对齐特征表示的跨模态人脸识别
2020-11-24王绍颖范春晓周江婉
明 悦,王绍颖,范春晓,周江婉
(北京邮电大学 电子工程学院,北京 100876)
1 引 言
跨模态人脸识别的目的是识别数据分布或外观差异较大的不同模态人脸图像[1]。近红外光与可见光人脸、侧脸与正脸、素描画像与照片等都是人脸的不同模态。在安防、刑侦、娱乐等场景中,跨模态人脸识别发挥着重要作用[2]。例如,在安防场景中,不可避免要识别近红外光下拍摄的人脸图像。大多数人脸识别算法,在面对跨模态人脸识别时准确率会大幅下降。因此,研究者开始深入研究不同模态人脸之间的差异,并提出多种跨模态人脸识别算法[3-8],降低不同模态人脸之间差异。
在跨模态人脸识别算法中,生成模型被广泛用于跨模态人脸合成和学习模态不变的特征表示[9]。生成对抗网络[10](Generative Adversarial Network, GAN)和变分自动编码器[11](Variational Auto-Encoders, VAE) 是两种常用于人脸合成的基本模型。GAN中包含生成器和判别器,二者交替训练和对抗,最终生成器生成能够欺骗过判别器的图像。然而其交替训练过程会导致训练不稳定。为克服这一缺陷,一些算法[12-13]采用VAE进行人脸合成。与GAN相比,VAE具有更加稳定的训练过程,通过最小化重构损失函数可构建输入数据的潜在高斯分布空间,并合成逼真的人脸,从而获得具有鲁棒性和判别能力的紧凑分布,适用于跨模态人脸识别任务。因此,本文将使用VAE作为基本模型,学习判别性的潜在高斯分布空间。
VAE模型能够很容易地构建出重建图像空间和潜在高斯分布空间。因此,相比于直接跨模态合成人脸或对齐潜在向量等在单一空间学习跨模态信息的算法[4-5],本文基于VAE模型提出一种基于对齐特征表示的跨模态人脸识别算法(Cross-Domain Representation Alignment, CDRA),提取不同模态人脸图像中能标识身份的特征信息和跨模态关联信息。该方法采用潜在高斯分布空间直接进行特征对齐,并在图像空间间接建立不同模态人脸间的联系方式,实现不同模态人脸特征在多空间维度的对齐,在图像空间和潜在子空间同时学习更加具有判别性的身份信息和更加丰富的多层次跨模态信息。如图1所示,是CDRA算法的框图。图中模态A和B为同一个人的可见光图像和近红外光图像。编码器通过模态内重建损失函数(LDSR)学习高斯潜在分布,交叉模态重建对齐损失函数(LCMA)和高斯分布对齐损失函数(LGDA)协同作用对齐潜在特征表示,将不同模态的潜在特征投影到共同的潜在子空间。该方法主要分为两部分:
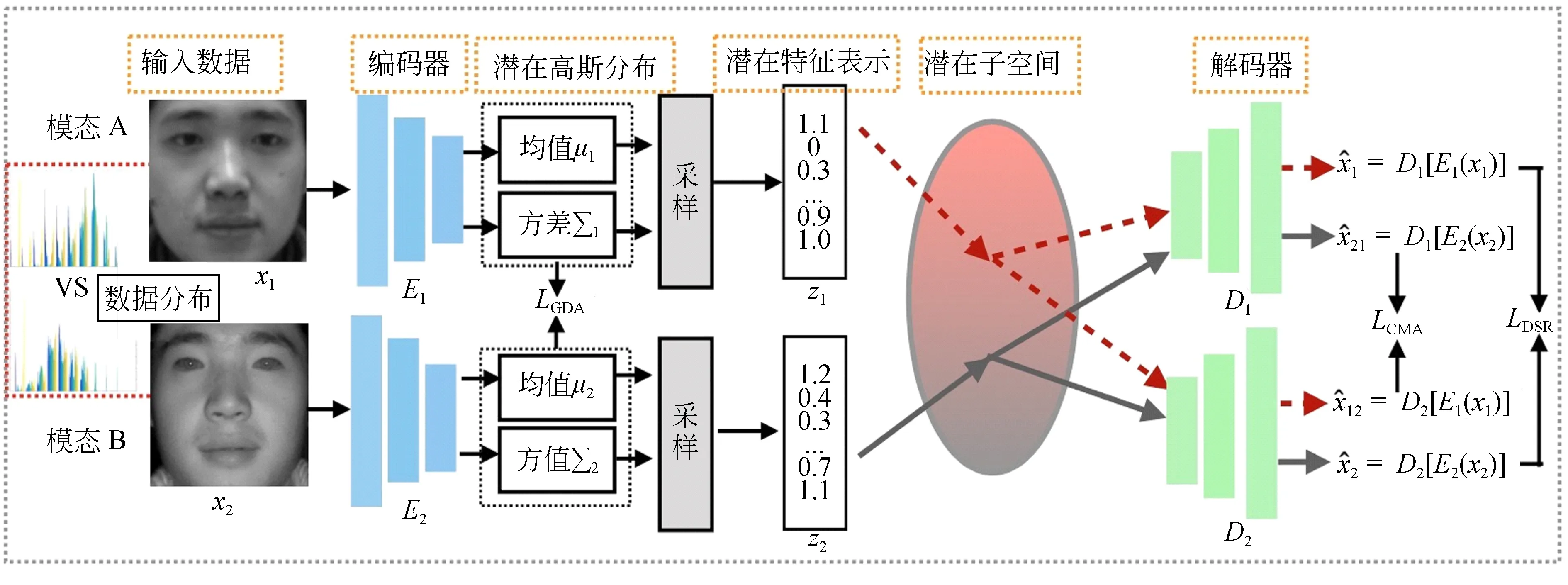
图1 基于对齐特征表示的跨模态人脸识别算法(CDRA)的流程框图Fig.1 Framework of Cross-Domain Representation Alignment (CDRA)algorithm
(1)模态内信息提取。为减少特征学习和特征重建过程中的信息损失,CDRA算法首先利用模态内重建(Domain-Specific-Reconstruction,DSR)损失函数来提取同一模态人脸数据的内在身份信息,主要包括同一模态人脸数据中的身份判别信息和纹理、结构等细节信息。
(2)模态间信息提取。在学习到身份信息的基础上,为减少不同模态人脸特征的差异,本文提出使用交叉模态重建对齐(Cross-Modal-Alignment, CMA)损失函数将潜在特征空间中某一模态的特征重构至另一模态的图像空间,学习不同模态特征间相关联的潜在信息,并利用高斯分布对齐(Gaussian-Distribution-Alignment, GDA)损失函数对齐高斯潜在分布,进一步减少不同模态人脸之间的差异。因此,CDRA算法基于CMA和GDA损失函数,将不同模态的潜在特征表示对齐到同一潜在子空间。
本文提出的CDRA算法主要的贡献如下:
(1)本文提出一种端到端的跨模态特征匹配算法。该算法基于VAE模型构建不同模态人脸的重建图像空间和压缩的高斯分布空间来对齐跨模态潜在特征表示,并且能够很容易地扩展为同时对齐两个以上的模态。
(2)本文提出使用DSR损失函数,学习模态内人脸具有判别能力的身份信息,能够有效减少特征对齐过程中的信息损失。
(3)本文通过CMA和GDA损失函数在人脸图像空间和潜在高斯分布空间协同学习公共的潜在特征表示空间,从而在不同空间提取到不同模态人脸间更加丰富的关联信息。
(4)来自于公共潜在特征表示空间的特征作为输出特征,直接用于跨模态人脸识别。本文在跨模态人脸数据集Multi-Pie和CASIA NIR-VIS 2.0上进行人脸识别实验。实验结果表明,CDRA算法获得了比现有方法更高的识别准确率,并具有良好的泛化能力。
2 跨模态人脸识别算法
跨模态人脸识别算法主要分为三类:潜在子空间方法、人脸合成方法和模态不变的特征方法。本节将从这三类方法分别综述近年来跨模态人脸识别领域的相关工作。
潜在子空间方法的目标是将不同模态的数据投影到一个公共的潜在子空间中。Wang等[14]将CCA (Canonical Correlation Analysis)引入到自动编码器中,学习针对不同模态特征的非线性子空间。MvDA (Multi-view Discriminant Analysis)[15]方法通过联合学习人脸多个视点的线性变换,寻找多个视点具有判别性的公共子空间。Wu等[3]通过在跨模态变量上施加松弛约束来为不同模态的人脸特征学习公共的解构潜在空间。潜在子空间方法可以很容易地减少不同模态人脸之间的模态差异,但是在投影的过程中会存在一定程度的信息丢失。
人脸合成方法利用生成模型将人脸从一个模态合成到另外一个模态,以减少不同模态人脸数据的差异。马尔科夫网络方法[16]基于人脸的局部块合成,实现跨模态的人脸生成。Zhang等[8]利用Siamese网络解构不同模态的人脸数据,通过编码-解构-解码的形式,减少不同模态人脸之间的差异。基于GAN的方法[7,17-18]通常通过感知图像全局或局部细节,实现不同模态间人脸的相互合成。一般人脸合成的方法对于不同的人脸生成任务需要不同的学习机制,因此人脸合成方法存在泛化能力较弱的缺点。
模态不变的特征方法旨在从同一个体不同模态的人脸中学习模态不变的特征。CDL (Coupled Deep Learning)[5]提出一种跨模态的排序机制,能够最大化类间的差异和类内不同模态之间的差异。He等[4]将Wasserstein距离引入到共享网络层中,度量不同模态人脸特征分布之间的差异。DFN (Deformable Face Net)[19]为可形变卷积层学习姿态感知的位移场,从而提取到姿态不变的人脸图像。但是当不同模态的人脸数据存在较大差异时,直接提取模态不变的人脸特征比较困难[20]。
不同于上述方法,本文提出的CDRA算法基于VAE模型学习潜在特征表示空间,并通过对齐潜在特征表示来实现跨模态人脸识别。首先,为减少信息丢失,CDRA算法利用DSR损失函数尽可能地学习具有判别能力的人脸特征表示。在此基础上,CMA和GDA损失函数分别在图像空间和潜在高斯分布空间对不同模态的人脸特征表示进行对齐。相比于单一空间对齐的方法,在图像空间和分布空间同时进行对齐的CDRA算法,能够获得不同模态人脸间多个空间维度不同层次的关联关系,有利于提取到更具判别能力的跨模态关联信息。并且,CDRA算法本质是对不同模态人脸数据的特征表示进行对齐。因此,适用于不同的跨模态人脸识别任务,而不需要改变学习机制。
3 基于对齐特征表示的跨模态人脸识别算法
基于对齐特征表示的跨模态人脸识别(CDRA)算法是将两个模型学习得到的特征表示进行对齐,构建不同模态人脸特征之间相关联的公共潜在特征空间。为减少信息损失和实现更有效的特征对齐,CDRA算法首先通过模态内重建(DSR)损失函数,学习单一模态人脸具有判别能力的信息。基于交叉重建和分布对齐原则,为实现特征在图像空间的精准映射和在特征空间不同模态特征的精准匹配,通过交叉模态重建对齐(CMA)损失函数和高斯分布对齐(GDA)损失函数实现特征对齐表示。不同于之前在单一图像或分布空间对不同模态的特征表示进行对齐。CDRA算法利用CMA损失函数和GDA损失函数在图像空间和分布空间协同建立不同模态人脸间的联系,从而促进不同模态的潜在特征表示在多空间维度实现更加精确的对齐。接下来,本节将描述CDRA算法的损失函数及其数学表达式。
3.1 VAE和模态内重建(DSR)损失函数
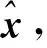
Lre=-Ez~Q(z|x)logP(z|x),
(1)
其中:z是独立的高斯随机变量,即z∈N(0,1)。VAE通过梯度下降算法最小化Q(z|x)的分布与高斯分布P(z)的差异,即最小化二者的KL散度,对潜在向量z的分布进行控制:
LKL=D[Q(z|x)‖P(z)].
(2)
因此,VAE是损失函数Lre和LKL共同组成:
LVAE=Lre+LKL.
(3)
CDRA算法的目标是学习n种模态的数据在公共潜在空间的特征表示。因此,CDRA算法模型中包含n个VAE模型。为了减少信息损失和提取具有判别能力的信息,每一个VAE中的编码器将一种模态的数据编码到潜在高斯分布空间,解码器从潜在特征表示中重建出原始输入数据。CDRA算法的模态内损失是n个VAE损失的总和,称为模态内重建(DSR)损失函数:
LDSR=
βD[Q(z(i)|x(i))||P(z(i))],
(4)
其中:β系数决定KL散度项的权重。通过最小化DSR损失,CDRA算法中每个VAE模型的潜在特征表示空间能够学习到具有判别能力的模态内特征表示。
3.2 交叉模态重建对齐(CMA)损失函数
交叉模态重建对齐是通过解码来自同一个体另一模态的潜在特征表示来实现的。也就是说,模态A的潜在特征表示输入到模态B的解码器中来重构模态B的人脸图像,而模态B的潜在特征表示输入模态A的解码器中来重构模态A的人脸图像。因此,每一个模态的解码器除了用于训练对应模态的潜在特征表示,也将用于训练另一模态的潜在特征表示。CMA损失函数定义如下:
(5)
其中:E(i)表示第i个模态的样本通过编码器得到特征表示,D(j)表示特征通过解码器得到的第j个模态的重建样本。通过CMA损失函数对模型进行优化,能够在图像空间中学习到不同模态之间的关联信息,并映射到潜在特征空间,从而实现将不同模态人脸图像的潜在特征表示映射到同一潜在子空间。
3.3 高斯分布对齐(GDA)损失函数
高斯分布对齐通过最小化同一个体不同模态的潜在高斯分布Wasserstein距离[4]实现。两个不同模态人脸数据高斯分布之间的2-Wasserstein距离,可构成封闭解:
(6)
其中,对角协方差矩阵由编码器预测,具有可交换性。因此公式(6)可以简化为:
(7)
其中,F表示Frobenius范数。因此,在CDRA算法中,GDA损失函数写作:
(8)
通过GDA损失函数能够进一步对齐不同模态的特征表示,提高CDRA算法模型的跨模态表达能力。
3.4 CDRA算法损失函数
CDRA算法的总体目标损失函数包括DSR损失函数、CMA损失函数和GDA损失函数。DSR损失函数能够减少信息损失,学习模态内具有判别能力的身份信息。CMA损失函数和GDA损失函数能够有效地关联不同模态人脸的图像空间和潜在分布空间,学习跨模态信息。为同时学习具有判别能力的身份信息和跨模态信息,CDRA算法将三种损失函数有机结合,学习不同模态人脸的公共潜在空间和特征表示。
L=LDSR+γLCMA+δLGDA,
(9)
其中γ和δ系数表示CMA损失函数和GDA损失函数的权重。γ和δ系数在训练的不同阶段将被设置不同的权重值,有利于逐步实现特征表示对齐。在特征对齐表示的基础上,不仅可以直接从潜在特征表示空间提取到模态不变的特征,而且可以由解码器解码潜在特征得到相应模态的生成人脸。具体细节将在下节中介绍。
4 训练算法
基于对齐特征表示的跨模态人脸识别(CDRA)算法采用基于卷积神经网络的VAE模型[21]学习含有高层语义信息的特征。如图2是基于卷积神经网络的VAE模型的结构框图:
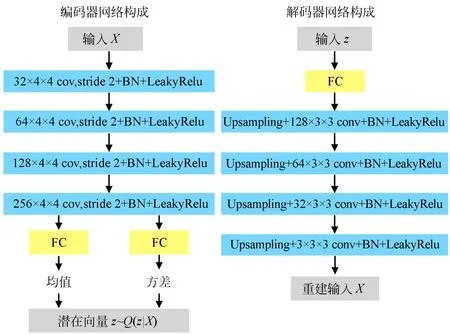
图2 基于卷积神经网络的VAE模型的结构框图Fig.2 Framework of VAE model based on convolutional neural network
(1)编码器由4个卷积层组成,卷积核为4×4,通过将步长设置为2实现下采样。在每个卷积层后都添加批量归一化(Batch Normalization,BN)来优化网络结构,并使用带泄露修正线性单元(Leaky ReLU)函数作为激活函数。
(2)在编码器中加入两个全连接的输出层,分别用于计算均值和方差,均值和方差将用于计算潜在特征表示和KL散度。
(3)解码器的卷积核设置为3×3,步长设置为1,通过最近邻法实现上采样。
在基于卷积神经网络的VAE中,编码器和解码器的结构大致对称:编码器实现学习到能够表示输入样本的潜在特征表示;解码器由潜在特征表示逐步上采样,实现从低分辨率重构样本中重建出高分辨率的重构样本。
在模型的训练阶段,CDRA算法模型首先通过DSR损失函数训练VAE学习模态内具有判别能力的信息。在变分自动编码器学会对特定模态进行编码之后,通过CMA损失函数和GDA损失函数约束模型将不同模态的特征映射到公共的潜在空间,实现精确的特征对齐。
CDRA算法模型采用warm up策略预热损失函数的权重并使用贝叶斯优化(Bayesian Optimization)确定权重值,初始值设置均为0,然后以不同的步长增长,如图3所示:δ从第6个epoch开始到第44个epoch为止,以0.27为步长递增;γ从第21个epoch开始到第150个epoch为止,以0.022为步长递增;对于KL散度损失的β系数,从第0个epoch开始到第180个epoch为止,以0.001 3为步长递增。为进一步增强潜在特征表示的判别能力,学习得到的潜在特征表示还将输入到softmax层。softmax损失函数从第50个epoch开始起作用。
图3 CDRA算法损失函数中基于warm up更新的参数权重值Fig.3 Weight parameters updated by warm up strategy in CDRA method′s loss functions
在测试阶段,CDRA算法模型通过可视化人脸生成的效果和人脸识别的准确率对学习得到的对齐潜在特征表示的效果进行验证:
(1)在人脸生成的实验中,A模态的人脸输入模态A的编码器得到模态A到人脸特征表示,将该特征输入到模态A的解码器中,则能够重建出模态A的人脸,而输入到模态B的解码器,将重建出模态B的人脸。
(2)在人脸识别的实验中,模态A的人脸图像和模态B的人脸图像分别输入到模态A的编码器和模态B的编码器中,模态A的编码器和模态B的编码器将两种模态映射到公共的潜在特征表示空间,二者对齐的潜在特征表示将作为最终输出的人脸特征,直接用于人脸识别中。
5 实 验
本文提出CDRA算法在经典的姿态人脸数据集Multi-Pie[22]近红外光和可见光人脸数据库CASIA NIR-VIS 2.0[23]上进行实验,并对实验结果进行分析和总结。在Multi-Pie[22]和CASIA NIR-VIS 2.0[23]数据集中均包含两种人脸模态,因此,n=2。
5.1 实验数据集
Multi-Pie:Multi-Pie[22]数据集用于姿态人脸对正脸的识别。数据集中前200人的图像(共计161 460张)作为训练集,剩余137人的图像作为测试集,包括probe集 (共72 000张)和gallery集(共137张)。其中正脸作为一种模态,包含姿态变化的人脸作为另一种模态。
CASIA NIR-VIS 2.0:CASIA NIR-VIS 2.0[23]数据集是目前最大和最具挑战性的可见光(VIS)和近红外光(NIR)异构人脸识别数据库。它包括725人,每个人有1~22张可见光和5~50张近红外光图像,分为10个子集。训练集含有来自360人的大约2 500张可见光和6 100张近红外图像。在测试集中,gallery集中包含358人的可见光图像,每个人只有一张图像,probe集包含着358人的6 000多张近红外图像。
5.2 潜在特征表示维度的影响
潜在特征表示维度是CDRA算法模型中,唯一需要进行手动选择的参数。因此,本节通过实验分析模型中潜在特征表示的维度对模型性能的影响,从而确定模型中公共潜在空间的最佳特征维度。
实验结果如图4所示,随着特征维度的增加,人脸识别的准确率总体呈现先上升后下降的趋势。在维度为128时,人脸识别准确率在两个数据库上均到达顶峰。原因主要有以下两点:(1)潜在特征表示的维度越大,模型的复杂程度和灵活度也越高,就能够学习到性能更好的特征表示;(2)潜在特征表示是对输入人脸数据的压缩表示,能够学习到人脸数据中最重要的特征表示。但是,如果维度太大,潜在特征空间会学习到人脸数据中不太重要的信息,反而会降低模型的特征表示能力。
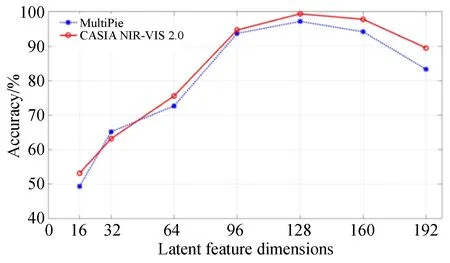
图4 潜在特征表示维度对人脸识别准确率的影响Fig.4 Face recognition accuracy rates with different latent feature dimensions
潜在特征表示维度的选取需要兼顾模型的复杂度和性能,因此,根据实验结果和分析,在后续实验中,选取的特征维度为128。
5.3 DSR,CMA,GDA损失函数的影响
为了确定DSR,CMA和GDA损失函数的影响,在不改变网络结构的前提下,本实验将采用不同损失函数的组合对网络模型进行训练和测试。不同损失函数的组合包括LDSR,LDSR+γLCMA,LDSR+δLGDA和LDSR+γLCMA+δLGDA。
如图5所示,由于基于LDSR训练的模型仅在模态内学习表示单一模态的信息,而不能获取不同模态之间的相关性,因而学习得到的模型的跨模态人脸识别准确率最低。基于LDSR+γLCMA和LDSR+δLGDA训练的模型通过在图像空间或潜在分布空间对齐潜在特征表示,提高了跨模态人脸识别准确率。而基于LDSR+γLCMA+δLGDA训练的模型相比于基于LDSR+γLCMA和LDSR+δLGDA训练的模型在Multi-Pie和CASIA NIR-VIS 2.0数据集上准确率均有较大幅度提升。这证明在图像空间和潜在分布空间同时对齐分布,能够建立图像空间和潜在分布空间的内在联系,有利于潜在特征表示学习到更具有判别能力的跨模态信息。

图5 损失函数对人脸识别准确率的影响Fig.5 Face recognition accuracy rates with different loss functions
5.4 Multi-Pie数据集上的实验结果
CDRA算法在姿态人脸数据集Multi-Pie上不同角度变化的人脸对正脸的识别。在该数据集上,本文使用人脸识别的准确率(识别正确的样本/样本总数)作为评价指标,实验结果如表1所示。
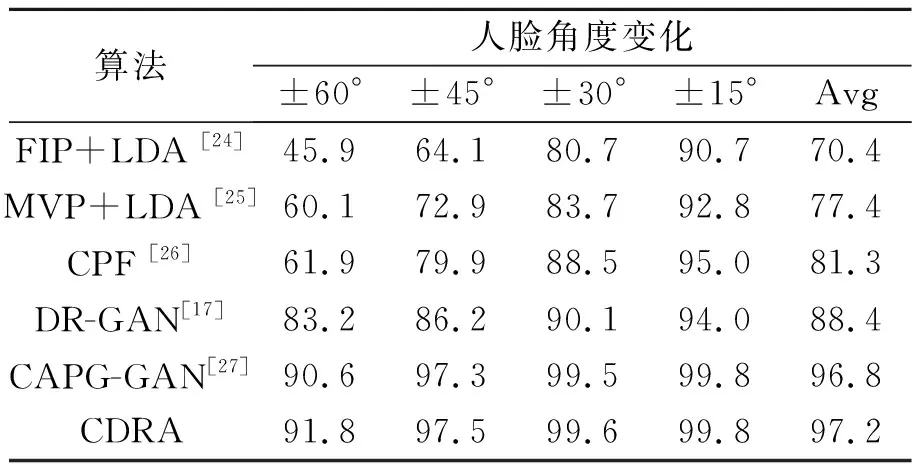
表1 Multi-Pie数据库上的人脸识别准确率
实验结果表明,随着人脸变化角度的增加,人脸纹理信息丢失的越来越多,因而所有方法的人脸识别准确性都随着角度的增加而下降。FIP+LDA[24]和MVP+LDA[25]算法在提取到对姿态鲁棒的特征后,利用LDA进一步提高特征的判别能力。而CPF[26],DR-GAN[17]和CAPG-GAN[27]算法通过对姿态进行编码,指导网络合成正脸。不同于上述方法,CDRA算法通过DSR损失函数学习具有判别能力的信息,然后通过CMA和GDA损失函数在图像空间和潜在分布空间学习跨模态信息,从而减少含有角度变化的人脸与正脸之间的潜在特征表示差异。因此,CDRA算法不仅能够在潜在特征分布空间学习到对姿态鲁棒的人脸特征,而且能够从公共的潜在特征空间中解码重建出正脸图像。如图6所示,是CDRA算法人脸合成的效果图。其中,a,c,e行是含有姿态变化的原始人脸,b,d,f行是合成的正脸。经观察可知,CDRA算法对人脸的一些外观细节实现了较为真实的合成,这表明不同模态的潜在特征表示不仅实现了精准对齐,而且包含具有判别能力的身份信息和结构信息。

图6 CDRA算法的人脸合成效果Fig.6 Visualization of face synthesis of CDRA method
5.5 CASIA NIR-VIS 2.0数据集上的实验结果
CDRA算法在可见光(VIS)和近红外光(NIR)人脸图像数据集CASIA NIR-VIS 2.0上进行VIS-NIR人脸识别实验,并与现有的最好的算法进行比较。在该数据集上,本文使用人脸识别的准确率和当假正类率(FAR)=0.1%时的真正类率(TAR)值作为评价指标,实验结果如表2所示。实验结果表明,CDRA算法能够将可见光与近红外光人脸图像映射到公共的潜在特征表示空间,有效地减少可见光与近红外光人脸图像之间的差异,提高了VIS-NIR人脸识别的准确率。

表2 CASIA NIR-VIS 2.0数据库上的实验结果
基于传统手工设计特征的方法KDSR[28]难以克服不同模态人脸间数据分布的差异,学习到具有模态不变性的特征。基于深度学习的方法Gabor+RBM[29],IDNet[30],CDL[5],ADFL[31],DVR[3]和Peng等.[33]得益于深度特征具有更强的表达能力[32],在VIS-NIR人脸识别中表现出较为出色的性能。本文提出的CDRA算法不仅在图像空间对可见光和近红外光人脸进行对齐,而且在潜在高斯分布空间对可见光和近红外光人脸的潜在特征分布进行对齐,从而在不同的空间学习到不同模态之间更强的关联信息。
5.6 人脸生成实验结果
CDRA方法在CUHK-CUFS[34]数据集上进行人脸生成的实验。该数据集包含素描人脸和照片人脸,CDRA模型中的编码器将素描人脸和照片人脸映射到同一潜在特征空间,而解码器将潜在特征解码为照片人脸和素描人脸。因此,CDRA模型可同时实现由人脸照片和人脸素描画像的互相转换,即由照片生成素描人脸和由素描人脸生成照片。
本文将CDRA方法与非GAN类方法和GAN类方法的生成人脸进行可视化对比,实现结果如图7和图8所示。非GAN类方法(MWF[35],SSD[36],RSLCR[37],FCN[38])生成的图像通常呈现较为模糊的效果,而GAN类方法(GAN[39],CycleGAN[40],DualGAN[41],CSGAN[42],EGGAN[43])生成的图像包含较为丰富的纹理和细节信息。但是非GAN类方法生成的图像与原始图像的相似性更高,而GAN类方法生成的图像在相似性保持方面表现不足。本文提出的CDRA方法更倾向于保持与原始图像的相似性,对于眼睛、鼻子等部分的细节信息生成效果较好,但是头发和衣服部分的生成图像较为粗糙。这是因为变分自动编码器的潜在特征空间是学习人脸的压缩表示,会提取到人脸中结构和五官等重要的信息,忽略不太重要的头发、配饰等信息。

图7 CUHK-CUFS数据集中由照片生成素描人脸的效果图Fig.7 Visualization of the sketch face synthesis from photos in CUHK-CUFS dataset

图8 CUHK-CUFS数据集中由素描生成照片人脸的效果图Fig.8 Visualization of the photo face synthesis from sketches in CUHK-CUFS dataset
本文使用SSIM作为生成图像的质量评测标准。SSIM用于测量原始人脸与生成人脸之间的结构相似性。
表3和表4是CDRA与现有方法在CUHK-CUFS和CUHK-CUFSF数据集上的SSIM值。本文不仅测试了由人脸照片生成的人脸素描图像的SSIM值,而且测试了由人脸素描图像生成的人脸照片的SSIM值。SSIM的取值范围是0~1,SSIM值越大表示两张图片越相似。实验结果表明,由人脸照片生成的人脸素描图像的SSIM值要整体低于由人脸素描图像生成的人脸照片的SSIM值。这是因为在绘制人脸的素描图像时,绘制者的手法不同,但是模型是所有绘制手法的统一表示。因此,由人脸照片生成素描图像比由素描图像生成人脸照片更加困难。
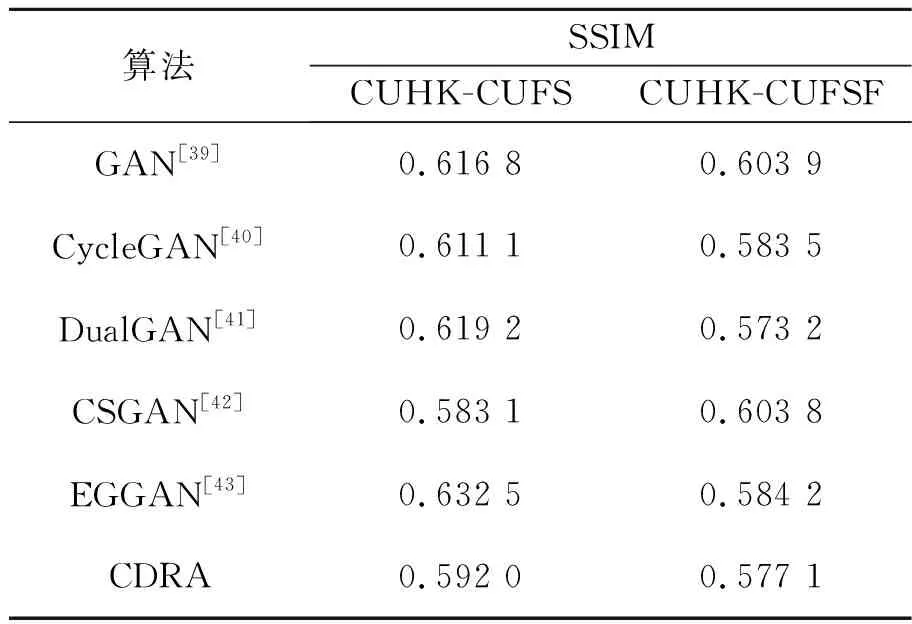
表4 由素描人脸生成照片人脸的SSIM值
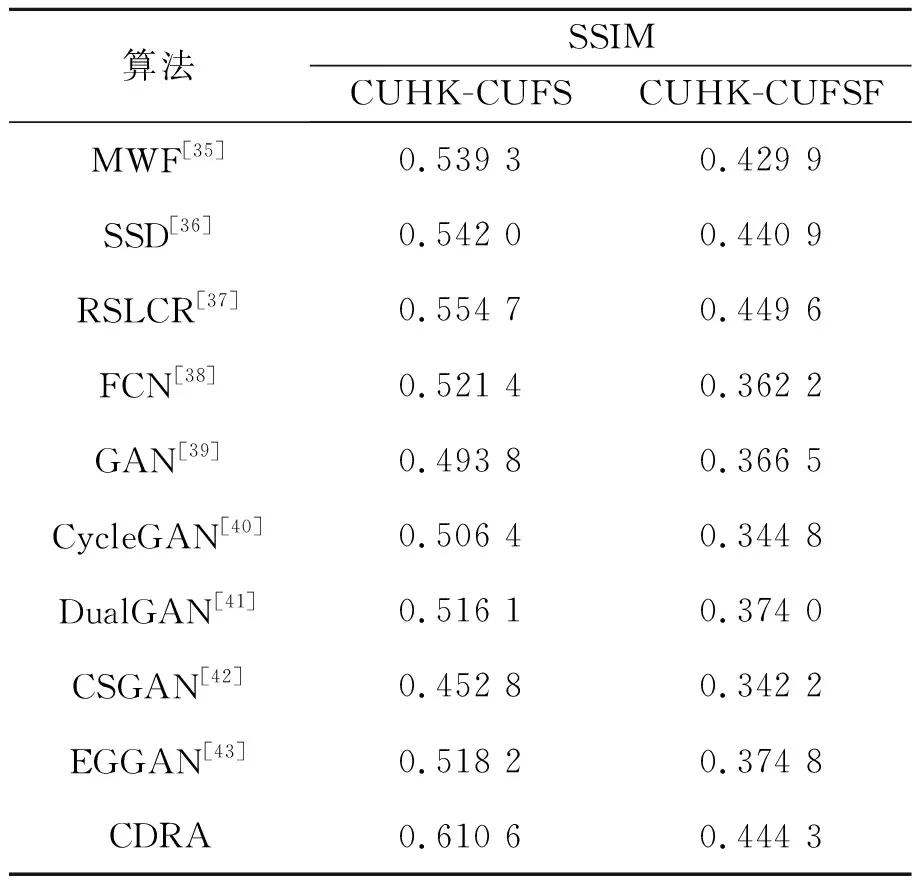
表3 由照片人脸生成素描人脸的SSIM值
非GAN类方法在SSIM上的表示要优于GAN类方法,原因是GAN类方法倾向于合成具有清晰纹理的图像,却容易忽略保持人脸的结构相似性。本文提出CDRA方法在非GAN类方法和GAN类方法中均获得较高的SSIM值。CDRA在图像空间的对齐使得图像获得纹理信息,在特征空间的对齐保证同一个体的人脸保持相似性信息,从而使得生成的人脸图像获得了较好的结构相似性。
6 结 论
本文提出了一种基于对齐特征表示的跨模态人脸识别算法(CDRA)。该算法基于VAE模型,利用DSR损失函数,促使CDRA算法模型从每一种人脸模态中学习到具有判别能力的身份信息。在此基础上,CMA和GDA的损失函数协同作用,在图像空间和潜在分布空间对不同人脸模态的潜在特征表示进行了有效的对齐,从而在不同的空间维度进一步增强了不同模态间的关联性。CDRA算法在不同的跨模态人脸识别任务中均表现出色,在Multi-Pie数据集上的人脸识别的准确率的平均值为97.2%,在CASIA NIR-VIS 2.0数据集上的人脸识别准确率为99.4%±0.2%,同时在CUHK-CUFS数据集的人脸跨模态生成实验中表现出较好的人脸结构相似性和局部细节描述能力。综上所述,CDRA算法具有良好的判别能力和泛化能力。
