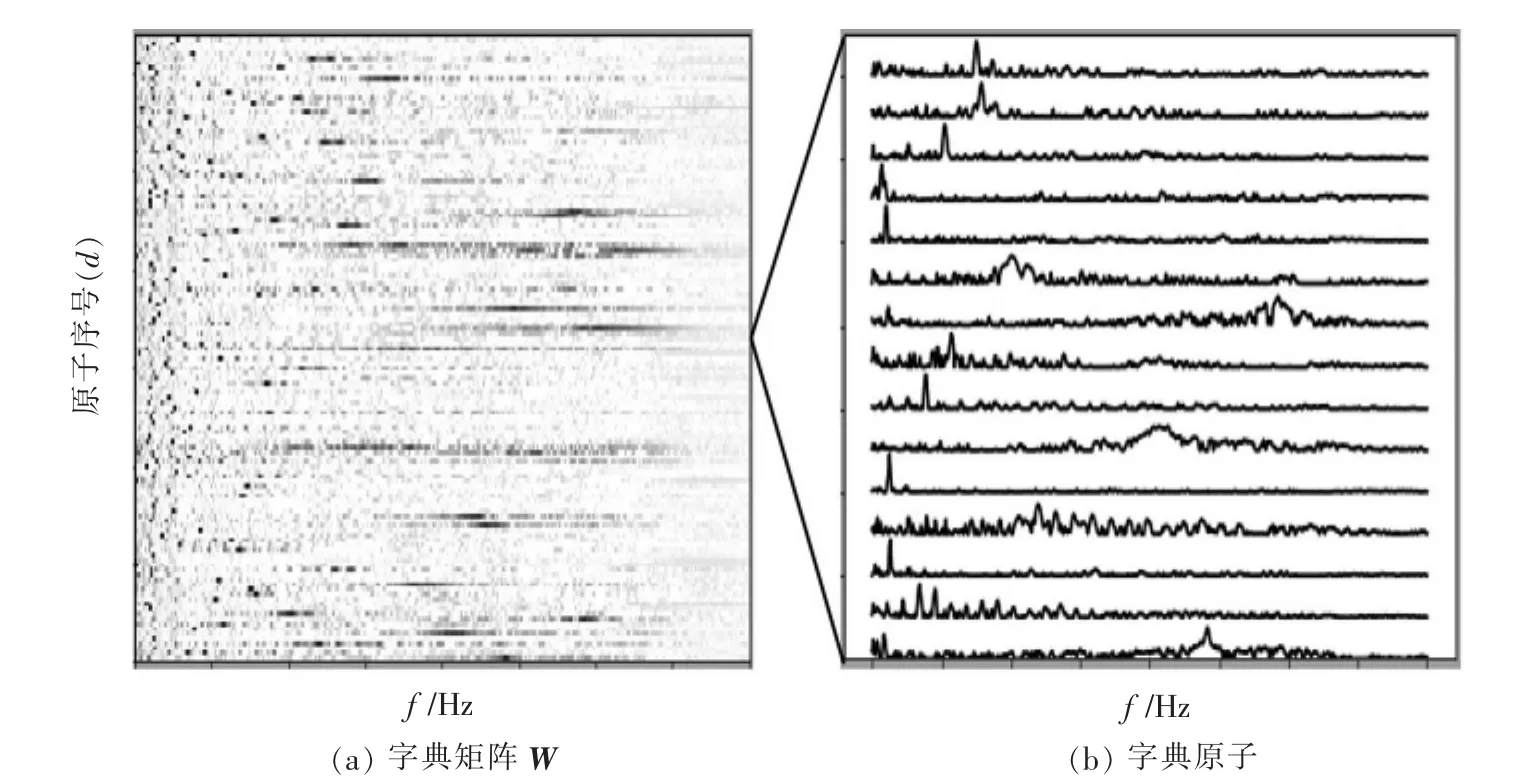
图1 NMF在混合语音信号中学习的词典
非负矩阵分解方法优化了包含重构误差项和可选系数稀疏性诱导项的代价函数。其使用了各种重构误差的度量,其中一些度量泛化为β散度 Dβ(V|Λ),包括欧几里得距离和广义Kullback-Leibler散度,l1范数通常用于系数稀疏性。然后定义乘法更新规则,以便通过随机初始化W和H并迭代更新它们,该算法收敛到代价函数的局部最小值。稀疏性为l0的 Dβ(V|Λ)的更新规则定义为:
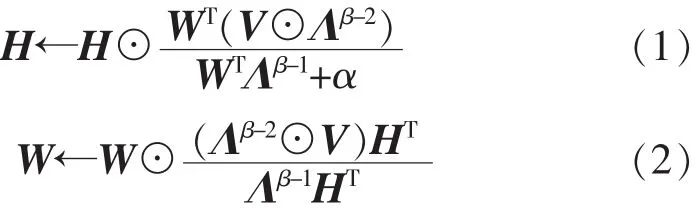
其中,⊙是Hadamard(按元素计算)乘积,矩阵指数是矢量形式的,并且α是权重系数稀疏性,对应重构误差。为了消除W和H之间的缩放不确定性,通常在每次更新后将字典原子标准化,并相应地调整其系数。
在研究立体声音频信号的情况下,左输入频谱图和右输入频谱图可以在训练之前及时合并,即Vft= [Vlft| Vrft],其中得到的系数相应地为Hdt=[Hldt|Hrdt],并且字典保持变。
1.2 广义互相关
成对的空间分布传感器之间的信号到达时间差[18](Time Difference of Arrival,TDOA)用于波束成形[19]和定位的各种传感器阵列应用中。GCC(Generalized Cross Correlation,GCC)算法是估算任意一组频率的TDOA的经典方法。GCC表示角度频谱图,见图2(a)。时间延迟τ和时间t的函数,在数学上定义为:

其中,Vlft和Vrft是左右复谱图;*是元素复共轭;ψft是时变频率加权函数。
在存在干扰声音和混响的情况下,最稳健的定位算法是GCC相变(GCC-PHAT),其频率加权函数是左右幅值频谱图的逆积:
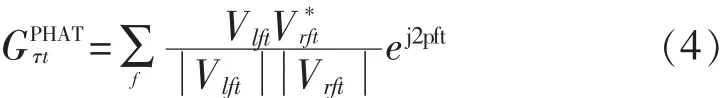
将角度频谱图随时间合并,生成总的角度频谱,然后将最高峰的位置与源TDOA估计相对应,见图2(b)。源的数量可以事先确定,也可以例如通过对k=2的局部最大幅度进行k均值聚类来估计。对于较小的麦克风间距,必须应用非线性来补偿所得GCC的宽瓣:
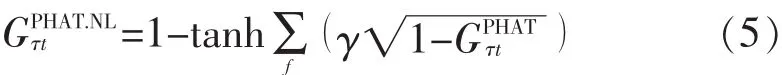
其中,γ=2在实践中表现良好。
2 GCC-NMF盲源分离
在本节中,提出了一种GCC-NMF分离算法。随后根据原子的空间定位将原子分组为源,然后分别独立地重建每组原子。
2.1 GCC与NMF结合
首先从标准化NMF字典原子定义一组GCC频率加权函数ψNMFdft:
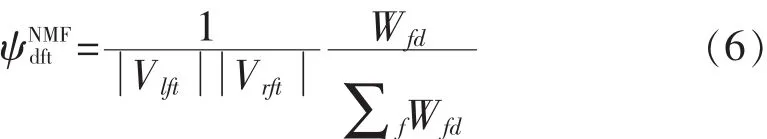
从而构造频谱函数使得对于给定的原子d,频率可以根据它们的相对重要性来加权。 然后,GCC-NMF是特定于原子的角度频谱图的结果集:
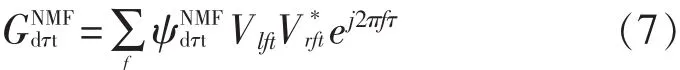
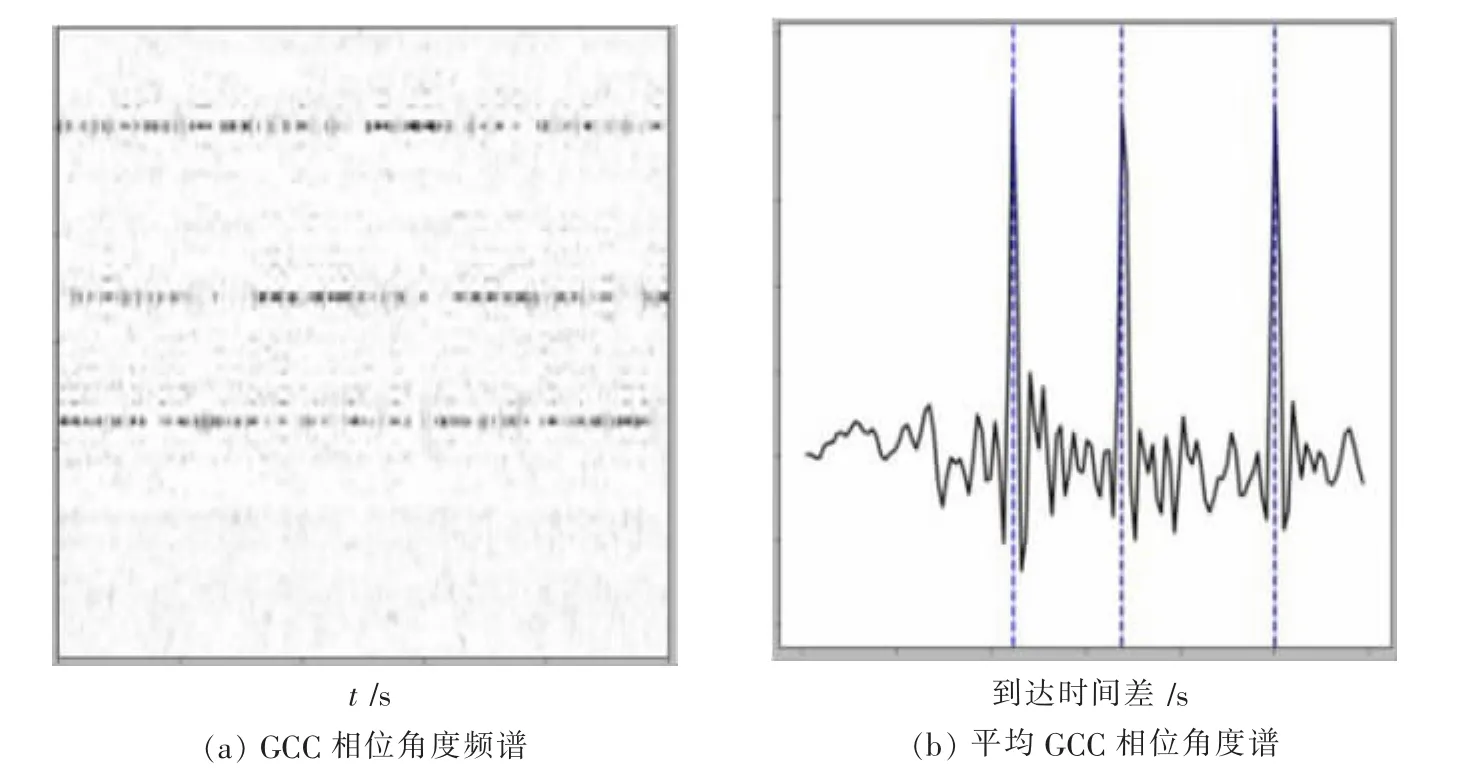
图2 使用GCC-PHAT进行混合信号的源定位
2.2 系数掩蔽
GCC-NMF角度频谱图用于将每个字典原子每次都与单个s相关联。如1.2节所述,首先使用GCC-PHAT估算源到达时间差Ts。然后对于任意时间t,字典原子都能产生最大值GNMFdτst的源。从而定义了一组特定源的二进制系数掩码:
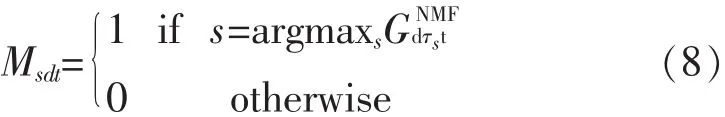
将它们与元素的混合系数相乘以便为每个源生成掩蔽系数。
2.3 源重构
通过使用特定源的掩蔽系数进行反NMF和时频函数[20-24]来实现源重构:
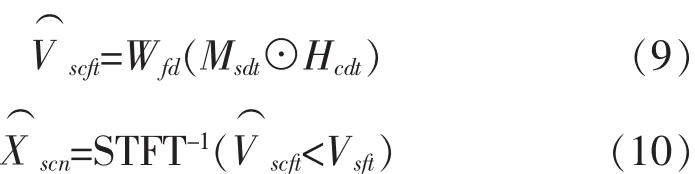
2.4 GCC-NMF分离系统
图3给出了分离系统的框图,然后在表1中描述了系统变量。分离系统始于由短时傅里叶变换(Short-time Fourier Transform,STFT) 和 NMF组成的编码解码块。然后,系数掩蔽块中断编码-解码过程,从而产生编码-分离-解码架构。粗箭头强调编码-解码过程。
3 实验测试与结果分析
实验是使用信号分离评估运动(Signal Separation Evaluation Campaign,SiSEC dev1) 现场语音记录数据集进行的,该数据集组成是“通过会议室中的扬声器播放的静态源,一次记录一个”,每个录音长度为10 s,由3个女性和4个男性通过16个扬声器混合录制而成,其中5个扬声器的麦克风间距为1 cm和1 m,混响时间为180 ms和250 ms。采用采样大小为1024个样本的Hann窗(64 ms)以及跳数大小为 16 个采样样本(1 ms),通过STFT从16 kHz混合信号生成复频谱图。默认NMF参数设置为1024字典原子,100次迭代,稀疏度 α=0.1,价函数 β=1。 GCC 非线性适用于 γ=3、间距为5 cm的麦克风。

图3 GCC-NMF源分离系统
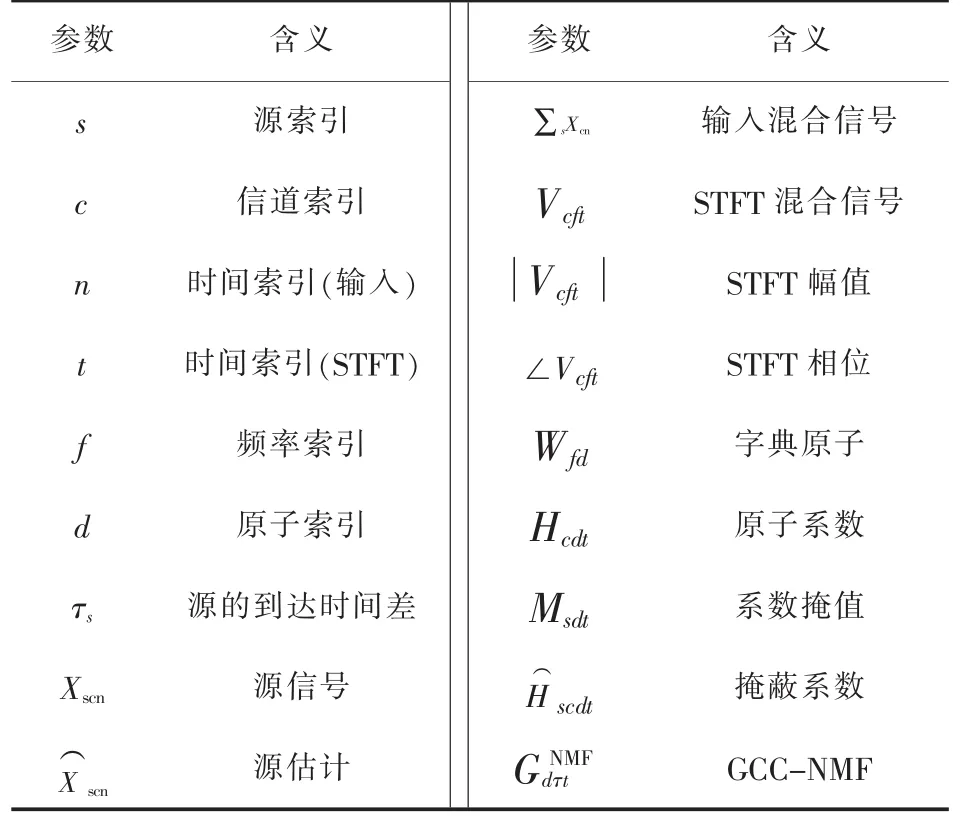
表1 变量说明
3.1 NMF参数对分离性能的影响
在图4、图5、图6中,分别探究了非负矩阵分解方法中字典大小、迭代次数和稀疏系数α 3个因素对分离性能的影响。对于信噪比和感知分数,增加字典大小会导致目标的 OPS、TPS、APS、SDR、ISR、SAR值提高,不过当字典大小超过100时,增长达到了饱和状态。而随着字典大小的增加,目标qGlobal、qTarge、qArtif的 PEMO-Q 值缓慢增大,在字典大小达到100后,PEMO-Q值几乎趋于稳定;qInterf的PEMO-Q值几乎没什么变化。尽管SNR和PEMO-Q的测量值表明干扰抑制与字典大小无关,但是随着字典大小的增加,Ips感知分数明显下降。因此,字典大小可控制干扰抑制与总体,目标和伪像得分之间的折中。对于目标的感知分数、信噪比、PEMO-Q值,迭代次数具有与字典大小类似的影响,尽管增加与降低的幅度没那么明显,而增加系数稀疏性 (散度)α则表现出了与前两种因素相反的效果:目标,伪像和总体得分随稀疏度的增加而降低,而干扰抑制则增加。为实现分离效果的最佳化,默认设置参数字典大小为100,迭代次数为1024,稀疏度α为 0.1。
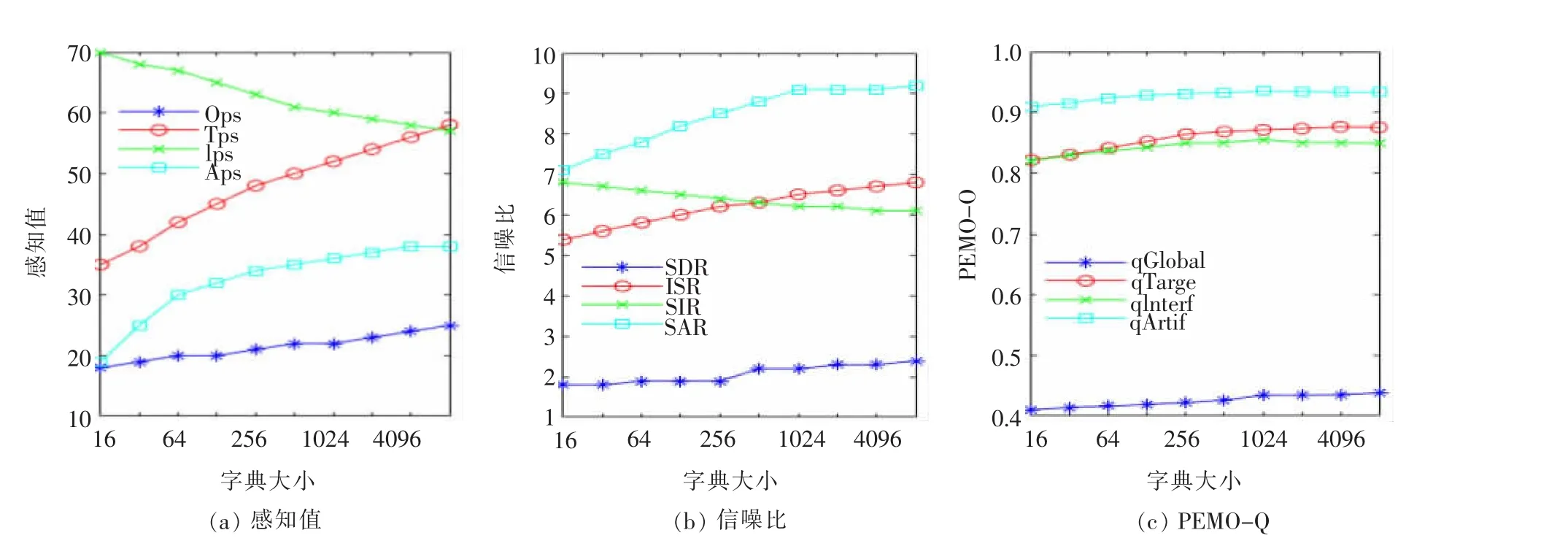
图4 不同字典大小下,信号的感知值、信噪比、PEMO-Q的变化趋势

图5 不同散度下,信号的感知值、信噪比、PEMO-Q的变化趋势

图6 不同迭代次数下,信号的感知值、信噪比、PEMO-Q的变化趋势
3.2 与其他基于模型方法的比较
在表2、表3、表4中,分别使用声源分离的感知评价方法(Perceptual Evaluation for Audio Source Separation,PEASS)工具包和盲源分离(Blind Speech Separation,BSS) 评测工具包进行了 PEASS、BSS、PEMO-Q三项性能测评,并将GCC-NMF得到的实验数据与其他基于NMF的语音分离算法的实验数据进行了比较。
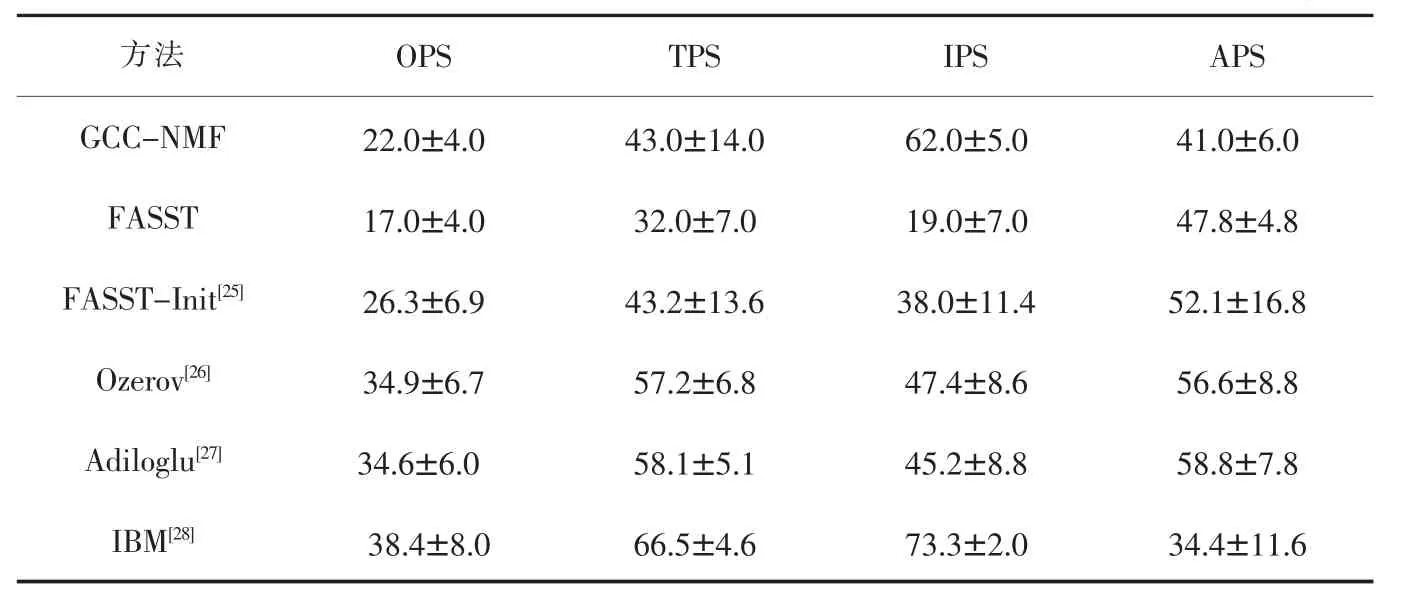
表2 PEASS评测值单位:dB
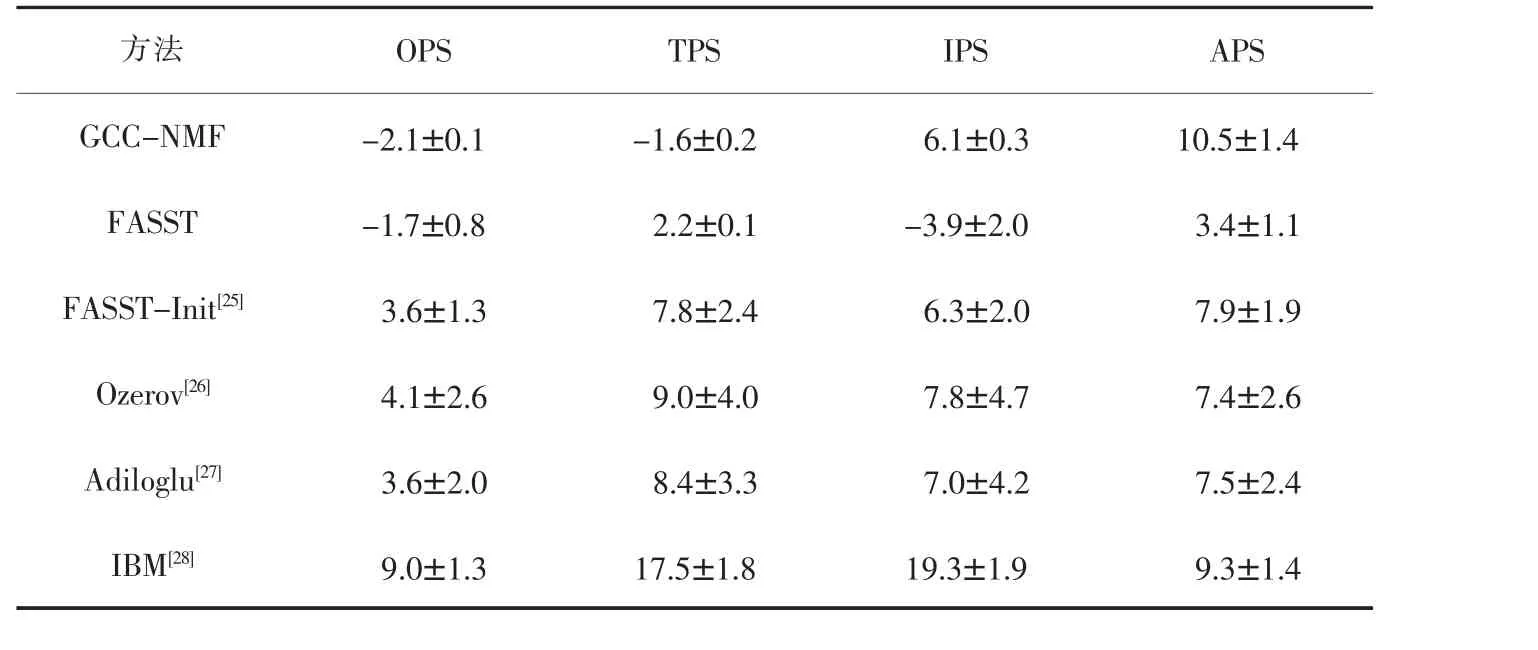
表3 BSS评测值单位:dB

表4 PEMO-Q评测值 单位:dB
实验数据都是以平均分离分数±标准偏差呈现,从而确保实验结果的相对稳定,数据集取自SiSEC dev1实时语音记录数据集。FASST[25]是一种灵活的、开源的、基于模型的方法,它将NMF与空间协方差混合模型结合在一起。在单纯无监督的环境中,它对初始化值过于敏感,并且缺乏鲁棒性。因此,对于FASST-init[25],使用oracle混合初始化过程,可以显著提高性能,但是需要事先混合模型信息。从表中的数据可以看到,尽管根据BSS Eval指标,这种半监督方法的性能优于GCC-NMF,但GCC-NMF可以显著改善总体,基于目标和基于干扰的PEASS分数,但代价是增加了伪像值。此外,还对比了文献[26-28]中提出的Ozerov、Adiloglu两种半监督和带约束条件的字典算法的结果,尽管GCC-NMF是一种非监督的方法,不过在PEASS、BSS、PEMO-Q三项性能测评上所得到的结果还是相当理想的。
OPS、TPS、IPS、APS 分别表示: 总体感知分数(Overall Perceptual Score,OPS)、 与目标相关的感知分数(Target-related Perceptual Score,TPS)、与干扰相关的感知分数(Interference-related Perceptual Score,IPS),以及与伪像相关的感知分数(Artifactsrelated Perceptual Score,APS);SDR、ISR、SIR、SAR分别表示:信号失真率(Source to Distortion Ratio,SDR)、信号图像空间失真率 (Source Image-to-Spatial Distortion Ratio,ISR)、信号干扰率(Source to Interferences Ratio,SIR),以及信号伪像率(Sources to Artifacts Ratio,SAR);qGlobal、qTarget、qInterf、qArtif分别表示信号PEMO-Q的全局值、目标值、干扰值及伪像值。
4 结 论
本文提出了一种将空间信息与非负矩阵分解相结合的无监督语音分离方法。通过利用广义互相关的源定位方法对随时间变化的单个字典原子进行定位,从而根据其空间源对其进行分组,最后通过控制变量法研究了NMF参数对于分离性能的影响,对比得出了3个参数的最优取值,从而实现了分离性能的最佳化。所提出的基于广义互相关的非负矩阵分解的方法优于无监督的空间协方差模型,并且相比需要先验知识或信息的半监督和受限的非负矩阵分解方法,也颇具优势。尽管简单的结合广义互相关和非负矩阵分解表现出较好的性能,同时需要研究其他更复杂的非负矩阵分解模型以及一些特征学习方法。
