自然语言中词汇的信息获取:改进的skip-gram 模型*
2020-11-20朱娅霖
章 乐 朱娅霖
北京电子科技学院,北京市 100070
引言
词向量是自然语言处理的最基础的构成部分之一。 不管是机器翻译,还是在自然语言和视觉领域的交叉问题,如计算机图像标注等,只要涉及到具体的自然语言语句,在输入进模型之后,都会有一个从单个单词转化为词向量的过程。 最早关于词向量的研究工作可以追溯至Rumelhart,Hinton 和Williams 在Nature 中所发表的工作[1]。 在该问题的发展过程中,一个重要的解决方式是利用神经网络语言模型来训练词向量,如Mikolov 等人的工作[2]中所阐述的方法。 虽然这些神经网络模型得到的词向量的质量要超过传统的N-gram 模型,但神经网络模型存在过于复杂、训练时间过长等问题。 对于中等规模的数据集,训练时间常常需要按周来计算。
Mnih 等人在其的工作[3]中基于所谓Noise Contrastive Estimation (NCE)方法提出一个快速、简单的训练上述神经网络的方法。 后来Mikolov 等人提出了skip-gram 模型[4,5],相比较前者而言其更加简单。 和大多数其他的基于神经网络的模型相比较而言,skip-gram 模型不依赖于稠密矩阵乘法,因而训练速度大大加快。 该模型让在大规模的、无结构化的文本语料库上的训练成为可能。 对于超过一千亿个词规模的语料库,skip-gram 模型都可以在单个计算机上仅用一天的时间完成训练过程。 由于Mikolov 等人此项工作,skip-gram 模型以及与之有关的cbow 模型(Continuous Bag-of-Words)被人们都称为word2vec.
Pennington 等人提出了GloVe 模型[6],其主要是将两个词向量训练技术融合到一起:全局的矩阵分解方式,以及基于局部上下文窗口的方式。 Skip-gram 模型属于后一种方式。 GloVe 模型在词类比任务中取得了当时最好的结果,达到了75%的准确率。
上述所述的词向量生成技术大多都是在英文语料库上进行训练的。 在中文语料库上Niu等人基于HowNet 这一专家知识库[7]提出了包括SAT 在内的一系列模型[8],其中SAT 模型在其所给出的中文词类比任务中的准确率等衡量指标上都取得了目前最好的结果。 注意SAT 等模型利用了HowNet 这一人工知识,所以并不是完全基于无结构化的文本训练数据。
朱靖雯等人也基于HowNet 构造了Hownet-Graph[9]这一知识图谱形式,并进行了一系列的模型训练及对比实验。 其在词相似度任务上取得了不错的结果,但在Niu 等人所提及的词相似度测试数据集[8]下略弱于SAT 模型。 同时在中文词类比任务中,其仅在一项子任务的一个衡量指标中取得了不错的结果,总体上仍然远弱于SAT 模型。 陈洋等人提出一种基于HowNet 的词向量表示方法H-WRL[10],并在词相似度计算和其所提及的词义消歧任务中取得了很好的效果。 然而这些工作均基于人工标注的HowNet这一专家知识。
本文将基于word2vec 提出scaled word2vec模型。 Mikolov 等人提出的word2vec 模型中对所涉及的负采样[4],即Negative sampling (NEG)技术,仅仅从启发式以及实验结果等经验结论等方面进行了解释,也未能有其他文献给出NEG技术的理论上的分析。 本文将NEG 技术归约到NCE 方法的一种简化形式,从而阐明了NEG 背后的理论意义。 且基于两者之间的联系,本文提出scaled word2vec 模型,并阐明了如何利用上述的理论分析得到改进后的skip-gram 模型,这里称为scaled word2vec. 实验结果表明在中小规模的数据集上可以有如下结论:
1. Scaled word2vec 不论是在中文数据集还是在英文数据集上,生成的词向量质量都不会弱于原本的word2vec;
2. 在本文中所给出的一千兆中文数据集上,scaled word2vec 远优于SAT 模型,而SAT 模型此前取得了中文词类比任务的最好结果,且在模型训练时间方面,scaled word2vec 在实验所给出的运行环境中,其所花费的时间不足SAT 模型的22%。
1 Skip-gram 词向量模型简介
给定训练语料,即词的序列w1,...,wT,skipgram 模型的目标函数如下式所示:
其中c 为训练模型时所用的上下文窗口的大小。
和一般所用的利用词w 周围的上下文来预测该词的做法不同,skip-gram 模型是使用词w来预测其的上下文。 Skip-gram 模型的结构非常简单,词wt作为输入的单词,其通过log-linear 分类器来预测其他的、在其的上下文周边的词wt+j.因为距离wt较远的词和wt之间的关系要弱于距离wt较近的词和wt之间的关系,在实际代码实现中,超参数c 并不是一个固定的值。 实际实现中,对于每一个wt都将先随机生成一个0 ~c -1 之间的整数b,上下文窗口的大小被修改为左边c - b 个词,以及右边c - b 个词。
Skip-gram 模型还采用另一种被称为下采样(subsampling)的技术。 该处理技术是针对于那些出现非常频繁的词。 比如英文中经常出现的“the”,“a”等。 这些单词几乎在语料中的每句话中都出现, 但包含的信息却非常的少。“Paris”在“France”周边出现时所表达出来的信息量远多于在“France”周边的词“the”。 这和中文中的停用词很类似。 如中文中的“的”,这个词占中文语料的总词频的比例非常高,但却几乎没有什么用处。 在skip-gram 模型中,下采样将对词的序列中的每个词wi, 以如下的概率被保留其:
其中z(wi) 是词wi出现的频度,即wi出现的次数除以语料库的大小,超参数t 是一个预先选择的阈值。 对于小规模的数据集,t 一般可选择为10-4;对于大规模的数据集,该值可选择为10-5. 如下对上述保留wi的概率给出一个简单的分析。 考虑z(wi) 为多少时,词wi将会被下采样。
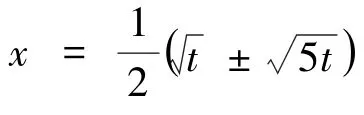
如前所述,Skip-gram 模型还使用了NEG 技术来简化其的目标函数中的Pr(wt+j| wt) 的计算。 其的细节将在下一节中详述。 本文中提出的改进方法也是针对于该NEG 技术。
2 改进算法
本节中先回顾skip-gram 模型中所使用的NEG 方法。 NEG 方法可以理解为NCE 方法的一种简化形式,本节中也将简要介绍后者的主要计算形式。 在本节的最后基于NEG 和NCE 两者之间的关系,将提出如何对NEG 进行修改来获得其的改进计算方法。
在基本的skip-gram 模型中计算Pr(wO| wI)时若不考虑计算的开销,采取的将是softmax 的计算形式,即:
其中v′wO和vwI分别为w 的“输出”、“输入”向量表示。
对于小规模的词汇表,如词汇量W 在1000及以内,上述这样计算softmax 的方式是可行的。但对于大规模的语料库所对应的词汇表, W 可达到105~107,而上述计算softmax 的方式每一次的计算开销都和W 成线性关系。 因此这样直接计算softmax 的方法显然对于一般的、规模较大的语料库是不可行的。 该问题的解决有一些方法:层次性softamx、NEG 和NCE 等。 其中层次性softmax 将W 个词表示为一棵二分树的叶子结点,这样每个词都对应一条从根到叶子的路径。 概率Pr(wO| wI) 的值可理解为对应该路径的随机游走所发生的可能性。
层次性softmax 比起NEG、NCE 要复杂很多。 同时在skip-gram 模型上目前最好的结果也是基于NEG 的,因此这里不再对层次性softmax过多赘述,但不管是哪一种方法,都是为了解决上述softmax 计算过于困难的事实。
2.1 NEG 方法
在skip-gram 模型的目标函数中, logPr(wO| wI) 将会被替换为如下的形式:
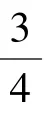
2.2 NCE 方法
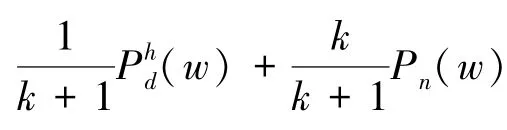
类似的其来自负样本的概率为:
在Mnih 等人的工作[3]中,ch被选择为了固定值0,也就是说归一化的因子exp(ch) 为0. 这本质上是由于上下文h 的定义略过复杂,如定义为w 在文本中的出现位置之前的m 个词。 这样的话,上下文的个数将会很多,无法有一个确切上界,因为不同的h 带来的参数ch将会过多而无法都作为模型的参数被学习。 无论如何在ch都为0 的情况下,参数θ = θ0将包括模型最终所能学习到的词向量。
2.3 NEG 与NCE 的联系及改进的NEG 方法
从NCE 的优化目标Jh(θ) 出发,这里将逐步建立其和NEG 形式之间的联系。 首先进行如下的等价变换:
其中σ(x) 也为sigmoid 函数。
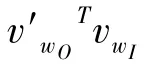
下一节中将用实验表明这一改变不仅具有理论上的意义,且在实际训练中也确实能生成质量更优的词向量模型。
3 实验结果
在衡量词向量的质量时将考虑训练出来的词向量在词类比任务中的表现。 该词类比任务是词向量技术公认的衡量方法之一,具有很强的代表性。 如下先对这个任务进行简要的阐述。
3.1 衡量方法:词类比任务
词类比任务首次在Mikolov 等人的工作[5]中被提出。 具体来说,经过训练后的模型需要回答类似这样的问题:和vector(“biggest”) -vector(“big”) + vector(“small”)最相似的词向量应该对应于哪个词? 毫无疑问若词向量能够准确反映词与词之间的联系,上述问题的答案应该是“smallest”。 除了这种上述这种语法上的代数关系,词类比任务还考虑这样的问题,如vector(“France”) - vector(“Paris”) + vector(“Germany”),该问题的答案应该是“Berlin”。也就是说词类比任务中既有考虑语法上的代数关系,还有考虑语义上的代数关系。 在中文词类比任务中也类似的问题,如vector(“侄子”) -vector(“侄女”) + vector(“孙子”),回答应为“孙女”;vector(“南京”) - vector(“江苏”) +vector(“成都”),回答应为“四川”。 在中英文词类比任务中,都会考虑有多少问题被回答正确。这样分别针对于语法问题和语义问题,将会有语法准确率和语义准确率这样的衡量指标,分别表示这两类问题中有多少问题被正确回答。 在这两者的基础上,总的准确率一般作为不同模型训练的词向量质量的最终衡量指标。
同时在中文任务中,还会考虑一个被称为rank 的衡量指标。 考虑一个词类比任务中某条测试数据对(w1,w2,w3,w4).模型将计算如下的w*,该w*具体可以这样计算:minwcos(w2-w1+ w3,w).若w*=w4,则模型回答正确。 同时不管模型回答是否正确,都将计算w4在所有w 按cos(w2- w1+ w3,w) 排序后中的排名。 所谓的rank 衡量指标,则是所有排名的平均值。 在差不多相等的准确率的情况下,若衡量指标rank过大,则表明相应的模型不够稳定,即对某些测试数据对能回答正确;对另一些测试数据对则回答得非常错误,正确答案在余弦相似度中的排名非常得靠后。
英文词向量任务中的词类比任务[5]包括8,869 个语义问题,以及10,675 个语法问题,总共是19,544 个词类比问题。 中文词向量任务中词类比任务包括1,124 个问题,并分为了Captial、City 和Family 这3 个类别。 中文词向量任务的有关的具体细节可参考Niu 等人的工作[8]。
3.2 中英文训练语料库的选择及模型训练环境
首先考虑英文语料库,这里选取text8 语料①http:/ /mattmahoney.net/dc/text8.zip,其大小约为100 兆,包括约17,000 个词。因英文词向量的生成不是本文所着重的重点,这里只考虑了这个规模大小的语料库,以验证修改后的NEG 是否优于原本的NEG 的形式。
中文语料库方面,本文中先考虑一个大小约为1 千兆的语料库。 该语料库是由中文文本分类数据集THUCNews②http:/ /thuctc.thunlp.org/得到。 原本的THUCNews包含74 万篇新闻文档,大小约为2.19 千兆。 本文中为节省训练时间,以及只提供词向量的质量的定性验证,从原本的THUCNews 中按类别随机抽取了一部分内容,并采用了THULAC③https:/ /github.com/thunlp/THULAC-Python进行了中文分词,最终形成的语料库的大小为上述所说的1 千兆。
关于模型训练环境方面,实验环境为16 千兆内存,16 核,处理器为Intel(R) Xeon(R)Bronze 3106 CPU @ 1.70GHz.
如下实验中将采用原本的NEG 方法的词向量模型称为word2vec,将改进后的NEG 方法的词向量模型称为scaled word2vec,将目前生成中文词向量质量最好的模型称为SAT.
3.3 中英文训练语料库的选择及模型训练环境
经过text8 语料库训练后,相关的实验结果如表1. 从中可以看出,改进后的NEG 方法对应的scaled word2vec,不管是在语义准确率上还是在语法准确率上都是优于原本的word2vec. 注意这里的准确率只是在text8 这样的小规模数据集下的准确率。 在大规模数据集下,如cbow 模型在特定的超参数设置下准确率可达到78%④https:/ /github.com/tmikolov/word2vec,而cbow 模型一般是弱于skip-gram 模型,无论数据集规模的大小。 注意word2vec 模型一般默认表示skip-gram 模型。 表1 的实验表明了在text8这样非常具有代表性和公开的数据集上,所提出的scaled word2vec 并没降低word2vec 的表现,反而带来质量更优的词向量表示。
在text8 语料库上训练时,相关的超参数设置上scaled word2vec 和word2vec 完全一致。 一些关键超参数的设置为:初始学习率为0.025,词向量的长度为200,上下文窗口大小c 为向左、向右均8 个词,NEG 中超参数k 为25,下采样超参数t 为1e-4,迭代次数为15. 这些参数的设置可参考word2vec 项目的在text8 上的默认设置4,后者针对于所谓的cbow 模型,初始学习率0.025 为代码为skip-gram 模式时的默认值,线程数因上述所提及运行环境所限制而选择为了16.
针对于中文语料库, 这里先考虑在THUCNews 中抽取的1 千兆的语料库。 实验结果如表2. 其中SAT 模型的训练时间长达9.4 个小时,而scaled word2vec 在相同的运行环境下训练时间不足2 个小时。 在中文数据集上的超参数设置,为了实验结果的公平起见,采取了和SAT 模型一样的设置。
超参数的设置和在text8 中训练的主要区别有:迭代次数为3。 线程数因运行环境的限制修改为了16 个线程。 从表2 中可以看出,从Total accuracy/rank 这一综合指标来看,无论是准确率,还是之前所述的rank,模型scaled word2vec都取得了3 个模型中最好的结果。 模型SAT 原本的项目中线程数为20,但这个对最后的影响结果不大。 多个线程意味着多个训练线程在同时进行,其会影响训练时间的长短。 对于16 核的运行环境,选择16 个线程可避免线程之间不必要的调度,因此这里的选择是合理的。

表1 在text8 上训练之后的word2vec 和scaled word2vec 的结果比较

表2 在THUCNews 的1 千兆的语料库上的各模型的结果比较
5 结语
本文中基于NEG 和NCE 之间的联系,提出了改进的skip-gram 模型。 这里的工作中因为计算资源的限制,未能在更大规模的(如20 多千兆的语料库等)的数据集上进行对比实验。 因提出的scaled word2vec 较word2vec 改动较小,可以很好地和现有的word2vec 等工具包融合在一起。 同时对比SAT 模型,scaled word2vec 较少的计算资源开销让其在大规模的语料上的训练成为可能,且无需人工知识的介入,所以也适合对其他语言的词向量的生成任务。
