面向电网安全监测的领域本体自动构建①
2020-11-24于碧辉
于碧辉,孙 思,2,李 岳,2
1(中国科学院 沈阳计算技术研究所,沈阳 110004)
2(中国科学院大学,北京 100049)
本体原本是一个哲学概念,随着人工智能领域的发展,被赋予了新的定义,领域内学者对此进行了深入的研究,对本体的定义也在不断发展变化,目前被广泛认可的是1998年Studer 对本体的定义:“本体是共享概念模型的明确的形式化规范说明”.本体主要依靠概念、概念之间的关系以及公理来发挥作用,其中关系又包括层次关系以及非层次关系[1,2].
关于本体的研究与应用主要围绕3 个方面:(1)对本体概念以及分类等等理论上的研究.(2)应用在信息系统中,包括信息组织、信息检索以及异构系统互操作问题.(3)应用在语义网中,在知识层提供知识重用和共享的依据.本体可以分为3 个层次:上位本体、领域本体和面向应用的本体.上位本体是可跨领域复用的本体,为不同本体之间的逻辑组织提供保证.领域本体针对某一个特定的学科、专业或领域,表述适用于这一范围内广泛使用的概念和关系.面向应用的本体是为了特定应用构建的本体知识库.
如今,本体构建主要有3 种方法,由领域专家和本体专家参与的手动构建方法;使用机器学习、深度学习或者自然语言处理的自动构建方法;融合了上述两种方法的半自动本体构建方法.然而,手动构建本体方法中本体概念的抽取以及概念之间的关系均通过人工来定义,依赖于本体专家的意见耗费大量人力,时间,而且依赖于人的主观性,具有高度局限性.因此,手工构建方法逐渐被半自动化、自动化构建方法取代,自动构建本体方法可以方便的和其他机器学习、自然语言处理领域相结合,可以使用不同的数据源来进行构建,文本数据具有数据来源广泛、便于获取等特点[3].鉴于此,本文采用电力安全相关文本作为数据源进行领域本体的自动构建并对构建出来的本体进行评估.
1 相关研究
文献[4] 采用形式概念分析FCA 来进行本体构建,基于概念格的相关理论,但是构造过程中计算代价大,适用于小规模本体的构建研究.文献[5]以叙词表为依据,针对叙词表等级结构及其包含的概念间关系开展基于叙词表的本体构建方法研究,但是仅适合应用于医学领域.文献[6]提出基于模板识别的SSE_CMM领域本体自动构建技术.文献[7]基于维基百科等开放知识库进行本体构建,但由于这些开放知识库的异构性,关于此类本体构建方法还处于初级阶段.在概念抽取方面,文献[8]采用TF-IDF 公式进行相关性的判断,得到术语在领域的相关程度,筛选出相关性高的作为领域内概念.文献[9]采用LDA (Latent Dirichlet Allocation)主题模型将语料中最核心的概念提取出来.
2 领域本体自动构建
依据电力行业相关规定,结合电力监控系统的实际需求,本文采用了电力监控系统网络安全管理平台基础支撑功能规范以及中国知网中电力监控系统网络安全相关论文作为数据集.通过以下步骤对输入的文本数据进行处理,从而实现领域本体文件的自动构建:
第1 步.文本数据预处理,该过程将成段的文本进行分词并去除停用词;
第2 步.本体概念抽取,该过程将中文词汇转换为本体的基本元素——本体概念;
第3 步.本体概念间关系抽取,该过程抽取并建立本体概念间的相互关系以完成本体网络的构建.
图1为本文所建立的领域本体自动构建流程图,图解本文自动构建领域本体的整体过程.
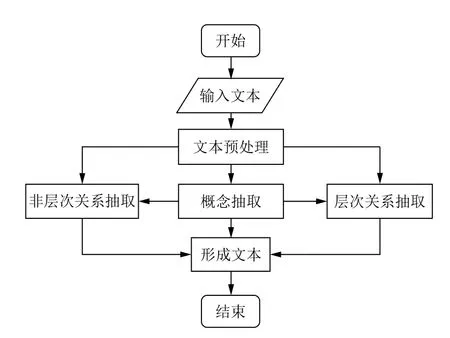
图1 领域本体自动构建流程图
下文将对各步骤中所涉及的设计细节进行详尽的介绍.
2.1 本体概念抽取
主要有3 种常用的概念抽取方法:基于规则的方法、基于统计的方法和规则与统计的混合方法[10].本文采用基于统计的方法,因为该方法易于扩展、不受具体领域语言学限制,易于实现.
首先,对文本数据进行预处理,采用开源的Jieba中文分词工具对文本进行分词,本文使用Jieba 分词时加载自行定义的电网安全监控词典来提高分词的效果.自定义的电网安全监控词典由搜狗细胞词库中电力词汇表、计算机词汇表以及网络工程词汇表等组成.
使用百度停用词表、哈工大停用词表、四川大学停用词表等中文停用词表组成的停用词表进行过滤.
目前,已有多种成熟的统计学方法可实现从文本数据中抽取本体概念.TF-IDF (Term Frequency-Inverse Document Frequency)是一种基于统计的方法,衡量一个词语在文档中的重要程度,词语的重要性与出现在文档中的次数成正比,与出现在语料库里的其他文档中的频率成反比.TextRank 算法是一种用于文本的基于图的排序算法,它的思想来源于PageRank 算法,把文本分为若干部分,建立图模型,使用投票机制对文本中的重要词汇进行排序.不同于TF-IDF、LDA 等方法,该算法是一种无监督的学习算法,不强烈依赖语料库,不需要对多篇文档进行学习训练,能够有效地处理本文所使用的文本资源.因此,本文采用TextRank 算法实现本体概念的抽取.在该算法中,单词的TextRank权重计算公式如下:

其中,d是一个人为设置的可调整参数,经过实验调整,本文将上式中的d设置为0.85.In(Vi)为每个单词i在单句内成线性关系排列的单词的集合,单词i的权重WS(Vi)取决于在i之前的各点j组成的(j,i)边的权重,以及j点到其他各边的权重之和.形如wji的权重值由计算两个不同的文本单元同时出现在同一个文本窗口中的比率而得,该权重的取值通常为2.初始化时,每个单词的权重统一初始为1,经过多次计算后所有权重整体达到一致性,分别以单个文档、单句为单位进行权重排名,取权重排名最高的单词为关键词.
现有的TextRank 算法主要基于统计学获取权重排名,在部分情况下,对文本资源中出现频次低却包含领域内关键概念的词汇抽取效果较差.实验表明,在应用中时常造成关键概念的遗漏,从而导致抽取准确度存在较大的提升空间.针对上述问题,改进TextRank算法将原本单一的权重排名队列扩大为3 个队列组成的多重权重排名队列.通过计算权重得到原始队列后,基于电网安全监控词典以及上下文语义关系,统计各词语与领域内的关键词汇的关联度.直接在词典中出现的关键词关联度置1,与词典中关键词产生语义关系的依照关系强弱置为[0.2,0.9)区间内的值.从队尾反向搜索,设定关联度阈值,将高关联的词汇认定为领域关键词升至上位队列.从队首正向搜索,将低关联词汇认定为高频次的非关键词汇降入下位队列.通过添加上述过程,能够有效地提升概念抽取的准确率,并在关系抽取过程之前过滤非关键词,从而提高了算法整体的运行效率.
2.2 本体概念间关系抽取
本体概念间关系主要划分为两种:层次关系与非层次关系.层次关系主要是概念之间的父子关系[11];非层次关系是指除了层次关系之外的关系,包括整体与部分之间的关系、属性关系等.所以先进行层次关系的抽取,再此基础上对非层次关系进行抽取.例如USB 是设备的子类,USB 和设备之间具有层次关系;设备的名称和设备的编号是设备的数据属性,设备与设备名称和设备编号具有非层次关系.
2.2.1 层次关系抽取
本体概念之间关系的抽取方法主要包括:基于模板的方法、基于关联规则的方法、基于词典的方法以及层次聚类的方法.聚类方法的思想在于根据事物的属性最小化类内距离,最大化类间距离,将一组具有异同特征的对象数据集依据特征的相似性分类为相似的对象类,同一分类下的对象具有相对的高度相似性,这一思想适用于本文中对本体概念进行层次关系的抽取过程.层次聚类根据不同的聚类策略又分为自顶向下的分裂方式和自底向上的凝聚方式,凝聚方式将每个概念作为一个簇,计算概念之间的相似度不断的进行合并,将簇不断扩大直到所有概念都合并为一个簇;而分裂的方式和他相反,初始情况将所有概念作为一簇,依据相似度将概念细分,不停迭代直到概念各成一簇为止.两种不同方式如下图所示.本文采用凝聚的层次聚类方法将1.1 小节得到的领域内概念向量化,根据向量之间的相似度对概念进行聚类,抽取它们之间的层次关系,方法的核心思路如图2所示意.

图2 基于凝聚的自底向上层次聚类方法示意图
使用空间向量模型,定义概念-文档矩阵,领域本体概念用W表示,特征项用t表示,其中t使用tf-idf权值表示.公式如下:
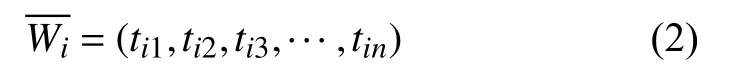
其中,表示第i个概念tij:

tfij表示抽取出的概念出现在文档集中的频率,n表示数据集中文档总数,ni表示出现概念i的文档数.按照上述公式构建向量空间模型,建立相似度矩阵步骤如下:
Step 2.计算两两概念之间的相似度:
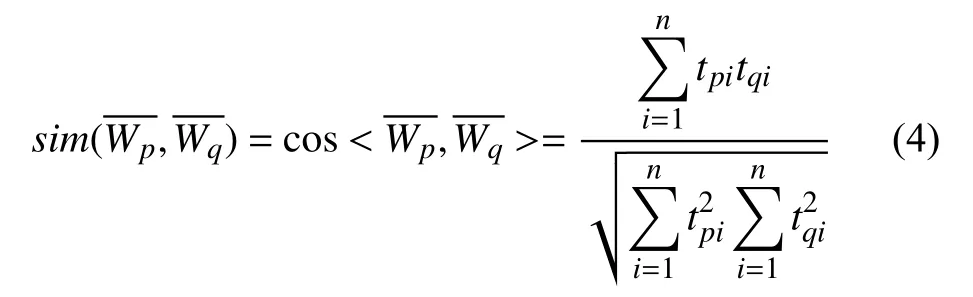
Step 3.构建概念相似度矩阵Sij,其定义如下:

簇间平均距离的定义如下:
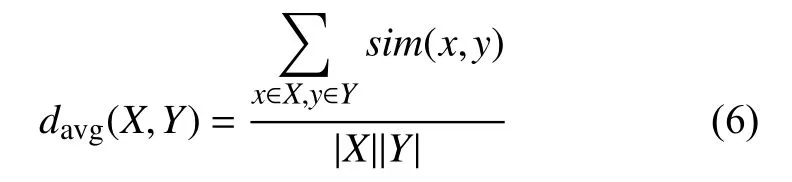
其中,X,Y表示两个簇,|X|和|Y|表示两个簇内元素的个数.
概念层次关系抽取步骤如下:
Step 1.将抽取出的每个概念单独作为一簇.
Step 2.计算两个簇之间的相似度即davg(X,Y).
Step 3.取相似度最大的两簇进行合并,若所有对象合并成一簇则跳转到Step 4,否则跳转至Step 2.
Step 4.结束.
在初始阶段,将每个领域本体概念作为一簇,根据相似度矩阵,逐一将相似度大于规定阈值threshold 的两簇合成一簇,直到簇内平均距离小于给定阈值为止.
聚类的方法可以将本体概念分为多个簇,但是簇内父概念和子概念的划分需要进一步定义,使用簇内平均相似度来划分.计算簇内概念两两之间的相似度,若某一个概念的簇内平均相似度越大,则说明此概念与其他概念联系广泛,更有可能为簇内的父概念.簇内平均相似度定义如下:

通过上述方法抽取的部分层次关系如图3所示.
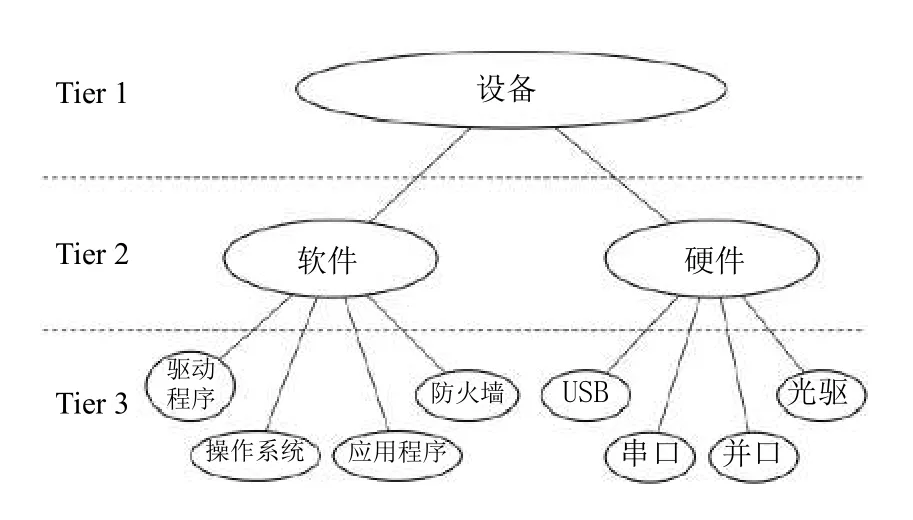
图3 部分层次关系示意图
2.2.2 本体概念非层次关系抽取
本体概念之间的非层次关系主要包括:部分与整体之间的关系、概念与属性之间的关系如对象属性和数据属性等.本文基于统计学方法进行构建,具有可移植性强,对语言依赖性低等优点.采用关联规则方法,该方法可发现事物之间的相互依存性和关联性.普通的关联规则方法只能得出概念之间确实存在非层次关系,但无法得出具体的关系名称,而概念之间的非层次关系可以用(主语,谓语,宾语)三元组表示,所以用动词可以作为概念之间的非层次关系改进关联规则.概念Wi和Wj之间具有关系Rt的关联强度可以用支持度和置信度来衡量.支持度Support表示两个概念出现在同一个句子里的概率,置信度Confidence表示在Wi出现的情况下Wj出现的概率,定义如下:
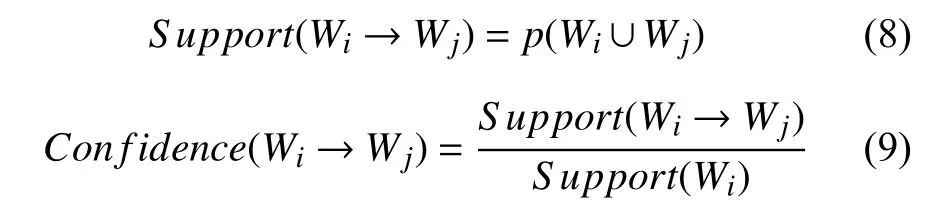
使用以下改进的关联规则进行非层次关系抽取的步骤如下:
Step 1.从抽取到的本体概念中选取概念Wi和Wj.
Step 2.根据上述公式计算Support(Wi→Wj)和Con fidence(Wi→Wj).
Step 3.给定支持度和置信度阈值min_Support和min_Confidence,如果S upport(Wi→Wj)>min_Support且Con fidence(Wi→Wj)>min_Confidence则概念Wi和Wj具有非层次关系,进行Step 4,否则转到Step 1.
Step 4.统计出现在Wi和Wj中的所有动词及其共现频率.如果概念与该动词的共现频率大于给定阈值,则把该动词定义为概念之间的非层次关系.
Step 5.验证所有动词之后结束.
以上方法抽取的部分非层次关系如表1所示.

表1 部分非层次关系
2.3 依据概念关系构建本体
通过上述两种本体概念间关系的抽取,完成概念间的分类关系、分层关系,以及跨层次的归属关系等关系的罗列,归纳得到本体构建所需的连接方式.根据领域概念和概念间的关系,可在Protégé工具软件中构建树状的领域本体.Protégé是由斯坦福大学开发的本体开发工具,该软件提供图形化界面可用于模拟概念类之间的关系以及属性.本文对于层次关系的抽取结果可以在Classes 选项卡定义,并且可以生成树状关系图,如图4所示.非层次关系抽取的结果主要包括对象属性和数据属性[12],可以在Protégé中的object properties选项卡和data properties 选项卡中完成定义.
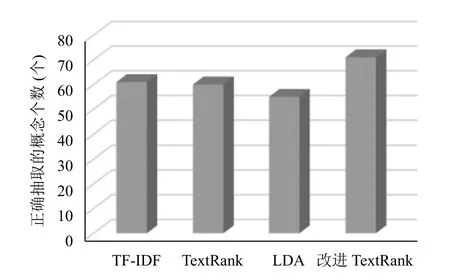
图4 本体概念抽取对比实验结果
3 实验验证与分析
3.1 实验环境
基于上文中提出的自动化构建方法,本文针对性地搭建了完整的实验环境以验证本文所提出方法的有效性.数据方面,采取了电力监控系统网络安全监测装置技术规范以及电力监控相关论文作为实验的文本数据源,与之相配套的开发环境及使用到的工具软件列举如表2所示.
3.2 实验结果
本体的评价一般可以从两个角度来进行:从应用的角度和从本体自身的角度.基于应用的角度是比较是否使用本体对应用效果的影响,依赖于具体的应用,不够直观,所以本文采用基于本体自身的评价.使用搜狗细胞词库中电力行业与计算机行业专业词汇表作为数据源,手工构建本体作为参照本体,其中包括87 个概念类,64 条数据属性以及49 条对象属性.为了提高实验评价的客观性在手工构建本体时使用《知网》(HowNet)词汇相似度计算工具进行概念以及概念之间关系的建立,并且增加适当的人工修正,提高评价的可信度.
表2 实验环境
(1) 本体概念抽取实验
在实验的本体概念抽取环节中,本文基于相同的文本数据源开展了多种本体概念抽取方法的对比实验,包括现有的TF-IDF 算法、TextRank 算法、LDA 主题模型,与本文提出的TextRank 改进算法进行横向对比,实验结果如图4所示.
通过实验对比可以看出,本文所提出的TextRank改进算法能够在相同的文本数据源中正确地抽取到更多的概念,本体概念的抽取能力有显著的提升.LDA 主题模型在短文本数据上进行概念抽取的效果不佳,而TF-IDF 算法以及一般的TextRank 算法本质上是依据词频,当领域核心概念出现频次较低时,容易产生遗漏,效果一般.
(2) 概念间层次关系抽取实验
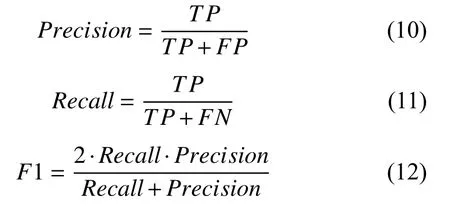
在层次关系抽取过程中,采用了准确率Precision、召回率Recall以及F1 值等3 种衡量指标来多角度地衡量关系抽取结果.准确率为正确抽取出的关系与实际抽取出的关系总数的比值,召回率为正确抽取出的关系与数据集中抽取出的所有关系总数的比值,F1 值为准确率与召回率的调和平均值.上述3 个衡量指标具体的计算方式如下:
在层次关系抽取过程中,选取不同的相似度阈值threshold 对上述衡量指标的影响如表3所示.
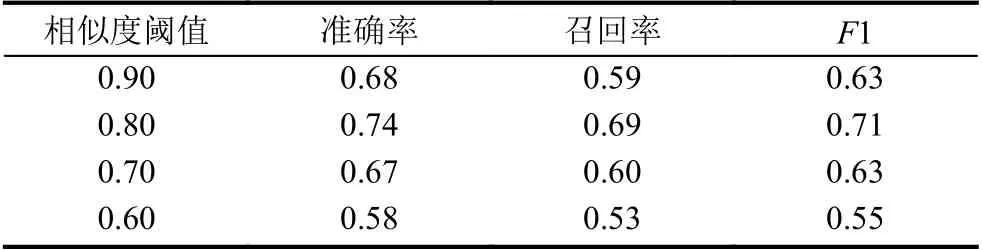
表3 Threshold 对实验结果的影响
将本文使用的层次聚类算法与文献[1]中使用的形式概念分析法FCA,以及一种基于Beta 分布的聚类算法BRT (Bayesian Rose Tree)进行对比,如图5所示.
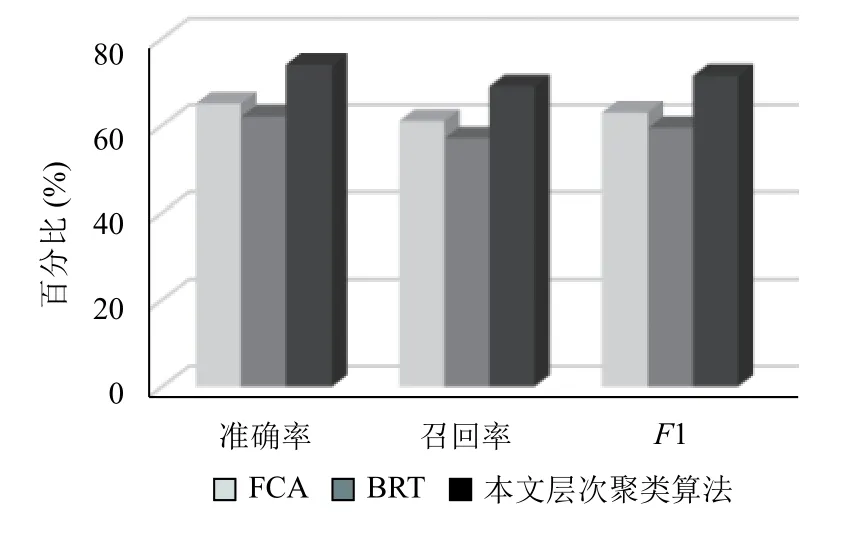
图5 层次关系抽取对比实验结果
使用形式概念分析法得到的准确率、召回率和F值分别是0.65、0.61 和0.63;BRT 聚类算法的准确率、召回率和F值分别是0.62、0.57、0.59;本文采用的层次聚类算法的准确率、召回率和F值分别是0.74、0.69 和0.71.可以看出本文使用的方法具有较好的抽取效果.原因如下:当句子中的概念存在并列关系时,层次聚类方法可以将这些概念归并到一个簇中,有效防止簇内概念被分开,而BRT 算法需要计算概念之间的合并概率,容易产生误差.
(3) 概念间非层次关系抽取实验
在非层次关系抽取中,使用式(8)和式(9)计算概念之间支持度和置信度,当支持度和置信度的阈值min_Support和min_Confidence取不同值时,对非层次关系结果的影响如表4所示,根据结果进行阈值选取.
使用词典的方法进行非关系抽取得到的非层次关系种类少,而传统的关联规则方法无法得到非层次关系的名称,所以上述方法无法进行实验对比.本文采用基于模板的方法,定义主语、谓语、宾语形式作为非层次关系的获取模板,与本文提出的改进关联规则方法进行实验对比,结果如图6所示.

表4 不同支持度与置信度阈值情况下的准确度(%)
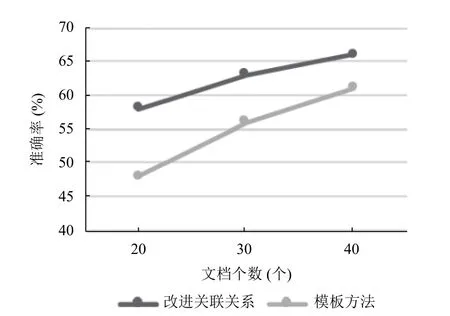
图6 非层次关系抽取对比实验结果
可以看出随着使用的文档数量的增加,两种方法的准确率均有所提高.基于模板的方法由于筛选条件简单,抽取到的非层次关系数量较多,但是准确率较低;本文提出的改进关联规则方法准确率较高.
通过统计结果可以看出,本文所提出的领域本体构建方法准确率、召回率达到实际应用中的可用性要求,能够为本体的自动化构建提供可靠的本体概念数据.自动化抽取得到本体概念后,依次进行了本体概念间层次关系、非层次关系的抽取.最终,依据概念、概念间的关系,在Protégé中构建了SafeAgent 本体.构建的本体(部分)如图7所示.
本文基于上述自动构建的电力监控安全本体开展进一步的实际应用,开发一套电网网络安全智能监控系统软件.该系统以SafeAgent 本体作为后台的逻辑内核,对电网监测设备采集的监测数据进行实时语义标注,后续处理中依据数据语义特征实施不同操作.在实际运行过程中,对比于早期由开发人员手动构建的领域本体,采用本文提出的方法进行自动化构建的本体具有可观的准确率、可靠性,可以实现对人工构建本体的初步替代应用.实验证明,在确保替代不影响系统整体性能的前提下,自动化构建本体方法可以切实有效地节省开发过程中的人力、物力,并且在大规模、多领域的语义网建设中保持高度的可扩展特性.
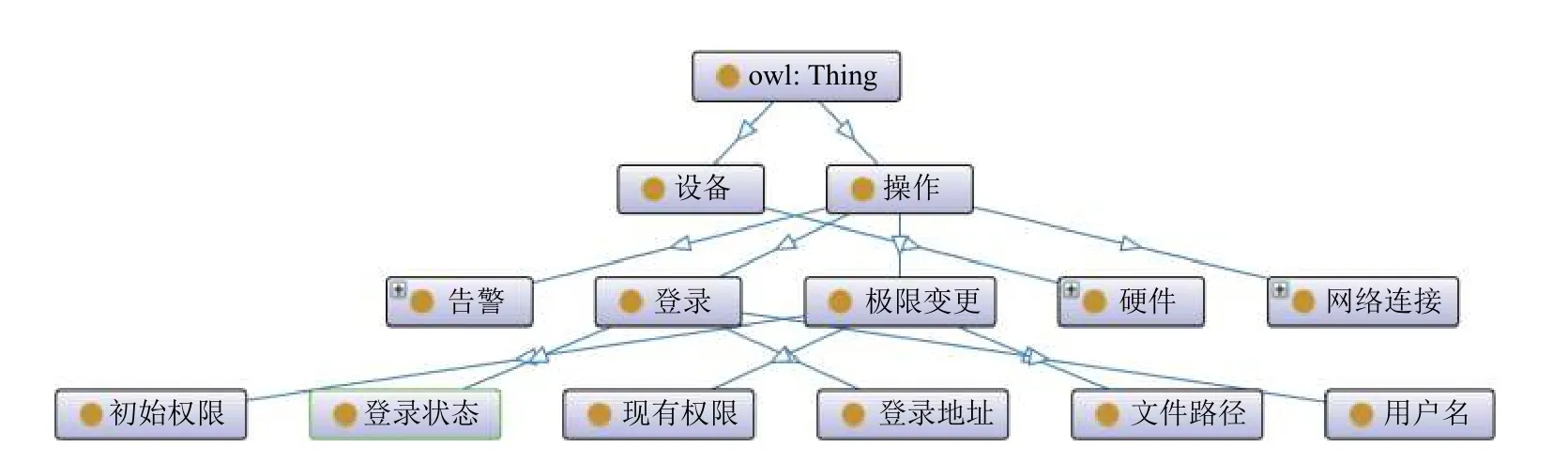
图7 电力监控安全本体(部分)
4 结束语
本文针对电力监控系统网络安全方面的实际需求,开展了领域本体的自动化构建研究,在现有的本体自动化构建方法基础之上,针对文本数据到领域本体概念的转化、本体概念间层次关系的抽取、非层次关系的抽取等多个必要步骤进行了改进,并初步实现了该领域本体的自动化构建过程.经实验验证,本文能够以较高的效率、准确率完成领域本体的自动化构建,避免了耗费大量人力、物力的领域本体的人工构建过程,从而实现对电力监控系统的网络安全行为进行快速的语义标注,为未来的电力监控系统中的物联网设备标准化、智能化奠定了基础.
