一种集成深度学习模型的旅游问句文本分类算法
2020-11-14马喆康迪力亚尔帕尔哈提早克热卡德尔吐尔根依布拉音西尔艾力色提艾山吾买尔
马喆康,迪力亚尔·帕尔哈提,早克热·卡德尔,吐尔根·依布拉音,西尔艾力·色提,艾山·吾买尔
(新疆大学 a.软件学院; b.信息科学与工程学院; c.新疆多语种信息技术重点实验室,乌鲁木齐 830046)
0 概述
随着我国社会经济的发展和人们物质生活水平的提高,旅游已经成为人们休闲娱乐的主要方式,但游客在旅游过程中发生的路线规划、酒店预订等问题也不断增加[1]。目前,游客主要通过旅游网站问答方式获取旅游信息,需要对问题进行发布并等待其他用户的回复,具有延时性,而且旅游问答社区通常根据地理位置的问题分类方式,无法全面覆盖问题的所有类别。此外,传统旅游问答社区一般采用人工标注或机器学习模型进行问题分类,导致分类效率和准确率均较低,无法快速精准地定位游客的问题类别,进而影响后续的信息检索。因此,如何快速高效地对各类旅游问句进行自动分类已成为亟待解决的问题。深度学习技术在近几年得到快速发展,且被应用于问句文本分类任务中并取得了较好的成果[2],相比传统机器学习技术更能捕获文本的深层语义信息及解决人工设计特征导致的误差问题,且分类精度更高[3],但其多数为基于单一结构的深度学习模型或仅对多个模型进行简单串联,因此在挖掘文本深层特征时,会丢失大量的语法和句法信息并增加冗余信息。
本文提出一种集成多种深度学习模型的旅游问句文本分类算法,通过词级卷积神经网络(Word Level Convolutional Neural Network,WL-CNN)获取词的低层空间结构信息构建文本的语法信息,利用句级双向长短期记忆(Sentence Level Bi-directional Long Short-Term Memory,SL-Bi-LSTM)网络对旅游问句文本的全局语义和句法信息进行建模,同时结合多头注意力机制(Multi-Head Attention Mechanism,MH-AM)对这两种深度学习模型进行联合学习并分配注意力权重,以提高旅游问句文本关键特征的利用率。
1 相关工作
早期的问句文本分类方法主要利用简单的机器学习模型或深度学习模型对不同类型的问句文本进行分类识别。文献[4]提出一种体育文本自动分类的半监督机器学习模型并取得了87%的分类精度。文献[5]提出一种基于时间加权函数(Temporal Weighting Function,TWF)的文本自动分类方法,实验结果表明,与基于传统支持向量机(Support Vector Machine,SVM)的文本自动分类方法相比,该方法的分类准确度提高了17%。文献[6]提出一种向量空间模型,通过对阿拉伯语言文本中的问题进行形式化及特征约束等处理,实现阿拉伯语言文本的分类及主题匹配。文献[7]结合人工标注和多类SVM对不同文本进行筛选,设计一种主动学习分类模型实现大型高维文本的精确分类,并减少了人工标注的工作量。文献[8]融合词向量和BTM模型对问题文本主题进行扩展,利用SVM进行问句分类。由于简单的机器学习模型难以捕获问句文本的深层抽象特征且受人工设计特征的误差影响,因此使其不能有效识别和处理相对复杂的问句文本。
深度学习技术的不断发展为问句文本分类提供了一种新的思路。文献[9]提出一种多层级注意力卷积长短期记忆(Multi-level Attention Convolutional Long Short-Term Memory,MAC-LSTM)网络的问句文本分类模型,实现问句文本的准确分类。文献[10]提出一种双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)网络的新闻文本分类识别方法,解决了新闻文本数据稀疏、维度爆炸以及人工设计特征参与标注带来的局限性等问题,提高了分类精度。文献[11]引入词向量模型并结合卷积神经网络(Convolutional Neural Network,CNN)进行问题分类,提高了未标注样本的利用率。文献[12]结合朴素贝叶斯支持向量机(Naive Bayes Support Vector Machine,NB-SVM)、词向量和长短期记忆循环神经网络(Recurrent Neural Network,RNN),提出一种混合深度学习模型的双语文本分类方法,提高了双语情绪文本的分类识别效果。文献[13]结合Word2vec和决策树并引入深度学习技术,实现了影评情感文本的准确分类。文献[14]针对邻域问题文本进行分类,并取得了较好的分类结果。
2 集成深度学习模型的旅游问句文本分类
旅游问句文本的句法和语义信息主要取决于文字组成和序列顺序。一方面,旅游问句的语法由多个疑问关键词和某些网络流行词组成,对文本序列中的词进行建模,构成文本序列的低层子空间结构信息。另一方面,旅游问句文本的语义信息和句法信息来自文本序列本身,因此本文使用one-hot方式对旅游问句文本进行编码建模,捕获文本的语义信息和句法信息。
为更好地表示旅游问句文本,本文提出一种集成深度学习模型的旅游问句文本分类算法。该算法主要由词级卷积神经网络、句级双向长短期记忆网络和多头注意力机制三部分组成,通过两种深度学习模型获取旅游问句文本的局部深层语义特征和低层子空间结构信息以及全局语义信息和深层结构信息,并利用多头注意力机制对其进行合并分类,实现两种深度学习模型在语言的句法和语义方面保持互补关系。
2.1 词级卷积神经网络
目前,卷积神经网络在场景分类、模式识别和图像分割等领域均具有广泛应用[15]。深度卷积神经网络中的卷积层和池化层不仅对文本中所含噪声具有很强的鲁棒性,而且其因为参数共享和局部连接特性可对文本的频谱或者语义进行建模[16],所以本文利用卷积神经网络对旅游问句文本中的词进行建模,进一步挖掘旅游问句文本中词的子空间结构信息。
在使用卷积神经网络提取旅游问句文本中词的相关特征时,将卷积层中预定义的1-of-n编码数字替换为旅游问句文本中的词[17],且最大编码数字为225。当使用文本中的词替换编码数字时,若每句文本中所含有的词不足以替换所有数字,则用数字0进行填充,即卷积神经网络中输入层的输入向量为(Nan,225,225),其中Nan表示空值,然后输入初始卷积层中对旅游问句文本的词进行编码,具体步骤如下:
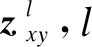
v=conv2(ω,x,″padding″)+b
(1)
其中,v表示初始卷积层的输出,ω表示权重矩阵,b表示偏置向量,padding表示填充,其输出表示为:
y=η(v)
(2)
其中,η(·)表示激活函数。
2)通过多层卷积层可计算得到旅游问句文本的卷积词汇特征向量:
(3)
3)通过最大池化层操作后可获得旅游问句文本中所有词的CNN特征向量:
(4)
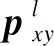
词级卷积神经网络在提取旅游问句文本中的词特征时,使用5层卷积和池化层,且每层神经元个数为32、64、128、256和512,且卷积核和池化核的大小分别为3×3和2×2。为进一步提高词级卷积神经网络对文本中词的建模能力,在5层卷积池化层后连接2层全连接层,即全连层中的神经元个数为512和64,从而实现旅游问句文本中词级子空间结构信息的提取。
由于词级卷积神经网络主要是用于捕获旅游问句文本中词的低层子空间结构信息和局部深层空间特征,因此需要对输入的旅游问句文本进行相关预处理,提高本文算法所提取特征的表征能力和抗噪能力。
2.2 句级双向长短期记忆网络
词级卷积神经网络主要获取旅游问句文本的词级低层子空间结构信息和局部深层语义信息,但忽略了旅游问句文本的全局语义信息。因此,为进一步挖掘旅游问句文本的全局语义特征,利用双向长短期记忆网络对旅游问句文本序列进行时空建模,具体步骤如下:
1)通过词嵌入技术[18]将旅游问句文本表示为一个one-hot编码向量,并利用前向和后向长短期记忆层对旅游问句文本编码向量序列中的时间特征进行建模。
2)利用双向长短期记忆(Long-Short Term Memory,LSTM)网络[19-20]对输入序列x之间的关系进行映射,并通过不同时刻的神经元激活状态计算得到输出序列y,计算公式为:
it=σ(wixxt+wiααt-1+wicct-1+bi)
(5)
文本序列在t时刻通过输入门it后,需要遗忘不必要的文本信息,计算公式为:
ft=σ(wfxxt+wfααt-1+wfcct-1+bf)
(6)
文本通过记忆单元的计算公式为:
ct=ft·ct-1+it·g(wcxxt+wcααt-1+bf)
(7)
文本通过输出门的计算公式为:
ot=σ(woxxt+woααt-1+wocct-1+bo)
(8)
文本通过上述计算可获得文本编码向量的输出,具体公式为:
αt=ot·h(ct)
(9)
yt=π(wyααt+by)
(10)
其中,·表示点乘运算,i表示输入门,f表示遗忘门,ft表示文本在t时刻通过遗忘门,o表示输出门,c表示记忆单元,σ表示激活函数,π表示总的输出激活函数,g、h表示记忆单元的输入和输出激活函数。
2.3 多头注意力机制
注意力机制[21-22]是指通过计算Q(Query)和每个K(Key)之间的相似性Sim(Q,K)以获取分配的权重,然后将分配的权重与相应的V(Value)值进行加权求和得到注意力权值,其中Q、K和V均为向量且K=V。与单一结构的注意力机制相比,多头注意力机制是对Q、K和V各维度分别进行多次线性映射并对其进行拼接,以获得最终的注意力权值。
本文利用多头注意力机制[23-24]不仅可对WL-CNN的低层信息和SL-Bi-LSTM的全局语义特征分配不同的权重,而且可进一步捕获不同位置和子空间的结构信息、深层全局语义信息以及内部结构信息。多头注意力权重的计算公式为:
(11)
其中,W表示线性变化参数,Q、K和V对应不同的W值。将式(11)进行多次线性映射及拼接后便可获得多头注意力的加权值,计算公式为:
MultiHead(Q,K,V)=Concat(Head1,
Head2,…,Headπ)Wo
(12)
其中,π表示多头注意力机制的并行层数,即该多头注意力机制包含π个头。
综上所述,本文使用词级卷积神经网络和句级双向长短期记忆网络来学习词序列子空间向量和句序列深层语义信息,并通过多头注意力机制将两种深度学习模型进行集成,实现子空间信息和句子语义信息的互补,如图1所示。

图1 集成深度学习模型的旅游问句文本分类过程
可以看出,将旅游问句文本以单词形式输入词级卷积神经网络中,基于该神经网络的计算获取文本中词的低层子空间结构信息和局部深层语义信息xword,旅游问句文本以句子的形式输入SL-Bi-LSTM中,通过学习该神经网络获得旅游问句文本的深层结构信息和全局语义信息xsentence。在此基础上,利用多头注意力机制对两种深度学习模型获得的层次特征进行权值匹配,并对各注意力机制所得注意力权重进行点积拼接,通过SoftMax分类函数得到文本的准确分类结果z1~zm,其中m表示分类类别数。
3 实验结果与分析
3.1 实验数据集
本文采用Tourism text数据集作为实验数据集,其为自定义的基准数据集,主要来自携程、途牛、马蜂窝和同程等旅游网站,包括旅游地点、时间和人物等6类10 000条样本数据。在实验前需对该数据集进行筛选、清洗、停用词等预处理操作减少误差。为验证本文算法的有效性,从各类样本中随机抽取60%的样本作为训练集,剩余40%的样本作为测试集,并随机划分训练集中10%的样本作为交叉验证集(实验共进行5次交叉验证),数据集统计结果如表1所示,其中All Doc表示每类旅游问句文本的总数。

表1 数据集统计结果
3.2 实验方法
将本文旅游问句文本分类算法与以下主流旅游问句文本分类算法进行对比:
1)基于CNN[25]的旅游问句文本分类算法。该算法主要是对中文文本中的词采用随机初始化嵌入,并输入卷积神经网络中进行分类。为使该算法在中文问句文本分类中取得理想的分类结果,采用与文献[25]相同的随机初始化词嵌入方法,获取中文问句文本中的词向量特征。
2)基于Word2vec+LR[26]的旅游问句文本分类算法。该算法利用词向量嵌入表示每种类型的文本,并将其映射到低维空间向量中使用逻辑回归模型进行文本分类。
3)基于Word Embeddings+SVM的旅游问句文本分类算法。该算法类似于基于Word2vec+LR的旅游问句文本分类算法,是将问句文本嵌入到低维空间向量中使用浅层机器学习模型实现文本分类。
4)基于LSTM与Bi-LSTM[27]的旅游问句文本分类算法。这两种算法是将训练的中文问句文本词向量按照时序依次输入网络模型,并对中文问句文本进行时序扩展和深层语义信息的捕获,实现中文问句文本的准确分类。
5)基于自注意力网络(Self-Attention Network,SAN)的旅游问句文本分类算法。该算法结合词向量技术,将中文问句文本映射到一个低维空间向量,并通过注意力网络对关键特征分配权重实现中文文本的准确分类。
6)基于RNN的旅游问句文本分类算法。该算法解决了卷积神经网络忽略全局语义信息及梯度消失等问题,进一步提高了分类算法的准确率。
7)基于独立循环神经网络(Independently RNN,Ind-RNN)的旅游问句文本分类算法。该算法解决了RNN算法梯度消失及不能对长时序特征进行有效建模的问题。
8)基于CNN-LSTM的旅游问句文本分类算法。该算法主要将CNN和LSTM进行串联,在利用CNN捕获问句文本的空间特征后再对其进行时序建模,以提高文本分类精度。
3.3 实验环境和参数设置
本文实验软件配置为Python 3.6和Keras、Numpy等框架,硬件配置为GTX1060 GPU。为确保文本分类算法的一致性,本文对其设置初始化参数,WL-CNN的嵌入向量设置为512,其具有两层卷积层且卷积核大小分别为3×3和1×1,神经元个数为512和128,学习率为0.000 1,丢码率为0.5。SL-Bi-LSTM的嵌入向量设置为512,神经元个数为256和64,学习率为0.02。在利用多头注意力机制进行集成时将π设置为10并对其分配不同的权重比例,同时采用概率计算统计不同类别的出现概率,实现旅游问句文本的正确分类。在前期实验中将词向量映射维度设置为100维,在后期实验中随着F-Score的变化对词向量映射维度进行调整。
3.4 实验结果
本文采用准确率、损失率、模型训练时间和F-Score进行实验结果评估,其中F-Score的计算公式如下:
(13)
其中,P表示精确率,R表示召回率。
3.4.1 词向量映射维度对算法性能的影响
由于词向量映射维度对算法分类精度具有至关重要的作用,因此本文通过改变词向量映射维度来验证其对旅游问句文本分类精度的影响。图2显示了Tourism text数据集在不同词向量嵌入维度下两种算法的F-Score对比。可以看出,随着词向量映射维度的增加,本文旅游问句文本分类算法的F-Score先快速增加,当词向量映射维度大于100时F-Score停止增加且开始减少,这表明过低的词向量映射维度不能较好地将文本映射到低维空间,而高维嵌入可能导致向量表示过于稀疏,不能有效提高分类性能且会耗费更多的训练时间。
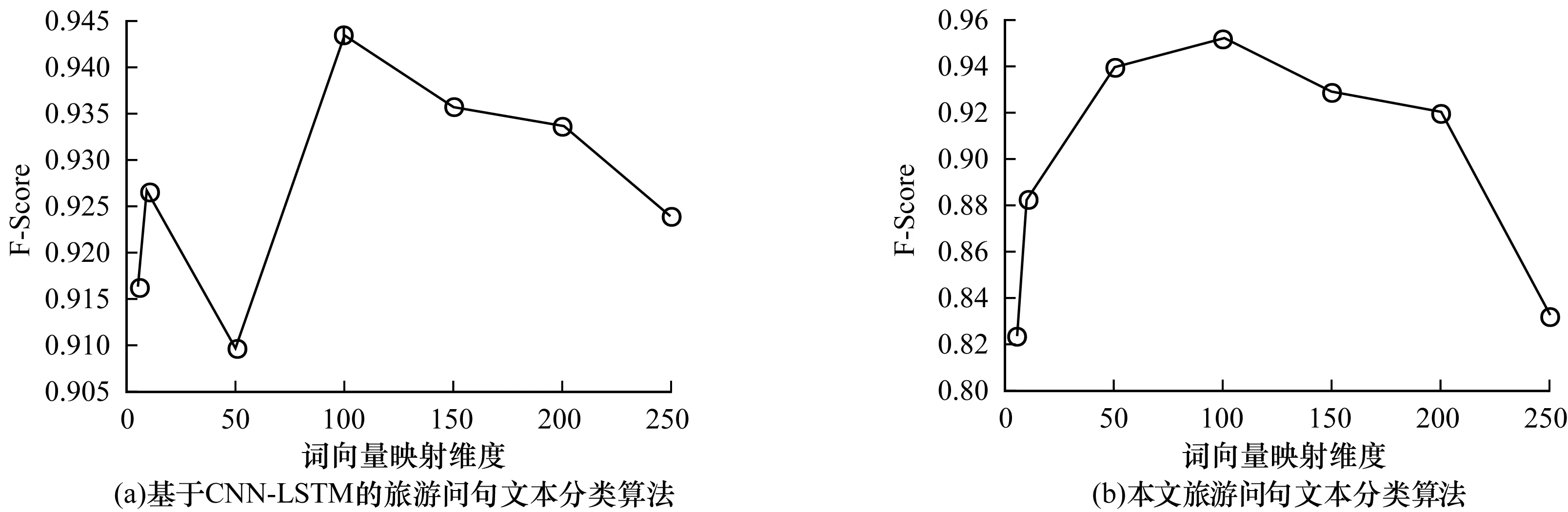
图2 不同词向量映射维度时旅游问句文本分类算法的实验结果
3.4.2 旅游问句文本分类算法的性能比较
为进一步验证本文算法的有效性,将其与不同问句文本分类算法进行对比,实验结果如表2所示,其中加粗数据表示最优结果。
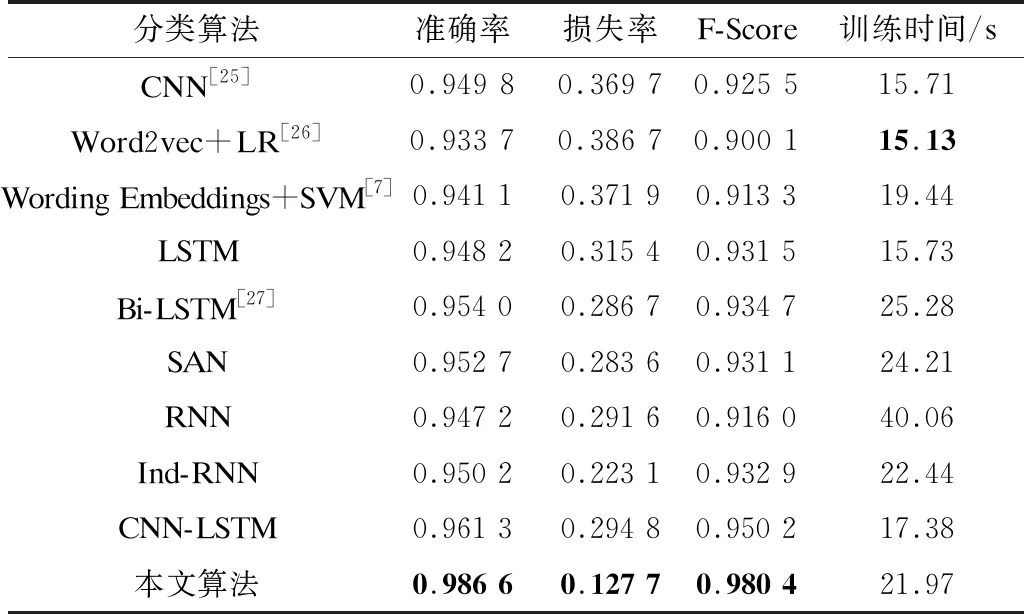
表2 10种旅游问句文本分类算法的性能比较结果
可以看出,基于Ind-RNN的旅游问句文本分类算法损失率为0.223 1,因为Ind-RNN内部神经元相互独立,且各层之间实现了跨层连接,所以其相比基于RNN的旅游问句文本分类算法更好地解决了梯度消失问题。基于Word2vec+LR和Wording Embeddings+SVM的旅游问句文本分类算法虽然取得了较好的分类结果,但其仅适用于小规模数据,其主要原因为基于浅层机器学习模型的旅游问句文本分类算法不能较好地捕获问句文本中隐藏的潜在信息,因此其相比基于深度学习模型的旅游问句文本分类算法准确率较低。基于Bi-LSTM的旅游问句文本分类算法的准确率和损失率均优于基于LSTM的旅游问句文本分类算法,其主要原因为基于Bi-LSTM的旅游问句文本分类算法同时使用前向和后向LSTM对文本进行编码,更好地捕获了旅游问句文本的上下文信息。与其他旅游问句文本分类算法相比,本文算法在准确率和损失率上分别取得了0.986 6和0.127 7的最优结果,相比基于CNN-LSTM的旅游问句文本分类算法提高了0.025 3和降低了0.167 1,其主要原因为本文算法不仅能捕获旅游问句文本的深层结构信息和全局语义信息,而且可对各类特征分配不同权重,从而实现准确分类。但是其在训练时间上略显不足,其主要原因为神经网络在集成时算法的总参数量有所增加,因此导致耗时较长。
3.4.3 旅游问句文本的可视化结果
为更直观地表示旅游问句文本分类后的结果,本文使用t-SNE可视化工具对分类结果进行可视化显示,得到旅游问句文本嵌入表示的可视化结果如图3所示。可以看出,基于CNN+LSTM的旅游问句文本分类算法不能较好地区分各类旅游问句文本,其主要原因为该算法仅对旅游问句文本的局部特征和语义信息进行建模,而忽略了旅游问句文本全局信息、上下文层级关系以及文本中的词对文本的影响。与基于CNN+LSTM的旅游问句文本分类算法相比,本文算法能更有效地对不同旅游问句文本进行分类且分类性能更好。
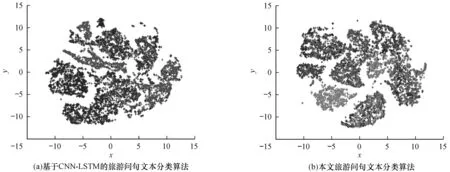
图3 旅游问句文本嵌入表示的可视化结果
4 结束语
本文提出一种改进的旅游问句文本分类算法,通过WL-CNN和SL-Bi-LSTM捕获旅游问句文本的局部和全局特征,并有效刻画了旅游问句文本的语义信息和上下文层级关系,同时利用多头注意力机制对所捕获的特征信息分配注意力权重,实现旅游问句文本的有效分类。后续将研究旅游问句文本的细粒度分类算法,通过对旅游问句文本中含有的关键词做进一步表征,增强特征信息对旅游问题文本的表征能力并提高分类准确度。
