外国人汉字书写偏误分析中的基本问题*
2020-11-25牛士伟赵林江
牛士伟, 赵林江
(天津外国语大学 国交处,天津 300204)
鲁健骥将二语习得的中介语理论引入到对外汉语教学中来,随后陆续出现了很多关于汉语语音、词汇、语法和篇章等各类偏误研究的文献,而针对汉字偏误的研究始于20世纪90年代,距今已有30年了。(1)鲁健骥.中介语理论与外国人学习汉语的语音偏误分析[J].语言教学与研究,1984,(3).在这30年里,有关汉字书写偏误研究的文献已近300篇,国别化研究不断深入、研究方法不断创新、研究内容不断细化,但研究模式从未改变,“找出偏误—描述偏误—解释原因—提出对策”成为最“经典”的研究模式。为更好地了解书写偏误研究,促进汉字习得和对外汉字教学,文章梳理了30年来汉字书写偏误研究的文献,沿着偏误分析的步骤,重新阐释各环节的内涵与功能,找出研究过程中存在的基本问题,在此基础上总结反思,权作后继者汉字偏误研究和汉字教学的引玉之砖。
一、汉字书写偏误分析的基本步骤
Corder最早提出了偏误分析的具体步骤:即搜集语料、鉴别偏误、描写偏误、解释偏误和评估偏误,(2)于红英.中级阶段俄罗斯留学生汉字书写偏误研究[D].黑龙江大学硕士学位论文,2015.后来的研究者都是在此基础上进行偏误研究的。其中,牛士伟将汉字偏误研究分为6个步骤,即确定研究对象、搜集语料、鉴别偏误、描述偏误、评估偏误和解释偏误。(3)牛士伟.外国汉语学习者汉字书写偏误研究的特点与反思[J].广东外语外贸大学学报,2018,(2).文章正是循着这样的顺序展开的。
(一)确定研究对象
确定研究对象是偏误研究的基础保障,偏误研究的其他环节都有赖于此。这个阶段的主要任务是明确研究对象的基本信息,包括学习者的性别、年龄、国别、汉语水平及其他个体因素等。在以往的研究中,研究者往往利用工作或学习的便利条件直接以搜集语料为始进行偏误研究,忽略了对研究对象的具体描述。然而,事实表明,我们对研究对象了解得越详细,研究结论的可靠性和应用性越强。
(二)搜集语料
搜集语料是偏误研究的基本条件,为偏误研究提供原料和素材。这个阶段的主要任务是搜集研究对象的偏误语料,为后续的偏误分析做准备。这里主要涉及三个因素,即学习者、语料和语料的搜集方式。学习者是输出偏误汉字的学习者,语料是学习者输出的偏误汉字,而语料的搜集方式将学习者和语料联系起来,它涵盖了学习者书写偏误产生的所有途径,反映了学习者表达书面汉语的全部情形,因此是这个阶段的核心内容。
(三)鉴别偏误
鉴别偏误之于偏误研究如同源头之于活水,是偏误研究存在的前提。没有经过鉴别的偏误不是真正的偏误,当然也就更谈不上偏误分析了。这个阶段的主要任务是辨别学习者的书写错误是偏误还是失误。关于书写偏误的认定,首先要确定汉字书写的错误是什么,然后再鉴别汉字书写的偏误与失误,最后才能认定哪些错误是汉字书写的偏误。(4)张琢婧.中级阶段韩国留学生汉字书写偏误分析与教学建议[D].河北师范大学硕士学位论文,2018.这基本上阐述了鉴别偏误的全过程,即判定错误、辨别偏误、确定偏误。
(四)描述偏误
描述偏误是偏误研究的核心内容和关键环节。它指的是以目的语为基准,对学习者偏误进行语言表面特征的描述。(5)蒋祖康.第二语言习得研究[M].北京:外语教学与研究出版社,1999.在书写偏误研究中,目前主要有两类描述法:一类是从笔画、部件和整字三个层级上,根据标准数学范畴如遗漏、误加、误代、错位和杂糅,从字形表面的偏误特征对偏误汉字分类,即字本位描述法,具体偏误类型见下表1;另一类是根据汉字构形的基本单位,同时参考汉字音、形、义的基本属性,从学习者所犯错误的偏误特征出发,从高到低逐层对偏误汉字进行描述,即人本位描述法,具体偏误类型见下表2。这两类描述法共同构成了偏误描述的基础。

表1 字本位描述法(6)空格表示没有相应的偏误类型。
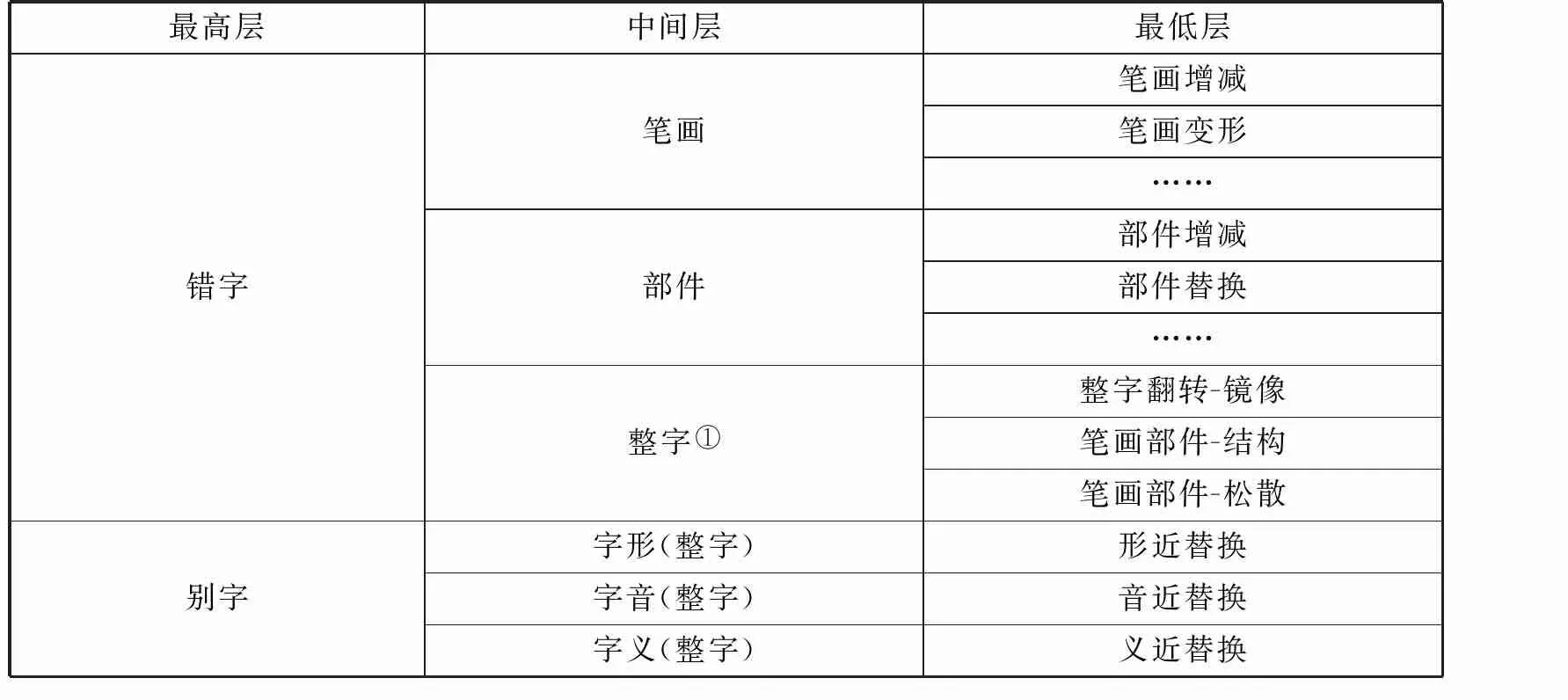
表2 人本位描述法
(五)评估偏误
评估偏误是偏误研究的结果,也是后续汉字纠偏和改进汉字教学的根本出发点。Corder认为,出于教学目的,我们需要知道学习者的主要学习困难是什么,这就要求我们对语言错误进行定性分类并量化每种错误类型,以便我们可以优先处理每个问题。(7)S.P.Corder.Error Analysis,Interlanguage and Second Language Acquisition[J].Language Teaching,NO.3,1975,pp.201~218.这是评估偏误的根本出发点。在评估方法上,一种是基于违反规则的数量和性质的评估方法,用以衡量偏离正确目标语言形式的程度;另一种是衡量错误对交际效率的干扰程度,包括频率(frequence)、概括性(generality)和可理解性(comprehensibility),或通过母语为英语者或语言教师对偏误的容忍度来衡量其严重性。(8)S.P.Corder.Error Analysis,Interlanguage and Second Language Acquisition[J].Language Teaching,NO.3,1975,pp.201~218.类似地,Khalil提出了评估偏误的三个维度:可理解性、可接受性和冒犯性。可理解性指的是包含各种偏误的句子在多大程度上是可以被理解的;可接受性是对偏误严重性的判断;冒犯性是评估者对包含错误句子的情感反应。(9)Aziz Khalil.Communicative Error Evaluation: Native Speakers' Evaluation and Interpretation of Written Errors of Arab EFL Learners[J].TESOL Quarterly,NO.2,1985,pp.335~351.另外,蒋祖康认为,评估偏误关注的是读者或听者对偏误的反应:听者和读者是否能理解含有偏误的语言所传达的信息?他们对偏误的严重程度和不自然程度会作出怎样的评价?偏误对听者和读者的冒犯程度如何?(10)蒋祖康.第二语言习得研究[M].北京:外语教学与研究出版社,1999.综上所述,理解性、严重性和冒犯性是评估偏误的三个重要维度。在汉字书写偏误研究中,目前几乎所有的研究者仅在严重性维度上评估偏误,偏误率被认为是评估偏误的唯一指标,忽视了理解性评估和冒犯性评估在偏误研究中的作用。
(六)解释偏误
解释偏误是对偏误结果的反思。偏误分析的目的就是要找到学习者偏误产生的原因,通过分析原因找出解决问题的办法。Taylor指出,偏误产生的原因可以从心理语言学、社会语言学、认知理论或篇章结构的角度来解释。(11)埃利斯(Ellis,R.).第二语言习得研究(第二版)[M].上海:上海外语教育出版社,2013.但目前几乎所有的偏误研究都仅从心理语言学和社会语言学的角度来解释偏误现象。语言学解释是从语言学角度对偏误现象进行描述,为从心理学角度解释做铺垫。心理学解释主要集中于对学习者学习策略和学习过程的说明。社会学语言学解释主要探讨社会环境对学习者偏误产生的影响。因此,汉字本身的因素、学习者因素和教师教材因素是当前解释偏误的三个重要考量。
二、汉字书写偏误研究中的主要问题
(一)确定研究对象阶段
如上所述,被试信息主要包括学习者的性别、年龄、国别、汉语水平及其他个体因素等。这里主要有两个问题:1、学习者汉语水平的划分标准不清。2、国别化研究的比例不低,但覆盖面并不广泛,且国家分布也不均衡。
第一个问题主要体现在两个方面:一是不同研究者有不同的划分标准。大多数研究者根据学习年限划分学生的汉语水平,如王帅将学习1~2年的学习者的汉语水平定为初级,3年左右的定为中级,4~5年的定为高级;(12)王帅.俄罗斯留学生的汉字学习情况偏误情况调查报告[D].黑龙江大学硕士学位论文,2011.有些研究者以学生掌握汉字(词汇)的数量作为划分汉语水平的标准,如沙比然将掌握1033个汉字的学习者的汉语水平定为初级,掌握3051个汉字的定为中级,掌握5253个汉字的定为高级;(13)沙比然.哈萨克留学生学习汉字的偏误分析[D].华中师范大学硕士学位论文,2016.还有的研究者以通过HSK考试的级别作为划分汉语水平的标准,如陈思颖以学生通过HSK3级考试为界限,将考试前的水平认定为初级,考试后的认定为中级。(14)陈思颖.初级和中级阶段的巴基斯坦学习者汉字偏误和改进措施[D].四川师范大学硕士学位论文,2018.二是即使采用同一标准,不同研究的具体规定也不尽相同。如魏玲玲以中亚留学生为研究对象,将学习一年以内的学生的汉语水平定为初级,一至两年的定为中级,两年以上的定为高级,(15)魏玲玲.留学生汉字偏误考察与分析—以中亚留学生为调查对象[D].复旦大学硕士学位论文,2013.而阿列娜以俄罗斯在华留学生为研究对象,将本科一二年级学生的汉语水平定为初级,三四年级的定为中级,研究生的定为高级。(16)阿列娜.俄罗斯留学生汉字书写偏误研究[D].哈尔滨师范大学硕士学位论文,2016.其他汉语水平的划分标准也多是如此。
对于第二个问题,截止到2020年8月底,在中国知网上以“篇名”为筛选字段,以“汉字偏误”和“书写偏误”为关键词,文章共搜集到297篇有关汉字书写偏误研究的文献。其中国别化研究共涉及38个国家179篇文献、占全部文献的60.3%,且泰、日、韩三国的文献数之和为75篇,占国别化研究的41.9%。与海外162个国家(地区)建立的550所孔子学院和1172个孔子课堂相比,(17)光明日报.国际中文教育,从热起来到实起来.[EB/OL].http://www.hanban.org/article/2019-12/10/content_795660.htm,2019.国别化研究还很狭隘,书写偏误研究仅集中在少数国家,我们并非对每个国家学习者书写偏误的情况都有同等程度的了解,由于某些国家的研究资料较少,我们对这些国家偏误情况的了解也不像泰国、日本和韩国那样详尽。
(二)搜集语料阶段
有效的语料是进行偏误研究的基础,而语料的自然性和真实性一直是制约语料有效性的重要参数。因此,如何搜集自然而真实的语料是这个阶段的主要问题,而这主要体现在语料的搜集方式上。目前主要有五种搜集方式:(1)课堂练习或课后作业(2)考试试卷(3)听写(4)问卷调查(5)语料库。从语料自然性和真实性的角度看,第一种语料是学习者在比较放松、自然状态下输出的语料,但有些学习者可能会查阅资料,因此这种语料的自然性较强而真实性不足,书写偏误数可能比实际偏少;第二种语料是学习者在时间比较紧张、情绪比较激动时输出的语料。一般来讲,由于考试,学习者会尽力调动全部资源完成答卷,但也正因为时间紧、任务重的原因,学习者反而会犯一些低级错误,因此这种语料的自然性较弱而真实性较强,书写偏误数可能比实际偏多;第三种语料需要学习者集中注意力并一直关注听写内容才能输出正确的信息,所以语料输出的过程并不轻松自然,而且这种语料具有不可逆性,因此它的自然性比试卷语料还低,另外,由于听写内容是否反映了学习者当前的书写水平会受到语音、环境和听写内容本身等多种因素的影响,因此这种语料的真实性也不确定;第四种语料既不要求被试提供关键的个人信息,也不要求被试在规定的时间内完成,因此学习者在轻松、自然状态下完成的问卷自然性较好,但由于问卷调查的性质,被试很可能不会认真对待,更不会查阅有关资料,因此这种语料的真实性也不会太高,但比课后作业或课堂练习的真实性要好;第五种与其说是一种新语料,不如说是几种语料的综合运用。与其他语料相比,这种语料的自然性和真实性更有竞争力。此外,这种语料还具有平衡性(平衡了被试的国别、汉语水平等)和连续性(可以对不同语言现象或个体做动态跟踪研究)的特点,因此被认为是最有前景的语料。
由于每种语料的自然性和真实性都不是完美无缺的,因此研究者一般通过综合运用几种语料来进行偏误研究,这种方式不仅平衡了语料的自然性和真实性,而且也丰富了语料来源的途径,但至少还存在以下问题:(1)既然“听写”这种方式既不自然,真实性也未可知,但为何诸多研究者都采用这种方式搜集语料?(2)如何正确理解并评估语料的自然性和真实性,它们的决定因素是什么?(3)每种语料的自然性和真实性问题还有很大的探讨空间,哪种或哪几种语料更能反映学习者书写偏误的全貌?(4)不同语料的自然性和真实性之间是否有可比性?如果有,该如何比较等,这些都是搜集语料时面临的重要难题。
(三)鉴别偏误阶段

对于第二个问题,学界已基本达成共识。引用肖奚强的说法,失误是在特殊情境下产生的偶然现象,如说话时临时改变主意,注意力不集中或疲劳、紧张等都会造成失误。失误是不成系统的,它不反映说话人的语言能力,操本族语的人也常出这样的错误,一旦出现错误,说话人有能力改正它。偏误则是对正确语言规律的偏离。这种错误是系统的、有规律的,它反映了说话人的语言能力。一般说话人自己不能改正错误。在解决了这两个问题后,我们就可以对学习者的错误进行判定了。(20)肖奚强.略伦偏误分析的基本原则[J].语言文字应用,2001,(1).
然而在具体实践中,尤其是在面对大量错字时我们并非总是逐个识别、判定,因为这种方式的主观性较强,不仅耗时费力,而且可操作性也很差。因此,大多数研究者都依据错字的判定标准,通过错字的统计学操作来解决这个问题。错字的统计学操作其实就是对偏误内涵的操作性转换。根据偏误内涵操作性转换的精细化程度,错字统计又分为不同的层次,包括个体层面和群体层面。当然,无论从个体层面还是从群体角度统计错字都各有问题。首先,从个体层面上看,“同一人对同一字的相同错误只记一次,同一人对同一字的不同错误分别记录”是错误统计的一般原则。前半句表明这个人在这个字上存在某类偏误。后半句表明这个人在这个字上有不同的错误类型。从整个字来讲,这个字是这个人的偏误字,这是没问题的,但如果从这个字的任意错误类型来看,任意错误类型都不能算是这个人的偏误类,而只能算是这个人的类偏误。类偏误是指介于错误和偏误之间,从错误类型上看属于错误,而从错误对象上看则属于偏误。(21)牛士伟.外国汉语学习者汉字书写偏误研究的特点与反思[J].广东外语外贸大学学报,2018,(2).其次,从群体角度来看,“不同人对同一字的相同错误按人次记,不同人对同一字的不同错误分别记录”是错误统计的一般原则。前半句表明不同人在这个字上存在某类偏误。后半句表明不同人在这个字上有不同的错误类型。从整个字来讲,这个字是这个群体的偏误字(一般以三人及以上学习者在这个字上有错误,才能将这个字认定为群体偏误),这也是没问题的,但从这个字的任意错误类型上看,同上所述,任意错误类型都不能算是这个群体的偏误类,而只能算是这个群体的类偏误。这就涉及第三个问题:如何统计类偏误。严格来讲,类偏误不属于偏误,因此不必统计,但个体间的类偏误联合起来又能说明群体问题,可能会造成信息流失,因此又不能忽略,但如果进行统计,一是不符合偏误内涵的规定,二是还有扩大偏误数量的嫌疑,因此在偏误统计时要格外注意。
(四)描述偏误阶段

此外,由于日韩学生独有的汉字背景,其笔下的汉字有的是不再使用的繁体字,有的是跟现代汉字有区别的本国字,这些字在传统意义上讲很难说是别字或错字。字本位描述法从字形表面的偏误特征出发,克服了人本位描述法中错别字的区分,但也掩盖了日韩学习者偏误汉字独有的特点,如沿用日语(韩语)繁体字、中日(韩)骈体字、日语(韩语)当汉字等。因此,如何科学有效地描述日韩学习者的偏误字也当前是亟待解决的重要难题。
(五)评估偏误阶段
在评估偏误上,目前几乎所有的研究都通过比较偏误率来评估偏误,即仅从偏误严重性的角度上进行评估,忽略了对偏误理解性和偏误冒犯性的评估。然而,即使在偏误严重性的评估上,偏误率也面临很多问题。首先,偏误率是由偏误的统计学规定决定的,由于观察角度、语料的搜集方式不同等原因,不同研究者制定的偏误统计规定也不相同,甚至某些规定之间还存在矛盾。如王宁规定“不同人在同一字的相同偏误只记一次”,(26)王宁.菲律宾学生汉字习得的偏误分析及教学策略[D].西北大学硕士学位论文,2014.而大多数研究者都认为“不同人在同一字的相同偏误按人次记”,这就使同一群体学习者的偏误率各不相同;其次,即使研究者在偏误统计的规定上相同,他们在偏误率的计算方法上也不一定相同。一种观点认为偏误率=各类型的错字量/全部错字量;(27)刘国画.泰国中学生汉字偏误分析及教学策略[D].暨南大学硕士学位论文,2008;贾君君.泰国小学生汉字书写偏误分析—以安努班丹昌小学为例[D].河北大学硕士学位论文,2017.另一种观点认为偏误率=各类型的错误处/全部错误处,(28)杜洪泽.泰国曼谷奇诺罗中学零基础学生汉字书写偏误分析[D].云南大学硕士学位论文,2014;周玲玉.泰国华校中学生汉字书写偏误调查报告—以东盟普及泰华学校为例[D].河北大学硕士学位论文,2015;陈彩虹.泰国中学生汉字偏误书写分析—以泰国普及皇太后中学为例[D].云南师范大学硕士学位论文,2016.这也会导致相同群体学习者的偏误率各不相同。最后,偏误统计规定下的偏误率在评估偏误中的作用被大大高估了。牛士伟认为,学习者的偏误可分为个体偏误和群体偏误。(29)牛士伟.外国汉语学习者汉字书写偏误研究的特点与反思[J].广东外语外贸大学学报,2018,(2).偏误统计规定下的偏误率不仅忽略了个体偏误的有关情况,不利于有针对性地进行汉字纠偏,而且也冲淡了群体偏误的具体内容,多少人在多少字上存在哪些偏误类型也不得而知,这些问题都削弱了严重性评估的效果。
另外,以往的偏误研究大多只在语法或语义层面用到了理解性评估和冒犯性评估。胡莎在汉字书写偏误研究中首次从理解性维度上评估了各类偏误是否会影响读者对字词义、语境义的理解,其影响程度有何不同等。(30)胡莎.MBBS印度留学生HSK三级常用字书写偏误分析——以东南大学2017级为例[D].东南大学硕士学位论文,2019.尽管得到了一些有价值的结论,但仍需更多的研究进一步验证。此外,至今仍未见冒犯性评估在汉字偏误研究中的应用,这些都是评估偏误面临的重要问题。
(六)解释偏误阶段
解释偏误是汉字纠偏和改进汉字教学的直接依据。它主要面临两个问题:一是三角测定法的局限性问题,二是偏误原因共性中的个体差异问题。对于第一个问题,目前主要有两类解释方法:一种是从汉字本身、学习者和教师教学三方面通过理性分析得出偏误原因,另一种是针对偏误现象通过问卷调查或个案访谈来了解被试产生偏误的原因,也叫三角测定法。(31)牛士伟.外国汉语学习者汉字书写偏误研究的特点与反思[J].广东外语外贸大学学报,2018,(2).尽管通过理性分析得出的偏误原因无可厚非,但与三角测定法相比,其解释力在程序上明显略逊一筹。当然,尽管三角测定法考虑到了与被试核实偏误原因的重要性,但要求学习者回忆犯错时的想法,可能在操作上并不容易,就像Bartlett’s总结的:人们是按照他们认为情节该怎样发生来记住某个事件,而不是照搬原真实情节,(32)安然,单韵鸣.非汉字圈学生的笔顺问题—从书写汉字的个案分析谈起[J].语言文字应用,2007,(3).而且并非所有的错误假设都能由学习者说得清楚。(33)韩明现.科德的错误分析模式初探[J].山东教育学院学报,2000,(5).
对于第二个问题,在解释偏误时,无论理性分析还是问卷调查抑或是个案访谈,汉字本身的特点、学习者母语的负迁移、学习动机和学习策略、教师的教学方法、教材和课程等因素似乎是所有书写偏误研究都共有的因素,至于这些因素如何作用于学习者,怎样通过学习者产生了何种偏误不得而知。另外,这些共性偏误原因的背后是否存在个体差异,如果有,这些差异体现在学习者的国别、年级、汉语水平还是其他方面也不得而知。
三、反思与小结
在确定研究对象阶段,学习者的个体信息会影响汉语水平的划分。以学习年限划分汉语水平会涉及很多因素,如学习者的年龄、专业及母语背景等;以掌握汉字(词汇)的多寡划分汉语水平尽管能最大程度上减少学习者个体因素的影响,但“掌握”的定义、“字词”的范围也是问题;而以通过标准化HSK考试的级别划分汉语水平不仅避免了个体信息的影响,而且这种划分标准更客观、更准确。目前,大多数研究者将通过HSK一二级考试的学生的汉语水平划分为初级,通过三四级的为中级,通过五六级的为高级。另外,在书写偏误研究中,一方面要继续深化国别化研究,尤其是努力探寻其他未知国家和地区学习者的汉字偏误情况,为全面了解学习者的书写偏误做准备;另一方面要加强对非汉字文化圈国家学习者书写偏误的研究,在制定国家语言文字政策时,适当倾向于那些汉语教学点较少、教师资源较贫乏的国家和地区。鼓励海外留学生“走进来”和国内汉语教师“走出去”,这是从源头上平衡不同国家和地区偏误研究的有效途径。
在搜集语料阶段,语料的自然性和真实性是语料有效性的决定因素,而他们之间很可能是一种悖论关系,即学习者在自然状态下产生的语料其真实性很可能受到影响,而能够反映学习者真实水平的语料又存在不自然的问题。因此,为平衡语料的自然性和真实性,很多研究者都通过综合运用不同来源的语料来解决这个问题。另外,从信息加工的角度看,“作业”“试卷”“问卷调查”和“语料库”的输入和输出都是视觉信息,而“听写”输入的是听觉信息,输出的是视觉信息,它是学习者输出汉字的重要途径,代表了学习者信息加工的方式。因此很多研究者在搜集语料时都采用了“听写”的方式。还有,自然性指的是学习者在自然状态下产生的语料,其“自然状态”决定了学习者不会紧张起来调动资源努力解决问题,而真实性指的是反映学习者当前语言学习水平的程度,这就意味着学习者要集中精力调动资源努力解决问题,而这也决定了学习者不能在自然状态下输出语料。可见,我们对二者的认识决定了它们之间的关系,决定了语料的自然性和真实性,也决定了语料的搜集方式。因此,要想弄清楚语料的自然性和真实性问题,至少需要在以下两点取得突破:一是加强基础性研究,从可操作性角度重新定义语料的自然性和真实性,这是关键;二是在此基础上探讨评估语料自然性和真实性的方法,这是根本。只有这样,我们才能回答好语料自然性和真实性的一系列问题。
在鉴别语料阶段,基于外国人汉字书写偏误的情况与中国人不同,他们的“错字”和“别字”并不是我们常规意义上的“错别字”,因此对错字的判定不应采取“一刀切”的办法,而要在实践中进一步积累判定依据,进一步形式化和可操作化。另外,在统计错字时,学习者类偏误的情况要格外注意。以“王”字为例,张三有三个不同的错误类型,分别为错误1、2和3;李四也有三个不同的错误类型,分别为错误1、4和5。根据错误统计的一般原则,从个体层面看,“王”字对张三和李四来讲都是偏误字,对张三来讲,错误1、2和3不能算是他的偏误类,而只能算是他的类偏误,不必统计。同样的情况也适用于李四。从群体层面看,“王”字是张三和李四的偏误字,错误1是张三和李四的偏误类,而错误2、3、4和5只能算是张三和李四的类偏误,不必统计。当然,如果错误2、3、4和5又和其他个体的类偏误有重合,则这重合的部分又成为群体的偏误类,需要统计,而剩下的类偏误同样不必统计,以此类推。因此,从个体层面上看,个体的类偏误不必统计,这是没有问题的,但从群体层面上看,个体间的类偏误相互关联,不同个体的类偏误联合起来有可能成为群体的偏误类,因此在偏误统计时要格外注意。
汉字识别是认知心理学研究的重要领域,而特征加工和整字加工一直是汉字识别研究争论的焦点。在汉字识别研究中,一般通过观察被试完成不同任务时的反应时和眼动情况来推断被试汉字识别的加工模式,而真假字判断就是汉字识别实验常用的任务之一。从另外的角度看,实验中的假字也可以近似地理解为偏误字。只是前者是人造假字,后者是真实语料。通过观察被试在真假字判断时的反应时或眼动情况,发现越来越多的研究开始从不同角度支持特征加工和整字加工共同作用的模式。(34)管益杰,李燕芳,宋艳.汉字字形加工的关键特征模型[J].山东师范大学学报(人文社会科学版),2006,(2);张积家.整体与部分的意义关系对汉字知觉的影响[J].心理科学,2007,(5);常玉林,王丹烁,周薇.字形判断过程中的整体与局部优先效应:来自反应时和眼动指标的证据[J].心理科学,2016,(5).由此,在进行偏误归类时,从小归类的原则和先“大”后“小”的原则可能反映了人们知觉偏误时信息加工的两种方式,即自下而上的加工和自上而下的加工。前者从周围环境中的外部刺激开始,先分析较小的知觉单元,然后再转向较大的知觉单元,经过一系列的连续加工达到对感觉刺激的解释。如看到一个错字,视觉系统先从构成该字的基本单位—笔画着手,然后再转向笔画组合关系、部件、结构或整字,经过一系列加工,最终识别错字。后者基于过去知觉环境中的经验、知识、动机和文化背景,学习者对知觉对象的期望和假设制约着所有加工阶段和加工水平。如看到一个错字,研究者将这个字与头脑中的已有原型进行比较,头脑中的已有原型决定了这个字的错误类别。此外,信息加工理论还认为,没有环境中的外部刺激,自上而下的加工只能是幻觉,失去了自上而下的加工,自下而上的加工负担过重,难于应付一些刺激所具有的双关性质或不确定性,因此,知觉过程中的两种加工方式需要相互配合,共同完成统一的知觉过程。(35)刘瑞光,孟晓雷,胡书林.认知心理学中的信息加工理论[J].聊城师院学报(自然科学版),1999,(1).反映到偏误归类中,从小归类的原则可能要与先“大”后“小”的原则相配合,至于如何配合,可能还要借助认知心理学中汉字识别研究的有关成果,进一步考察偏误汉字的特点、学习者的个体因素以及信息加工的环境等,弄清楚什么样的人在何种情境下对哪些偏误字倾向于哪种方式的知觉加工,只有弄清楚这些问题,我们在偏误归类时才能从实际出发,客观公正,科学有效。
在严重性的评估上,文章认为应按照“明确评估层次—统一偏误规定—选择计算方式”这样的思路进行评估。首先,学习者的偏误分为个体偏误和群体偏误,(36)牛士伟.外国汉语学习者汉字书写偏误研究的特点与反思[J].广东外语外贸大学学报,2018,(2).因此评估偏误应分别从个体层面和群体层面进行;其次,在评估层次的基础上统一偏误规定:从个体层面上讲,同一人对同一字的相同错误只记一次,同一人对同一字的不同错误分别记录;从群体层面上讲,不同人对同一字的相同错误按人次记,不同人对同一字的不同错误分别记录。尽管以往的偏误研究并没有从个体层面和群体层面分别明确偏误统计规定,但很多研究中都表达了类似的观点。(37)刘国画.泰国中学生汉字偏误分析及教学策略[D].暨南大学硕士学位论文,2008;魏玲玲.留学生汉字偏误考察与分析—以中亚留学生为调查对象[D].复旦大学硕士学位论文,2013;贾君君.泰国小学生汉字书写偏误分析—以安努班丹昌小学为例[D].河北大学硕士学位论文,2017.最后,选择恰当的计算方法。文章赞同“偏误率=某类偏误数/总偏误数”的计算方法,因为这种方法考虑到了有的偏误字有两处及以上偏误的情况。这样,在严重性的评估上,从个体层面和群体层面,按照统一的偏误规定及计算方式得出的数据将会更可靠、更有说服力,不仅使偏误解释更全面、更深刻,而且也为汉字纠偏和改进汉字教学提供了最可靠的数据。此外,今后需增强理解性评估和冒犯性评估在汉字偏误研究中的应用,构建两个层次(个体层面和群体层面)、三个维度(理解性、严重性和冒犯性)全方位的评估方式。
在解释偏误阶段,三角测定法在一定程度上克服了单纯理性分析的片面性,更能接近偏误原因的本来面貌,但在利用其探寻偏误原因时仍需十分谨慎,要与其他方法获得的资料相互印证,减少由三角测定法本身的缺陷而导致的偏差。许欣妍在考察了学习者汉字偏误的情况后,通过汉字识别实验间接推导了偏误汉字产生的原因,(38)许欣妍.中亚汉语学习者汉字偏误识别的实验研究[D].华东师范大学硕士学位论文,2019.这种通过实验间接推导出的偏误原因虽然管中窥豹,但为我们探索偏误原因提供了新的思路。另外,在探寻偏误原因时,一方面,我们要继续开展有针对性的偏误研究,为探求共性原因做准备,另一方面,在共性研究发展到一定阶段时,探寻共性中的个体差异便又成为偏误研究进一步发展的需求。考察偏误原因在不同群体成员间是否存在性别、汉语水平、母语背景等个体差异是进一步深化个性研究的重要内容。汉字偏误研究正是循着从个性研究到共性分析再到个体差异研究的方向发展,螺旋式上升循环往复。
总之,确定研究对象、搜集语料、鉴别偏误、描述偏误、评估偏误和解释偏误是汉字书写偏误研究的基本程序。在研究过程中,各个环节都存在这样或那样的问题。由此我们大胆假设:在众多的偏误研究中,真正有效的研究会很少,偏误研究的有效性会很低。文章的主要目的是通过梳理以往偏误研究中的基本问题,提醒后继者在进行偏误研究时要充分考虑到各偏误环节中的基本问题,减少偏误分析中的不利因素,提高偏误研究的有效性,为汉字纠偏和改进汉字教学提供更可靠的依据和保障。
