人体行为识别特征提取方法综述
2020-11-17张会珍刘云麟任伟建1b刘欣瑜
张会珍, 刘云麟, 任伟建,1b, 刘欣瑜
(1.东北石油大学a.电气信息工程学院; b.黑龙江省网络化与智能控制重点实验室, 黑龙江大庆163318;2.中国石化销售股份有限公司上海石油分公司 信息管理处, 上海200002)
0 引 言
多媒体信息(尤其是视觉信息)在如今网络和电子视频设备快速发展并普及的时代, 不断渗透到人类生活的各个领域, 已逐渐成为信息交互的主要载体。 计算机视觉应运而生, 目的是希望计算机获得与人相似的视觉感知能力, 其最吸引人的一面是能从图像或视频中获取外部信息的描述。 由于大多数视频记录的都是作为组成社会活动主要部分的人类的活动, 由此衍生出了行为识别这个备受重视的研究方向。该方向在例如智能视频监控[1]、 医疗诊断监护[2]、 智能人机交互[3]和身份识别等[4]领域中具有广泛的应用。 基于视觉的人体行为识别主要是为了解决原始图像和图像序列数据的处理分析问题, 这些图像通常是计算机通过传感器(摄像机)采集的, 同时该方法还能学习并理解其中人的动作和行为[5]。 人类行为识别涵盖了计算机视觉中的许多研究课题, 包括视频中的人体检测、 姿态估计、 跟踪以及对时间序列数据的分析和理解。 识别过程主要分为以下3 部分[6]: 1) 在视频帧中检测运动信息并提取底层特征;2) 对行为模式进行建模研究; 3) 建立动作行为类别与底层视觉特征等高层语义信息间的对应关系。近年来, 该领域得到了广泛的关注与研究, 例如IJCV( International Journal of Computer Vision)、 CVIU(Computer Vision and Image Understanding)、 PAMI(Pattern Analysis and Machine Intelligence)等国际知名期刊以及ICCV( IEEE International Conference on Computer Vision)、 CVPRI ( EEE Conference on Computer Vision and Pattern Recognition)和ECCV(European Conference on Computer Vision)等重要学术会议都将人类行为识别与理解作为一个重要的研究课题[6]。
随着人体行为识别领域的发展和研究任务的深入, 从最初在受限条件下只能识别简单的单体动作到如今在真实自然场景下的复杂群体行为识别, 无论对信息采集设备或算法能力上都提出了严峻的挑战。而特征提取作为行为识别过程的重要环节, 提取结果的好坏在很大程度上影响着行为识别效果的实时性与准确性。 特征提取作为计算机视觉和机器学习领域中的经典问题, 与图像空间中的特征提取不同, 视频中人类动作的特征表示不仅描述了人在图像空间中的形态, 而且必须将人的外貌以及姿态变化提取出来, 将特征提取问题从二维空间扩展到三维时空, 大大增加了行为方式表达及后续识别任务的复杂程度, 与此同时也为视觉研究者在解决思想和技术方法方面拓宽了思路[4,7]。 人体特征是指从视频序列底层提取出可以对目标行为进行表征的信息[8], 比如颜色、 轮廓、 纹理、 深度, 或是人体运动方向、 速度、轨迹以及时空兴趣点和时空上下文等。
笔者旨在从不同类型行为识别特征的角度、 常用的行为数据集等方面论述目前该领域的研究现状,探讨研究难点并阐述未来可能的发展方向。
1 特征提取
特征提取旨在从底层数据抽取部分具有代表性的特征信息对人体动作进行表征。 特征提取的好坏直接影响识别方法的精确度和鲁棒性, 从原始视频序列中提取具有较强表征能力的行为特征一直是行为识别领域的一个研究难点。
1.1 外观形状特征
外观形状特征一般包括运动物体的大小、 侧影轮廓、 颜色、 紧密度和深度等, 这些特征在行为识别中由于能较好地表征人体行为细节, 因此被广泛采用。
Bobick 等[9]最早采用轮廓描述人体的运动信息, 在其方法中, 首先采用背景减法, 然后将一系列的背景减法块聚合到单个静态图像中,并提出了两种聚合方法—— 第1 种方法对序列中的所有图像给予同等的权重, 从而产生了一种称为 “运动能量图像”(MEI: Motion Energy Image)的表示, 其可以指示运动在哪些部位发生过; 第2 种方法对序列中的图像给出衰减的权重, 给新帧赋予更高的权重、 旧帧赋予较低的权重, 被称为“动态历史图像”(MHI: Motion History Image), 其可以表征人体在一个动作过程中最近的动作情况。 Sahoo 等[10]提出了一种基于MHI 的兴趣点细化算法去除噪声兴趣点, 将方向梯度直方图和光流直方图技术从空间扩展到时空域保存时间信息。 Khan 等[11]针对动作识别的表示通常只使用形状特征而忽略颜色特征的问题, 受到颜色在图像分类和目标检测方面的成功启发, 研究了颜色在静态图像中用于动作分类和检测的潜力, 并对颜色描述符和动作识别的融合方法进行了综合评价, 实验表明, 颜色和形状信息的后期融合在动作识别方面优于其他方法, 同时给出不同的颜色形状融合方法会产生互补的信息, 并将其进行组合, 从而获得先进的动作分类性能。 Elmezain 等[12]提出了一种基于亮度不变颜色和自适应高斯混合的背景建模方法, 能自适应地建立和更新具有颜色不变性假设的阴影, 用于复杂场景中前景目标与背景的识别, 该方法在不牺牲实时性能的前提下, 比现有的先进技术更有效。
Liang 等[13]提出了一种基于深度的局部描述子和基于位置约束的仿射子空间编码的三维动作识别方法, 实现了再深度图像中对人体行为进行识别。 Maity 等[14]提出了基于剪影图像序列的人体行为识别方法, 首先采用尺度平移归一化和轮廓畸变去除, 用于提取新引入的活动区域能量特征( AREF: Active Region Energy Features)和轨迹分析; 其次, 使用层次结构进行分类。 一个活动区域是两个连续轮廓中的变化区域, 用以描述完成的动作; 最后利用包含活动区域能量的有功区域能量像(AREI: Active Region Energy Image)估计AREF, 其值越高, 表示该区域在剪影序列中越活跃(变化), 即该区域被更多地使用(活动)完成动作, 提取的特征更加具有鲁棒性和尺度不变性。 Kushwaha 等[15]针对以往基于轮廓的人类活动识别工作大多是从单一视角进行识别, 忽略了视角不变性的问题, 提出了一种基于轮廓的姿态特征和基于均匀旋转的局部二值模式的视图不变活动识别方法。 该框架由3 个连续的模块组成: 首先通过背景减法检测和定位人; 然后将从轮廓中提取基于尺度不变轮廓的位姿特征和均匀旋转不变局部二值模式(LBP: Local Binary Pattern)结合; 最后使用多类支持向量机(SVM: Support Vector Machine)分类器对人的活动进行分类。 Vishwakarma 等[16]旨在利用人体轮廓的关键姿态, 构造一种新的分类模型, 为视频序列中的人体活动识别提供一种新的方法。 将人体轮廓的时空形状变化通过轮廓的关键姿势划分成固定数量的网格和单元表示, 从而实现无噪声的描述。 Cai 等[17]提出利用Procrustes 分析和局部保留投影(LPP:Locality Preserving Projection)技术从剪影图像中提取姿态特征, 然后将所提取的特征能保留人体姿态的判别形状信息和局部流形结构, 且不受平移、 旋转和缩放的影响, 最后在提取姿态特征后, 利用基于费舍尔向量编码(FV: Fisher Vector)和多类支持向量机的识别框架对人体动作进行分类。 Qian 等[18]提出了变速度下的虚拟粒子随机游动理论。 在该理论的指导下, 利用九点有限差分法对二维泊松方程解进行离散, 并在基于人体轮廓的时空运动累积图像上进行定义, 得到了用于动作描述的深度轮廓图像, 成功地将人类行为的时空演化信息包含在深度轮廓图像中。 此外, 与直接使用三维时空描述符相比, 将三维人体动作投影到二维图像描述符中, 可大大降低相应识别算法的计算成本。
外观形状特征是全局特征的一类, 这类特征包含了丰富的人体信息, 因此它是有效的, 要获取这类特征必须要先将人体所在区域事先定位。 实现这个目的的方法有很多, 例如背景减法、 帧间差分法或目标跟踪算法等, 因此其解决了视觉监控系统中人体行为识别的问题。 然而其又十分依赖底层视觉的处理, 比如精确的前景提取和跟踪, 这本身也是计算机视觉中的难点。 尤其是在场景较为复杂和视频采集设备运动的情况下, 无法获得准确的人体外观, 并且随着计算机设备与深度学习领域的发展, 研究者们将研究的重点更倾向于真实场景中, 因此单一的外观形状特征并不适用。
1.2 运动特征
目前被广泛使用的运动特征包括轨迹、 方向、 速度、 加速度和光流特征等。 使用这些特征提取方法的优点是所提取的特征信息较为完整, 且完全不考虑人体结构的任何形状信息, 对视频中的人体行为是一种良好的表征方式。 Wang 等[19]提出了一种基于密集轨迹的人体行为识别方法, 通过对各个视频帧不同空间尺度进行密集采样, 对采样获得的兴趣点进行帧间追踪得到密集轨迹, 并结合灰度图像方向梯度直方图(HOG: Histogram of Oriented Gradient)、 光流直方图(HOF: Optical Flow Histogram)、 运动边界直方图(MBH: Motion Boundary Histogram)3 种描述子组成特征描述符对人体信息进行表征, 最后通过使用SVM 分类器在不同行为数据集上进行分类, 可以获得良好的的分类精度。 但提取基于轨迹的采样方法考虑到了人体运动的时间信息, 因其沿着轨迹密集采样, 所以采样得到的兴趣点数目较多, 算法运行效率无法达到预期, 而例如背景的细小变化也对识别结果有一定的影响。 为了解决这个问题,Wang 等[20]提出改进方法, 其中最明显也是最重要的改进是引入了消除背景光流的方法( 估计相机运动), 目的是去除无意义背景光流对识别造成的干扰, 识别效果得到显著提升。 受此启发, Lu 等[21]提出了一种新型多尺度轨迹池三维卷积描述符(MTC3D: 3D Multi-scale Trajectory Convolution Descriptor), 即从输入视频中计算多尺度密集轨迹, 并在三维卷积神经网络(CNN: Convolutional Neural Network)的特征图上进行轨迹池化, 提出的描述符具有两个优点: 3D CNN 具有从视频中提取高级语义信息的能力, 多尺度轨迹池方法巧妙地利用了视频的时间信息。 Carmona 等[22]通过改进的稠密轨迹(IDTs: Improved Dense trajectories)提高性能, 增加新的基于时态模板的特征, 把一个视频序列看作一个三阶张量, 并计算3 个不同的投影构造这些模板, 通过使用几个函数投影视频序列中的数据及求和池的方式将它们组合。
Yi 等[23]提出了一种基于显著性检测和低秩矩阵恢复的突出前景轨迹提取方法, 将密集轨迹划分为显著轨迹和非显著轨迹。 突出轨迹与感兴趣的前景区域近似对应, 而非突出子集主要由背景轨迹组成。此外, 根据背景运动的低秩性, 如果视频具有背景运动, 则通过低秩矩阵恢复方法在隐式轨迹子集上进一步构造背景轨迹子空间。 然后可以减去突出子集中可能的背景轨迹。 最后, 采用特征词袋模型或Fisher 向量法对得到的突出前景轨迹特征进行编码和动作分类。
轨迹描述的是目标在空间中的运动轨迹, 因此想要计算出目标的速度、 方向等运动特征变得十分容易。 Hu 等[24]结合人的空间位置、 运动方向和速度等不同特征, 提出了一种三维场景的轨迹聚类算法和一种室内感兴趣区域(ROI)提取方法, 并利用动态时间规整(DTW)方法研究了异常动作序列。 Fan 等[25]提出了一组动力学特征描述人体每个关节的速度、 加速度、 角速度、 角加速度、 动能、 势能和总能量。Malawski 等[26]在相似运动模式的分析中使用动力学, 提出了基于加速度测量数据、 骨骼关节特征和深度图的信息运动描述符, 并展示了它们对运动动力学建模的潜力。
由于轨迹特征在对目标进行长时间跟踪过程中可能发生轨迹漂移的情况, 特别是在复杂的场景下更易出错, 因此, 研究者们将目光放在光流特征上。 光流(Optical Flow)计算的是像素的瞬时变化, 当物体运动模式发生改变时, 所对应的像素点亦会发生变化, 因此光流法被广泛应用于目标检测跟踪领域中。Shi 等[27]提出了一种基于多尺度局部模型的动作识别系统, 并使用一种保持不连续的光流算法提高识别性能; Kinoshita 等[28]基于旋转观测器的一维光流跟踪方法, 利用运动物体的像素计算一维光流, 以消除静止环境物体的视运动, 也较好地实现了复杂背景下的人体跟踪, 但这会引入运动噪声。 为了解决这个问题, Efros 等[29]提出了模糊光流特征(Blurred Optical Flow)对运动目标进行表征,该方法仅通过提取以人体为中心点的光流特性即可实现降低噪声的目的。
综上所述, 针对表观特征在中远距离视觉和能见度低条件下难以很好地对运动进行表征的问题,基于运动特征的行为识别取得了不错的效果。 但大多数运动特征尤其是光流的计算方法非常复杂, 抗噪性能差, 且需要满足一些基本假设条件从而难以进行实际应用, 因而使该方面的研究较为困难。 目前,因外观形状特征和运动特征各有优势, 可以相互补充, 人们更倾向于融合运动特征与外观形状特征共同对人体行为进行表征。
1.3 时空特征
在行为表达过程中, 物体的姿态孕育了空间信息, 而运动信息则反映在时间空间中, 因此, 时间的动态信息对于行为表达至关重要[8]。 时空特征将一段视频视作时间轴上的级联, 通过提取如时空兴趣点、 时空上下文信息、 时空立方体等特征, 对人体行为进行表述。
由于时空兴趣点特征很容易被提取, 因此该特征在行为识别领域被广发使用, 兴趣点的求解思想[30]是将视频看作三维函数, 建立一个映射函数, 将三维空间的数据经过该函数计算映射到一维空间, 对此一维空间的局部极大值进行求解, 得到的各个极值点即是时空兴趣点。 比较经典的求取时空兴趣点的算法有Harris 角点算法, Susan 算法和(SIFT: Scale-Invariant Feature Transform)算法以及以其为基础的一些改进算法等。 Maity 等[31]提出了一种新的时空人体部位运动( STBPM: Space and Time Body Parts Movement)特征, 其特性的设计目的是累积多个主体部分的活动签名, 以完成任何操作, 并将其应用于人体行为识别。 纪亮亮等[32]为了研究真实条件下的人体行为识别, 建立一个基于深度图像摄像机的动态多视角人体行为数据库, 该数据库收集了20 人的600 多个行为视频, 约60 万帧彩色图像和深度图像,利用(CRFasRNN: Conditional Random Fields as Recurrent Neural Networks)图片分割技术将人像进行分割并分别提取Harris3D 特征, 利用隐马尔可夫模型对动态视角下的人体行为进行识别。 Wei 等[33]为了充分利用视频序列的逻辑结构, 同时提取方向梯度的三维直方图、 基于频域滤波(FDF: Frequency Domain filtering)的全局描述符和基于时空兴趣点(STIP: Space-Time Interest Point)的局部描述符特征对人体行为进行表征。
基于时空兴趣点的方法在目前行为识别领域中取得了良好的效果, 但是这类方法几乎都是描述单一的兴趣点特征而忽略了视频序列中大量时间和空间信息, 因此研究人员希望通过引入上下文特征弥补这个不足。 时空上下文特征是对事物时间上的联系进行描述, 这种联系主要发生在视频相邻帧之间, 对以人体为主的运动中心这种时间联系更加明显。 Yuan 等[34]针对具有长距离运动或多个身体部位与人交互的高层次人类活动中低层次的特征具有局限性, 提出一个计算中层特征并考虑其上下文信息的框架解决这一问题。 首先采用一组中层构件(它们在空间和时间域中具有一致的结构和运动)表示人类活动; 然后引入时空上下文内核(STCK: Space-Time Context Kernel), 其不仅捕获了特征的局部属性, 而且考虑了特征的时空上下文信息。 Chen 等[35]在改进的运动尺度特征变换(iMoSIFT: Improved Motion Scale-Inviriant Feature Transform )的基础上, 考虑了iMoSIFT 兴趣点之间的时空结构关系, 并采用局部加权的上下文描述符进行编码, 然后对每个视频片段使用双层弓表示。 时空立方体特征是将提取到的时空兴趣点特征映射到一个三维立方体上进行表征的方法, Seo 等[36-37]利用时空局部回归核(3D LSKs: 3D Space-Time Local Regression Kernels)对视频图像中人体行为进行表征, 通过进行时空立方体的匹配完成行为识别。 Vieira等[38]提出了一种利用深度图序列进行三维动作识别的新视觉表示方法—— 时空占用模式(STOP: Space Time Occupation Pattern), 其不仅捕获了特征的局部属性, 而且考虑了特征的时空上下文信息, 同时具有优秀的灵活性适应动作内部变化, 对解决深度图像序列中的遮挡和噪声问题取得了良好的效果并且降低了行为特征的类内差。 Nazir 等[39]提出了一种动态时空词袋包(D-STBoE)模型, 用于人类动作识别, 其表达式是基于视觉词的时空立方体的密度形成以处理类间的变化, 通过使用类特定的视觉词表示生成视觉表达式。
总之, 基于时空特征的行为识别方法在一定程度上解决了外观形状特征和运动特征存在的视觉变化和部分遮挡等较为敏感的问题, 并且时空特征属于局部特征, 因此不需要精确的人体定位和跟踪。 另外还可以通过引入上下文信息提升局部特征的表征能力, 从而引起研究者广泛兴趣。 但由于时空局部特征点本身包含大量的噪声, 从而导致特征的表征能力有限, 同时, 对于复杂的真实场景, 以及如今数据量的激增所导致的巨大的行为类内差, 使得行为表达也受到限制。 因此, 如何解决这些问题, 是未来该领域研究学者们的攻克难点与方向。
1.4 特征融合
近年来随着硬件设备的不断提升, 深度学习领域的快速发展, 采取特征融合的方法应用到行为识别中的优势也越来越明显。 研究者们通过使用特征融合的方法以获得鲁棒性更好的行为特征表征能力, 从而达到将不同种类的特征融合, 减少信息冗余, 提高识别精度和效率的目的。
多特征融合技术在人体动作识别领域得到广泛应用, Huan 等[40]提出了一种基于方向兴趣区域运动直方图的融合特征和基于亲和传播(AP: Affinity Propagation)聚类的词袋模型(BOWs: Bag of Words)的人体动作识别方法, HOIRM(Histogram of Interest Region Motion)是介于局部特征和全局特征之间的一个中层特征, 使用累积直方图将HOIRM 与3D HOG 和3D HOF 局部特征融合, 该方法进一步提高了局部特征对复杂场景中摄像机视角和距离变化的鲁棒性, 从而提高了动作识别的正确率。 Wang 等[41]使用骨架和骨架节点周围的深度点学习由不同节点特征构成的集成模型表示每个动作并捕获类内方差, 然后, 通过多核学习对不同的特征进行融合和分类。 Majd 等[42]将光流特征和时空特征进行融合。 Gao 等[43]提出多特征映射和字典学习模型 ( MMDLM: Multi-feature Mapping Dictionary Learning Model ),首先提取深度图像序列的不同特征, 然后使用MMDLM 旨在深入发现这些不同特征之间的关系, 同时学习两个字典和一个特征映射函数; 而且, 这些词典可以充分表征不同特征的结构信息, 而特征映射功能是一个正则化项, 可以揭示这两个特征之间的内在联系, 在大规模数据集中取得了较好的效果。Azher 等[44]利用深层卷积网络提取深度空间特征, 采用基于韦伯定律的体积局部梯度三元模式提取时空特征, 利用梯度运算考虑形状信息, 将这两个提取的特征连接后提供给支持向量机进行分类。 Yao 等[45]提出了一种基于时空双特征的多特征融合算法提取有用的视觉信息进行识别, 同时将压缩的时空视频表示方法引入到词包表示中, 在两个流行数据集上的实验显示了有效的性能。 Zhong 等[46]通过对密集轨迹上的时空网格进行分析, 生成HOG 和HOF 描述人体物体的外观和运动, 然后, 通过词汇树将HOG 与HOF 组合转换为BoWs, 最后, 应用随机森林识别人类行为的类型。 Abdulmunem 等[47]提出了一种基于突出目标检测和局部描述符与全局描述符相结合的人体动作识别新框架, 首先检测视频帧中的突出对象, 提取这些对象的特征; 然后使用 一个简单策略识别和处理包含突出对象的视频帧, 并用突出目标代替所有帧, 在提高算法效率的前提下抑制了背景像素的干扰; 最后将这种方法分别与局部描述符和全局描述符结合(分别称为3d-sift 和方向光流直方图), 利用所得到的显著性指导特征, 结合多类SVM 分类器进行人体行为识别。 姚明海等[48]从特征提取和选择的角度提出了融合特征区分度和相关性的方法对视频数据进行降维并去除特征集合中的冗余信息。 Li 等[49]提出了一种加权融合方案, 将RGB 和光流与人体姿态特征结合进行动作分类。
在人体行为识别过程中, 仅仅使用单一特征对人体行为进行表征是完全不够的, 并且如浅层特征的自遮挡问题及深度特征的复杂性问题亦是不可忽视的弊端, 因此多特征是未来的研究方向之一。 随着新特征的不断引入, 特征向量的维度也随之提高, 虽然引入新的特征会提高识别精度, 但过高的特征维度使计算量大幅提高, 因此需要有效的特征选择和降维方法, 提高分类性能。 而目前多特征的融合策略十分单一, 因此如何将多特征更巧妙的融合设计和提出或选择更适合的降维手段是未来人体行为识别过程中的研究重点。
2 行为识别常用数据集
在行为识别过程中使用公开可用的数据集可以比较不同的方法, 并深入了解各自方法的能力, 是识别方法在统一标准下校验各种不同性能指标的重要判别依据。 表1 列出了行为识别研究发展历程中一些常用数据集的信息[50-64], 包括对各个常用数据集特点进行简要以及提供下载网址, 并列举了2 个具有代表性的数据库UCF101 和KTH 上分析得近年来传统机器学习方法和深度学习方法, 如表2 ~表3 所示[27,64-79]。 由表2 ~表3 中所示文献的准确率可以发现, 传统机器学习方法在行为识别已逐渐陷入瓶颈,且近年来主要以围绕改进密集轨迹算法展开, 但效果并不明显; 而深度学习方法通过近年来的发展,准确率得到显著提升, 成为研究未来行为识别任务的主流方法。

表1 人体行为识别领域常用数据集Tab.1 Common data sets in the field of human behavior recognition

(续表1)
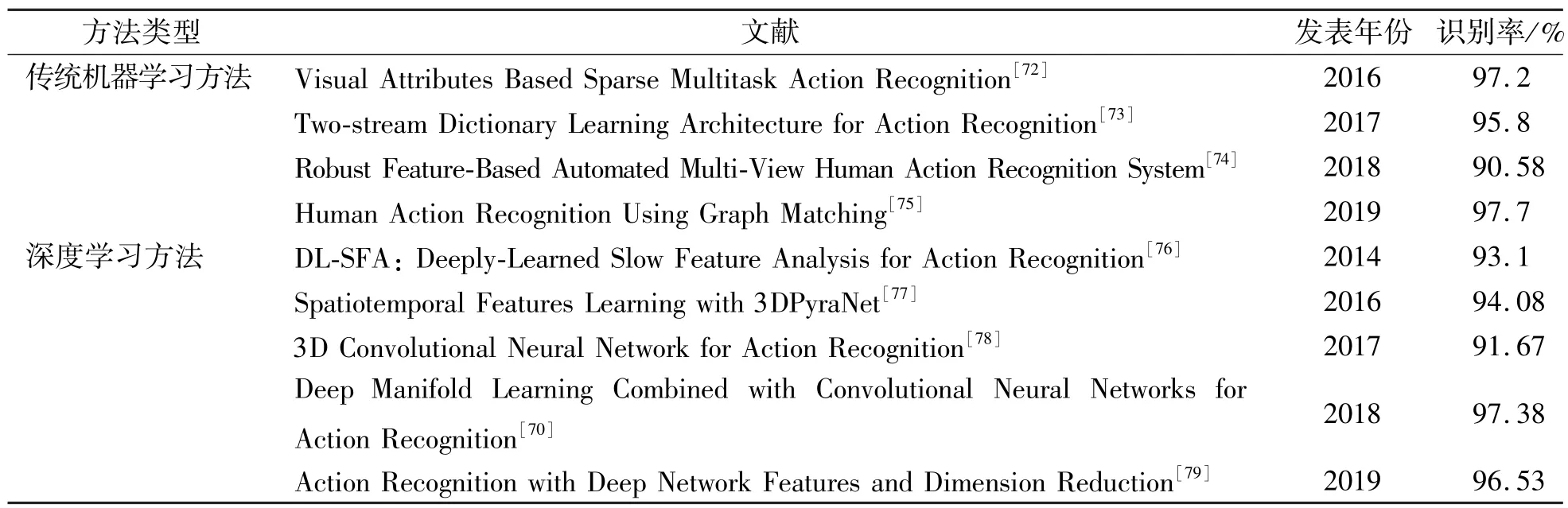
表3 KTH 数据集行为识别方法分析比较Tab.3 Analysis and comparison of behavior recognition methods for KTH data sets
总而言之, 随着人体行为识别领域的发展, 数据集变得更庞大, 样本类别也越来越多, 视频中背景也越来越复杂。 例如较早的KTH、 Weizmann 等数据集, 视频场景简单, 动作种类很少, 相机视角固定且只有焦距变化, 这使现有的算法很容易达到饱和, 很难对比算法的优劣。 近年来, 随着深度学习在行为识别领域的高速发展, 需要训练的数据相比传统算法更加庞大, 小数据集无法满足深度学习算法的需求。 因此学者们在选择测试评估数据时更倾向于HMDB51、 UCF101 等这种大型的且更接近真实环境的数据集, 因此对算法的鲁棒性提出了更大的挑战。
3 目前的难点与未来可能的研究方向
在人体行为识别中, 特征提取起着十分重要的作用, 当前, 外观形状特征、 运动特征和时空特征都属于人体行为识别特征的种类, 且其中每类特征具有多种不同的表述形式。 尽管如此, 在特征提取上仍然有很多亟待解决的问题, 这些问题也同时是特征提取领域未来主要的研究方向。
1) 特征的选择。 在选择特征时, 为了保证识别方法的有效性以及识别性能的良好性, 选择合适的特征向量至关重要。 深层特征具有大量的信息, 能区分不同的动作模式, 但相对提取算法复杂性, 尽管能在特定场景下识别颜色、 形状和运动等单一的视觉线索, 并取得较好的效果, 但在实际的自然场景却有较差的识别性能。 在识别过程中, 特征过多的选取会导致特征向量维数过大, 从而增加计算的复杂程度, 而若选取的特征太少, 则无法获取较高的识别率。 因此如何在这两者中权衡, 是研究者们未来需要解决的问题。
2) 特征的比较与算法性能评测。 要对不同特征进行比较和测评, 需要构造较为合理的包含人体动作行为视频的测试库, 并在合理比较和测评方法的基础上进行研究, 同时还要考虑鲁棒性、 准确率和实时性这3 个衡量算法性能的指标。 目前的研究工作中这3 个指标准确率是最重要的, 鲁棒性相对其他两个指标受到关注较少, 但在实际应用中鲁棒性和实时性都是不容忽视的问题, 在实际情景中衡量算法性能时, 需将这3 个因素综合考虑。 因此, 在考虑某些具体应用时需开发既能提高识别性能, 又能降低算法复杂度的新技术。
3) 多特征融合。 每种算法在不同的环境中对人体行为的特征提取不尽相同, 如何融合多种行为特征寻找出描述人体行为更根本的特征, 并运用于其他学科中, 有待研究者们进一步的研究。 目前, 多摄像机环境由于能解决单摄像机系统中存在的视频特征与三维模型对应的歧义问题, 在多视角环境下能提供深度信息[80]并通过准确恢复三维模型的参数帮助解决遮挡问题受到人们广泛关注。 因此, 多摄像机的特征融合已经成为目前人体行为识别研究的一个热点。
4 结 语
人类行为识别与理解已成为计算机视觉领域的一个重要研究方向。 它在智能视频监控、 医疗诊断监护、 智能人机交互、 身份识别等领域中具有广泛的应用。 笔者主要从不同类型特征的角度, 较为全面的介绍了特征提取方法以及一些常用的经典行为数据集, 最后讨论了目前行为识别中特征提取所存在的问题以及未来可能的发展方向。
