临床科研数据抽取研究
2020-11-25牛承志
牛承志 骆 鑫 赵 丹
(郑州大学第一附属医院 郑州450052)
1 引言
随着信息化迅速发展,医院业务流程已实现闭环管理以及全流程数据记录。医院信息系统中存储大量临床数据,从类型来区分,可以分为临床医学影像数据和临床医学文本数据两类。临床医学文本数据主要包括患者检验结果、诊断报告、病历文书、病理报告等。临床医学文本中嵌入大量有用信息,如何利用现有技术方法从医学文本数据中提取潜在、有价值的信息逐渐成为信息抽取领域关注和研究的重点[1]。本文以国内某大型三甲医院信息系统为基础,以临床医学文本分类为依据,从数据来源角度分析临床科研数据抽取方法和过程,使用自然语言处理、数据库检索手段对医学文本进行抽取和挖掘,取得较好效果。文中介绍的数据分析、抽取、集成方法均来自日常临床科研数据工作实践,希望能够为临床科研数据挖掘工作提供一些思路。
2 临床科研数据
2.1 概念
指医院信息系统运行过程中产生的各种形式数据,包括患者医嘱、费用、医疗文书和检查检验等信息,主要来自医院信息系统(Hospital Information System,HIS),电子病历系统(Electronic Medical Records System,EMRS),医学影像存储与传输系统(Pictures Archiving and Communication System,PACS),检验信息系统(Laboratory Information System,LIS)4大系统。医疗数据是医疗活动的数据记录,对诊断和治疗疾病具有重要意义。临床科研数据针对课题研究使用,研究课题不同,所要抽取数据也不同。例如药物研究课题是针对使用某种药物的患者来展开研究,糖尿病、肾病是以疾病为中心展开研究。临床科研数据抽取是精准、定量定性的数据抽取过程。例如狼疮肾炎课题需要抽取患者第1次血常规中的红细胞计数数据,而不是所有实验室数据;研究2型糖尿病课题需要从入院记录中抽取患者糖尿病病史,而不是整个现病史记录。
2.2 分类
临床医学文本从结构化角度分析,可分为两类,即结构化和非结构化数据。结构化数据是按照预先设计好的数据类型和长度规则,通过不同软件进行数据存储和管理;是典型的关系型数据,以行和列组成的二维表,可以通过结构化查询语言(Structured Query Language,SQL)语句实现检索和使用,主要有患者病历首页、实验室、医嘱、费用信息等[2]。非结构化数据是未使用数据库软件进行存储管理的数据,暂无法用二维表结构来描述,以HTML、XML、PDF等形式存储在硬盘等介质,以大段医疗文书描述为主,优点是便于书写,可以反映书写者连贯思维,缺点是不易存储,信息抽取困难。主要有患者医疗文书、影像报告描述等。
3 结构化数据抽取
3.1 内涵
从医院信息系统数据库中获取数据,要充分考虑到信息系统安全和业务系统负载,可以采用相对独立的数据仓库模式,在医院信息系统中负载较轻的时间从相应业务系统中通过提取-转换-加载(Extract,Transform and Load,ETL)采集工具将来源于HIS、EMRS、集成平台等系统的患者数据、门诊诊疗、门诊用药、住院治疗、住院医嘱、手术、检查检验等大量数据信息,经过转换清洗,存储到数据库中[3],见图1。
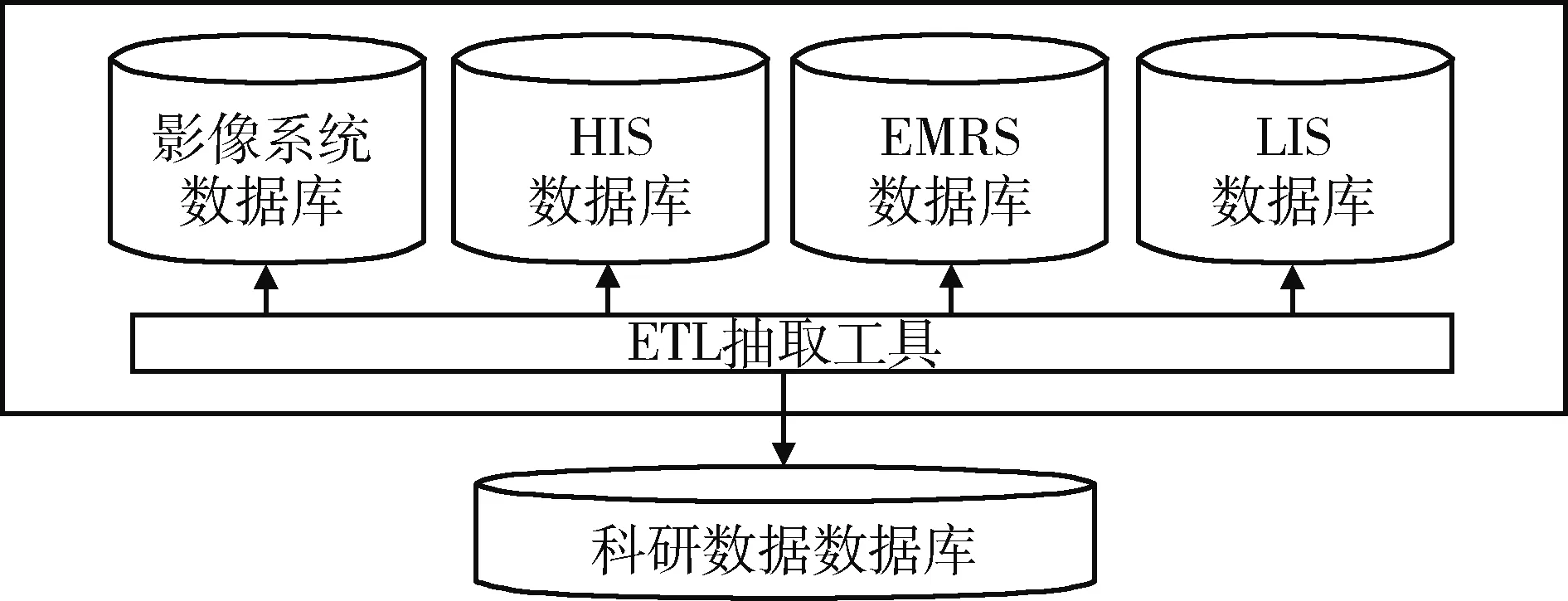
图1 结构化数据抽取设计
3.2 步骤
结构化数据抽取需要耗费大量服务器资源,在抽取过程中将业务系统和抽取业务相互独立,保证医院日常业务正常运行。结构化数据抽取步骤如下:从诊断表中按时间找到符合条件的患者住院号;从患者变更表中筛选出在ICU治疗过的患者住院号,存入本地数据库。住院号是患者唯一标识,以此将患者所有数据串联起来;依据住院号抽取患者首页信息,存入本地库;依据住院号将患者所有LIS数据抽取出来,存入本地库;依据住院号将患者医嘱抽取出来,存入本地库;按需求创建数据集表,更新患者首页部分内容;与需求者沟通确定医嘱中的打分规则,输入每名患者分值,更新数据集表医嘱部分内容;按需求抽取患者LIS数据,整合数据,分别取最高值、最低值更新数据集表。
4 非结构化临床医学文本抽取
4.1 内涵
从电子病历抽取科研课题所需信息,本文以常见多发疾病2型糖尿病为研究对象,采用基于规则的自然语言处理、文本挖掘技术与算法从电子病历中入院记录自动抽取患者病史,将其结构化处理。
4.2 数据描述
电子病历中患者疾病史会出现在入院记录中,大多数格式为“疾病名称+时间陈述”,例如“自述糖尿病15年”、“既往史,患糖尿病8年余”、“20年前确诊2型糖尿病”,常见的糖尿病史描述模式,见表1。

表1 糖尿病史描述模式示例
4.3 方法与步骤
分析病史描述规则后进行糖尿病史抽取与组织,见图2。糖尿病史抽取与组织可分为5个步骤,首先构建糖尿病史语料库,组织在校医学硕士分为3组,其中两组文本标注,1组核对结构,对内分泌科入院记录进行规范化标注,总结分析出入院记录中的描述糖尿病史模板;其次将第1步结果经内分泌临床医生讨论后构建规则库[4];第3步在非结构化的入院记录中,基于构建的规则库对糖尿病史进行自动抽取,将抽取的病史结果进行存储;第4步核对入院记录中有关否定描述内容,从抽取的结果中剔除有关否定的结果[5];第5步采用人工和算法核对相结合的方法对结果进行验证。糖尿病史抽取结果,见表2。
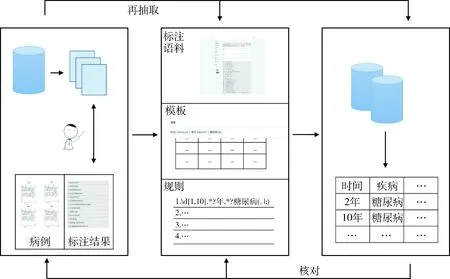
图2 非结构化电子病历文本数据中的糖尿病史抽取与组织

表2 糖尿病史抽取结果
4.4 结果分析与验证
为说明抽取结果有效性,采用两种验证方法并行策略,第1种方法选取1个科室2015年全部数据进行基于辅助工具的人工验证,其验证结果为整体抽取结果的指标分析提供参考依据;第2种方法对所有科室数据进行10%取样,取样使用人工标注语料的5%,其目的在于经过专业人员标注的内容可以作为糖尿病史抽取结果来验证[6],从而提高全部科室糖尿病史抽取准确率。抽取结果验证指标,见表3。

表3 抽取结果验证指标
5 结语
通过对临床医学文本结构化和非结构化数据抽取,将获取到的数据组织成数据集表,供临床科研工作使用。通过基于规则的抽取方法和自然语言处理技术相结合,实现非结构化电子病历、文本数据的定制化抽取;采用基于数据库的ETL技术实现从结构化临床医学文本抽取信息,取得良好效果,助力临床科研工作。
