基于Petri网的数据清洗规则链自动组合与检测
2020-11-14张云飞张德海
何 俊,张云飞,张德海
(1.昆明学院 信息工程学院,昆明 650214; 2.云南大学 软件学院,昆明 650206)
0 概述
随着信息技术的快速发展,数据规模逐渐扩大,劣质数据不断增加,从而导致数据质量低下,在一定程度上降低了数据可用性,因此数据清洗(Data Cleaning,DC)技术应运而生[1]。目前的数据清洗方法多数关注技术本身或者针对某个领域的语义和业务逻辑规则进行清洗,面对复杂应用领域的大规模、异构数据时表现出清洗效率低下、出错率高等问题。虽然清洗规则的孤立使用简化了问题的复杂度,但由于没有严格的规则间逻辑校验机制,致使规则冗余普遍存在,逻辑冲突不易发现,因此最终严重影响数据修复质量。
目前,国内外学者在数据清洗规则库领域进行了大量研究。文献[2]提出一种基于动态可配置规则的数据清洗方法,具有跨领域、可重用、可配置和可扩展等特点,提升了规则重用和清洗效率。文献[3]将数据质量问题分为单数据源模式层问题、单数据源实例层问题、多数据源模式层问题和多数据源实例层问题四大类,并给出了较清晰的规则分层思路。文献[4]针对数据噪声、缺失值和不一致数据等脏数据问题进行识别和修复。文献[5-6]围绕相似重复记录的识别与剔除方法展开研究,以召回率和准确率作为算法评价指标,对解决规则冗余问题具有一定的指导作用。文献[7]将数据清洗结合端到端质量执行机制进行上下文整体清洗。文献[8]对基于特征相似度、上下文和关系的规则推理方法进行研究,但没有给出具体模型和执行路径。文献[9-11]针对数据清洗中的逻辑不一致问题,利用规则推理方法进行降噪,具有一定的参考价值。文献[12]提出一种模仿专家手动操作的基于规则的数据清洗方法,但该方法未给出具体的实现步骤和算法。此外,文献[13-15]给出了大数据清洗规则的系统架构、具体方法和实现过程。文献[16-18]在大数据清洗系统中充分考虑了数据一致性问题,并有效地提升了数据质量。
目前,虽然在数据清洗、领域规则库和规则清洗等方面具有较多的研究,但是针对规则链组合和规则一致性问题的研究尚不多见。因此,本文提出一种分层的规则库,采用Petri网(Petri Net,PN)对其进行建模,并使用形式化方法对规则链流程的正确性和可达性进行推理与检测,同时对规则链进行优选。
1 分层规则库与规则链
数据清洗具有逻辑性强、上下文相关和不同领域重用难等特征[19],可见,组合大量规则以批量执行数据清洗任务则较为复杂。因此,通过建立包含通用层、领域层和自定义层的三层规则库,将规则按可重用程度和规则间相关程度进行划分,重点关注同层内规则之间的逻辑关系,可为进一步实现规则批量执行提供基础。
定义1(规则) 将规则定义为一个三元组[20],即R=(Rd,Rc,Rl),假设R为不可分割的最小逻辑单元,即原子规则,其中:Rd表示规则唯一标识,由规则的层编码和顺序码组合而成;Rc表示基于上下文的规则描述,定义为一个二元组Rc=(Di,Rx),Di是待处理的目标数据项集合参数,Rx是规则操作描述文档,采用Petri网标记语言(Petri Net Markup Language,PNML)进行描述[21];Rl表示规则间的逻辑关系,定义为一个三元组Rl=(PR,CR,SR),PR是前置规则集,CR是冲突规则集,SR是后续规则集。
定义2(规则层) 规则库是R的集合,包括通用规则层(General Rules Layer,GRL)、领域规则层(Field Rules Layer,FRL)和自定义规则层(Custom Rules Layer,CRL),分别表示为LG、LF和LC。每个规则层定义为一个三元组,以通用规则层为例,LG=(Li,{R},La),其中,Li表示层编码,{R}表示该层中所有规则的集合,La表示规则层间的操作权限限制集。
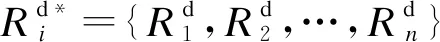
定义4(规则链) 假设在规则选择集S中包含n个规则且n≠0,并设其中任意一个规则Rk为初始规则,则可根据业务需求建立选择集S中的规则链:
(1)
其中,k≤j≤k+m-1,m是该规则链中的规则数量且满足0≤m≤n。规则链C是根据规则之间的前置规则集PR、冲突规则集CR和后续规则集SR的逻辑和约束关系连接而成,只有满足以下条件,才能连接两个规则:
1)前一个规则在后一个规则的前置规则集中或者后一个规则在前一个规则的后置规则集中。
2)两个规则都不在对方的冲突规则集中。
由定义4可知,此处的规则链只定义了规则的执行顺序,并未考虑规则的并行、分支和循环等问题。规则选择集S中所有满足上述条件的规则链C组成的集合称为规则链生成集,记为C*={∪Ci}。
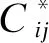
1)Ci⊄∅,Cj⊄∅。
2)Ci.R∉LG.La,Ci.R∉LF.La。
如果规则选择集S中有n个规则且所有规则之间都可以任意连接,则总共可生成(n-1)!个规则链,但每一条规则链可能存在并行、选择和循环等多种组合关系。因此,需要进一步研究规则组合方法以及规则链的逻辑正确性和规则链优选等问题。
2 Petri网与规则链组合模型
2.1 Petri网
Petri网是一种状态变迁模型,用于描述系统异步和并发状态的变迁关系。
定义6(Petri网) 将Petri网定义为一个四元组PN=(P,T,F,M)[22],当满足下列条件时,称PN为Petri网:
1)P∪T≠∅,P∩T=∅。
2)F⊆{(P×T)∪(T×P)}。

5)触发规则,如果∀p∈′t:M(p)≥1,则称变迁t是使能的,表示为M[t>。如果状态标识M下t是使能的,则称t可以触发,且触发后得到的后继标识为M′,记为M[t>M′,并且:
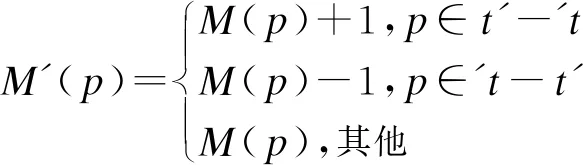
(2)
其中,P为库所集合,T为变迁集合,F为基于P和T建立的有向弧集合。
定义7(输入集和输出集) 对于∀x∈P∪T,称′x={y|(y∈P∪T)∧((y,x)∈F)}为x的输入集,x′={y|(y∈P∪T)∧((x,y)∈F)}为x的输出集[22]。
定义8(可达标识集) 若Petri网中存在t∈T使得M[t>M′,则称M′是从M可达的,则PN中从M可达的全部标识集合称为可达标识集[22],记为R(M),且对∀t∈T,推得∃M∈R(M)⟹∃M′∈R(M)。
定义9(关联矩阵) 在Petri网中,若P={p1,p2,…,pn},T={t1,t2,…,tm},则可表示为矩阵A=[aij]n×m,当且仅当A满足下列条件时,A称为PN的关联矩阵[22-23]:
(3)
(4)
(5)
定义10(迁移矩阵) 当且仅当矩阵K=A-diag(t1,t2,…,tn)A+满足下列条件时,称K为PN的迁移矩阵[22-23]:
1)当|ti|=1时,变迁触发,其中,ti是PN中的变迁,i=1,2,…,n。
2)当|ti|=0时,变迁触发失效。
经济全球化的发展,出国旅游也变得越来越普遍,代购行业也越来越繁荣。在此背景下,提高英语能力尤其是口语能力口语更好地满足社会发展的需求,因此,在高职院校的英语教学中,需要正视自己与本科院校学生英语水平的差距,高职院校英语综合能力较弱,在表达能力上更是有所不足,因此,在这个大背景下,高职院校学生英语能力无法满足社会日益发展的需求矛盾,传统的教学模式重视教师的主导作用侧重于教,现代化教学模式侧重学生的主体地位,而混合式教学的新鲜元素的应用在课堂上,可以打破限制英语口语能力的发展的因素,积极引导学生英语课堂的参与积极性,促进英语口语交流的可能性,激发学生学习英语的自主性与积极性。
2.2 基于Petri网的规则链组合模型
在数据清洗操作开始前,根据业务需求选择适合的规则选择集S,而从S中生成无冗余规则、逻辑正确和最优的规则链至关重要,直接关系到规则链的自动执行和数据清洗质量。因此,基于Petri网建立规则链组合模型(Rule Chain Combination Model,RCCM),在规则集执行前使用形式化方法对规则链的正确性和可达性进行检测。
定义11(规则链组合模型) 当且仅当满足下列条件时,称四元组Q=(S,C*,PN,M)为数据清洗规则链组合模型,其中:S表示包含n个原子规则R的规则选择集;PN表示包含有限库所集、有限变迁集和有向规则关系的Petri网;C*表示S的规则链生成集,PN的变迁集合T⊆S;M表示PN中库所和变迁的标识符状态函数集。
对于规则链组合模型作如下说明:
1)RCCM模型中PN的所有库所集合P包含前置规则集PR(表示为Pp)、后续规则集SR(表示为Ps)及冲突规则集CR(表示为Pc),并满足P=Pp∪Ps∪Pc。为与Petri网特性保持一致,定义两个特殊规则库所:源规则库所和终止规则库所,其中,源规则库所对应规则链中的起始规则,终止规则库所对应规则链中的终止规则。
2)RCCM模型中PN的变迁表示规则链中的规则R,在变迁集合T中,对于∀t∈T,在′t和t′中至少有一个前集和后续的元素相匹配且不在冲突集中。此时变迁使能,即M[t>M′并将规则不冲突作为变迁触发的前提条件:
(6)
3)此处的规则链已经由定义4中的规则顺序执行,扩展到规则并行、分支和循环等逻辑结构。因此,RCCM模型中基本逻辑结构包含顺序、并行、分支和循环4种,如图1所示。
3 RCCM模型分析与检测
3.1 RCCM模型相关问题
RCCM模型是利用Petri网对并发和异步系统进行形式化表达和逻辑验证,构建可重用、可靠、高效的规则链组合和优选方法,提高数据清洗质量和效率。RCCM模型形式化分析的前提条件为:
1)规则语义规范性。为保证规则语义的一致性、清洗操作的协同性,采用Petri网描述语言对规则进行形式化描述,同时与模型语义保持一致。
2)孤立规则。在给定的规则选择集S中,不能组成任何规则链的单个规则将被模型检测为孤立规则或冗余规则,尽管这些孤立库所不纳入模型重点考虑的范畴,但在实际应用中具有重要意义,必须作为单独的一类规则链参与数据清洗的执行过程。
3)规则链优选指标。在保证规则链正确性、可达性和无死锁的前提下,需要在给定的规则链生成集S*中判断最优规则链,当且仅当满足下列条件的规则链称为最优规则链C*(m):
(7)
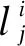
4)层间规则链组合。为简化模型且不失一般性,在组合层间规则链后直接进行数据清洗操作,不在模型中进行单独处理。
3.2 RCCM模型分析
3.2.1 规则链生成与正确性检测
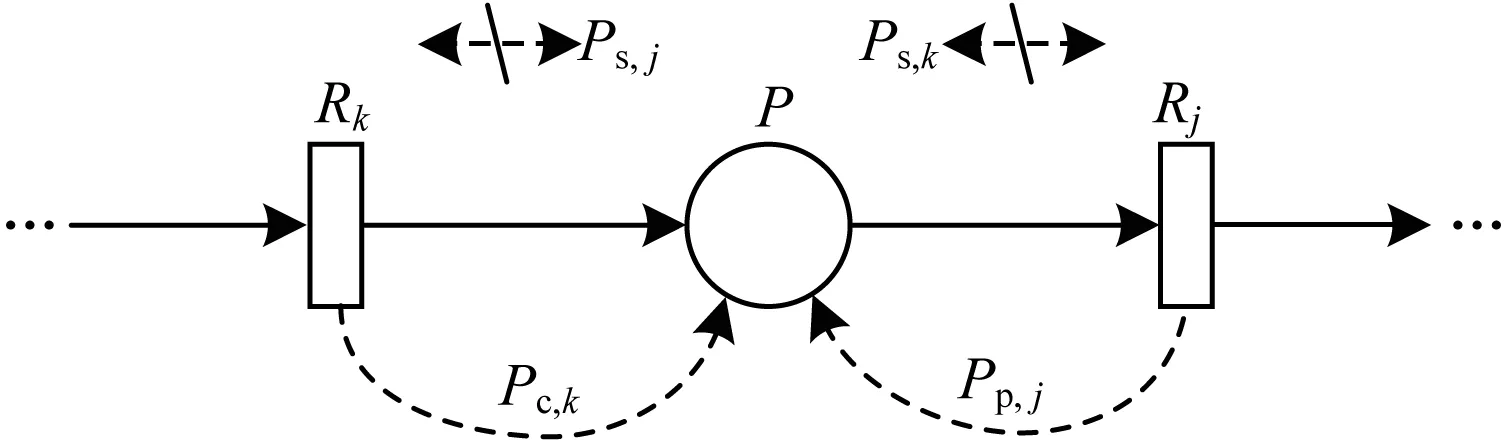
图2 规则PN组合示意图
规则链中每组合一个规则需要完成一次回溯检测过程。当遍历所有k时,即可生成一个关于规则链C的PN,构建完成一个规则链PN需要k(k-1)/2次回溯检测,保证了规则链的逻辑正确性,且根据PN的特点,规则链中可能存在顺序、并行、分支和循环4种结构。重复上述操作,可得到满足使能条件的所有关于规则链C的PN集合,记为Px,并将这些满足逻辑正确性的规则链数量记作x。
3.2.2 规则链可达性检测
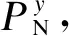
3.2.3 规则链优选
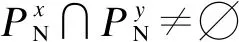
3.3 规则链生成与检测算法
根据上述规则链生成、规则链正确性和可达性检测,设计规则链生成与检测算法,具体如下:
算法1规则链生成与检测算法
输入规则选择集S、初始规则R0、规则链最大长度N
输出规则链检测结果、最优规则链C*(m)
1.CheckModel(S,N)
2.For i=0 to N when//读取选择集中的所有元素
3.R[i]=S.R;
4.R[i].Ri=R.Ri& Rc& Rl;
5.C[0][0]=R0;//初始化规则链
6.For i=0 to M when//生成与回溯检测规则链
7.For j=0 to N when
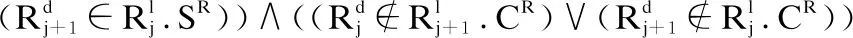
9.C[i][j]=Ri;
10.Check 1 is true.
11.For i=0 to M when
12.If (Rj∉C[i])
13.Mk[tk,Rk>M′;//检测规则链可达性
15.Rk=Rk+tj;
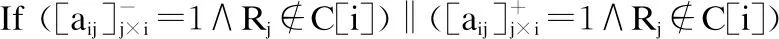
17.Check 2 is true.
18.For i=0 to M when//规则链优选
19.For j=0 to N when
20.If (C[i][j] =C[i][j+1])
21.l[i]= l[i]+1; //规则重复计数
22.p=max{mi/(l[i]+1)};
23.C*(m)=C[i];
24.Output Check 1 Check 2 and C*(m)
以规则选择集和规则链最大长度作为算法输入,通过第1行~第4行读取选择集中的元素,第5行~第7行为初始化规则R0并对每一个规则进行回溯遍历,第8行判断规则是否满足加入规则链的条件。第11行~第17行计算Petri网的状态可达图,测试RCCM库所及变迁是否正确,检测所生成的每一条规则链是否正确和可达。通过遍历可能生成多条规则链,因此第18行~第24行利用第7行的计算规则选择最优规则链并对其进行输出。假设规则选择集S中的规则数目为n,生成的规则链数目为m,每次循环都需要进行全部规则遍历,因此算法中规则链生成对应的时间复杂度为O(n2),规则链检测对应的时间复杂度为O(m×n),空间复杂度均为O(m×n)。算法1实现了规则链生成、规则链正确性和可达性检测以及规则链自动优选过程,从逻辑上保证了后续数据清洗操作执行的可靠性。
4 实验结果与分析
4.1 实验数据集设置
实验以某地区扶贫领域的数据清洗应用为背景,从实际数据清洗规则库中提取出部分规则作为选择集,建立RCCM模型。以该地区实际扶贫数据为实验数据,分别使用本文方法和传统规则链顺序执行方法[24]进行对比实验。实验数据集设置如下:
1)实验目标数据集DataSet,主要包括贫困人口基础数据集和其他辅助清洗数据集。贫困人口基础数据集为{序号,户编号,人编号,姓名,证件类型,证件号码,与户主关系,民族,文化程度,在校状况,劳动力状况,务工时间,大病保险,脱贫属性,脱贫年份,户属性,房屋状况,人均纯收入,联系电话,识别时间,帮扶责任人编码},数据记录350 000条。其他辅助清洗数据集包含人口、卫健、教育、银行、交通、税务、工商、残联、民政等9个行业单位的异构数据记录900多万条[25]。
2)数据清洗分层规则和规则选择集S。根据数据清洗业务的目标要求,第1次先抽取GRL层中的5个规则、FRL层中的10个规则及CRL层中的5个规则,共20个规则作为规则选择集(如表1~表3所示),并在此基础上再次增加规则数量。GRL层主要包括通用清洗规则,通常作为进一步开展业务清洗的基础。FRL层主要包括业务逻辑比对和逻辑错误数据清洗规则,通常需要符合业务实际情况。CRL层包括根据用户扩展的规则。每次实验选取的规则将作为RCCM模型实现的规则选择集S。

表1 GRL层中的规则设置
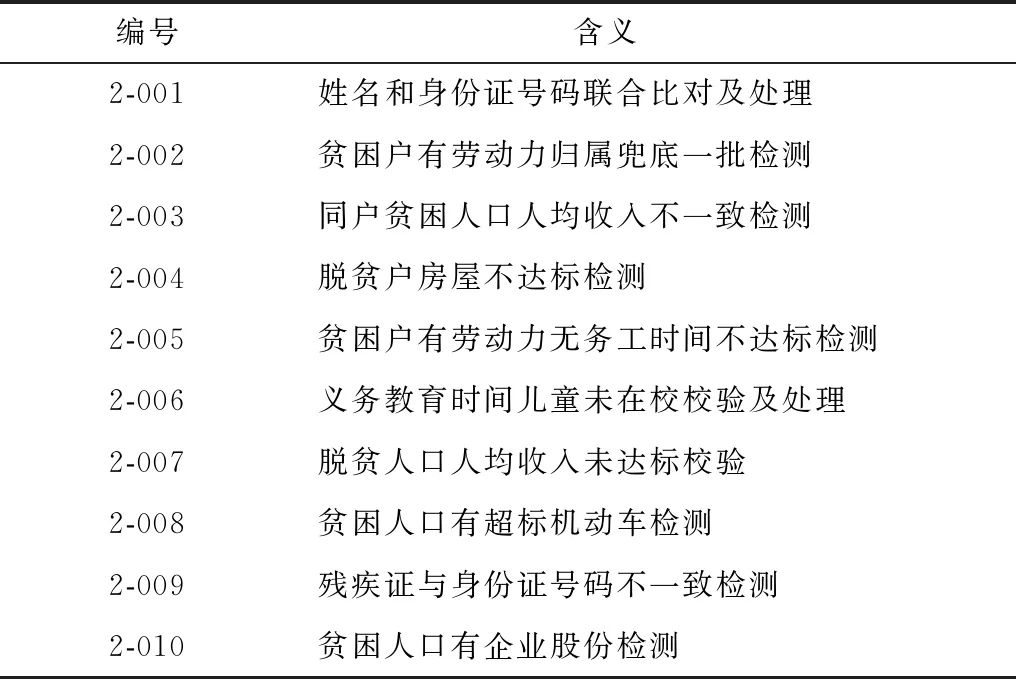
表2 FRL层中的规则设置

表3 CRL层中规则设置
4.2 RCCM模型实现
根据规则选择集S建立RCCM模型。本文首先需要根据清洗目标建立每一个规则的前置规则集PR、冲突规则集CR和后续规则集SR,然后使用算法1的回溯遍历方法生成规则链,经过正确性和可达性检测后生成规则链PN集,最后计算出最优规则链C*(m)执行数据清洗操作。扶贫领域的RCCM模型执行流程如图3所示。
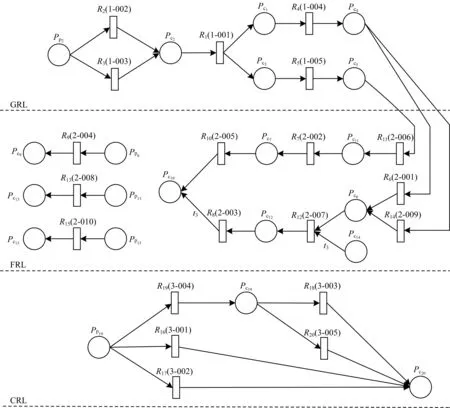
图3 扶贫领域的RCCM模型执行流程
从RCCM模型实现结果可以看出,RCCM模型有效优化了规则之间的逻辑关系和执行顺序,例如规则1-001和1-003,如果采用传统规则链顺序执行方法先执行1-001再执行1-003,即先检测重复记录再检测和处理异常数据,则重复记录通常会严重影响异常数据检测和处理,而采用RCCM模型先执行1-003再执行1-001,避免了上述问题。另外,3-003和3-005有逻辑冲突,即帮扶责任人帮扶对象超过5户和帮扶责任人无帮扶对象两种情况不可能同时存在,无需同时执行两个规则,属于规则并行结构。因此,RCCM模型通过检测逻辑冲突,选择最优规则链,从而提高数据清洗效率。
4.3 对比方法与结果分析
在扶贫领域数据清洗实际应用场景中,具有数据量大、异构数据源多和分级清洗等特点[26],由于目前采用传统规则链顺序执行方法主要存在效率低、错误传递等问题,因此将通过逐步增加规则数量的方式,分别采用本文方法和传统规则链顺序执行方法对实验目标数据集DataSet进行数据清洗再比较实验结果。
实验环境为包含2个8核CPU的服务器1台、Windows 10 Server操作系统、SQL Server 2014数据库,并采用XML的方式存储规则。实验待清洗目标数据为356 123条贫困人口基础数据,辅助数据为9 325 642条行业扶贫数据,分别采用本文方法和传统规则链顺序执行方法各自独立开展4次实验,规则数从第1次的20个分别增加至50个、100个、200个(由于规则编辑和配置工作量较大,因此本文中不再增加规则数量),其中分层规则数量采用各层规则等比增加的方式。同时,为避免引入特殊规则使实验结果失真,规则均在同一类型基础上进行增加。时间消耗以服务器记录时间为准,错误数据的评判标准为采用实验数据集与国家扶贫办基础数据库已校准的对应数据集进行比对,若发现不一致则再经过人工核对,最后确认为符合规则逻辑但被错误删除或修改的数据,如表4所示。从实验结果看,本文方法和传统规则链顺序执行方法都产生了错误数据,错误数据量和时间开销均随着规则数量的增多而增加。

表4 本文方法与传统规则链顺序执行方法的实验结果对比
本文分别从错误数据量和时间开销两方面对实验结果进行分析,如图4和图5所示。可以看出,随着规则数量逐步增多,传统规则链顺序执行方法的错误数据量急剧增加,而本文方法的错误数据量增加比较平稳,说明其可以有效减少错误数据的产生,并且所消耗的时间更少,具有更高的执行效率。
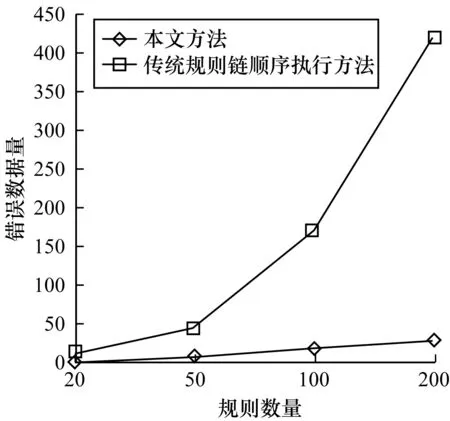
图4 本文方法与传统规则链顺序执行方法的错误数据量对比Fig.4 Comparison of the number of error data between the proposed method and traditional rule chain sequential execution method
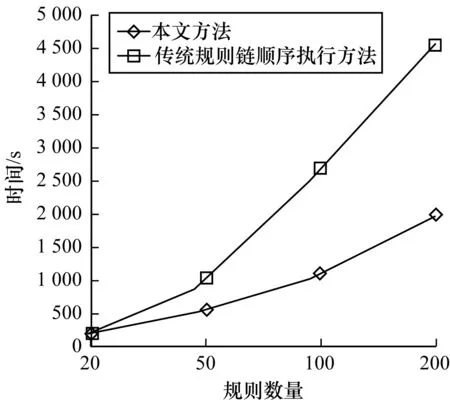
图5 本文方法与传统规则链顺序执行方法的时间消耗对比
5 结束语
本文针对数据清洗规则链组合和规则一致性问题,提出一种分层的规则库,并采用Petri网建立数据清洗规则链组合模型,对规则链进行逻辑正确性和可达性检测,从而选择最优规则链执行数据清洗操作。实验结果表明,该方法能有效减少错误数据量,并具有更高的执行效率。后续将对规则链分层组合效率进行研究,进一步提高规则重复利用率和数据修复质量。
