甲骨文研究中跨模态知识图谱的重要性刍议
2020-11-16韩胜伟
熊 晶, 韩胜伟
(1.安阳师范学院 计算机与信息工程学院, 河南 安阳 455000;2.甲骨文信息处理教育部重点实验室,河南 安阳 455000)
一、前言
甲骨文是目前发现的最早成体系的汉字,是中华民族传统文化的瑰宝。甲骨文因其记录了3000年前殷商时期各方面的事件,具有极高的文物价值、史料价值和研究价值[1]。从1899年甲骨文被发现以来,经海内外学者近120年前赴后继的探索,甲骨文的历史奥秘逐渐揭开,针对甲骨文的研究崭然成为一门举世瞩目的国际性显学——甲骨学[1]。甲骨学是以甲骨文和它的载体卜甲、卜骨及相关考古学现象为研究对象,整合古文字学、历史学、历史文献学、文化人类学等多个学科的理论、方法和材料探析甲骨文和甲骨自身规律及商周历史文化的专门性学科[2]。但是传统的甲骨学研究方法存在知识体系庞大、学习难度高、学习周期长、知识关联性弱、知识共享程度低等问题[3],若能将海量的甲骨学知识点以语义关联方式进行组织和管理,可以有效解决或缓解这些问题。2019年10月18日,“殷契文渊”——甲骨文大数据平台正式发布,该平台为甲骨学研究提供大数据支持,标志着甲骨学研究进入智能化时代。正如中国社会科学院学部委员、中国社会科学院甲骨学殷商史研究中心主任宋镇豪先生在纪念甲骨文发现120周年国际学术研讨会学术工作委员会上所说:“新世纪、新机遇,新使命,在甲骨文的整理保护与科学研究方面,应该有新的作为。”因此,新时代的甲骨学研究需要开启新的研究模式。
二、人工智能时代的甲骨学研究
近年来,人工智能技术发展迅猛,在各行业都有了成熟的应用或突破性的进展,如人脸识别、语音助手、自动驾驶等。总体而言,人工智能在感知层面的发展较好,如人脸识别技术。但是,在认知层面人工智能的发展相对滞后,如常识理解。其主要原因是目前的人工智能绝大多数是基于大数据、大算力和强算法的,需要大量的人工进行数据的标注和处理,呈现“人工有余而智能不足”的现象。而认知层面的人工智能需要计算机具备认知理解和知识推理的能力,需要有深厚的背景知识作为基础。甲骨学是属于融合了感知智能和认知智能且认知多于感知的综合研究,因此势必需要一个庞大的知识库作为支撑。知识图谱[4]就是一个可以提供领域背景知识超大规模的知识库,它通过“节点-边-节点”的方式,将知识点进行语义关联,从而构成一个庞大的知识网络,可望实现人工智能从感知智能向认知智能迈进。因此,构建甲骨学知识图谱是一项极其重要的基础工程,可为甲骨学的知识共享和推理提供基本需求。
因此,人工智能时代的甲骨学研究需要实行人机结合、分工明确、通力合作、机服务人的策略和部署。即甲骨文专家和计算机各自充分发挥自身优势,由计算机负责感知层面的图像识别、信息检索等有规律可循、有模式可用的重复性强的工作;由甲骨文专家负责认知层面的知识推理、正误判断等无固定模式、需要决策的创造性强的工作。在现阶段,总体思路是计算机服务于甲骨文专家,辅助专家进行甲骨学研究。
随着甲骨学研究的不断推进,我们已经积累了相当规模的基础数据,包括甲骨学文献、甲骨文著录、数据库、文本语料库、视频、图像、3D模型等多种形式,已体现出多模态特征[3]。因此,我们的目标是基于多源异构数据源,构建跨模态的甲骨学知识图谱。
三、构建跨模态知识图谱的重要性
作为一门综合学科,甲骨学的研究涉及到多领域多来源的知识,且知识存储格式不统一,知识表示方式各异,涉及到字(甲骨文字形字体)、图(甲骨文图片)、文(甲骨文文本)、表(数据表格)、著(文献及著录)等多种形式。管理、共享和重用这些知识需要一个有效的工具,跨模态知识图谱可堪此重任,且在解决甲骨文考释和缀合两大难题方面有着重要作用。跨模态知识图谱示意图如图1所示。

图1 甲骨学跨模态知识图谱示意图
1.在知识管理和共享方面的重要性
甲骨学研究必须依赖大量的文献资料,并基于文献进行一系列的知识关联分析。如学者与文献的关系、学者及其合作关系、研究机构及其合作关系、文献之间引用与被引关系。而且,甲骨学的研究必须借助于相关的辅助学科。如借助于考古学,去解决甲骨出土的问题;借助于文献学,去解决甲骨学中的殷商历史问题;借助于语言学理论,去解决甲骨学的语言文字的问题;借助于自然科学中的天文学、地理学、物理学和数学,去解决甲骨学中的诸方面的问题[5]。这些问题都涉及到文献的计量与分析技术,因此构建甲骨学文献图谱极其重要。
甲骨文信息处理为改善传统的甲骨学研究开拓了一条新的有效途径。经过20年的甲骨文信息处理的研究积累,我们设计和构建了一系列甲骨文数据库,如甲骨文语义词典、甲骨文著录数据库、甲骨文文献数据库、甲骨文缀合数据库等。这些数据库符合一定的模式,存储的是知识元组,是从海量的甲骨文知识数据源中提炼出结果,是知识在一定程度的整理和总结。因此,建设甲骨文数据库有着重要作用。
利用计算机进行甲骨文研究,需要考虑甲骨文的语法结构、句法结构以及语义信息,因此甲骨文的文本整理成为一项基础工作。甲骨文文本既包括甲骨文释文,也包括甲骨文文献及著录的文本化,还包括涉及甲骨文研究的网页、教材、评论等信息。基于甲骨文文本,通过构建语言模型,可以进行文本挖掘、实体识别、关系抽取、语义相似度计算等机器学习和自然语言处理等自动化工作。因此,构建甲骨文文本语料库具有重要作用。
甲骨文研究的对象包括甲骨照片、拓片、摹本等图像,如何从这些图像中自动检测和识别出甲骨文字,是甲骨文信息处理研究的重要任务。与其他自然场景的图像处理不一样的是,甲骨图像含有更为特殊的噪声,而且对拓片图像进行处理时,往往会将甲骨上的生物纹理识别为文字笔画。甲骨片的残缺以及甲骨上的残字模糊字给甲骨文字的检测与识别带来极大的挑战,往往需要综合考虑和对照甲骨照片、拓片、摹本以及释文等信息。因此,构建甲骨文图像资源库是极其重要的。
甲骨学体系庞大,知识点众多,知识表示及存储格式不统一,而且甲骨文专家对甲骨文的辨识依靠长期的学术钻研和经验积累,这种经验知识仅存储在专家的头脑中,并不能实现知识的有效共享。如何利用一种有效的技术实现现有甲骨文知识的共享,并方便计算机对其进行理解和处理?本体作为共享概念模型的明确的形式化规范说明[6]可以为这一问题提供解决方案。甲骨文信息处理研究中,为了给甲骨文基础数据提供语义信息,需要采取一种机器可读的表达形式。构建甲骨文本体可以为甲骨文数据提供语义表达及知识推理功能,因此,对甲骨文知识的共享、重用和推理具有极其重要的作用。
综上所述,管理和共享甲骨学知识需要整合各种数据资源,并从这些多源异构的数据中抽取知识实体,并挖掘和构建实体之间的语义关联,这样就构建了一个大规模的跨模态知识图谱。具体的构建流程如图2所示。
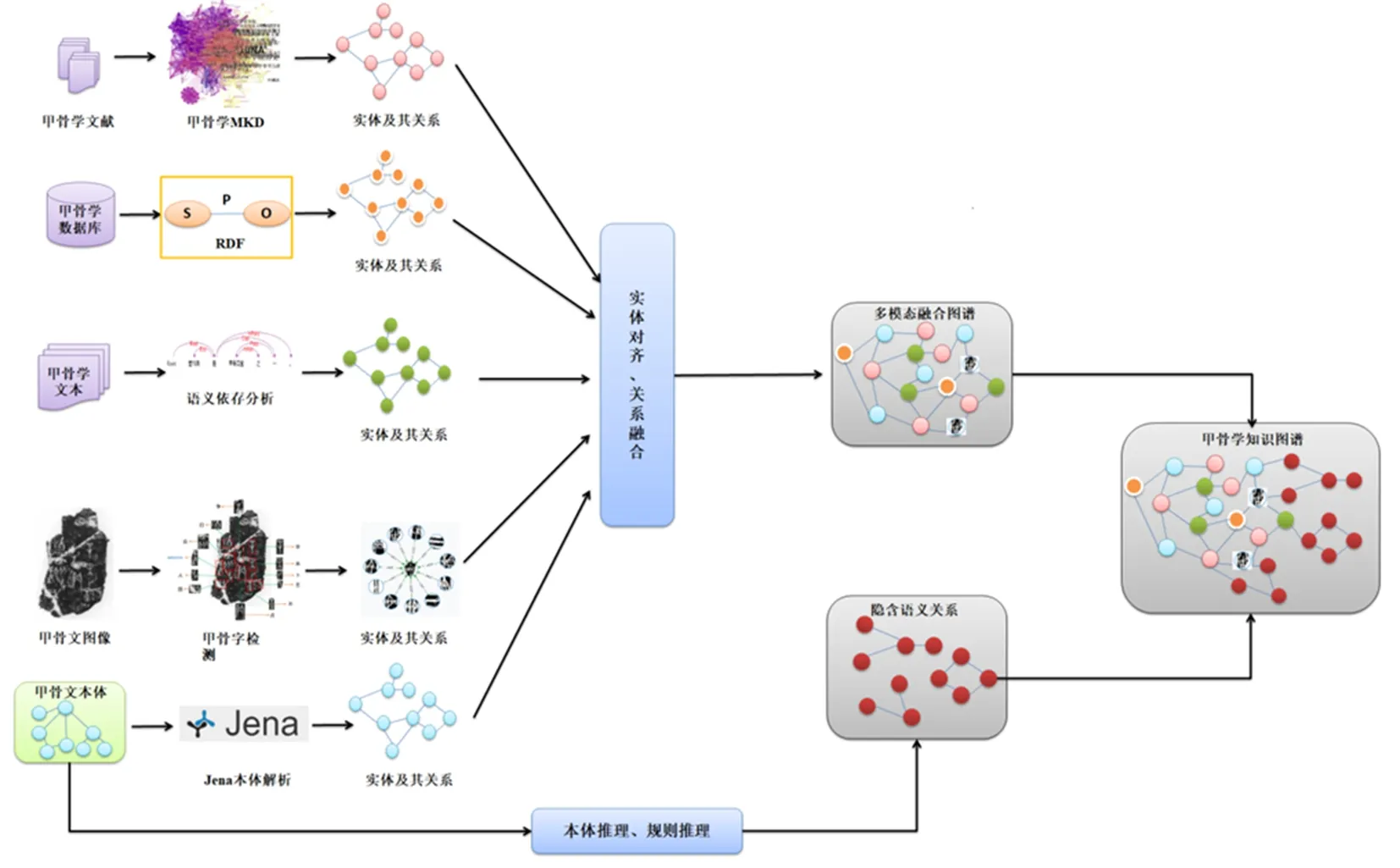
图2 甲骨学跨模态知识图谱的构建流程
2.在甲骨文考释方面的重要性
甲骨文字考释,是利用其他古文字材料和传世字书把过去不认识的甲骨文字释读出来,从而把不易理解的甲骨卜辞讲解清楚,为其他研究做准备。甲骨文考释的常用方法有“字形比较法”“辞例推勘法”“偏旁分析法”等。
“字形比较法”一方面要求熟悉每一个甲骨字的笔画特征,还要深入把握同一个甲骨文字的不同异体,需要明确哪些笔画区别字形,哪些笔画不区别字形,通用无别;而且还要对甲骨文字的类组差异、异体分工等现象有深入理解,需要全面梳理甲骨用字情况。另一方面,要求把握每一个已识甲骨字的形体演变,总结出基本构字偏旁的历时演变规律,因此需要掌握不同时期甲骨字关联的其它形体的古文字。
“辞例推勘法”主要通过不同辞例的互相比较、分析,归纳出甲骨未释字的语义特征和范围,锁定释读方向。虽然多数情况下不能直接得出释读结论,但却是“字形比较法”的重要补充,具有重要的作用。因此,在不能肯定某一未释甲骨字究竟为何字时,能推测其所属的语义范畴也是极其重要的。
“偏旁分析法”是形体分析法的重要组成部分,也是学界常用的考释文字的手段和方法,它是通过文字构成部件及其组构关系的分析来达到考释文字的目的。把这种方法提高到一种具有科学意义的研究手段,是从清末孙诒让开始的。其做法是先把已经认识的古文字,按照偏旁分析为一个个单体,然后把各个单体偏旁的不同形式收集起来,研究它们的发展变化;在认识偏旁的基础上,最后再来认识每个文字[7]。因此,明确偏旁和文字之间的关联和位置关系也是一项重要工作。
因此,对甲骨文考释而言,知道哪一个字出现在哪些甲骨片上,知道某个甲骨字的异体字有哪些,知道哪些甲骨片记载于哪些著录,知道哪些文献研究过哪些甲骨片是至关重要的。这就势必要求建立这些知识元素之间的关联关系,并能通过关系获取考释线索,从而辅助甲骨文专家进行考释研究。跨模态知识图谱可以很好地满足这些要求,一个知识图谱片段如图3所示。
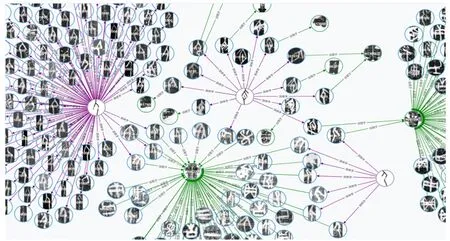
图3 甲骨字与甲骨片、异体字的关联关系
知识图谱的另一个优势是链接预测和知识图谱补全,通常知识图谱补全以链接预测的形式来实现。简言之,在知识图谱的“节点(头实体,可用h表示)-边(节点之间的关系,可用r表示)-节点(尾实体,可用t表示)”结构中,可能会有缺失的元素,知识图谱补全则是将缺失的元素补充完整。例如,假定有一个链接预测任务 (h, r, ?) ,对于一个给定的实体h,和一个给定的关系r,预测的任务就是确定哪个实体或者哪些实体可以形成一个知识三元组 (h, r, t)。利用知识图谱补全的方法,可以预测甲骨文中残缺或模糊字语义链接,从而为甲骨文专家进行考释提供有价值的线索。
综上所述,跨模态知识图谱在甲骨文考释方面具有重要的作用。
3.在甲骨文缀合方面的重要性
通过缀合而得到的甲骨刻辞具有相当高的史料价值。刻写着文字的龟甲兽骨,有的早在殷代就已断裂,有的经过三千多年地下的埋藏腐蚀,已成碎片残骨,有的在出土后遭人为的原因而断缺。把断片尽可能缀合复原,是甲骨文研究的重要工作之一[8]。甲骨文经过缀合复原的处理,才能找出各辞之间的相互关系,恢复当时的卜辞文例,从而成为认识商代社会的重要史料[9]。
进行甲骨文缀合研究,需要综合考虑多种数据来源和数据属性,如甲骨图片、甲骨缀合图版、释文考释、缀合人、缀合方法、缀合时间、增量缀合(即在前人缀合成果上增加的缀合新例)情况、著录、发表的缀合文章、缀合出处等,还需要考虑片形、文字、卜兆、文例、分期等信息。不同时期的甲骨缀合也采用了不同的方法,如甲骨缀合的初级阶段多是传世著录拓片碎片的零散片断的缀合,主要是靠学者的学识和聪慧;发展与成熟阶段,董作宾首倡的甲骨拓片“定位法”研究,不仅对甲骨文例的研究,而且对零碎的甲骨拓本缀合研究也颇有启示意义,并愈来愈得到1928年科学发掘殷墟出土甲骨实物的验证和丰富;“甲骨形态学”研究的新阶段,开始对甲骨文的载体——龟甲和胛骨进行深层次、全方位、多角度的研究。如黄天树等学者对龟腹甲(包括背甲)和胛骨进行了化整为零的齿缝片形态和特征的深层次观察,为甲骨碎片的求其全体的“定位”的“甲骨形态学”的完善和形成作出了贡献,推动了甲骨缀合研究的发展[9]。
由此可见,从事甲骨缀合研究,需要专家长期的科研积累和对甲骨材料、文献的敏锐洞察,一点一滴的缀合线索往往隐含在海量的甲骨数据和传世文献中。而且,缀合过程中往往需要各种数据相互印证和信息互补。如较小的拓片无法确定材质时,通常可以用照片或3D来补充;候选缀合片组合是否正确时,通常利用释文进行验证。这些线索之间往往有着直接和间接的联系,一旦找到其关键点,就能达到“纲举目张”的效果。而这些关联信息一旦存储和记录在跨模态知识图谱中,通过节点路径查找,可以寻觅“蛛丝马迹”,从而辅助甲骨文专家进行缀合。
计算机辅助甲骨缀合研究中,排除不正确的缀合候选项也是一个重要内容。一方面,缀合后的甲骨有利于复原甲骨卜辞;另一方面,拟复原的甲骨卜辞也可以印证缀合候选项是否正确。但是,判断拟缀合的候选甲骨是否正确是一项高要求高标准的工作,完全依赖甲骨文专家仍然无法摆脱现有的研究困境。而知识图谱可在这一方面“助一臂之力”。基于知识图谱进行查询和推理,利用一致性检验、异常点分析、团组挖掘,可以发现潜在风险。正因为如此,知识图谱在金融反欺诈场景中有着广泛应用。同样,这一优势可以迁移到甲骨缀合研究,通过发现“缀合异常”为甲骨文专家提供判断线索。
综上所述,跨模态知识图谱在甲骨文缀合研究方面有着重要作用。
四、 总结
大数据时代,一个场景中缺失的信息往往在另一个场景中重复出现,各种信息重叠和复现,很容易就能实现“用户画像”,甲骨文信息处理的研究也是如此。基于甲骨文基础研究数据的多模态特性,通过构建大规模跨模态的甲骨学知识图谱,将知识实体的属性及关系进行知识表示和存储,就能实现“甲骨画像”。借助甲骨学知识图谱,利用人工智能技术可以有效缓解或解决目前甲骨学研究中知识表示、管理、共享及重用等诸方面的问题,从而服务于甲骨文专家从事考释及缀合方面的研究。
